ToBigs GAN
GAN (Gnerative Adversarial Networks)
: Discriminator(판별기)와 Generator(생성기)가 경쟁적으로 대립시켜(Adversarial) 학습을 시키는 신경망
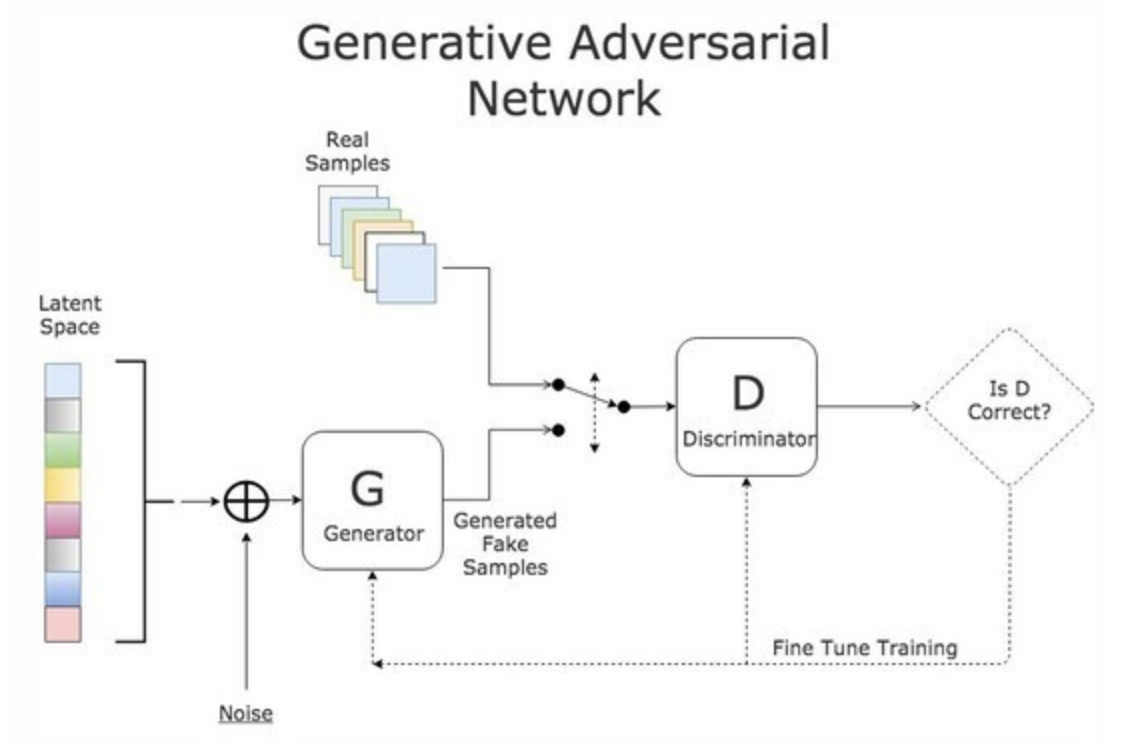
- 생성 모델의 대표
- 생성모델의 성능이 높아질 수록 분류모델은 어려운 문제를 풀게되고, 성능도 함께 오르게됨
- 다양한 분야로 적용되어 고급 딥러닝 기술로 활용되고 있음
GAN 문제점
Vanishing Gradients
: Discriminator의 학습력이 매우 좋을 경우, generator가 만든 fake sample을 모두 fake로 처리해버리기 때문에 새로 generate되는 data가 없어 vanishing gradients가 발생하므로 generator가 학습하지 못하는 문제점이 생김
< Vanishing Gradients >
신경망의 활성함수의 도함수 값이 계속 곱해지다 보면 가중치에 따른 결과값의 기울기가 0이 되어 버리므로 Gradient Descent(경사하강법)을 이용할 수 없게 되는 문제
해결 방법
Wasserstein loss
: Real과 Fake의 점수 차이를 최대화하는 방식으로 작동
- Discriminator를 최적으로 학습시키는 경우에도 vanishing gradient가 발생하지 않도록 설계되어있음
- 기존 GAN 논문이 아닌 WGAN 논문에서 처음 제시된 방법
- 진행 과정
(1) 우선 fake, real 두 이미지를 비교한다.
(2) for 문을 돌면서 critic network에서 fake, real의 점수를 구한다.
(3) 두 점수의 기댓값의 차이(= wassertein distance)를 최대화하는 방식으로 critic network가 학습된다.

따라서, Real과 Fake의 점수 차이를 극대화하여 Discriminater의 성능이 최적화되어도 Real과 Fake의 점수가 같아질 수 없으므로 모두 fake로 처리해버릴 일이 생기지 않으므로 vanishing gradient 문제가 발생하지 않는다.
Modified minimax loss
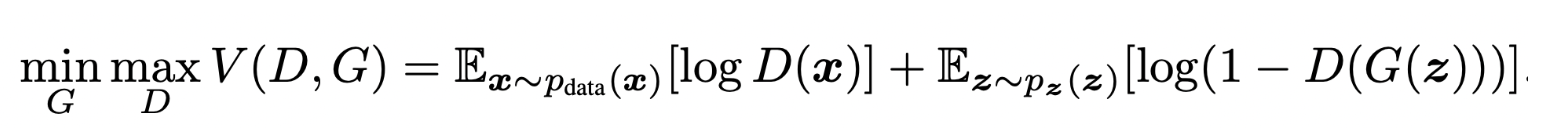
: Discriminator는 V(D,G)를 최대화시키고, Generator는 V(D,G)를 최소화시키는 방식으로 작동
- GAN loss라고도 불리며, 기존 GAN 논문에서 Vanishing gradient 문제를 해결하기위해 제시된 방법
- 진행 과정
(1) for 문을 돌면서 Discriminator는 k step만큼 Generator는 1 step 만큼 최적화하도록 한다.
(2) log(1-D(G(z))가 포화상태가 되므로 log(D(G(z))이 최대화되도록 학습한다.

Mode Collapse
: Generator가 real에 가까운 그럴듯한 이미지를 생성해낼 경우, generator는 이 이미지가 최적이라 판단하여 계속 이와 같은 이미지만 생성함. 따라서 Discriminator는 다양한 이미지를 학습하지 못하고 같은 이미지만 학습하게되므로 small set of output types만 학습하는 Mode Collapse 문제점이 생김
해결 방법
하나의 고정된 Discriminator에 최적화되는 것을 방지하기위해 Generator의 범위를 늘림
Wasserstein loss
: Generator가 새로운 이미지를 생성하도록 작동****
- 앞서 설명했듯이 Discriminator가 vanishing gradients 문제 없이 학습할 수 있도록 하므로 Discriminator가 local minima에 빠지지 않음
- Discriminator가 local minima에 빠지지 않으므로 generator가 같은 이미지를 지속적으로 생성하면 그 이미지를 거부할 수 있으므로 새로운 이미지를 생성함
따라서, Generator가 같은 이미지를 지속적으로 생성하면 Discriminator가 그 이미지를 거부하여 Generator가 새로운 이미지를 생성하도록 하므로 계속 같은 이미지가 생성되어 적은 이미지를 학습하는 Mode Collapse 문제가 해결된다.
Unrolled GANs
: Generator가 하나의 Discriminator에 over-optimize하지 않도록 작동
- Generator loss function을 사용하여 현재 discriminator's classifications 뿐만 아니라 future discriminator versions의 이미지도 통합함
따라서, 하나의 Discriminator가 아닌 현재 뿐만 아니라 미래의 Discriminator의 이미지를 통합하여 이미지의 수가 늘어나므로 적은 이미지에 과도하게 최적화되는 것을 방지하여 Mode Collapse 문제가 해결된다.
Diffrent Model
: Mode Collapse 문제를 해결하기 위해 제안된 모델들
- AdaGAN (2017)
- MAD-GAN (2018)
Failure to Converge
: 학습 단계에서 수렴하지 못해 문제점이 생김
- 모델 훈련의 불안정성
해결방법
GAN이 수렴하도록 다양한 정규화 방법을 시도함
Adding noise to discriminator inputs
: Discriminator의 이미지에 노이즈를 추가함
- Toward Principled Methods for Training Generative Adversarial Networks 논문
- KL과 JSD가 항상 발산인 상태를 유지하게 되고, 이런 발산 상태에서 gradient를 구하면 항상 0이기 때문에 generator의 학습이 제대로 이루어지지 않음
- 따라서, Manifold assumption을 해결하기 위해 real data space로 mapping한 후 노이즈를 추가하여, 두 개의 manifold의 disjoint를 해결하고자 함
< Manifold >
: 실제 데이터 space에서의 분포에서 meaningful한 데이터의 영역은 매우 국소적인데, 이 부분들의 set을 실제 data space에서 클러스터링한 모양
- Manifold의 차원이 실제 데이터의 차원보다 항상 작으므로, 실제 데이터 차원에서의 manifold에 대한 measure가 0이 됨
- 실제 P_r 로 만들어진 Manifold와 P_g 로 만들어진 Manifold사이의 겹치는 부분이 disjoint할 수 밖에 없음
Penalizing discriminator weights
: Discriminator의 가중치에 패널티를 부과함
- Stabilizing Training of Generative Adversarial Networks through Regularization 논문
(추후 추가할 예정)
GAN 평가 지표
Inception Score (IS)
: 생성된 이미지의 분포와 원래 이미지의 분포가 어느정도 비슷한지, 얼마나 다양한지 측정하는 지표
- Quantitative GAN Generator Evaluation (GAN의 양적 척도)
- 생성된 이미지의 품질과 다양성을 평가하는데 사용됨
- GAN의 성능 평가에 널리 사용되는 지표
- 진행 과정
(1) Inception v3 네트워크를 사용하여 생성된 이미지를 분류한다.
(2) 단일 이미지에 대한 라벨의 확률 분포로 반환한다.
(3) 식별하기 쉬운 이미지와 레이블의 Variation(편차)가 클수록 score가 높게 출력된다. (score 측정에 Kullback-Leibler divergence(KL 발산)이 쓰임)
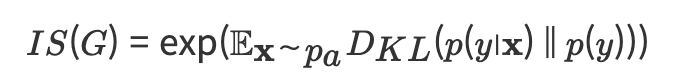
하지만, IS에는 실제 샘플 대신 생성된 이미지를 사용해 계산하고, 클래스 당 하나의 이미지만 생성하면 다양성이 낮더라도 p(y)p(y) 가 균등 분포에 가깝게 나오기 때문에 성능을 잘못 나타낼 수 있다는 단점이 있다.
Frechet Inception Distance (FID)
: 생성된 이미지의 분포와 원래 이미지의 분포가 어느정도 비슷한지 측정하는 지표
- Quantitative GAN Generator Evaluation (GAN의 양적 척도)
- 생성된 이미지의 품질을 평가하는데 사용됨
- 활성화 분포 사이의 거리를 측정 했을때, 유사한 이미지일수록 낮은 FID을 출력함
- 거리가 가까울수록 이비지의 집합 간 거리가 가깝기 때문임
- FID는 IS보다 노이즈에 더 강건함
- 평가 과정
(1) Inception 네트워크를 사용하여 중간 layer에서 feature를 추출한다.
(2) 이 feature에서 평균 μ와 공분산 Σ를 추출하여 계산한다.
(3) 실제 이미지 x와 생성된 이미지 g사이의 FID를 다음 이미지 속 식으로 계산한다.
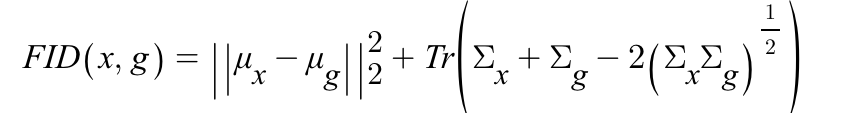
따라서, FID는 모델이 클래스당 하나의 이미지만 생성하는 경우 거리의 값이 높아지므로 이미지의 다양성을 측정하는데 적절한 지표다.
Nearest Neighbors
: 생성된 이미지가 얼마나 현실적인지 평가하기위한 지표
- Qualitative GAN Generator Evaluation (GAN의 질적 척도)
- 도메인에서 실제 이미지의 예시를 선택하고 비교를 위해 하나 이상의 가장 유사한 생성된 이미지를 찾기위해 사용됨
- 진행 과정
: Euclidean distance를 사용하여 유사한 이미지를 찾는다.
