[LG CNS AM Inspire Camp 1기] MSA (7) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (3)
LG CNS AM Inspire 1기
INTRO
이전 포스팅에서는 Sink Connector만 사용해서 Kafka 토픽에 데이터를 저장하면 DB에 자동 저장되도록 구현을 해봤다.
이번 포스팅에서는 간단하게 Source Connector를 사용해보는 포스팅을 작성해보려고 한다 👀
1. Source Connecotor 사용 이유?
이전 포스팅에서 작성한 내용과 같이 Sink Connector만 사용해도 우리가 원하는 작업을 충분히 수행할 수 있다.
사용자가 주문을 요청하면 주문 정보를 Kafka Topic에 저장하도록 Producer 코드를 작성하고, Sink Connector가 Topic에서 변경 사항이 발생하면 DB에 데이터를 저장하는 식이다.
당연히 각 요청은 Kafka Topic에 저장되기 때문에 비동기 방식으로 데이터를 DB에 저장할 수 있다.
그렇다면 이와 같은 구조에서 Source Connector를 어떻게 사용할 수 있고, 만약 사용한다면 왜 Source Connector를 사용하는걸까?
💡 구조도
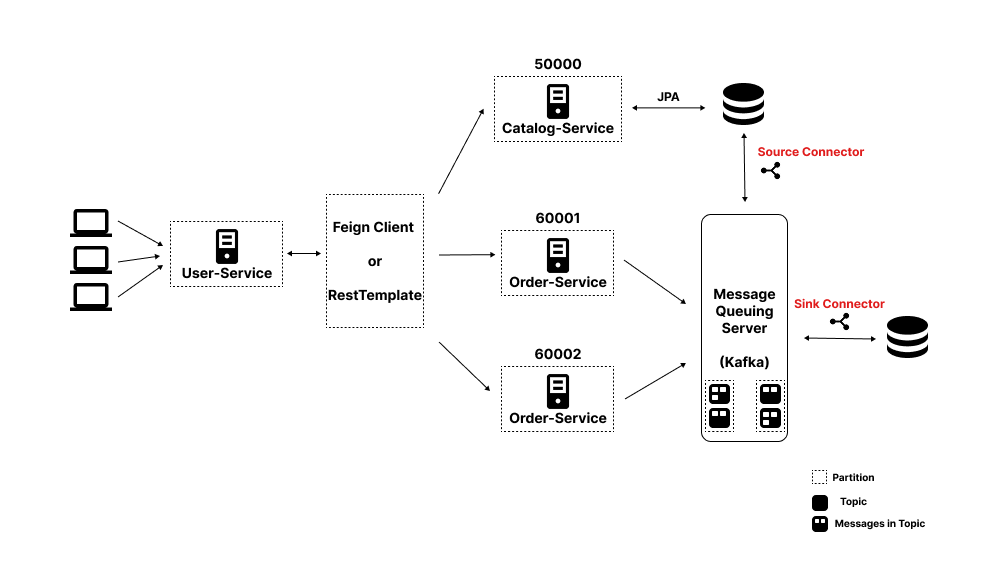
필자가 생각하는 구조는 다음과 같다.
만약, Catalog-Service가 SpringBoot 프레임워크 기반의 코드가 아닌 다른 언어로 작성된 API 서비스라고 생각해보자
여기서 개발자는 Catalog 정보는 중요한 정보라고 판단하기 때문에, 동기방식으로 JPA를 사용하여 DB에 데이터를 저장한다고 가정해보자
이때, 위 구조도에서 보다시피 Source Connector는 DB에서 변경된 내용을 감지하여 Kafka의 토픽으로 메세지를 가져온다.
여기서 만약, 개발자가 원한다면 토픽에 가져온 메세지를 이용하여 Order-Service와 관련된 DB에 무언가 작업을 진행할수도 있을 것이다.
이처럼, Source Connector는 특정 대상(ex. DB)에서 변화가 발생하면 Kafka Topic으로 메세지를 전송해주는 역할을 수행할 수 있으며, Sink Connector와 조합하여 다른 서비스와 연관된 여러가지 작업을 수행할 수 있을 것이다.
💡 양방향 구조
방금 가정한 내용처럼, Source Connector와 Sink Connector를 같이 사용하여 변화를 계속 감지하고 이를 기반으로 업데이트를 진행하는 구조를 양방향 구조 라고 한다.
이러한 구조를 채택한다면, 데이터 동기화를 자동화시킬 수 있다.
즉, 한쪽 DB의 변경이 다른 DB에도 자동으로 반영되는 방식으로 자동화를 구현할 수 있다는 장점이 있다.
또한, DB를 직접 수정하는 관리 도구나 백오피스 시스템이 있을 때, 그 변경사항을 마이크로서비스에 전파할 수 있을 것이다.
당연히 DB 동기화를 진행한다면, 서비스가 일시적으로 다운되어도 이전 작업 내용을 빠르게 복구할 수 있다는 장점이 있을 것이다.
2. Source Connector 사용해보기
필자는 이번 포스팅을 통해 간단하게 Source Connector를 등록해보고 동작하는 과정을 살펴보려고 한다.
우선, [LG CNS AM Inspire Camp 1기] MSA (6) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (2)
에서 포스팅한 내용처럼 Kafka Connector 설치 및 JDBC 커넥터까지 다운로드 된 상태라고 판단하고 진행해보자
💡 Kafka Source Connector 등록
Sample Code
// [POST] localhost:8083/connectors { "name": "my-source-connect", "config": { "connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector", "connection.url": "jdbc:mariadb://localhost:3307/mydb", "connection.user": "root", "connection.password": "개인 DB 비밀번호", "mode": "incrementing", "incrementing.column.name": "id", "table.whitelist": "users", "topic.prefix": "my_topic_", "tasks.max": "1" } }
Result View
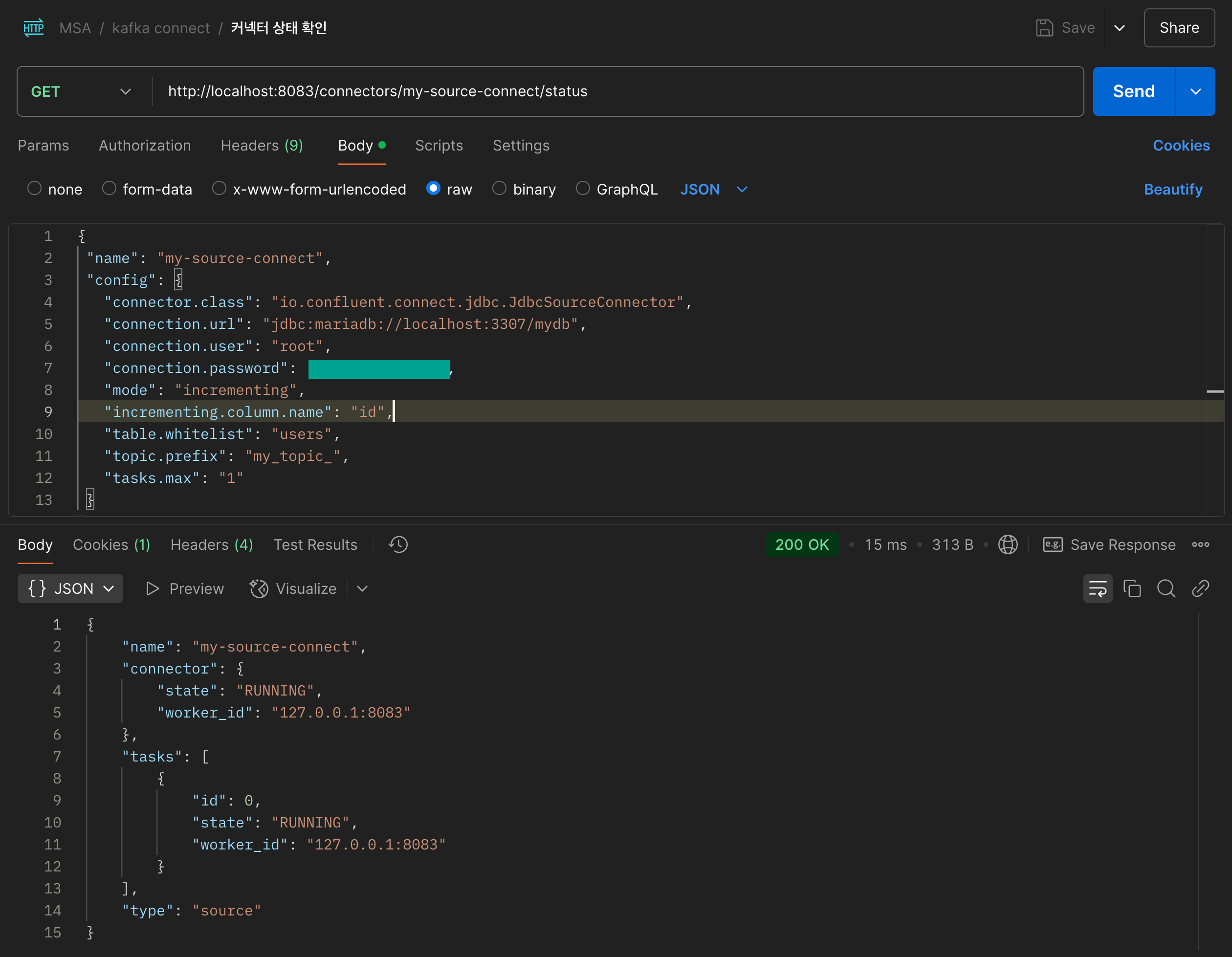
Sample Code로 제공된 JSON 데이터를 localhost:8083/connectors 로 POST 요청을 보내면 내가 지정한 Source Connector가 등록된다.
당연히 Kafka Connector가 켜져있는 상태여야 한다.
이후, 사진 처럼 등록한 커넥터의 상태를 확인했을 때, connector 와 tasks 모두 RUNNING 이 떠야 한다.
만약, Running이 뜨지 않았다면 DB가 제대로 동작하고 있는지, 아이디 비밀번호는 맞는지, 오타는 없었는지 등등.. 로그를 직접 확인하면서 에러를 잡아야한다.
이제 JSON으로 보낸 데이터를 한번 살펴보자
mode: "incrementing"
- 증가 방식으로 데이터 변경 감지
- 즉, ID 값이 증가하는 새 레코드를 감지
incrementing.column.name: "id"
- 증분 변경을 감지할 컬럼 이름
table.whitelist: "users"
- 모니터링할 테이블 이름
topic.prefix: "mytopic"
- 생성될 Kafka 토픽의 접두사
- 따라서, 실제 토픽은 "my_topic_users"가 된다.
tasks.max: "1"
- 최대 태스크 수 (병렬 처리 정도)
만약, 여기서 감지해야할 대상 토픽인 my_topic_users 가 없다면 자동으로 생성된다.
💡 Users 테이블에서 쿼리 날려보기

사진과 같이 user 테이블에서 쿼리를 날려보자
Result View
{ "schema": { "type": "struct", "fields": [ { "type": "int32", "optional": false, "field": "id" }, { "type": "string", "optional": true, "field": "user_id" }, { "type": "string", "optional": true, "field": "name" } ], "optional": false, "name": "users" }, "payload": { "id": 1, "user_id": "test_id1", "name": "TEST_USER_01" } }


쿼리를 요청하면 my_topic_users 토픽이 생성되고, 해당 토픽에는 위 사진과 같이 메세지가 들어온다.
당연히 이전에 Producer 코드를 작성하면서 살펴봤던 포맷과 동일하게 schema와 payload 부분으로 나뉘어서 메세지가 등록되는 모습을 볼 수 있다!
이제 개발자가 원한다면 이 메세지를 이용해서 다른 DB에 데이터를 동기화시키는 등의 작업을 추가할 수 있을 것이다.
OUTRO
이번 포스팅에서는 간단하게 Source Connector를 등록하고 사용하는 과정을 정리해봤다.
필자가 진행하는 실습 코드에서는 Source Connector를 사용하지 않았기 때문에 직접 DB에 쿼리를 날리고, 토픽에 메세지가 등록되는 과정을 살펴봤다.
이렇게 Source Connector와 Sink Connector를 함께 활용하면 다양한 시스템 간의 데이터 동기화를 효과적으로 구현할 수 있다.
특히 마이크로서비스 아키텍처에서 데이터 일관성 문제를 해결하는 강력한 방법이 될 수 있으니 알아두자 👊
