
🏷️ 4줄 요약
- Logistic Regression은 이진 분류 문제를 해결하는 가장 간단한 분류 모델.
- 예측값을 0 또는 1의 범주로 나누어 예측하는데, 이는 확률로 계산.
- 선형 회귀와 달리, 로지스틱 회귀는 시그모이드
sigmoid함수를 통해 출력값이 0과 1 사이의 값으로 제한. - 독립변수 입력 → 선형회귀
Linear regression로 예측값 계산 → 예측값을 시그모이드sigmoid함수를 통해 0과 1 사이의 확률값으로 변환 → 클래스 1 또는 0으로 분류!
📌 Classification 모델 VS Regression 모델
- Classification: 범주형 값을 예측하는 문제.
- 예를 들어, 클래스 A 또는 클래스 B를 예측하는 이진 분류 문제를 처리. 종속변수(출력)는 범주(class)로 나뉜다.
- Regression: 연속형 값을 예측하는 문제.
- 예를 들어, 주택 가격이나 온도와 같은 실수값을 예측. 종속변수(출력)는 연속적인 값입니다.
📌 Class(클래스)의 정의
- Class(클래스)는 분류 문제에서 예측하려는 결과의 종류를 의미.
- 예를 들어, 스팸 메일 분류에서 "스팸"과 "스팸 아님"이 각각 하나의 class.
- 이진 분류에서는 두 개의 클래스가 있으며, 다중 분류에서는 여러 개의 클래스가 존재할 수 있음.
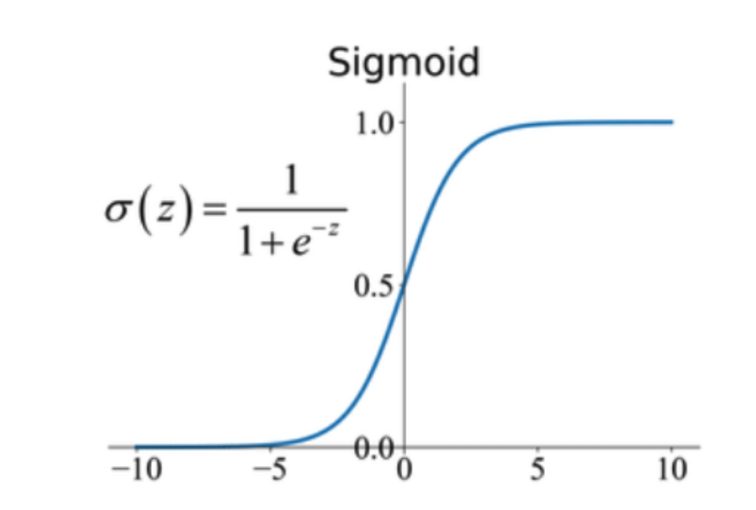
📌 Sigmoid(시그모이드) 함수?
- 정의: 시그모이드 함수는 S자 모양의 함수로, 실수 값을 0과 1 사이의 확률값으로 변환.
- 목적: 로지스틱 회귀에서 예측값을 확률값으로 표현하기 위해 사용.
- 역할: 선형 회귀에서 계산된 값을 시그모이드 함수에 통과시켜, 0과 1 사이의 확률값으로 변환한 후, 이를 기반으로 분류.
- 수식:
- 여기서 는 선형 회귀 식.
📌 라벨값(Label value)에 따른 로스(Loss)
라벨은 정답을 의미. 이 값은 문제가 무엇을 예측하느냐에 따라 다르게 설정.- 예시) 스팸 메일 분류: 1 = 스팸, 0 = 스팸 아님.
- 예시) 고양이 vs 개 분류: 1 = 고양이, 0 = 개 (또는 그 반대).
- 라벨값이 1이라는 것은 실제 정답이 해당 클래스임을 의미.
- 예를 들어, 스팸 분류 문제에서 라벨이 1이면, 이 데이터는 스팸을 의미.
- 예측값 . 즉, y = 1에 가까울수록
Loss는 작아진다. - 예측값 . 즉, y = 0에 가까울수록
Loss는 커진다.

연장 대신 키보드 뚱땅거리며 분석하는 '데이터분석 공장 529'