
- 전체보기(79)
- am(64)
- LG CNS AM Inspire Camp(64)
- Springboot(15)
- React(14)
- msa(11)
- frontend(10)
- docker(7)
- Java(5)
- NAVER MAP(4)
- Spring(4)
- SpringSecurity(4)
- CSS(3)
- routing(3)
- bean(3)
- State(3)
- component(3)
- aop(3)
- kafka(3)
- Naver API(3)
- react-query(3)
- Database(2)
- cloud(2)
- Route(2)
- API(2)
- backing service(2)
- JavaScript(2)
- useCallback(2)
- lifecycle(2)
- Cloud Native(2)
- Spring Container(2)
- memo(2)
- di(2)
- MPA(1)
- router(1)
- MVC(1)
- playwright(1)
- 다형성(1)
- DAL(1)
- Lighthouse CI(1)
- useEffect(1)
- useState(1)
- View(1)
- Transpiler(1)
- js(1)
- ref(1)
- network(1)
- 중첩 라우팅(1)
- electron(1)
- 업캐스팅(1)
- useParams(1)
- 클래스형 컴포넌트(1)
- entity(1)
- database access layer(1)
- transaction(1)
- Prettier(1)
- ComponentScan(1)
- login(1)
- stream(1)
- config server(1)
- lighthouse(1)
- https(1)
- Infra(1)
- queryKey(1)
- 번들러(1)
- REST API(1)
- JWT(1)
- 컨테이너(1)
- 트랜잭션(1)
- application(1)
- context(1)
- theme(1)
- hikari(1)
- Kafka Connect(1)
- Sink Connector(1)
- dependency injection(1)
- 제네릭(1)
- useMemo(1)
- useRef(1)
- intercepter(1)
- Code Formatter(1)
- DOM(1)
- axios(1)
- repository(1)
- html(1)
- markup(1)
- BrowserRouter(1)
- API Gateway(1)
- font(1)
- 성능 측정(1)
- 다운캐스팅(1)
- zipkin(1)
- spring mvc(1)
- monitoring(1)
- mock(1)
- form(1)
- Fetch(1)
- spa(1)
- aws(1)
- cookie(1)
- bundler(1)
- e2e(1)
- D2Coding(1)
- devops(1)
- docker compose(1)
- jetbrains Mono(1)
- kafka connector(1)
- component scan(1)
- vscode(1)
- session(1)
- scope(1)
- useSearchParams(1)
- service descovery(1)
- test(1)
- 서비스 통신(1)
- virtual DOM(1)
- cors(1)
- web(1)
- hooks(1)
- responsive web(1)
- Circuit breaker(1)
- View Resolver(1)
- proxy pattern(1)
- http(1)
- eureka(1)
- ResponseEntity(1)
- Microservices Architecture(1)
- 트랜스파일러(1)
- 함수형 컴포넌트(1)
- volume(1)
- PORT(1)
- lambda(1)
CustomMockService npm 패키지 만들기 - 2
INTRO 이전 포스팅에 이어서 아이디에이션 과정과 개발 과정을 포스팅해보려고 한다 1. XMLHttpRequest 인터셉트 구현 이전 포스팅에서 설명한 것과 같이 XMLHttpRequest 방식과 Fetch API 방식을 모두 구현해서 레거시 환경까지 커버하는
CustomMockService npm 패키지 만들기 - 1
웹 개발을 진행할때는 주로 MSW를 사용해서 서버 상태를 모킹시켜서 사용하곤 했었다.하지만, POPI 프로젝트에서 사용자 어플리케이션을 개발할 때, 그리고 이번에 진행하는 Nextron 프로젝트를 진행하면서도 MSW는 동작하지 않았다.물론 필자가 세팅을 제대로 못한 것
Zod에서 스키마 정의가 필요한 이유
최근에 커스텀 로깅 패키지를 만들면서 apiValidation 이라는 유틸리티를 구현하려고 했다.아이디어는 간단했다. 제네릭으로 타입을 받고 매개변수로 response를 받아서 타입 체크를 통해 문제가 있는 경우에만 콘솔로그를 찍도록 하는 것이었다.하지만 구현 과정에서
커스텀 Logger npm 패키지 구현해보기
INTRO 요즘 개발하면서 디버깅할 때 console.log를 자주 사용하는데, 로깅을 너무 대충찍다보니 관리하는게 꽤 복잡했다 특히 복잡한 프로젝트에서 여러 파일에 걸쳐 로그가 흩어져 있으면, 어느 파일의 어느 함수에서 출력된 건지 추적하기가 쉽지 않았다. 그래서
[FE] 에러핸들러 패키지 만들어보기
INTRO 이번에 운이좋게도 새로운 프로젝트를 진행하게 되었다. UI를 Next.js 환경에서 App Router를 사용하여 개발을 진행하는 중이다. 이전에 POPI 프로젝트를 진행하면서 고민했던 부분 중 하나는 에러를 어디서 어떻게 처리하는게 적절할까? 였다.
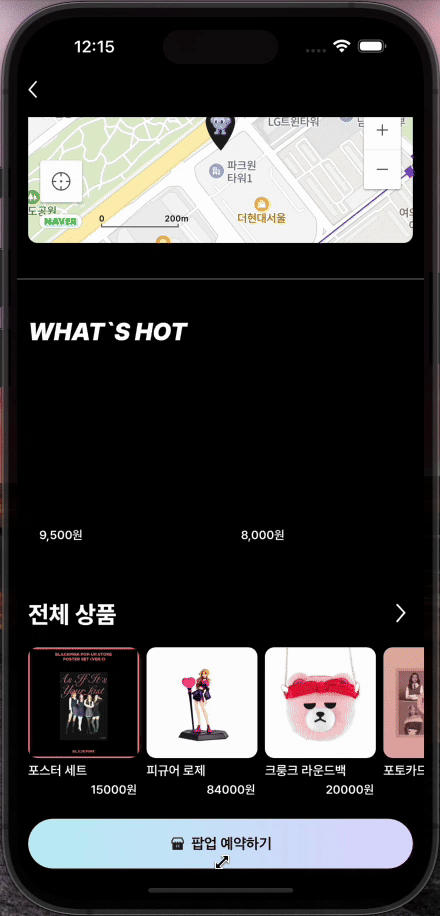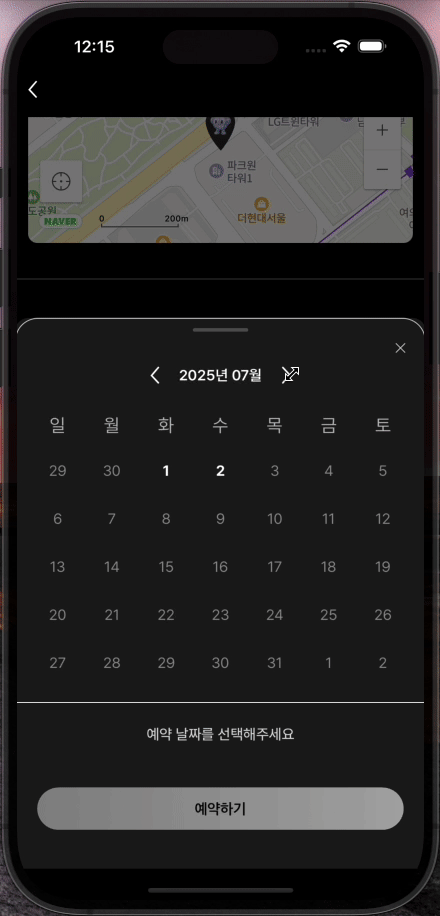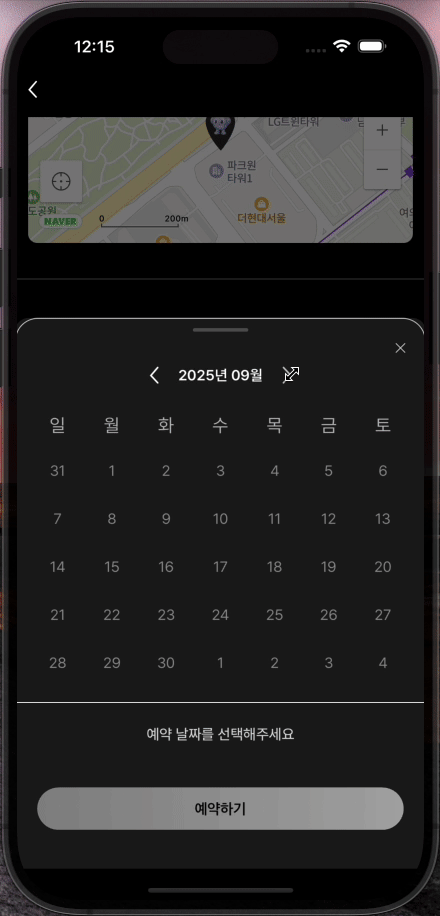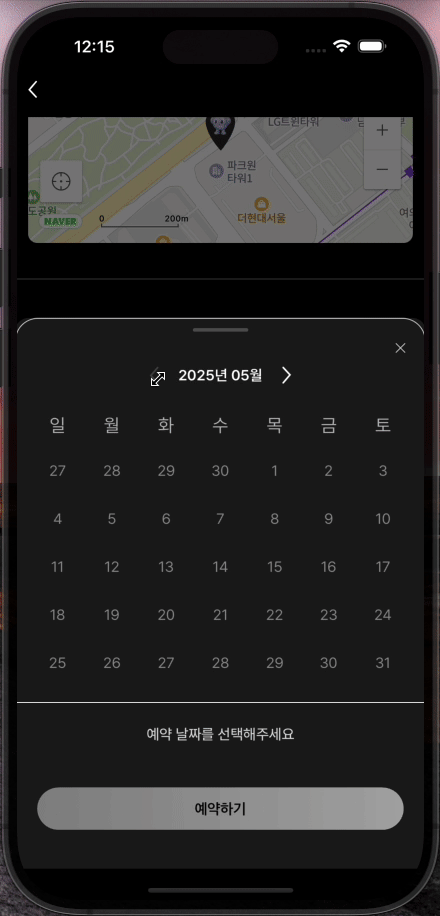
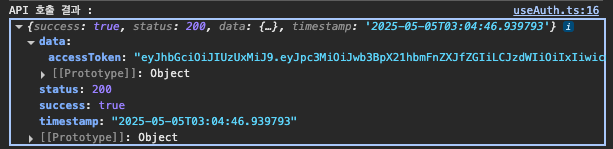
[FE] Prefetch 사용해보기
프로젝트에서 사용자 어플리케이션을 개발하고 실제로 사용해보니 약간의 UX 문제를 발견했다. 바텀시트에서 월을 변경할 때마다 로딩 인디케이터가 나타나서 사용자 경험이 매끄럽지 않았던 것이다. 이번 포스팅을 통해, 어떤 문제였고 어떻게 해결했는지 아주 간단하게 소개해보
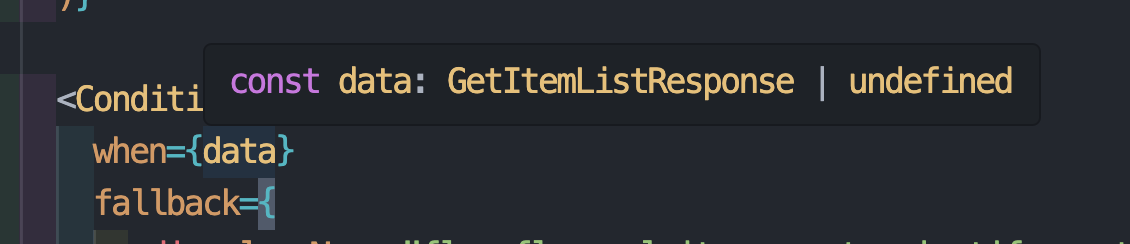
[FE] 팀 개발을 위한 조건부 렌더링 규칙 만들기
INTRO 개발을 진행하면서 코드가 꽤 읽기 어려운 경우를 모두 경험해봤을 것이다. 필자의 경우에도 본 프로젝트에서 그런 경험을 가끔 느꼈는데, 그런 경우 대부분 조건문이 하나의 컴포넌트 내에서 많이 적용된 경우라는 것을 알게 되었다. 하나씩 따라가다 보면 물론
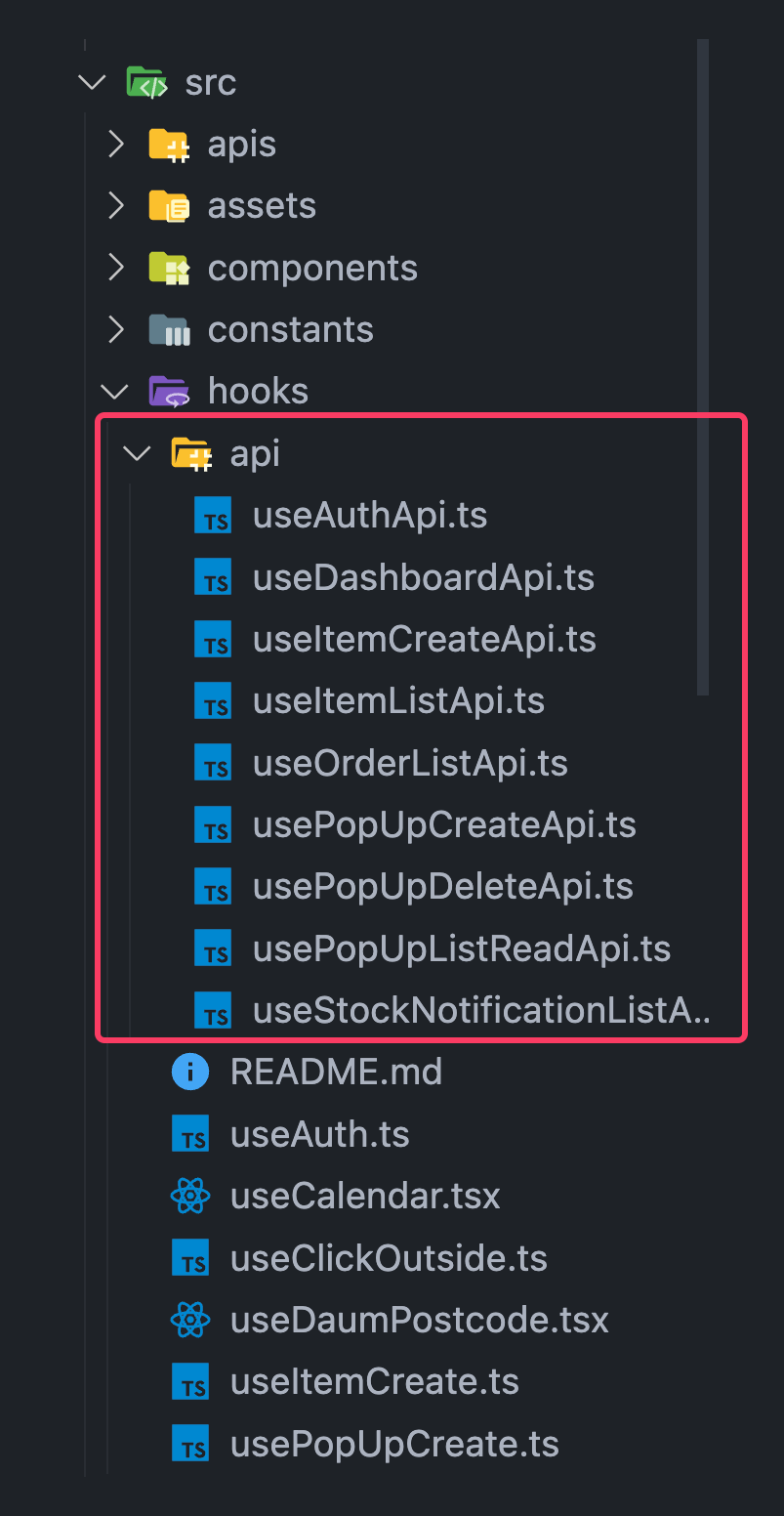
[FE] Query Key 모듈화하여 관리하기
프로젝트가 커지면서 React Query 쿼리키 관리가 점점 복잡해졌다. 여러 파일에 흩어진 쿼리키들을 찾아다니며 캐시를 무효화하는 작업이 어느순간부터 번거롭다고 느껴졌고, 이를 해결하기 위해 `Query Key 모듈화` 를 도입하게 되었다.

[FE] 세상에 완벽한 성능 측정은 없다
여러 개발 커뮤니티에서 진행되는 세션을 살펴보면 간혹 성능 개선 이라는 주제로 진행되는 세션을 볼 수 있다.그런데 그러한 세션들은 성능 개선 이라는 주제로 발표를 진행하기 때문에, 어떻게 성능 측정 을 진행했는지는 간단하게 소개하거나 그냥 넘어가는 경우가 많다.필자는
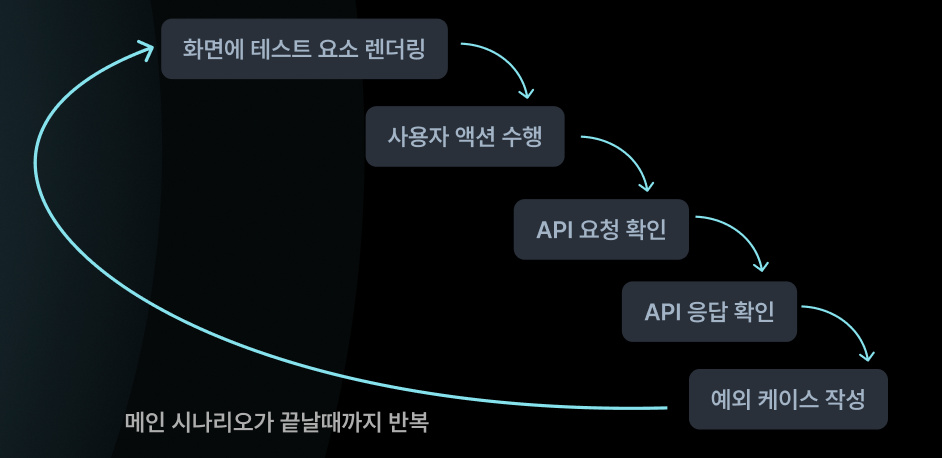
Playwright를 사용한 E2E 테스트 적용기
이번 프로젝트를 진행하면서 E2E 테스트를 진행하기위해 Playwright를 도입하게 되었다. E2E 테스트를 도입하게된 이유는, 여러 이유가 있겠으나 사용자 경험이 우리가 예상한대로 흘러가는지를 테스트하기 위함이다 그렇기 때문에, 실제 개발 서버에 API를 호출하

[LG CNS AM Inspire Camp 1기] 2차 미니프로젝트 회고록
2차 프로젝트가 끝나고 3일이 지난 이제서야 회고록을 써보려고 한다 😅프로젝트 기간 동안 많은 트러블 슈팅이 있었고, 이를 해결하기 위해 정말 많은 시간과 노력을 쏟았다. 짧은 기간이었지만 MSA 아키텍처와 클라우드 환경에서의 서비스 구축을 직접 경험하면서 의미 있는
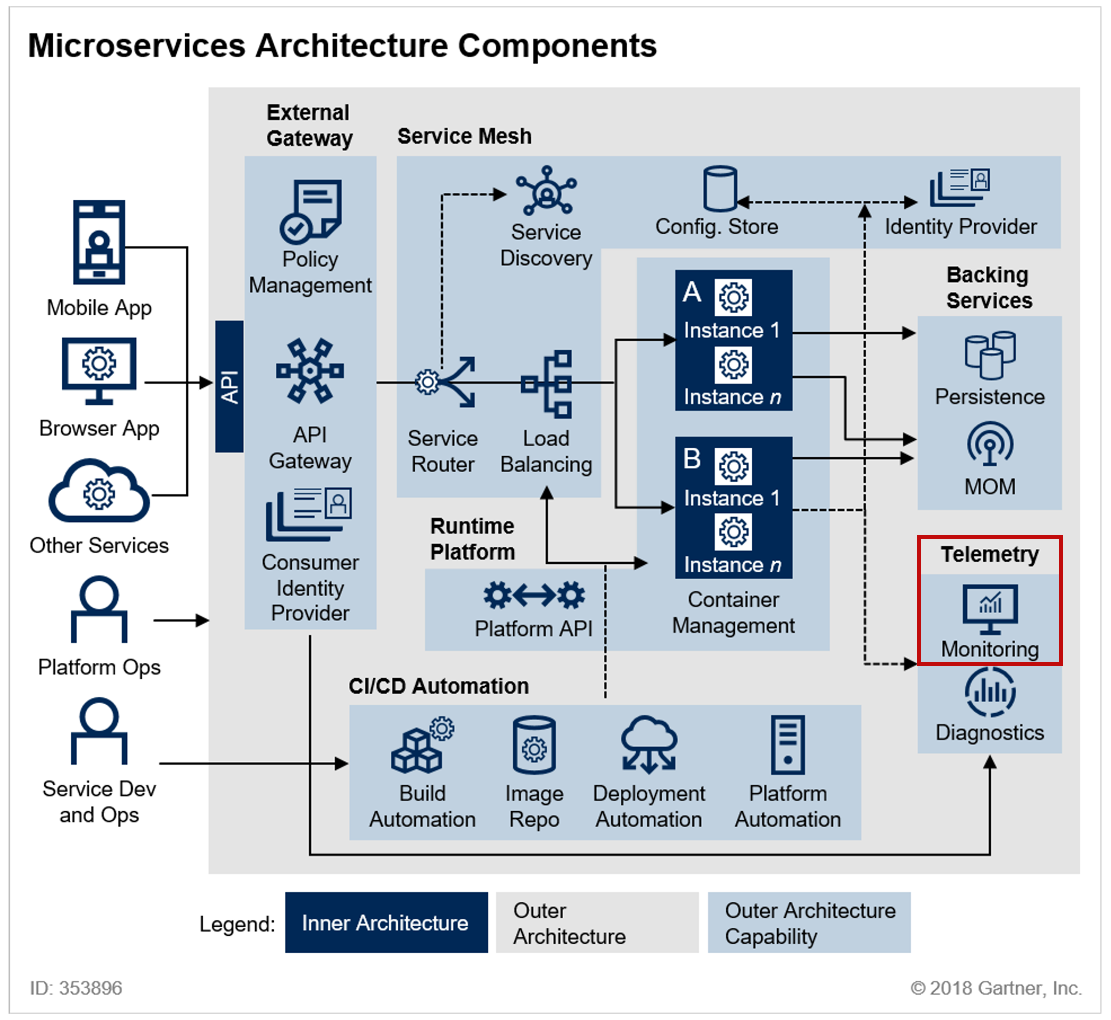
[LG CNS AM Inspire Camp 1기] MSA (9) - Zipkin을 이용한 분산 트레이싱
이전 포스팅에서는 서킷 브레이커 패턴을 이용하여 마이크로서비스 아키텍처에서 회복성을 확보하는 방법에 대해 살펴봤다.이번 포스팅에서는 MSA 환경에서 또 다른 중요한 문제인 '디버깅과 모니터링'을 해결하는 분산 트레이싱 시스템인 Zipkin에 대해 알아보고, 실제로 적용
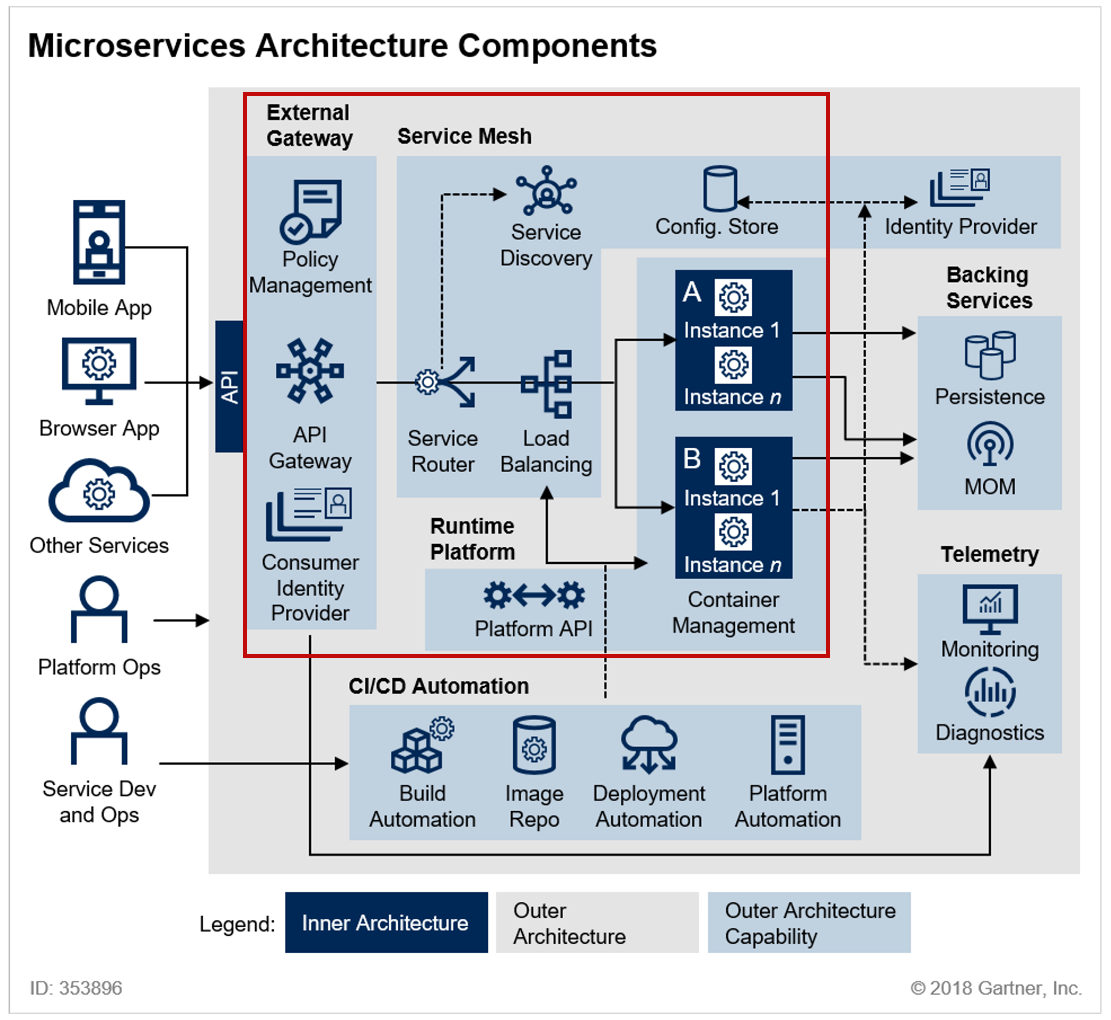
[LG CNS AM Inspire Camp 1기] MSA (8) - 서킷 브레이커
이전 포스팅에서는 Kafka를 이용해서 마이크로서비스 간 데이터 일관성 문제를 해결하는 방법에 대해 살펴봤다.이번 포스팅에서는 마이크로서비스 아키텍처에서 또 다른 중요한 패턴인 서킷 브레이커(Circuit Breaker)에 대해 알아보고, 실제로 적용해보자 👀
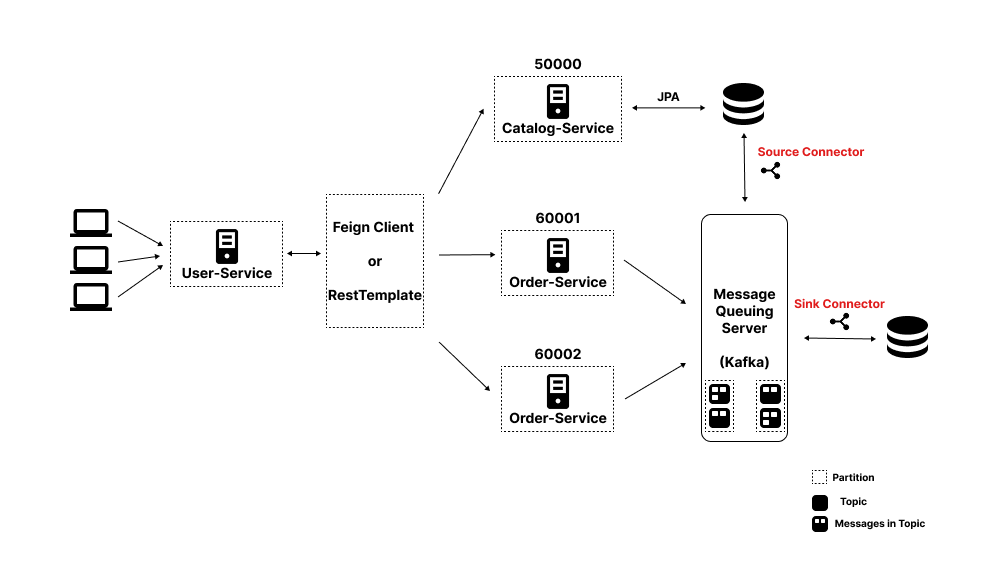
[LG CNS AM Inspire Camp 1기] MSA (7) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (3)
이전 포스팅에서는 Sink Connector만 사용해서 Kafka 토픽에 데이터를 저장하면 DB에 자동 저장되도록 구현을 해봤다.이번 포스팅에서는 간단하게 Source Connector를 사용해보는 포스팅을 작성해보려고 한다 👀이전 포스팅에서 작성한 내용과 같이 Si
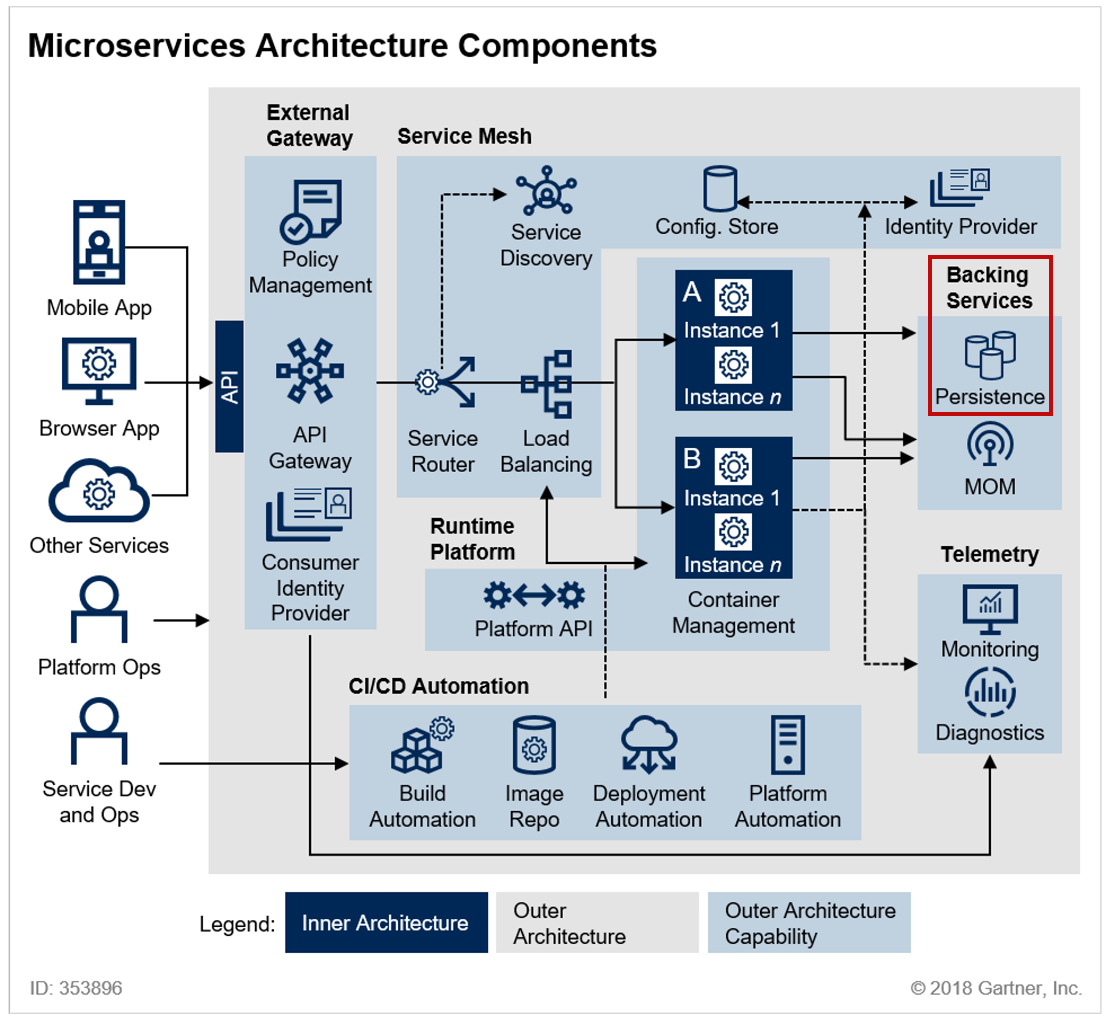
[LG CNS AM Inspire Camp 1기] MSA (6) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (2)
이전 포스팅에서는 Catalog Service에 Kafka를 적용하는 과정을 살펴봤다.현재 진행과정을 간단하게 리마인드해보면 Kafka 도커 컨테이너를 9092 포트에 매핑해서 띄워둔 상태이고, Kafka를 사용하기 위한 명령어들을 다운로드 받은 상태이다.이번 포스팅에
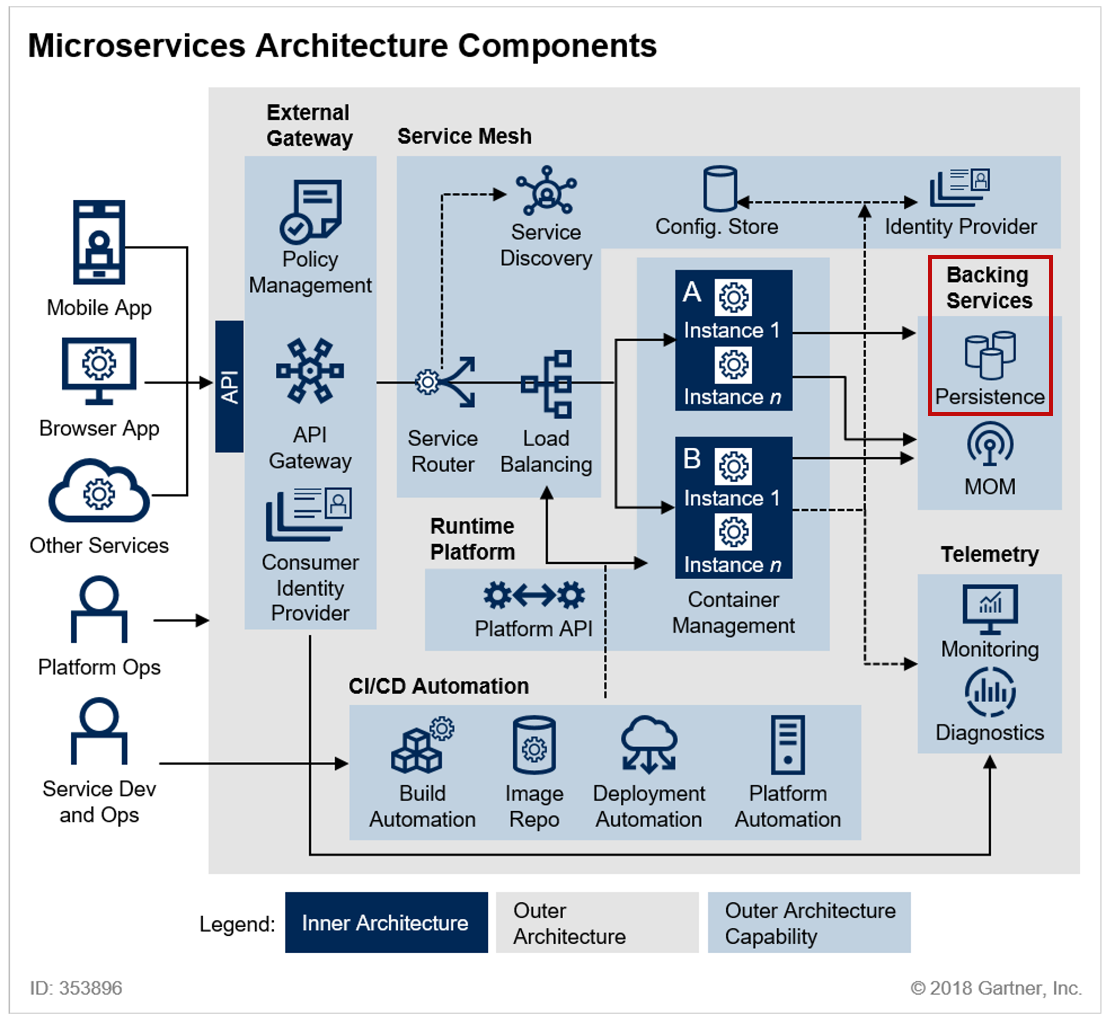
[LG CNS AM Inspire Camp 1기] MSA (5) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (1)
이전 포스팅에서 마이크로서비스 간 통신 방법에 대해 알아봤다. 특히 여러 서비스 인스턴스를 운영할 때 발생하는 데이터 일관성 문제를 다뤘는데, 이번에는 Kafka를 활용해 이 문제를 어떻게 해결할 수 있는지 알아보려고 한다 👀 먼저 이전 포스팅에서 살펴본 문제를 다시
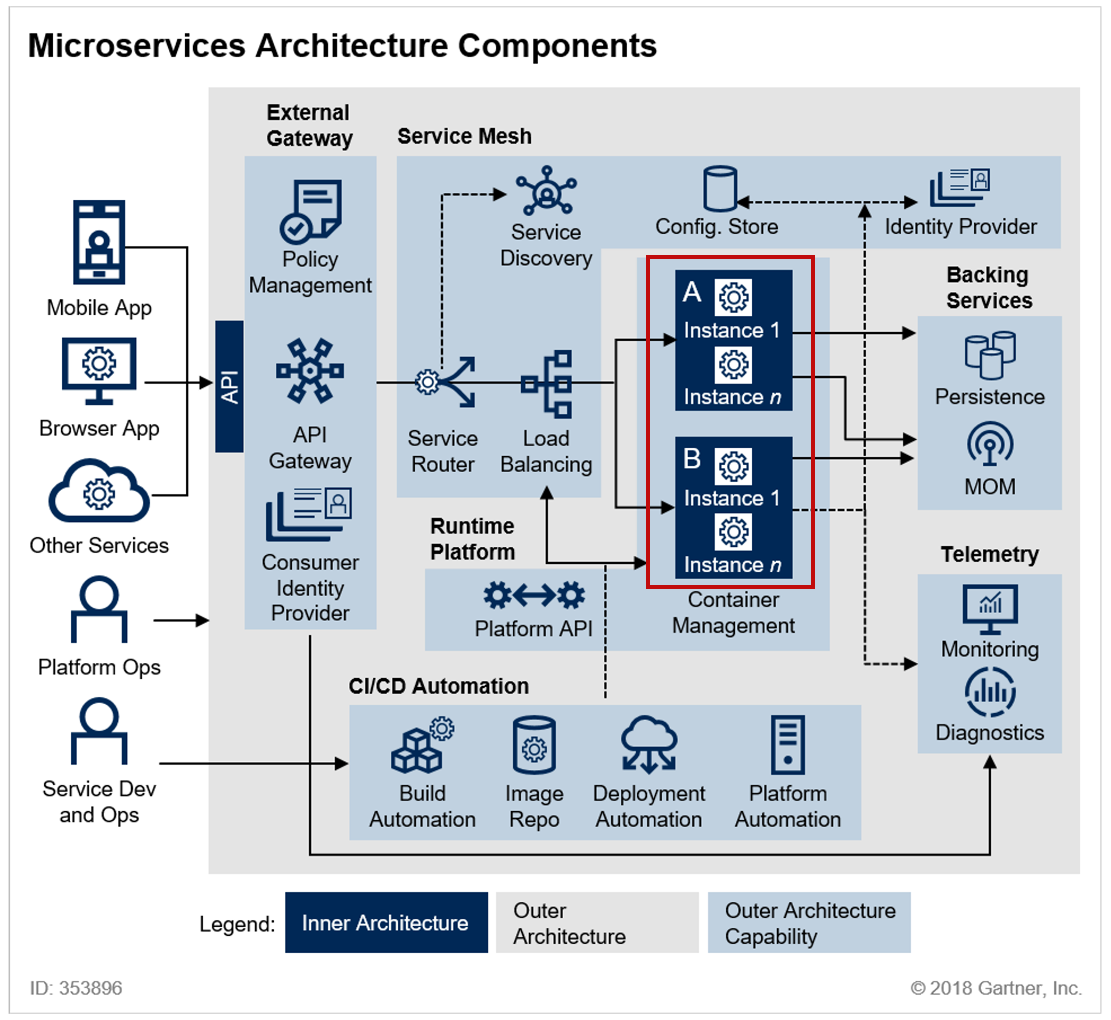
[LG CNS AM Inspire Camp 1기] MSA (4) - 서비스 사이에서 API 통신
이전 포스팅에서는 Spring Cloud Config Server에 대해 알아봤다.MSA를 채택했다면 서비스 사이에서 데이터를 주고받아야하는 경우가 대부분일 것이다. 따라서, 이번에는 MSA 환경에서 서비스 간 통신 방법에 대해 정리해보려고 한다 👀MSA 환경에서는
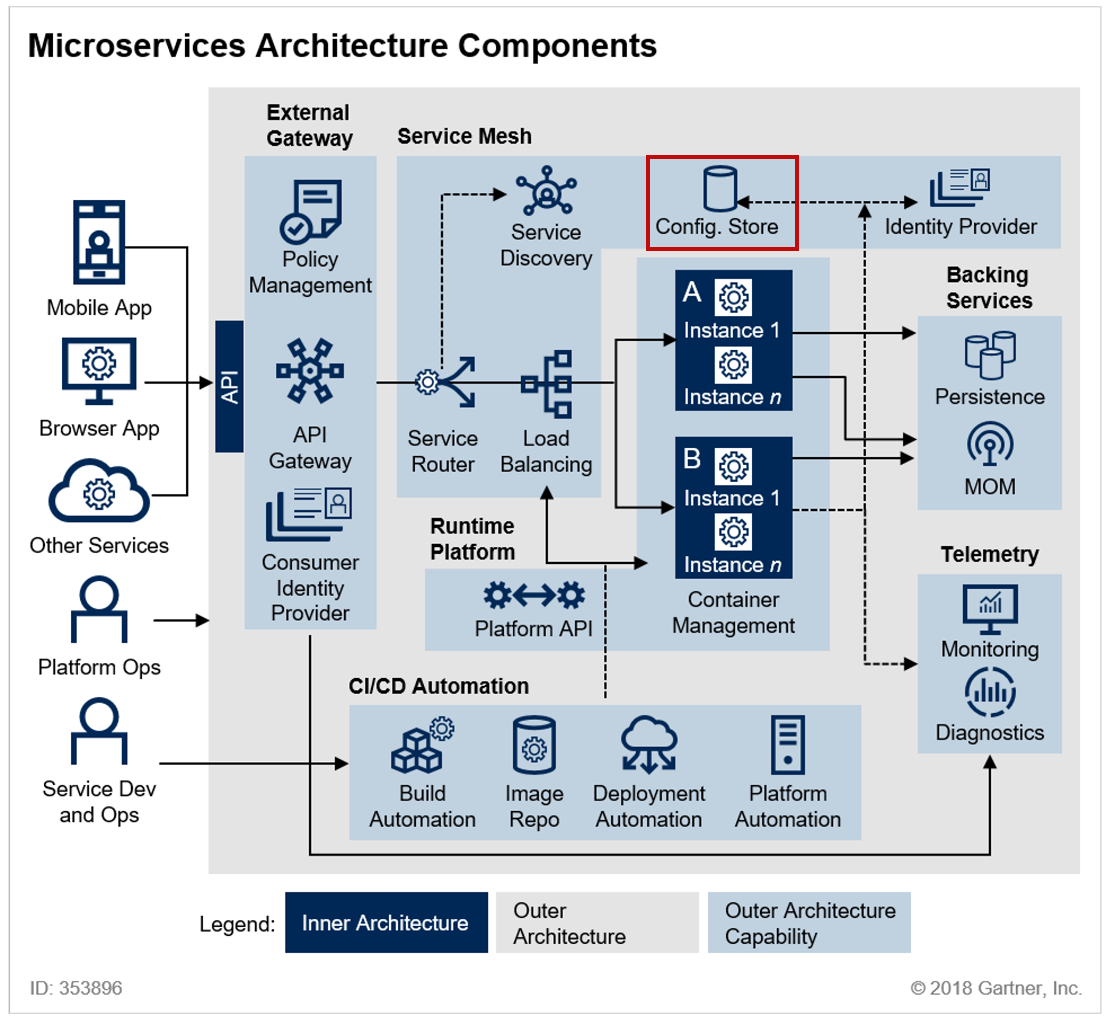
[LG CNS AM Inspire Camp 1기] MSA (3) - Config Server & RabbitMQ
이전 포스팅에서는 API Gateway에 대해서 알아봤다. API Gateway는 MSA와 같은 분산 시스템 환경에서 요청을 적절하게 라우팅을 해주기 위해 사용했었다. 앞으로도 계속해서 MSA 아키텍처에서 필요한 내용을 하나씩 정리해볼건데, 이번에는 여러가지 서비
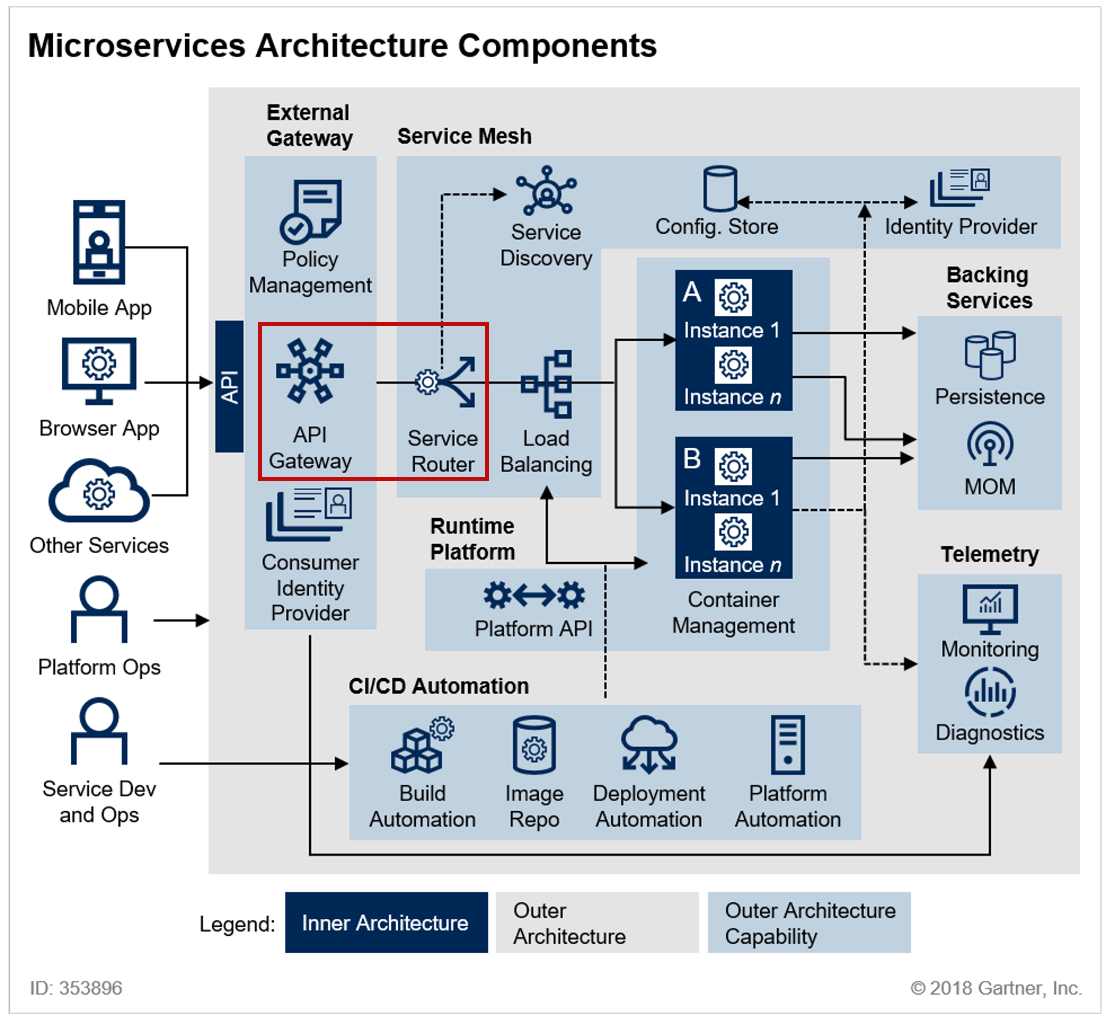
[LG CNS AM Inspire Camp 1기] MSA (2) - API Gateway
이전 포스팅에서 서비스 인스턴스의 정보를 관리하는 서비스 디스커버리에 대해서 정리해봤다.이번에는 이 정보를 사용하여 여러가지 작업을 수행하는 API Gateway에 대해서 정리해보려고 한다 👀
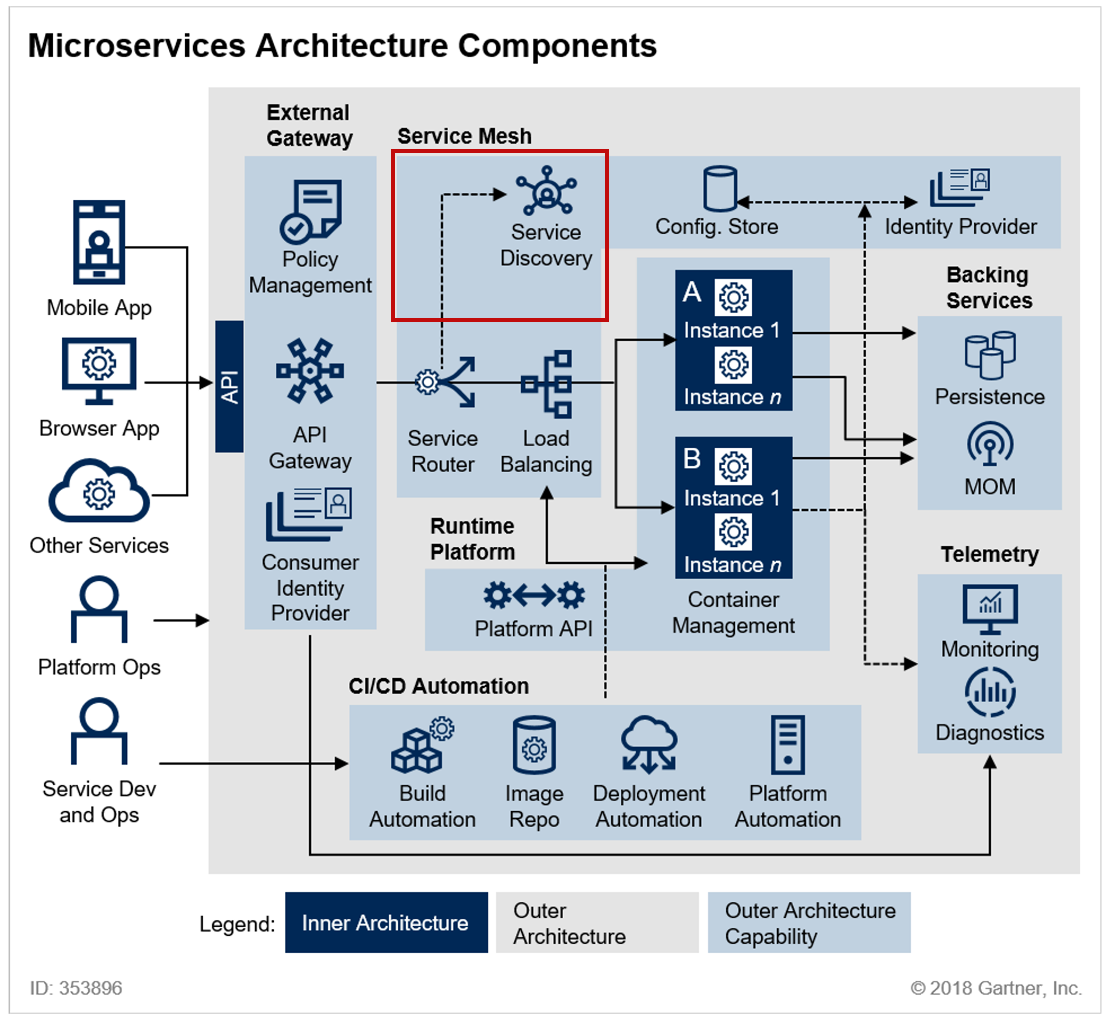
[LG CNS AM Inspire Camp 1기] MSA (1) - MSA와 서비스 디스커버리
오랜만에 포스팅을 쓰는 것 같다 😅최근 MSA(마이크로서비스 아키텍처) 관련 강의를 들으면서 여러 흥미로운 개념들을 접하게 되었고, 이전보다 더 명확하게 이해하게 된 것 같아 이제부터 정리해보려고 한다.이번 포스팅에서는 MSA의 기본 개념을 다시 한번 살펴보고, 이