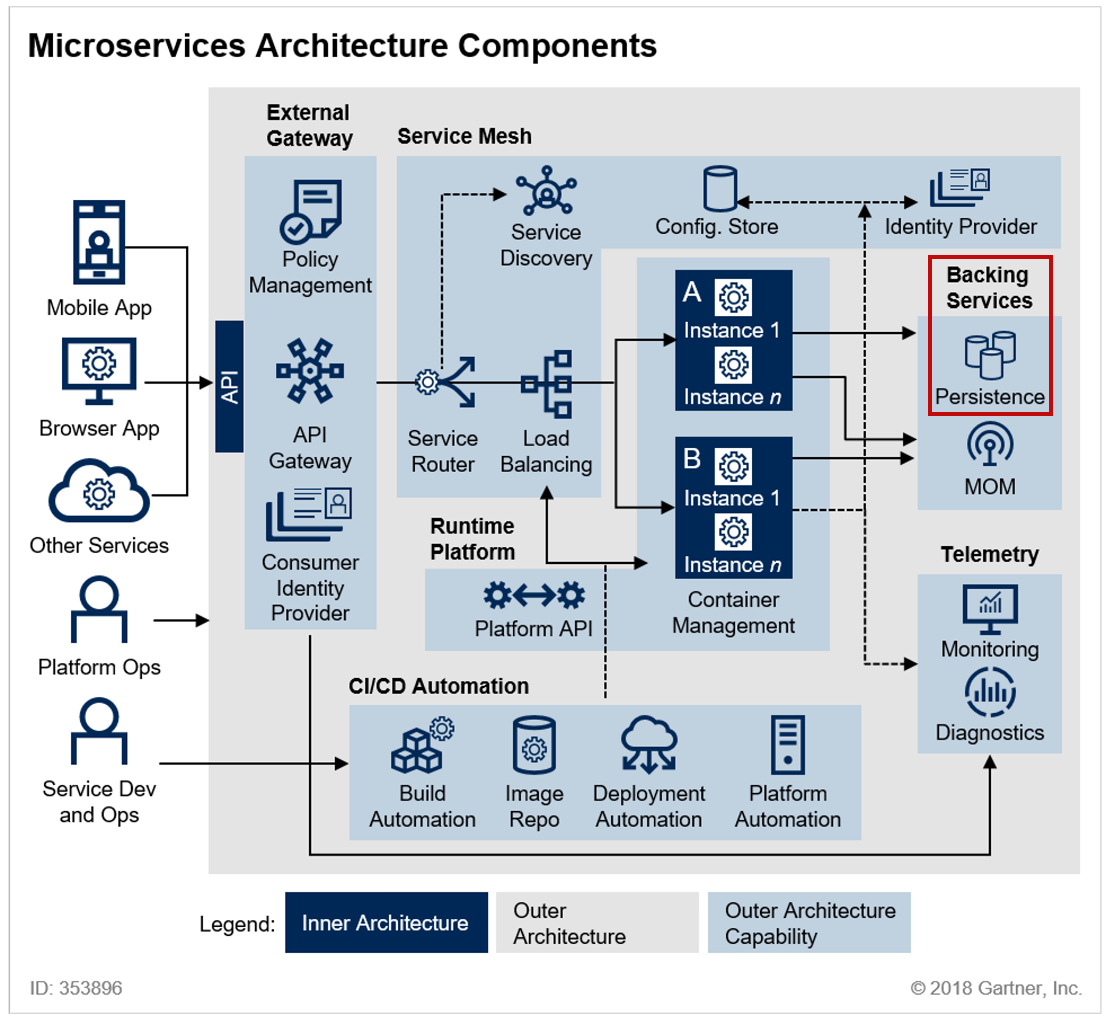
[LG CNS AM Inspire Camp 1기] MSA (6) - Kafka를 이용하여 MSA 데이터 일관성 문제 해결하기 (2)
LG CNS AM Inspire 1기
INTRO
이전 포스팅에서는 Catalog Service에 Kafka를 적용하는 과정을 살펴봤다.
현재 진행과정을 간단하게 리마인드해보면 Kafka 도커 컨테이너를 9092 포트에 매핑해서 띄워둔 상태이고, Kafka를 사용하기 위한 명령어들을 다운로드 받은 상태이다.
이번 포스팅에서는 Order Service에 Kafka가 어떻게 적용되고 있는지 코드를 살펴보고 Kafka Connect를 이용해서 DB에 데이터가 자동으로 저장되도록 해보자 👀
1. Kafka 사용 이유
우선 목표부터 설정하면 다음과 같다.
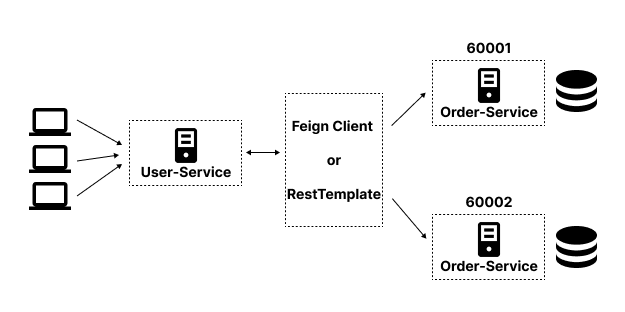
위 구조는 API 통신 포스트에서 사용했던 구조인데, 현재 구조는 각 서비스마다 각기 다른 DB를 갖고 있다.
따라서, 주문 내역을 조회할 때마다 각 DB에 저장된 데이터를 보여주기 때문에 조회할 때마다 결과가 달라지는 문제가 있었다.
이를 해결하기 위해 하나의 DB를 사용할 수 있지만, 단순히 하나의 DB를 사용한다면 병목현상이 생겨 성능 저하가 발생하기 때문에 중간에 메세지 브로커인 Kafka를 사용하기로 결정했다.
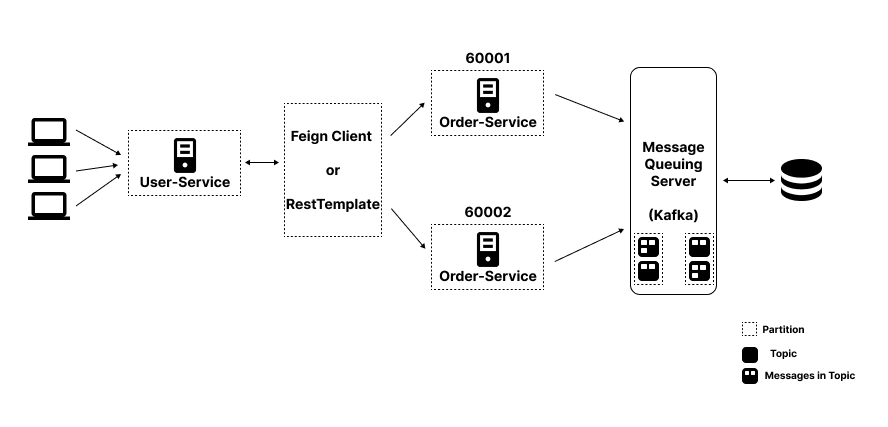
따라서, 현재 필자가 만들려는 구조는 위 사진과 같다.
중간에 메세지 브로커인 Kafka를 이용해서 각 서비스에서 들어오는 메세지들을 토픽 단위로 적절하게 묶어서 관리하고자 한다.
이후, orders 토픽에 들어있는 메세지들을 DB에 넣고 메세지가 들어올 때마다 중간에 위치한 Sink Connector가 하나의 DB와 동기화 작업을 수행하도록 할 예정이다.
2. Kafka 설정하기 - Order Service
이전 포스팅에서 Order Service는 사용자가 주문한 내역(메세지)를 토픽에 저장하는 Producer의 역할을 수행한다고 정리했다.
따라서, Order Service에서는 Catalog Service에서 적용한 Consumer 설정이 아닌 Producer 설정을 진행해보자
💡 Kafka 설정 추가
우선 코드를 살펴보면 다음과 같다.
Sample Code
@EnableKafka @Configuration public class KafkaProducerConfig { @Bean public ProducerFactory<String, String> producerFactory() { Map<String, Object> properties = new HashMap<>(); properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return new DefaultKafkaProducerFactory<>(properties); } @Bean public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
Catalog-Service의 ConsumerConfig와 거의 유사한 모습을 보여준다.
다만, 설정 내용중에서 KEY_SERIALIZER_CLASS_CONFIG, VALUE_SERIALIZER_CLASS_CONFIG 는 StringDeserializer.class 가 아니라 StringSerializer.class 를 사용하고 있다.
즉, 전송가능한 바이트 배열로 바꾸는 데이터가 String임을 의미한다.
간단히 정리하면 다음과 같다.
직렬화 / 역직렬화
Producer: String → Byte 배열 (직렬화)
카프카 토픽에 Byte 배열 저장
Consumer: Byte 배열 → String (역직렬화)
또한, 빈으로 등록된 객체가 ConsumerFactory 가 아니라 ProducerFactory 임을 기억하자
💡 Kafka Producer - catalog 토픽
Order Service는 Producer 역할을 수행한다고 언급한 바 있다.
그렇다면 주문 내역 메세지를 단순히 하나의 토픽에만 발행하면 될까?
Kafka의 구조상 파티션 하위에 여러개의 토픽을 가질 수 있고, 여러개의 토픽에 메세지를 넣을 수 있다.
즉, 용도가 다르다면 다른 토픽을 사용하는 것이 유지보수에 더 좋을 것이다.
따라서, 주문내역을 DB에 저장할 orders 토픽과 이전 포스팅에서 살펴봤던 example-catalog-topic 2개에 주문 내역 메세지를 넣어주려고 한다.
여기서는 example-catalog-topic 에 메세지를 넣어주는 Producer 코드를 다뤄보려고 한다.
우선 코드를 살펴보자
Sample Code
@Service @Slf4j public class KafkaProducer { private KafkaTemplate<String, String> kafkaTemplate; @Autowired public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public OrderDto send(String topic, OrderDto orderDto) { ObjectMapper mapper = new ObjectMapper(); String jsonInString = ""; try { jsonInString = mapper.writeValueAsString(orderDto); } catch(JsonProcessingException ex) { ex.printStackTrace(); } kafkaTemplate.send(topic, jsonInString); log.info("Kafka Producer sent data from the Order microservice: " + orderDto); return orderDto; } }
KafkaProducer는 단순하게 토픽에 데이터를 넣는 역할을 수행한다.
보다시피 Producer는 KafkaTemplate 를 의존성 주입받아 구현 한다.
간단하게 send 메서드를 살펴보면, topic 이름과 topic에 저장할 데이터인 OrderDto를 전달받는다.
과정에서 보다시피 직렬화를 String으로 진행하기 때문에 OrderDto를 String으로 변환한 이후, 이전에 주입받은 KafkaTemplate 을 사용하여 메세지를 발행한다.
send 메서드에서 OrderDto를 반환하고 있는데, void를 사용해도 로직 자체는 무관하다!
💡 Kafka Producer - orders 토픽
방금 설명한 것과 같이 orders 토픽에도 orderDto 메세지를 넣어줘야 한다.
다시말하지만 orders 토픽에 저장된 메세지는 DB에 저장하기 위해 사용되는 데이터이다.
우선 Producer 코드를 살펴보자
Sample Code
@Service @Slf4j public class OrderProducer { private KafkaTemplate<String, String> kafkaTemplate; List<Field> fields = Arrays.asList( new Field("string", true, "order_id"), new Field("string", true, "user_id"), new Field("string", true, "product_id"), new Field("int32", true, "qty"), new Field("int32", true, "unit_price"), new Field("int32", true, "total_price")); Schema schema = Schema.builder() .type("struct") .fields(fields) .optional(false) .name("orders") .build(); @Autowired public OrderProducer(KafkaTemplate<String, String> kafkaTemplate) { this.kafkaTemplate = kafkaTemplate; } public OrderDto send(String topic, OrderDto orderDto) { Payload payload = Payload.builder() .order_id(orderDto.getOrderId()) .user_id(orderDto.getUserId()) .product_id(orderDto.getProductId()) .qty(orderDto.getQty()) .unit_price(orderDto.getUnitPrice()) .total_price(orderDto.getTotalPrice()) .build(); KafkaOrderDto kafkaOrderDto = new KafkaOrderDto(schema, payload); ObjectMapper mapper = new ObjectMapper(); String jsonInString = ""; try { jsonInString = mapper.writeValueAsString(kafkaOrderDto); } catch(JsonProcessingException ex) { ex.printStackTrace(); } kafkaTemplate.send(topic, jsonInString); log.info("Order Producer sent data from the Order microservice: " + kafkaOrderDto); return orderDto; } }
@Data @AllArgsConstructor public class KafkaOrderDto implements Serializable { private Schema schema; private Payload payload; }
@Data @Builder public class Schema { private String type; private List<Field> fields; private boolean optional; private String name; }
@Data @Builder public class Payload { private String order_id; private String user_id; private String product_id; private int qty; private int unit_price; private int total_price; }
마찬가지로 KafkaTemplate 을 의존성 주입받아 사용하고 있다.
여기서 한가지 차이점은 별도의 send 메서드에서 kafkaOrderDto 를 별도로 생성한 이후, 이를 String으로 만들고 있다.
그렇다면 왜 KafkaOrderDto 를 중간에 만들어주는걸까?
💡 Kafka Schema와 Payload 구조
예시 코드에서 볼 수 있듯이, orders 토픽에 메시지를 보낼 때 schema와 payload를 포함한 구조를 사용하고 있다.
이는 Kafka Connect와 Kafka Connect Sink Connector가 데이터를 처리할 때 주로 사용하는 정해진 형식이다.
이렇게 Kafka Connect가 정해진 형식을 사용하는 이유는 스키마를 통해 데이터 형식의 유효성을 검증할 수 있기 때문이다.
또한, Kafka Connect가 자동으로 데이터베이스 테이블 구조에 매핑할 수 있도록 하기 위해서 schema와 payload를 사용한다.
여기서 PayLoad와 Schema를 살펴보면 다음과 같다.
Payload
- 실제 데이터 값을 포함하며, 데이터베이스 테이블의 컬럼명과 정확히 일치하는 필드명을 사용해야 한다.
- 예시 코드에서 Payload 클래스의 필드들(order_id, user_id, product_id 등)이 실제 DB 테이블의 컬럼명과 일치한다.
Schema
- Kafka Connect가 데이터 타입을 이해하고 데이터베이스 스키마와 매핑하는 데 사용된다.
- type: 주로 "struct"를 사용하여 구조화된 데이터임을 나타낸다.
- fields: 각 필드의 데이터 타입과의 관계를 정의한다. 필드를 구성하는 리스트는 DB 테이블의 컬럼과 일치시킨다.
- name: 주로 대상 테이블명과 일치시킨다.
조금 더 나중에 살펴보겠지만, Kafka Connector에서 Sink를 추가할 때 JSON 형태로 POST 요청을 보낸다.
그때 사용하는 JSON의 프로퍼티 중에서 auto.create 와 auto.evolve 에서 정의된 스키마를 활용할 수 있다.
💡 Kafka Producer 사용
Kafka Producer는 로직 처리 과정에서 호출하여 사용하면 된다.
우리는 사용자가 주문을 했을 때 Kafka 토픽에 메세지를 저장하면 되기 때문에 createOrder 로직 내부에서 호출하면 된다.
Sample Code
@PostMapping("/{userId}/orders") public ResponseEntity<ResponseOrder> createOrder(@PathVariable("userId") String userId, @RequestBody RequestOrder orderDetails) { log.info("Before add orders data"); ModelMapper mapper = new ModelMapper(); mapper.getConfiguration().setMatchingStrategy(MatchingStrategies.STRICT); OrderDto orderDto = mapper.map(orderDetails, OrderDto.class); orderDto.setUserId(userId); orderDto.setOrderId(UUID.randomUUID().toString()); orderDto.setTotalPrice(orderDetails.getQty() * orderDetails.getUnitPrice()); ResponseOrder responseOrder = mapper.map(orderDto, ResponseOrder.class); /* send this order to the kafka */ kafkaProducer.send("example-catalog-topic", orderDto); orderProducer.send("orders", orderDto); log.info("After added orders data"); return ResponseEntity.status(HttpStatus.CREATED).body(responseOrder); }
이제 example-catalog-topic 에 저장된 메세지는 catalog-service에서 리스닝하고 있는 메서드가 동작하여 JPA기반으로 DB를 업데이트할 것이다.
반면, orders 토픽에 들어있는 메세지는 아직 활용되지 않고 있다.
이제부터 orders 토픽에 있는 메세지를 기반으로 DB를 자동으로 업데이트하도록 Kafka Connector를 사용해보자
3. Kafka Connector 사용하기
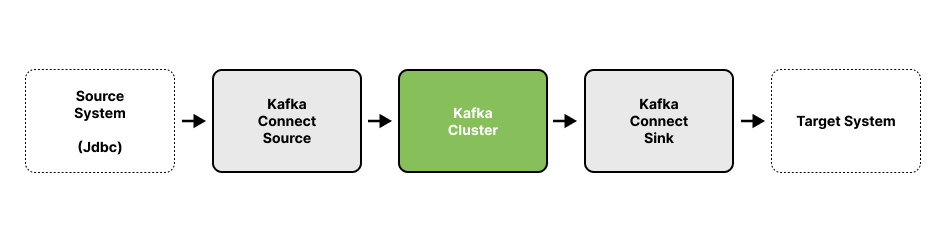
이전 포스팅에서 살펴봤던 이미지를 다시한번 확인해보자
여기서 우리는 Kafka Cluster를 기준으로 데이터를 이동시키기 위해서는 Kafka Connect를 사용한다고 했다.
Kafka Connect를 사용하기 위해 우리는 confluent.io에서 현재 Kafka 버전에 맞는 Connector를 설치해야 한다.
호환 버전 사이트에 접근해서 자신이 사용하는 Kafka 버전과 호환되는 Connnector를 설치해야 한다.
필자는 kafka:latest 를 사용하기 때문에 7.9 버전을 다운로드해서 사용했다
💡 Kafka Connector 설치 (1)
사이트에 접근해서 다운로드해도 상관없지만, curl 명령어를 사용해서 간단하게 다운로드 해보자
◉ 명령어 - Kafka Connector 명령어 다운
curl -O http://packages.confluent.io/archive/7.9/confluent-community-7.9.0.tar.gz
◉ 명령어 - 압축 해제
tar xvf confluent-community-7.9.0.tar.gz
압축해제를 진행한 이후, 디렉토리를 확인해보면 이전에 Kafka에서 다운로드 받은 것처럼 쉘 스크립트가 저장된 모습을 확인할 수 있다.
💡 Kafka Connector 설치 (2)
이후, Kafka Connector Sink에서 사용할 JDBC Connector를 다운로드 받아야 한다.
여러가지 커넥터가 있겠지만, 필자는 DB에 데이터를 저장하기 위한 목적으로 사용하기 때문에 JDBC Connector를 설치한다.
JDBC Connector 설치 사이트에서 다운로드 받으면 된다.
필자는 Self-Hosted로 다운로드 받았다.
💡 Kafka Connector 연결 (1)
이전에 압축해제하면서 설치했던 confluent-7.9.0 디렉토리에서 다음 파일을 수정하자
수정 해야하는 파일
confluent-7.9.0/etc/kafka/connect-distributed.properties
해당 파일을 열고 맨 마지막으로 스크롤을 내리면 path를 설정하는 부분이 있다.
여기서 path를 우리가 방금 설치한 JDBC Connector/lib 경로로 수정하자

💡 Kafka Connector 연결 (2)
다음으로 필자는 orders 토픽에 저장된 데이터를 MariaDB에 저장할 예정이기 때문에 MariaDB 드라이버를 /share/java/kafka/경로에 저장해야 한다.
maven으로 프로젝트를 한번이라도 빌드했다면, m2 라는 디렉토리 하위에 사용한 DB 드라이버가 존재한다.
맥 OS를 사용한다면 open ~/m2 명령어를 입력해서 해당 디렉토리를 열고, ~/.m2/repository/org/mariadb/jdbc/mariadb-java-client/2.7.2/mariadb-java-client-2.7.2.jar 경로에 해당하는 드라이버를 복사하자
다음으로 커넥터 명령어가 있는 디렉토리에서 confluent-7.9.0/share/java/kafka 경로에 이전에 복사한 드라이버를 붙여넣기 해주면 된다.
💡 Kafka Connector 실행
이제 confluent-7.9.0/ 으로 이동하고 다음 명령어를 입력하자
◉ 커맨드 - Kafka Connector 실행
./bin/connect-distributed ./etc/kafka/connect-distributed.properties
두 명령어를 동시에 실행시키기 때문에 /confluent-7.9.0 에서 명령어를 입력해야 한다.

이후, 토픽 리스트를 확인해보면 connect 관련 토픽이 3개 생긴 모습을 볼 수 있다.
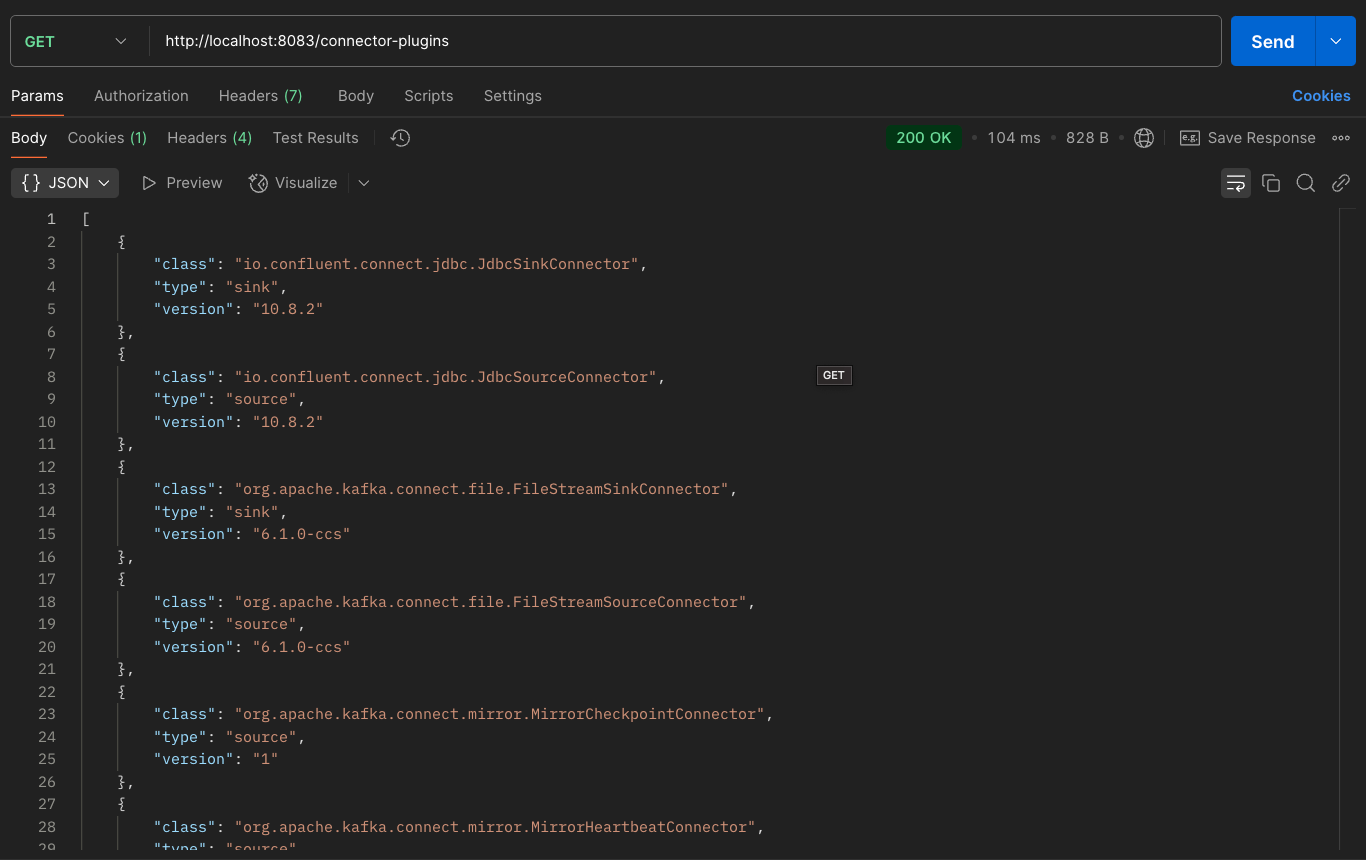
위 사진과 같이 8083포트의 /connector-plugins 엔드포인트로 get 요청을 날리면 현재 등록된 커넥터들을 확인할 수 있다.
여기서 8083은 Kafka Connector가 자체적으로 제공해주는 포트이다.
화면에서 확인할 수 있다시피, 방금 등록한 JdbcSinkConnector와 JdbcSourceConnector가 제대로 등록된 모습을 볼 수 있다.
💡 Kafka Connector 등록
이제 위 커넥터를 이용해서 우리가 사용할 DB 정보를 세팅하여 커넥터를 등록해보자
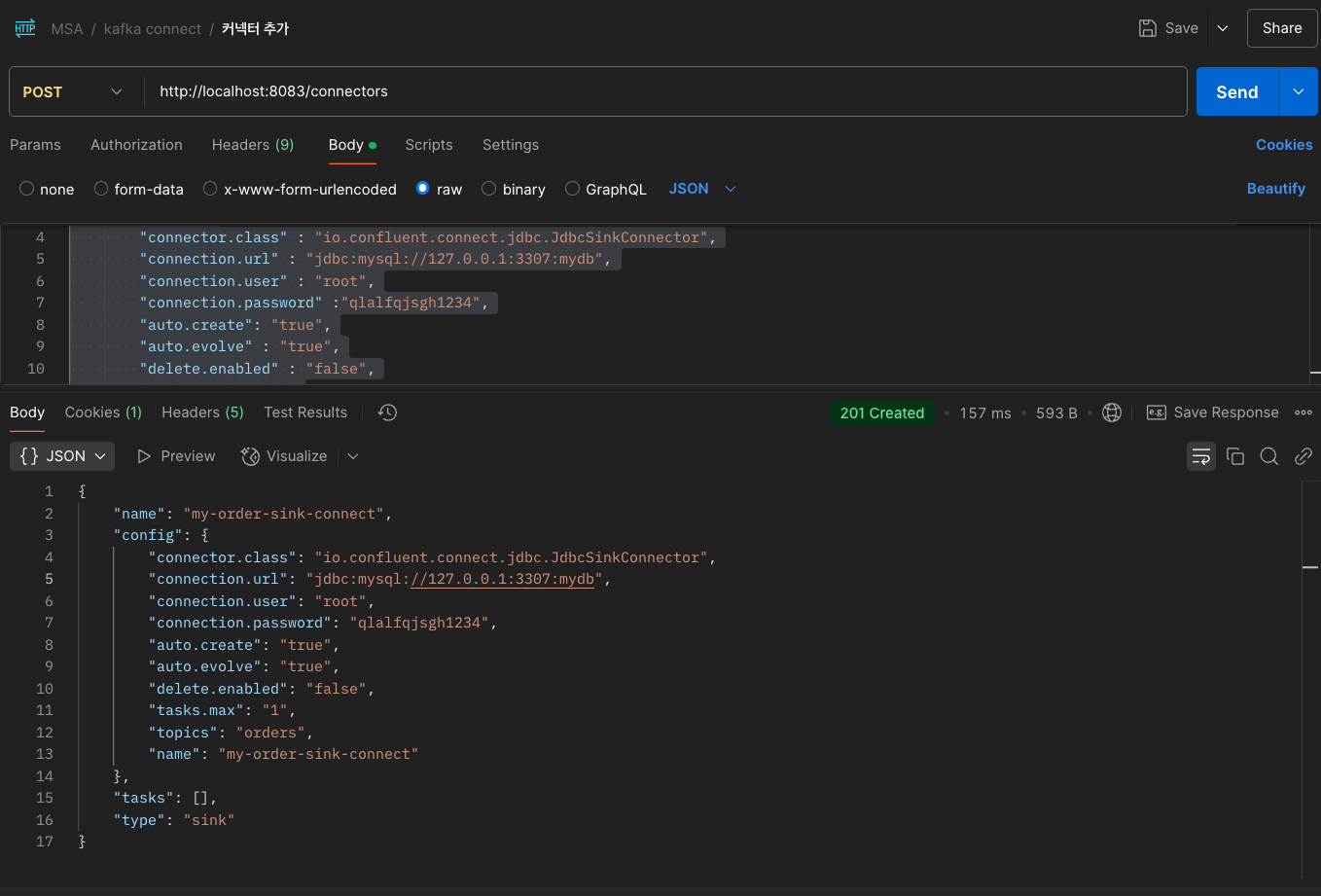
Sample Code
{ "name" : "my-order-sink-connect", "config" : { "connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector", "connection.url" : "jdbc:mysql://127.0.0.1:3307:mydb", "connection.user" : "root", "connection.password" :"개인 DB 비밀번호", "auto.create": "true", "auto.evolve" : "true", "delete.enabled" : "false", "tasks.max" : "1", "topics" : "orders" } }
사진과 같이 8083 포트의 /connectors 엔드포인트로 위 JSON 데이터를 POST 날려주면 우리가 사용할 Sink Connector가 등록된다.
JSON 포맷에서 config쪽을 살펴보면 connector 관련 설정을 추가해주고 있다.
여기서 눈여겨봐야할 것은 topics 부분인데, 우리가 사용할 orders 토픽에서 메세지를 Sink 하겠다는 의미이다.
참고로 생성한 Connector를 삭제하길 원한다면 localhost:8083/connectors/my-order-sink-connect 엔드포인트에 DELETE 메서드로 요청을 보내면 된다.
4. Kafka 실습
이제 Connector 연결까지 완료했으니 실제로 서비스 인스턴스를 여러개 띄운 상태에서 실습을 진행해보자
💡 Order Service 실행
우선 실습을 위해 Order Service 인스턴스를 2개 띄우자
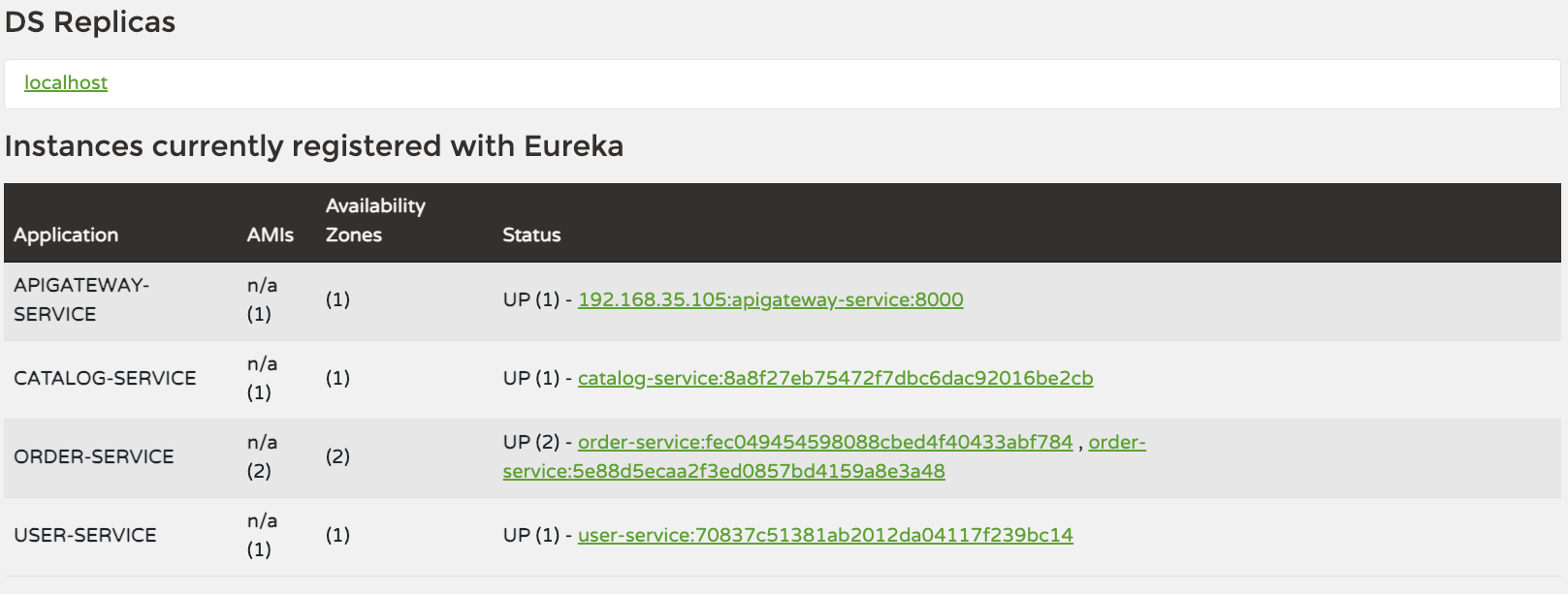
Gateway 설정에서 라운드 로빈 방식으로 라우팅이 진행되도록 설정했기 때문에, 각 요청은 서비스 인스턴스를 번갈아가면서 사용할 것이다.
💡 주문 요청
주문 요청
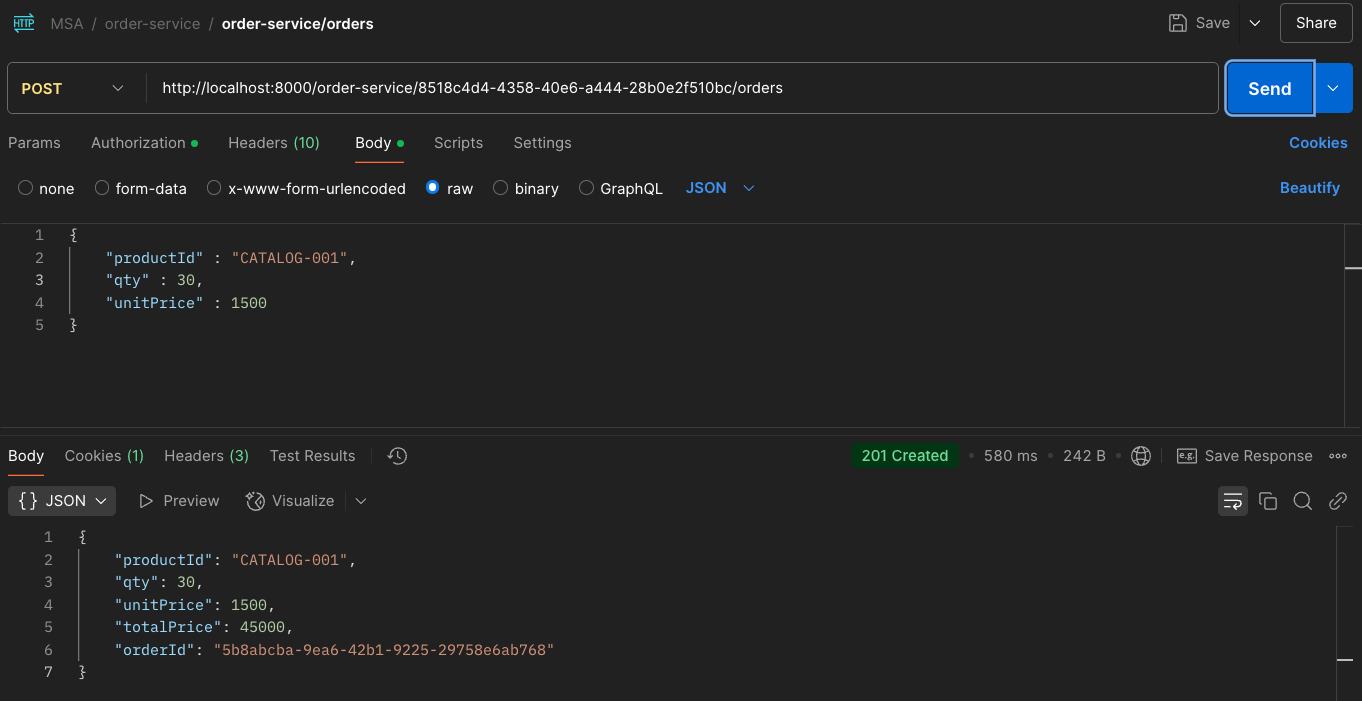
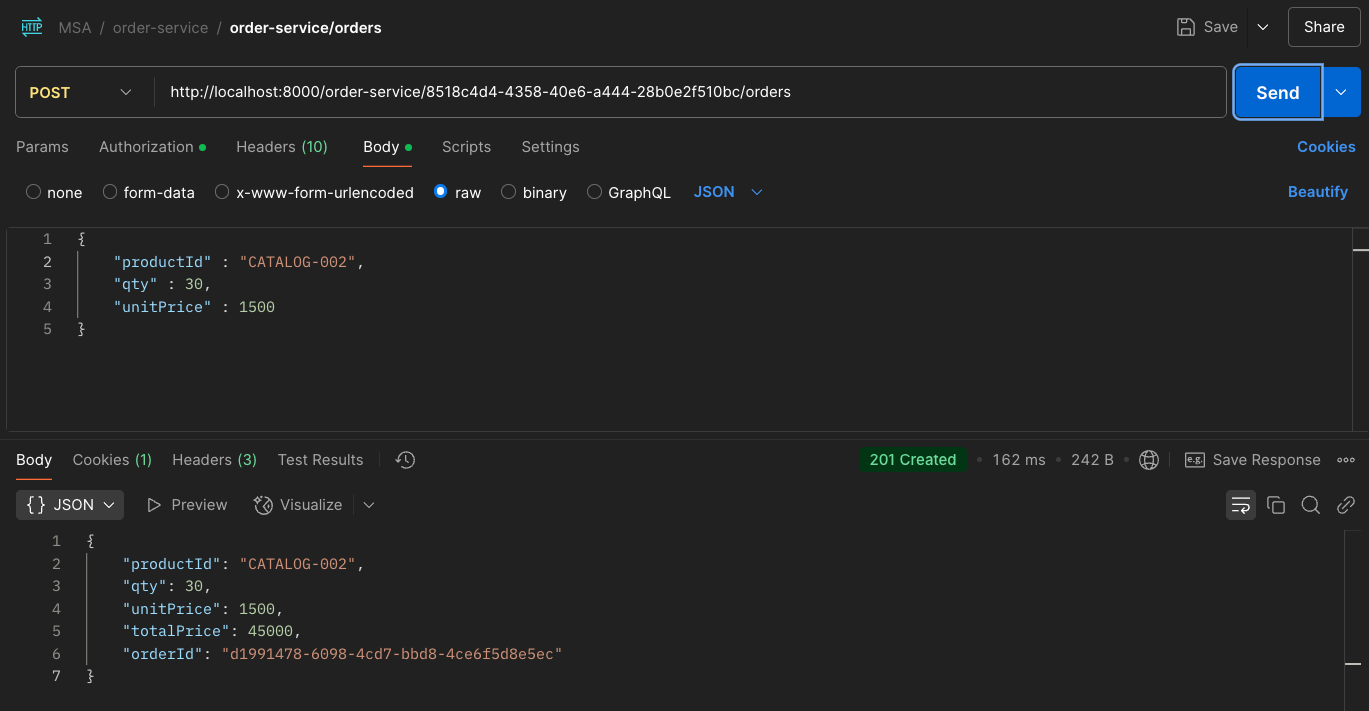
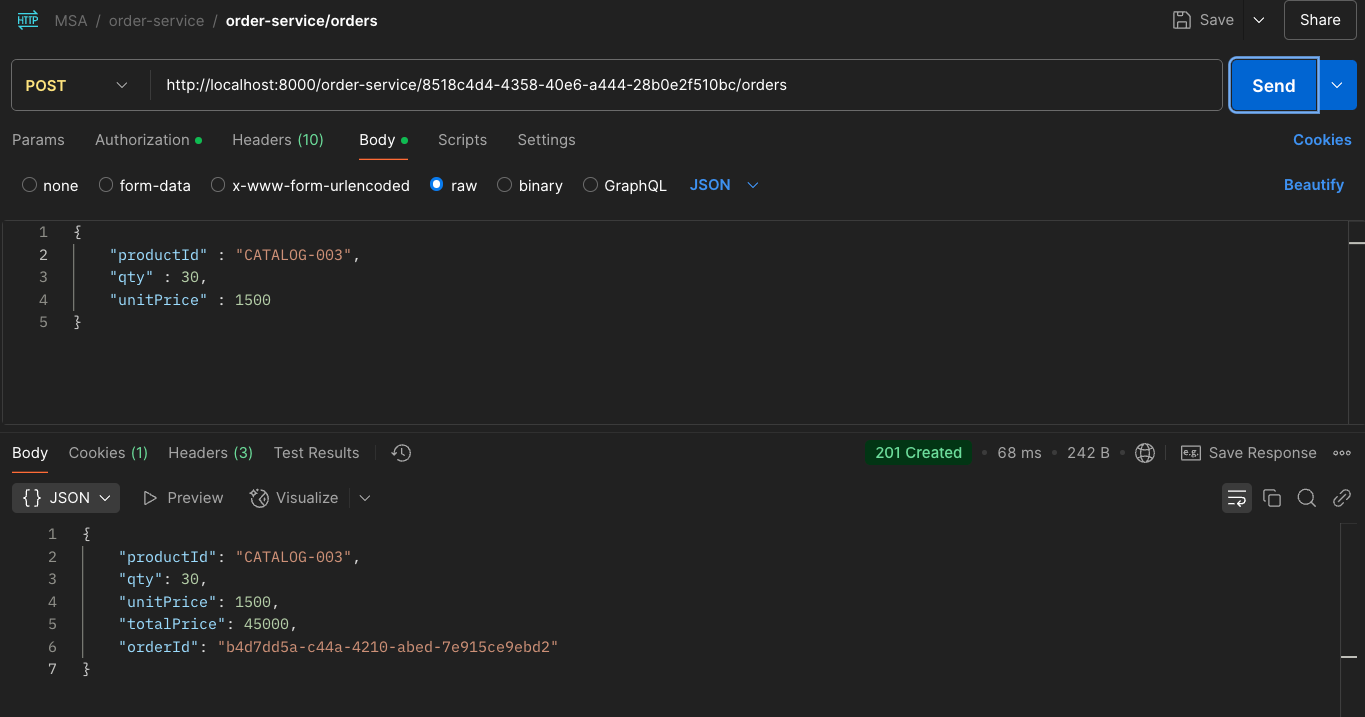
위 사진은 order-service에 catalog-001, 002, 003 주문을 3번 넣는 과정이다.
💡 orders 토픽 확인

사진이 잘 보일지 모르겠지만, 각각 요청한 catalog-001, 002, 003이 orders 토픽에 제대로 저장된 모습을 볼 수 있다.
(위에있는 메세지는 테스트하면서 생긴 더미 데이터다 😅)
💡 DB 확인

사진과 같이 주문이 자동으로 들어온 모습을 볼 수 있다!
💡 주의사항
필자는 해당 실습에서 Sink Connector만 등록해서 단방향 처리 (Kafka Topic -> DB)만 구현했다.
만약, JDBC Source Connector를 사용한다면 DB에서 변경사항이 감지되면 Kafka Topic으로 가져오는 기능도 구현할 수 있을 것이다.
하지만, 양방향을 구현하게 될 경우에는 무한 루프를 조심해야한다는 것을 기억하자
이 부분은 다음에 시간되면 별도의 포스팅으로 작성하도록 하겠다!
OUTRO
이번 포스팅에서는 Kafka Connector를 세팅하는 방법과 Producer 코드를 어떻게 작성해야하는지까지 살펴봤다.
실제로 필자가 테스트하는 과정에서는 Connector 버전이 맞지 않아서 마지막 DB에 데이터가 저장되지 않는 문제가 있었다.
이 부분에서 Kafka와 Connector 버전의 호환성이 중요하다는 것을 절감했다..😅
그래서 다시 처음부터 Connector를 설정했는데 여러번 하다보니까 막상 어려운 부분은 하나도 없었다.
한 번 익숙해지면 설정 과정이 꽤 직관적이라는 걸 알 수 있었다.
2편의 포스팅을 통해서 Kafka Consumer, Producer를 구성하는 방법과 이를 통해 데이터 일관성을 유지하는 방법에 대해서 기억하면 좋겠다!
특히 마이크로서비스 환경에서 각 서비스의 독립성을 유지하면서도 데이터 정합성을 확보하는 패턴으로 큰 도움이 될 것이다 👊
