"YOLO"
- 실시간 object detection라는 개념을 제시한 논문
- 하지만 작은 물체와 겹쳐있는 여러 물체를 잘 감지하지 못한다는 단점
1. Introduction (생략)
2. Unified Detection
이미지를 S * S grid로 나누고 한 grid cell 마다 B개의 bounding box를 예측합니다. 이 때 bounding box는 5개의 예측값을 포함하는데 이는 x, y, w, h, confidence 입니다.
x,y는 grid cell에 대한 상대 좌표이고 w,h는 이미지 전체 가로 세로 길이에 대한 절대 길이입니다. 그리고 confidence는 로 정의합니다.
또 각 셀마다 C(conditional class probabilities를 예측합니다. 이는 로 정의합니다.
출력 Tensor의 크기는 다음과 같이 계산할 수 있습니다.
C의 길이는 클래스마다 확률이 있으므로 클래스의 개수와 같기 때문에 모델의 출력 tensor의 크기는 S * S * (B * 5 + C)입니다. PASCAL VOC 데이터셋에서는 S = 7, B = 2, C = 20(클래스가 20개이므로) 으로 설정해서 출력 Tensor의 크기는 7 * 7 * 30 이 됩니다.
2.1. Network Design
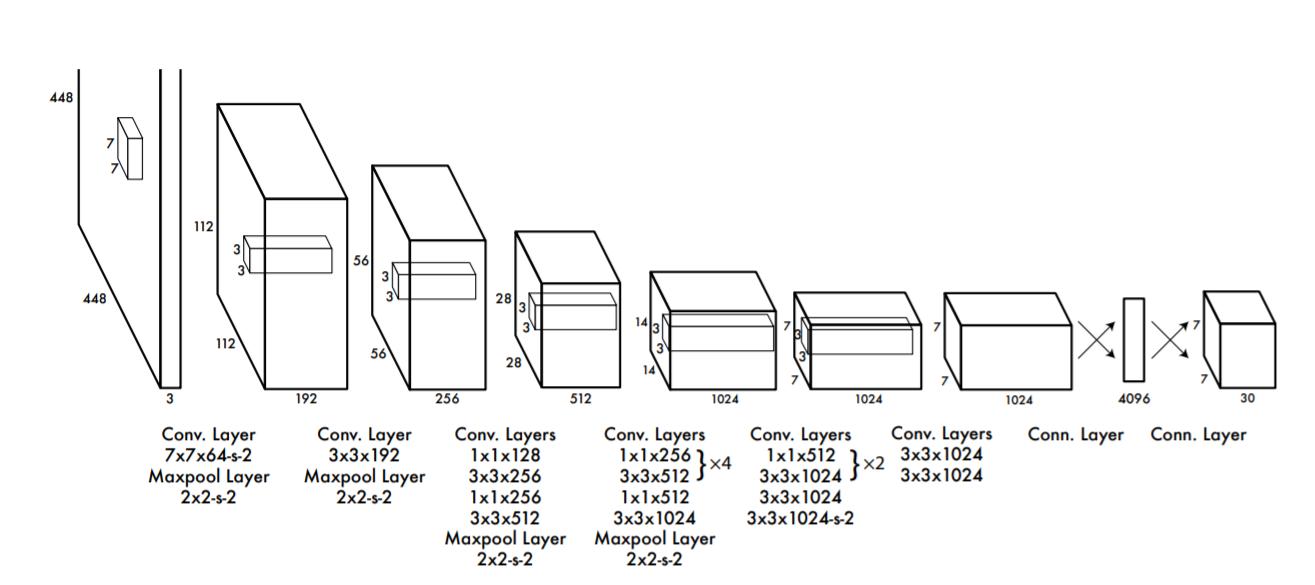
network design은 googlenet에서 영감을 받았습니다. 하지만 YOLO의 network는 googlenet의 Inception 모듈 대신 단순한 1*1 reduction(줄인다는 의미로 보입니다) layer -> 3*3 conv layer를 사용합니다.
network 구조를 간소화한 Fast YOLO 도 있지만 넘어가겠습니다.
2.2. Training
24개의 conv layer 중 앞에서 20개만 선택해서 그 뒤에 average pooling layer와
fc layer를 붙여서 ImageNet 1000-class competition dataset으로 pretrain합니다.
이후 4개의 conv layer와 2개의 fc layer를 추가하는데 가중치들은 랜덤으로 초기화됩니다.
또한 입력 이미지의 해상도를 224 224에서 448 448로 변경합니다.
마지막 layer에서는 class probabilities와 bounding box 좌표들을 예측합니다. 이 때 이미지의 가로 세로에 대한 w, h는 0~1 로 예측됩니다. 또한 x, y는 grid cell에 대해 0~1로 예측됩니다.
활성화 함수는 leaky relu를 사용합니다. 이때 leaky relu 피라미터는 0.1입니다. leaky relu는 다음 이미지를 참고하면 좋습니다.
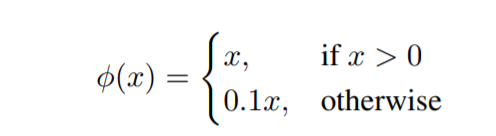
loss function:
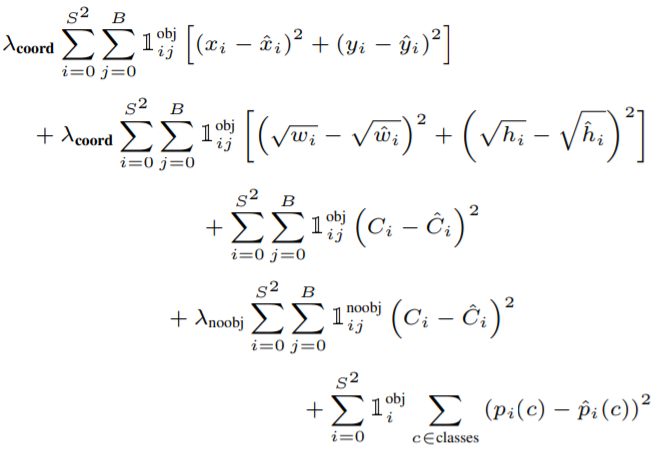
𝟙는 i번째 cell에 객체가 존재하는지 여부이고 𝟙는 i번째 cell의 j번째 bounding box predictor가 사용되는지 여부입니다. noobj는 반대로 객체가 존재하지 않는지 여부입니다. 참이면 1이고 거짓이면 0의 값을 가집니다.
입니다.
Learning Rate Scheduling:
첫번째 epoch에는 learning rate를 천천히 에서 로 증가시킵니다. 그리고 75 epochs동안 으로 학습을 진행하고 으로 30 epochs, 마지막 30 epochs는 로 학습을 진행합니다.
2.3. Inference
test 단계는 간단합니다. 하나의 신경망 계산만 수행하면 되기 때문입니다.
먼저 S*S 개의 그리드 셀마다 B개의 bounding box를 구하고 bounding box마다 class probabilities를 구해주면 끝입니다. 서로 다른 grid cell이 같은 객체에 대한 bounding box를 생성하는 문제는 Non-maximum Supression을 이용해서 해결할 수 있습니다.
NMS는 R-CNN 패밀리에 모두 설명해놓았으므로 딱히 설명하지는 않겠습니다.
참고한 글:
논문: You Only Look Once: Unified, Real-Time Object Detection
이번엔 최대한 다른분들이 번역해놓으신 글을 참고하지 않고 논문만 보고 직접 해석했습니다.
