What is zero shot
- 관찰되지 않은 데이터에 대한 작업을 수행할수 있도록 학습
- 패션 코디네이션에서 제로샷 학습
- 최근 심층학습 기반(Deep learning) 의 복합 모달 챗봇 기술은 상품 추천을 위한 대화형 전자 상거래 분야에 적극적으로 활용 (Deep learning 은 대량의 고품질 데이터가 필요)
- 빈번하게 신상품이 출시되는 패션 리테일 분야에서, 사전에 패션 아이템에 대한 레이블링 작업은 비용이 많이 들고, 소요되는 시간 떄문에 제품을 판매해야하는 시기를 놓칠 수도 있다.
- 소량의 레이블 있는 데이터로 빠르게 학습하는 기술이 중요, 더 나아가 데이터 없이도 상품을 추천할 수 있는 제로샷 학습이 필요.
→ TPO 에 맞는 제로샷 패션 코디네이션을 추천 해주는지



- 보는 사람에 따라 달라지는 옷의 색깔이 있다. 우리는 그럼 이렇게 다른 두사람의 서치방법으로 같은 ‘이 제품’을 추천하게 할 수 있는가? 그렇게 할 수 있도록 논리 설계 할 수 있는가?

제로샷 학습
Zero-shot learning (ZSL)
모델이 학습 과정에서 본 적 없는 새로운 클래스를 인식할 수 있도록 하는 학습 방법입니다. 이는 모델이 클래스 간의 관계나 속성을 통해 일반화하는 능력을 활용
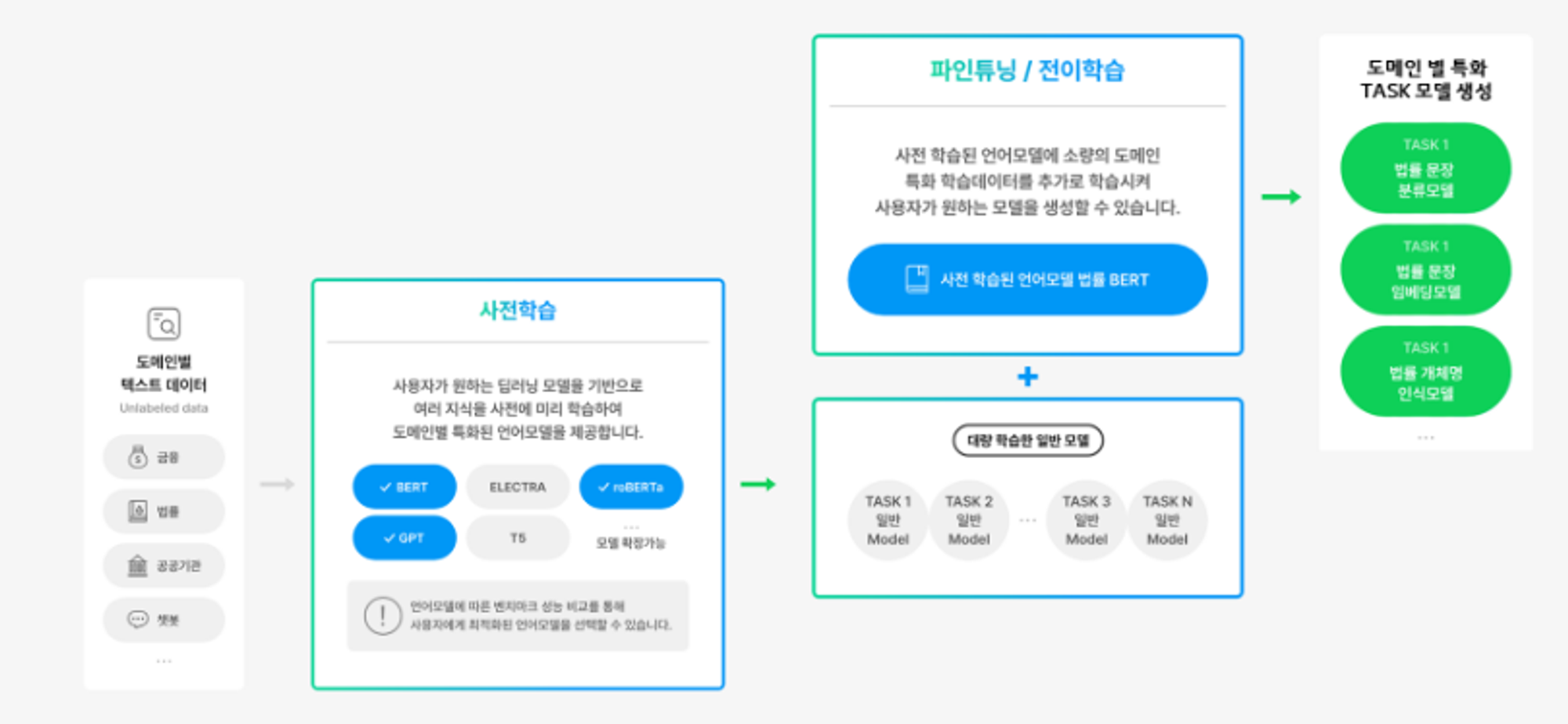
- 사전학습 단계에서는 모델이 대규모 데이터셋을 사용하여 광범위한 지식을 학습 이 과정은 모델에게 일반적인 패턴, 구조, 언어적 특성 등을 이해하게 하는 기반을 마련한다. LLM 모델의 경우, 위 그림처럼 Large Text Corpus(대용량 텍스트 데이터)를 기반으로 다양한 Task에 대하여 사전학습을 수행하는 것 (사전학습이 잘 된 모델은 ZSL에서 더 좋은 성능을 보일 가능성이 높다.)
- 파인튜닝 단계에서는 사전학습된 모델을 좀 더 특정 태스크나 적은 양의 데이터에 적합하도록 조정한다. 예를 들어, 금융 도메인 특화 모델, 법률 도메인 특화 모델과 같은 특정 도메인에 초점을 둔 모델이라면 해당 데이터로 모델 파인튜닝을 수행해주면 성능이 향상되게 된다. (제로샷 같은 경우, 전통적인 파인튜닝보다는 인퍼런스 단계에서 모델이 어떻게 새로운 클래스를 처리할 수 있는지에 더 중점을 둔다.)
- 인퍼런스 단계에서는 학습된 모델을 새로운 데이터에 적용하여 예측을 수행한다. (인식, 예측 등의 테스크를 수행하는 능력이 이 단계에서 평가된다. )
ZSL vs OSL vs FSL
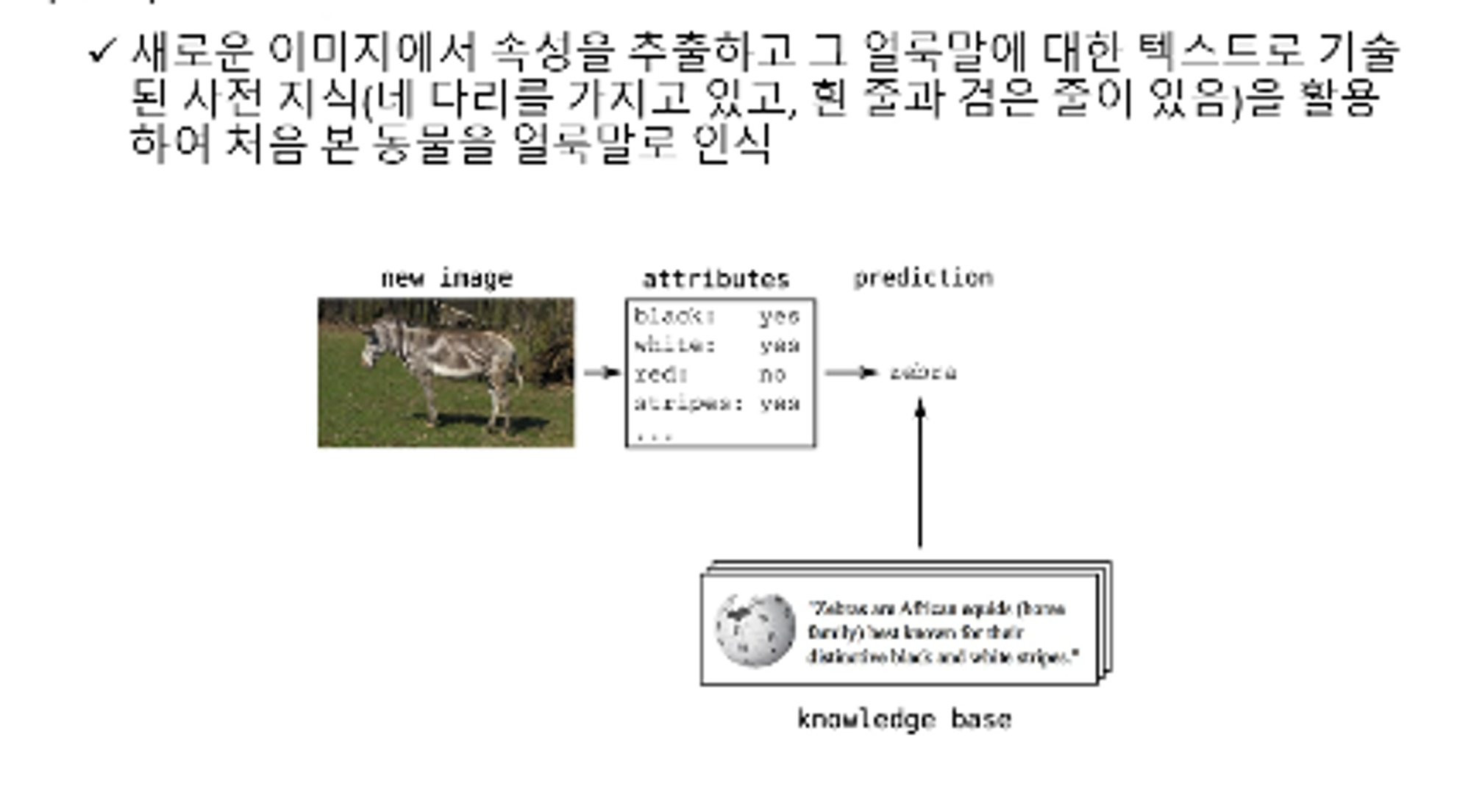
- ZSL: 모델이 사전에 정의된 속성을 통해 새로운 객체를 인식하는 경우, 예를 들어, '유모차'를 '바퀴가 네 개 있고 아기를 태울 수 있는' 속성을 통해 인식
- OSL: 특정 동물의 한 장의 사진을 학습하여, 다른 사진 속 같은 동물을 인식한다.
- FSL: 새 종류를 몇 장의 사진만 보고 분류하는 경우입니다.
학습 방법:
- ZSL에서는 모델이 이미지 속성과 클래스 간의 관계를 학습하여, 본 적 없는 클래스의 이미지를 인식할 수 있게 학습한다.
- OSL과 FSL에서는 유사도 측정, 메타 학습, 데이터 증강 등을 활용해 제한된 예시로부터 클래스를 학습
데이터 셋 구성 예시
Zero-Shot Learning: 학습 데이터셋은 다양한 주제의 텍스트를 포함하며, 모델은 이를 통해 일반화된 언어 이해를 학습한다.
텍스트의 주제나 감정 등을 이해하고, 본 적 없는 새로운 태스크에 이를 적용할 수 있어야 한다.
ex) 주제에 대한 기사나 블로그 포스트가 사용
⚡ CV와 NLP는 다루는 데이터의 형태(이미지 vs. 텍스트)와 관련 태스크에서 차이를 보이고 있다. NLP는 프롬프팅이 자주 사용되며, 이는 사전 학습된 언어 모델을 활용해 새로운 태스크에 적응하는 방법이다. CV에서는 이미지의 속성이나 유사도를 기반으로 학습하는 경우가 많다.

GNN과 관련한 이해
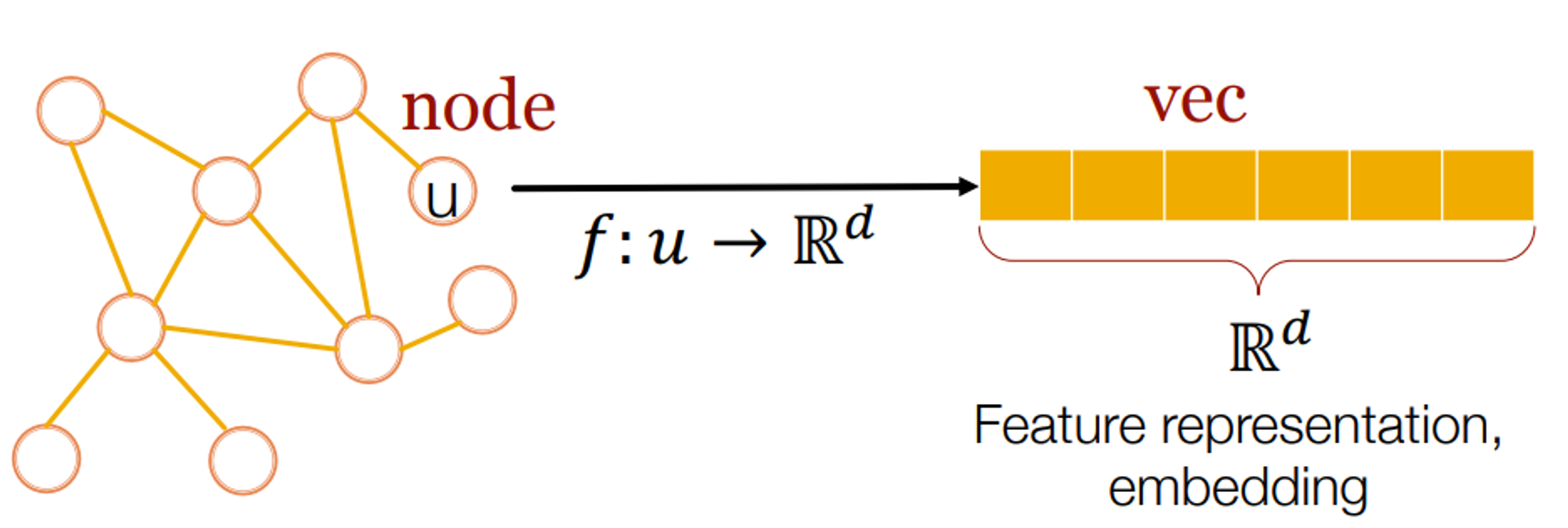
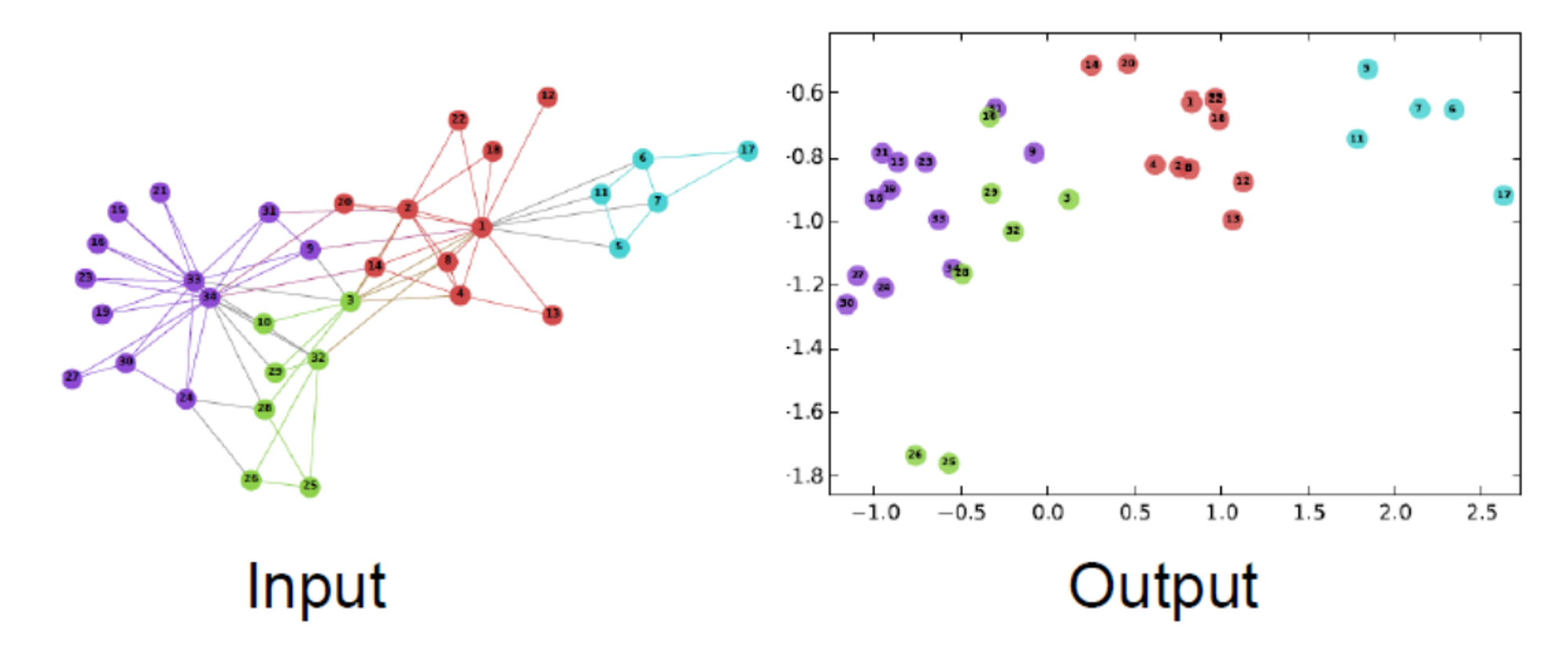
Node2Vec: Shallow embedding for node
Abstract
네트워크의 node와 edge에 대해서 prediction task를 수행하는 것은 feature engineering 측면에서 많은 노력이 소요된다. 최근의 연구들에서는 reprsentation learning 측면에서 feature 자체를 학습하여 이 측면에서 많은 혁신들이 있었으나, network에서 파악되는 connectivity pattern에 대해서는 제대로 학습하지 못한다는 한계를 가지고 있다. 따라서, 이를 해결하기 위해서 network의 이러한 feature를 학습할 수 있는 프레임워크인 node2vec을 제시하였다. node2vec에서는 network의 node들의 관계(neighborhood)를 우도(likelihood)를 최대화할 수 있는 low-dimensional(저차원) 피쳐 공간을 학습시켰다. 실제로 기존의 존재하는 데이터들을 대상으로 수행을 해봤는데 괜찮은 결과가 나왔다.
Recap : word2vec
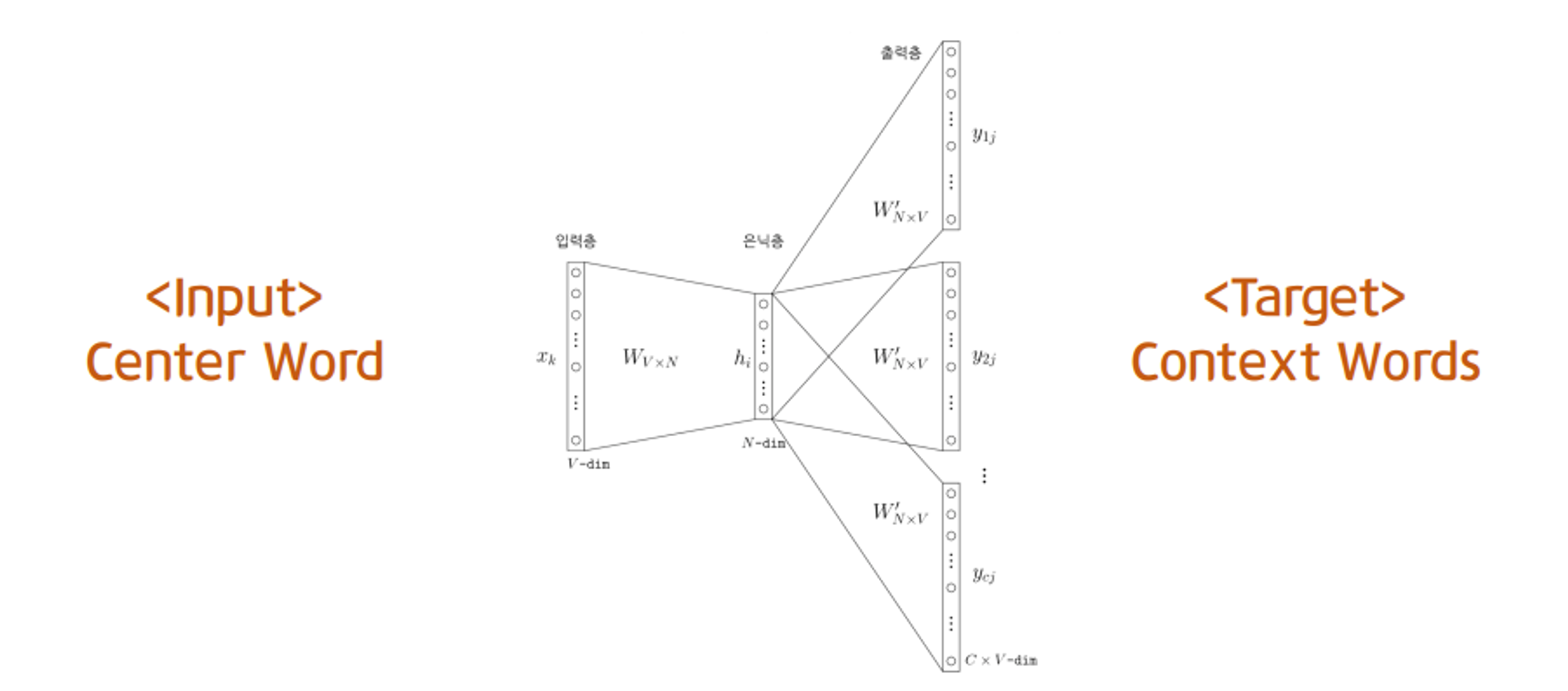
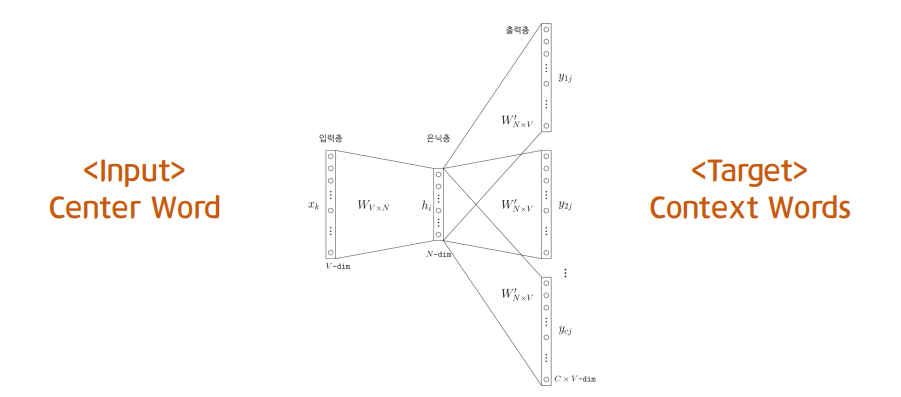
- skipgram : 중심단어(center word)로 주변단어(context word)를 예측가정 : 실제 문장들에서 비슷한 위치에 있는 word들은 embedding space에서도 비슷한 위치에 있을것이다.따라서 중심단어(c)가 주어졌을 때 주변단어(o)가 나타날 확률(아래식)을 최대화 하면 됩니다.P(o∣c)=∑w=1Wexp(uwTvc)exp(uoTvcgraph에서는 특정 node가 주어졌을 때 그 node의 neighborhood가 나타날 확률을 최대화 하면 되겠네요! !https://velog.velcdn.com/images%2Fminjung-s%2Fpost%2F07375f5e-b88c-4264-8106-b9d57a6acb52%2Fimage.png
random하게 neighbor를 보아서 graph 전체 structure를 고려하지 못한 Deep Walk의 단점을 개선하기 위해, node2vec에서는 기존의 randomwalk를 사용하지 않습니다.
node2vec key idea
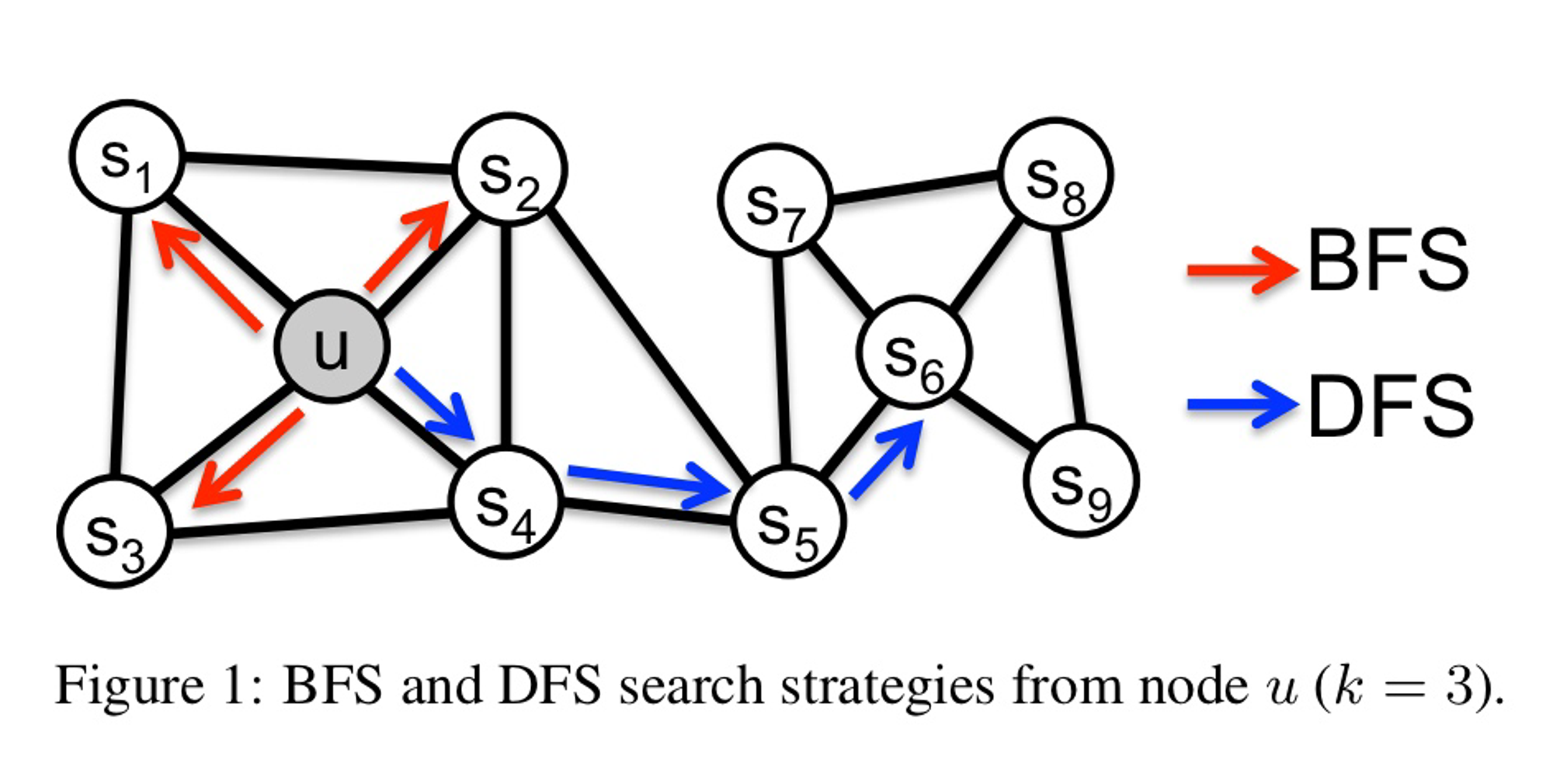
node2vec에서는 Biased 2nd-order random walk를 사용
- 1st-order random walk : node to node
- 2nd-order random walk : edge to edge
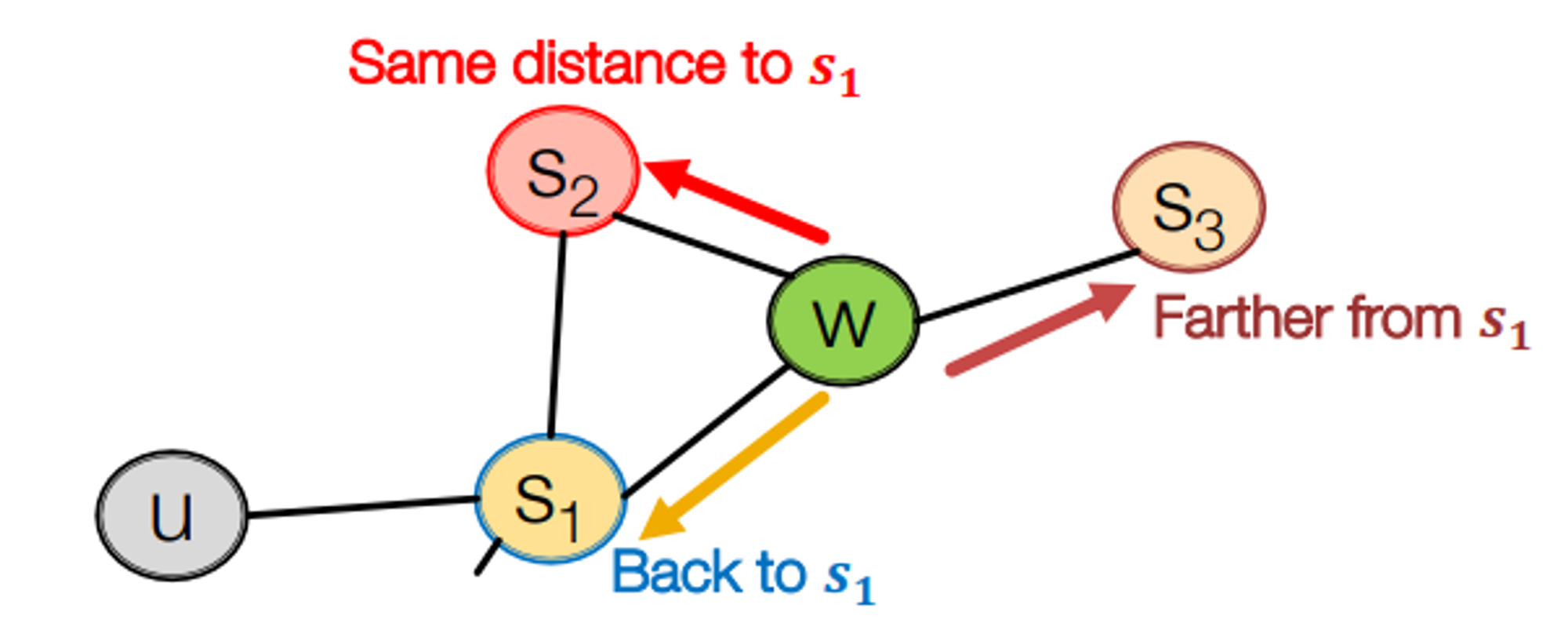
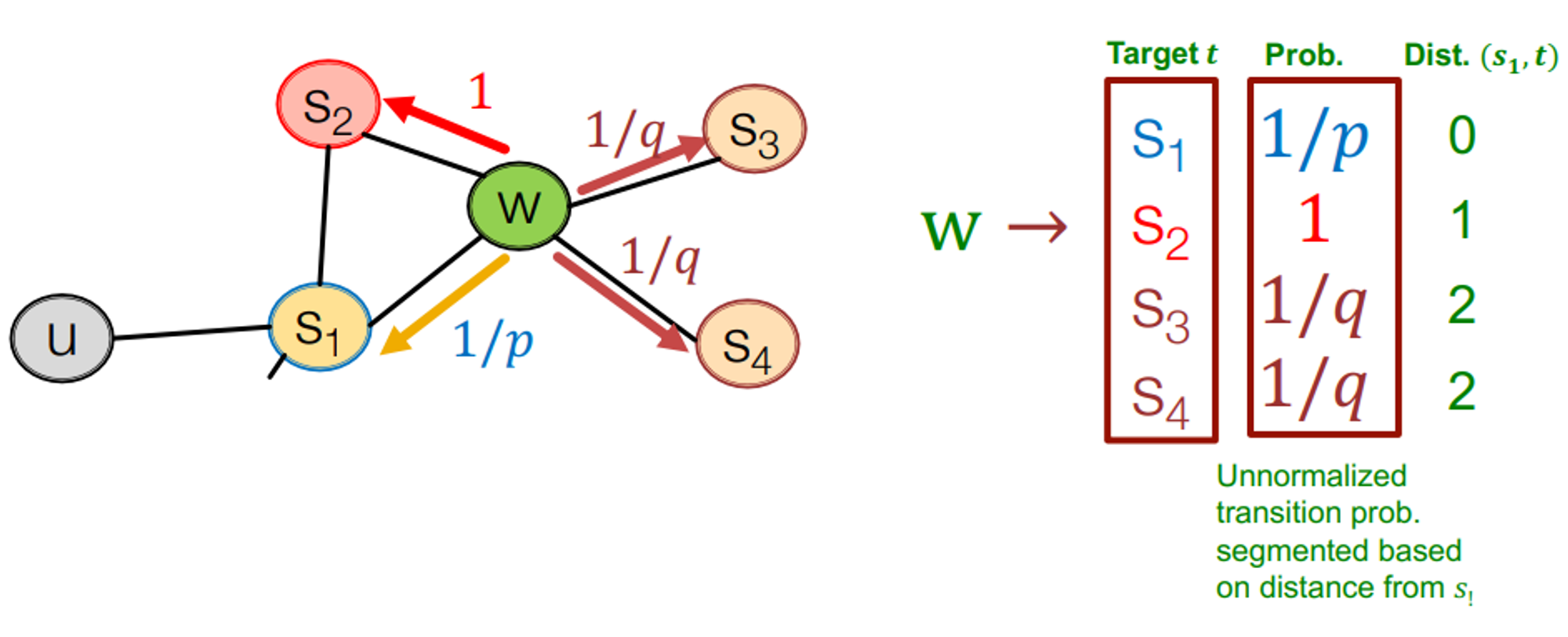
biased fixed-length random walk는 두가지 parameter를 정의
- return parameter p : 이전 node로 돌아갈 가능성을 계산하는 parameter. 주변을 잘 탐색는지 봄
*p*가 낮을수록 **BFS** like walk (좁은 지역 고려)
- in-out parameter q : DFS와 BFS의 비율. random walk가 얼마나 새로운 곳을 잘 탐색하는지
*q*가 낮을수록 **DFS** like walk (넓은 지역 고려)
EX

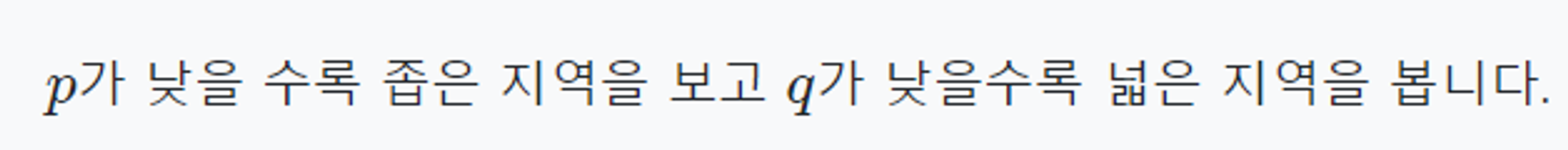
Translating Embedding for Modeling Multi-relational Data
Knowledge Graph
knowledge graph에서는 node를 entitie, link relation이라고 합니다. 한 KG의 relation에는 많은 종류가 있을 수 있습니다. KG에서의 link는 종류마다 갖는 의미가 다 다르다.
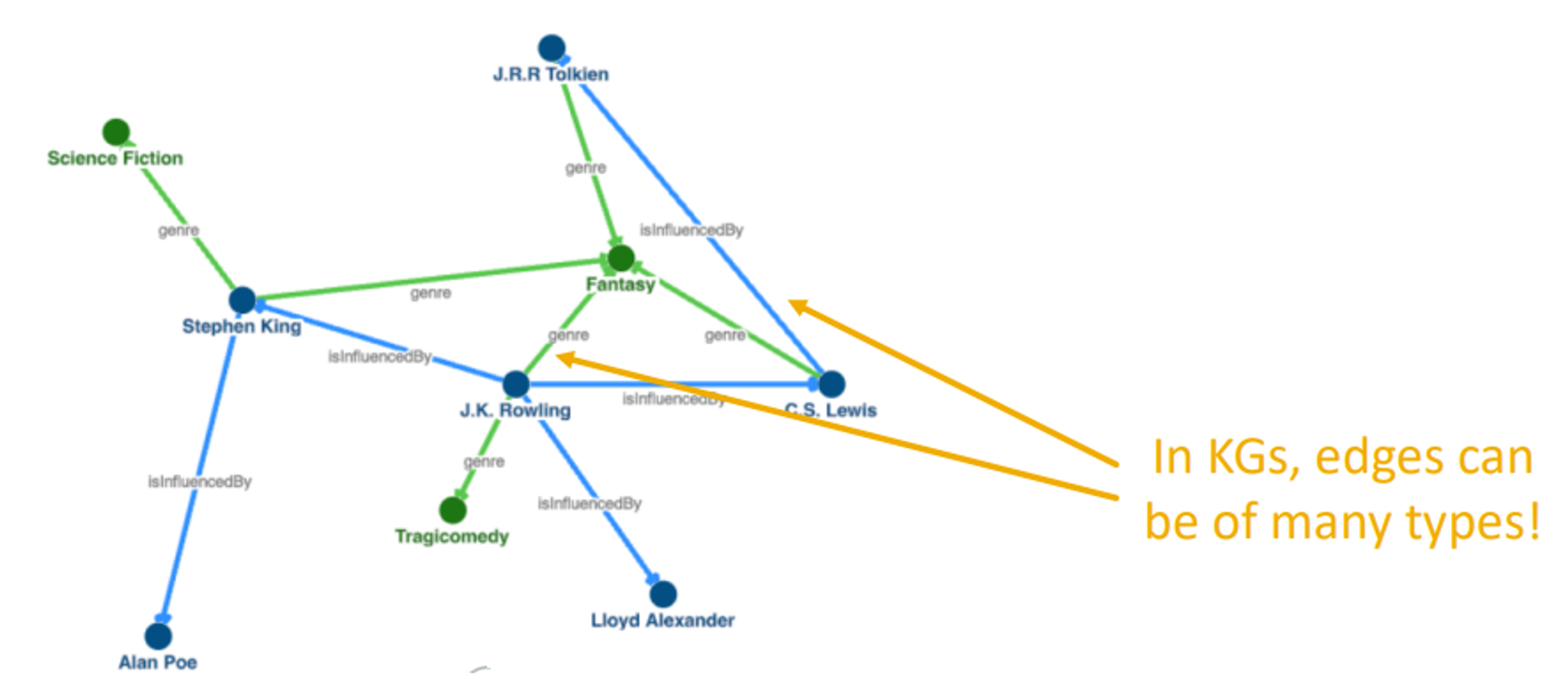
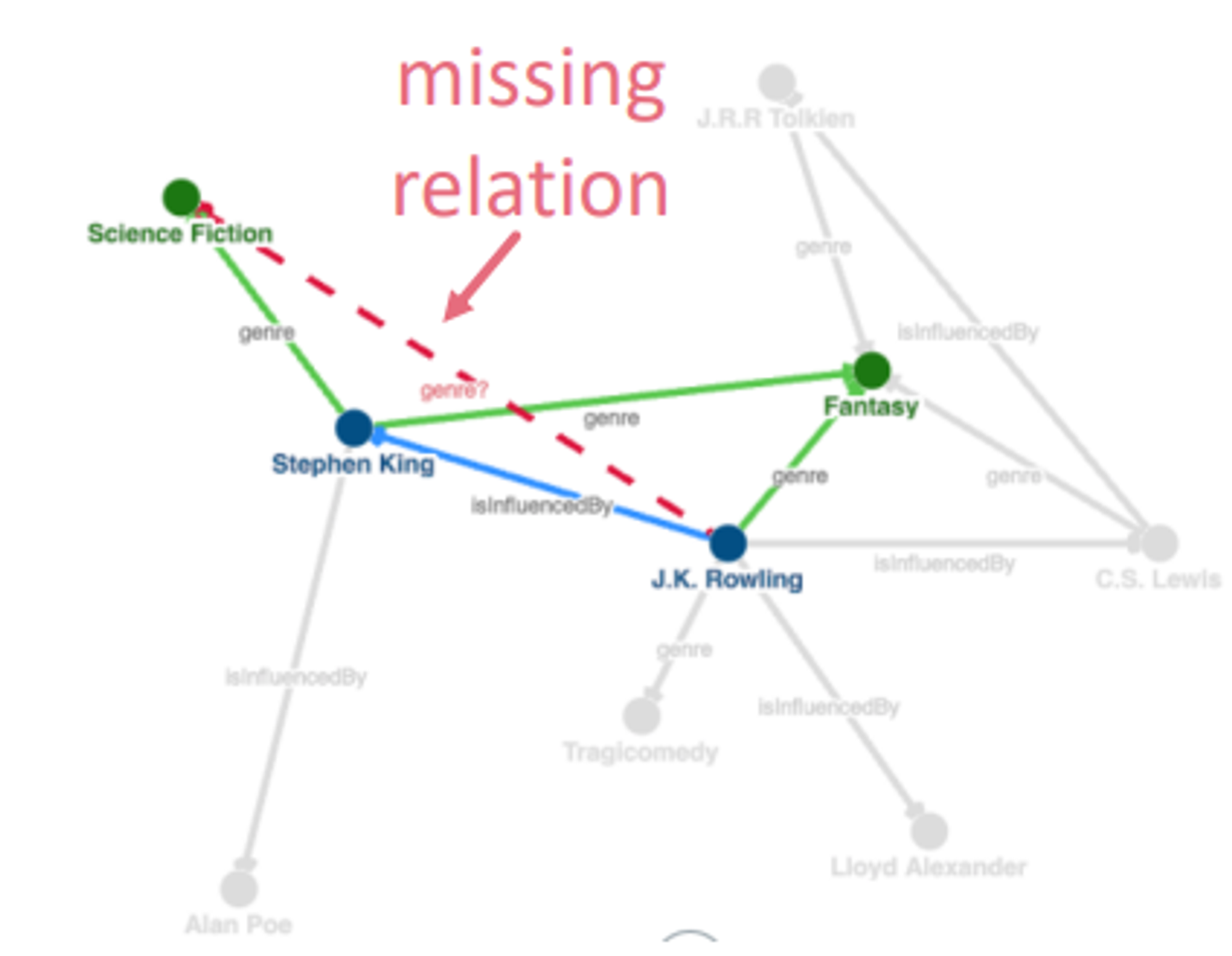
KG의 이어지지 않은 entitie(node)의 relation(link)를 예측하는 KG completion (=link prediction)에 대한 연구가 활발하다.
💡 KG의 local&global pattern을 잘 학습하는 link prediction model을 만들자.- link prediction은 학습된 패턴을 사용하여 관심 node와 그 외 모든 node간의 relationship을 일반화함으로써 수행
TransE(Trans R, TransH )
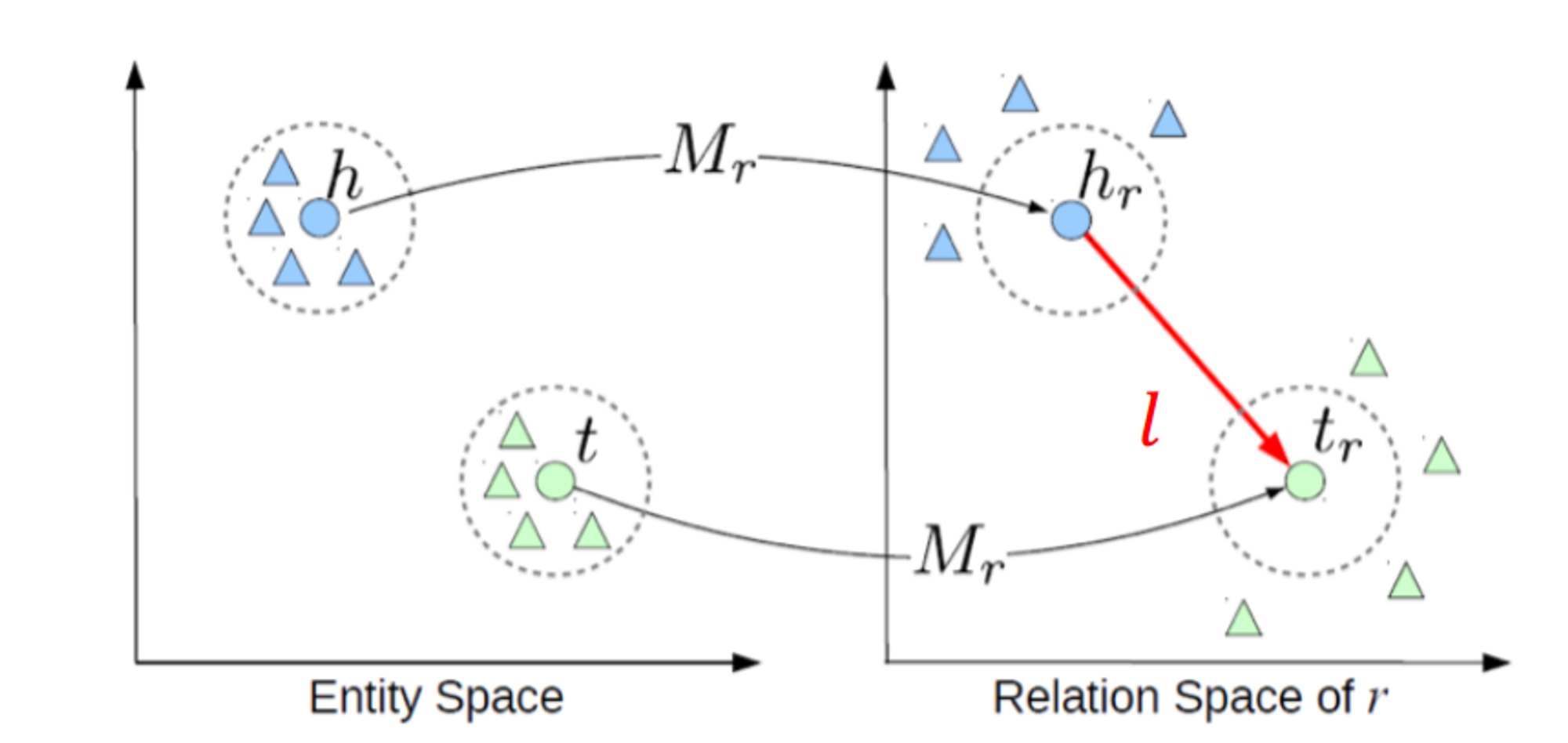
지금 우리가 해결할 문제는 구성요소와 관계들을 저차원의 벡터 공간으로 임베딩 시키는 것이고, 무엇보다 지식 그래프의 기반이 되고 학습하기 쉬운 장점을 가지는 것을 목표로 한다. 이에 TransE 라는 모델을 제시하는데 이 모델은 relationship(관계)를 저차원의 임베딩된 구성요소간 translations(전환) 으로 해석한다는 것이 핵심이다.
knowledge graph를 embedding하는TransE에서는 KG의 두 node(entity)의 관계를 triplet으로 표현한다.
*h (head entity), l (relation), t (tail entity) → (h,l,t)*

1) relation set의 l에 대해 uniform distribution을 따르게 하고 정규화를 시킵니다.
2) entitiy set의 e에 대해 uniform distribution을 따르게 하고 정규화를 시킵니다.
3) triaining triplet set S에서 batch size만큼의 triplet을 뽑아 Sbatch를 구성하고, Tbatch를 공집합으로 초기화합니다.
4) Sbatch에 대한 corrupted triplet을 만들어 Tbatch에 원소로 넣어줍니다.
5) 구성된 Sbatch와 Tbatch로 loss를 mimize하는 방향으로 임베딩을 업데이트합니다.
6) 2)~5)를 반복합니다.
TransE는 KG에서 entities간의 관계를 잘 반영하고 기존 SE model보다 최적화가 간단합니다. 2-way interactions를 표현하는데 있어 강점이 있지만, 3-way dependencies를 표현하는데는 약점을 가집다. 또한 1-to-1 이상의 , 1-to-N, N-to-1 관계를 포함하는데 TransE는 부적합할 수 있습니다.
글로벌소프트웨어캠퍼스와 교보DTS가 함께 진행하는 챌린지입니다.

{kind=link}