지금까지 다루었던 Logistic Regression과 다르게, 2개 이상의 클래스 중 하나로
관측값을 분류하는 상황을 생각해보자.
반응변수 Y가 가질 수 있는 값은 K개가 있고, πk는 무작위로 선택된 관측값이 k번째 클래스에 속할 사전확률을 의미한다.
그리고 fk(x)=P(X=x∣Y=k)는 k번째 클래스에 속한 관측값의 x에 대한 확률밀도함수(pdf)이다. 이때 Bayes Theorem에 따라 다음과 같이 표현할 수 있다.
Pk(x)=P(Y=k∣X=x)=∑i=1Kπlfl(x)πkfk(x)(4.15)
Linear Discriminant Analysis (p=1)
p=1, 하나의 예측 변수가 있는 상황을 생각해보자. fk(x)을 (4.15)에 대입하여 Pk(x)를 구하려고 하는데, 그 전에 몇 가지 가정이 필요하다.
우선 fk(x)를 가우시안 분포라고 가정해보자.
fk(x)=2πσk1e−2σk21(x−μk)2(4.16)
여기서 μk와 σk2는 k번째 클래스에 대한 평균과 분산이다.
그리고 모든 클래스에서의 분산이 같다고 가정하자. (즉, σ12=...=σk2=σ2)
Bayes Classifier는 Pk(x)를 최대로 하는 클래스에 관측치 X=x를 할당한다. πk는 k번째 클래스에 속할 사전확률(Prior)를 나타내며, (4.17)에 로그를 취하면 다음과 같은 식이 도출된다.
δk(x)=xσ2μk−2σ2μk2+logπk(4.18)
로그함수는 Monotonic 이므로 δk(x)를 최대로 하는 클래스에 X=x를 할당하는 것과 같다.
Bayes decision boundary
K=2 이고 π1=π2일 때, Bayes Classifier는 2x(μ1−μ2)>μ12−μ22 인 경우 관측치를
클래스 1에, 그렇지 않으면 클래스 2에 할당한다.
이때의 베이즈 결정 경계는 δ1(x)=δ2(x)인 지점이며, 이를 통해 다음과 같은 결과를 도출할 수 있다.
x=2(μ1−μ2)μ12−μ22=2μ1+μ2(4.19)
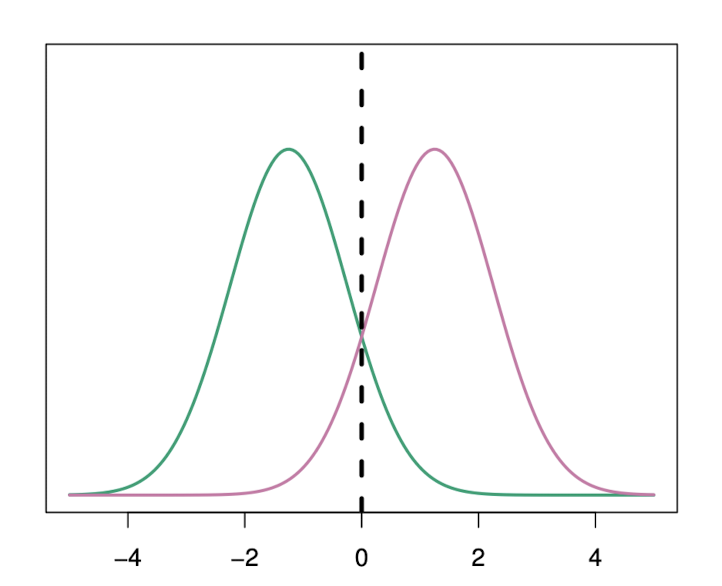
위 그림을 보면, 두 개의 가우시안 분포 함수 f1(x)과 f2(x)이 그려져 있다.
이 함수들은 두 개의 서로 다른 클래스를 나타낸다. 함수가 겹쳐져 있으므로 관측값 X=x이 주어졌을 때 x<0 인 경우 클래스 1에, 그렇지 않으면 클래스 2에 할당하는 것이다.
실제로 fk(x)가 정규 분포를 따른다고 하더라도 Bayes Classifier를 적용하려면 π1,...πk와 μ1,...,μk, 그리고 σ2를 추정해야 한다. 구체적으로는 다음과 같은 추정값들이 사용된다.
여기서 n은 총 train observation의 수이고, nk는 k번째 클래스의 train observation의 수이다. 위 추정치들을 (4.18)에 대입하면 판별 함수(determinant function)는 다음과 같다.
δ^k(x)=xσ^2μ^k−2σ^2μ^k+logπ^k(4.21)
위 Classifier의 이름에 'linear'가 들어가는 이유는 판별 함수가 x에 대한 선형 함수이기 때문이다.
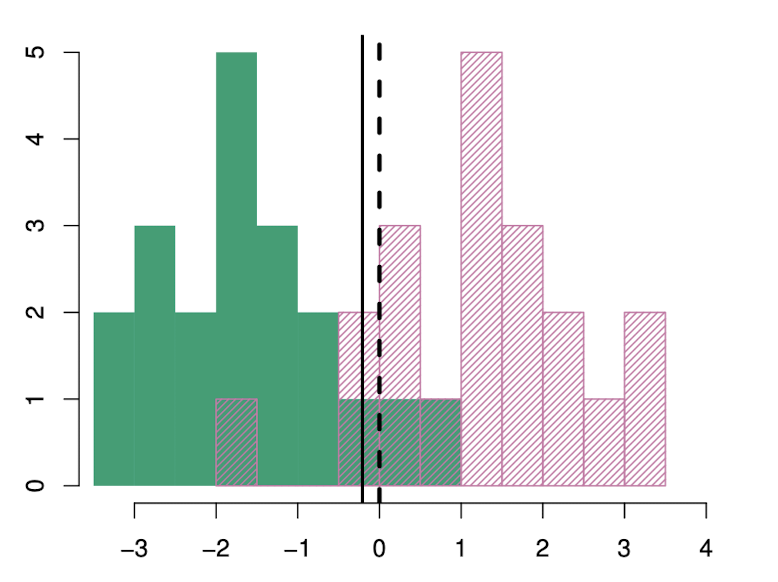
위 그림은 각 클래스에서 20개의 무작위 관측값을 나타낸 히스토그램이다. LDA를 구현하기 위해 (4.20)과 (4.21)을 사용하여 추정치들을 구한 후 (4.21) 이 최대가 되는 클래스로 관측값을 할당하는 경계를 계산했다.
그림을 보면 LDA 결정 경계가 베이즈 결정 경계보다 약간 왼쪽에 있다는 것을 보여준다.
많은 테스트 데이터를 생성하여 시뮬레이션된 두 가지 분류기의 오류율을 보면 베이즈는 10.6%, LDA는 11.1%으로 LDA Classifier가 잘 작동하고 있다는 것을 알 수 있다.
정리하면, LDA Classifier는 각 클래스의 관측값이 클래스 별 평균과 공통 분산을 가지는 정규 분포를 따른다고 가정하고 이것을 Bayes Classifier에 대입하여 얻는다.
Linear Discriminant Analysis (p > 1)
이제 2차원 이상의 예측값을 갖는 다변량 데이터를 생각해보자.
우선 fk(x)=(2π)p/2∣Σk∣1/21e−21(x−μk)TΣk−1(x−μk) 와 같이 다변량 가우시안 분포를 따른다고 가정하자.
이때 μk는 p×1 평균 벡터, Σ 는 p×p 공분산 행렬이다.
p=1 일 때와 비슷하게, 판별 함수는 다음과 같다.
δk(x)=xTΣ−1μk−21μkTΣ−1μk+logπk(4.22)
위 식은 (4.18)을 다차원으로 확장한 형태이다.
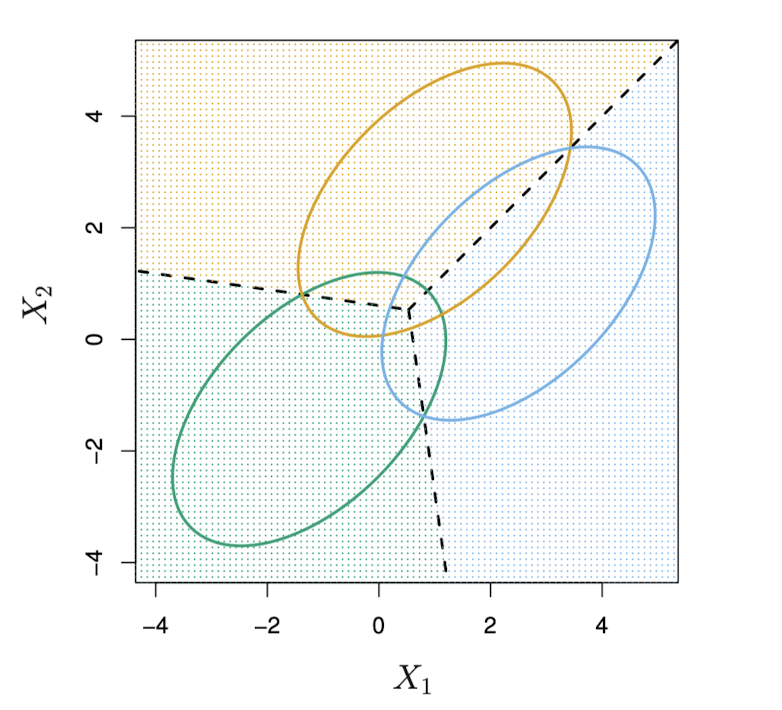
위 그림 속 세 개의 타원은 각 클래스에 대해 95% 확률을 포함하는 영역을 나타낸다. 점선은 베이즈 결정 경계로, δk(x)=δl(x)을 만족하는 x들의 집합이다. 즉,
QDA Classifier 역시 추정값들을 (4.25)에 대입해 최댓값을 갖는 관측치 X=x를 할당한다. (4.22)와 달리 판별 함수가 x의 이차 함수로 나타나기 때문에 이름에 Quadratic이 들어간다.
그렇다면 왜 공통 공분산 행렬을 사용하는지 여부가 중요할까? 다시 말해 LDA를 QDA 보다 선호해야 할 이유는 무엇일까?
그 답은 편향-분산 트레이드오프(Bias-Variance Trade-Off)에 있다. p개의 예측값이 있을 때, 공분산 행렬을 추정하려면 p(p+1)/2개의 parameter를 추정해야 하고, QDA는 K개의 클래스 각각 추정하므로 Kp(p+1)/2개의 parameter를 추정해야 한다.
결과적으로 LDA는 QDA에 비해 훨씬 덜 유연한 분류기이기 때문에 분산은 훨씬 낮다.
하지만 여기서 Trade-Off가 발생하는데, 만약 LDA가 K개의 클래스들이 공통 공분산 행렬을 갖는다는 가정이 맞지 않다면 LDA는 높은 편향을 갖게 될 것이다.
대체로 훈련 데이터가 상대적으로 적고 분산을 줄이는 것이 중요할 경우 LDA가 좋은 선택이 될 수 있다.
반면 훈련 데이터가 매우 많아서 분산이 큰 문제가 되지 않거나 K개의 클래스가 공통된 공분산 행렬을 갖는다는 가정이 성립하지 않는 경우에는 QDA를 사용하는 것을 권장한다.
Naive Bayes
이번에는 베이즈 정리를 이용하여 자주 사용되는 Naive Bayes Classifier를 소개하겠다.
지금까지 사후 확률 Pk(x)를 π1,...,πK와 f1(x),...,fK(x)로 표현했는데, 실제로 이 공식을 사용하려면 π1,...,πK와 f1(x),...,fK(x)의 추정값이 필요하다.
사전 확률 π1,...,πK 를 추정하는 것은 K번째 클래스에 속하는 훈련 샘플의 비율로 간단하게 추정할 수 있지만, f1(x),...,fK(x)를 추정하는 것은 매우 복잡한 일이다.
그래서 LDA와 QDA에서는 pdf가 정규 분포라는 가정을 세웠지만, 나이브 베이즈에서는 조금 더 강력한 가정을 세운다.
각 클래스 내에서 p개의 예측 변수들이 서로 독립적이다.
fk(x)=∏j=1pfkj(xj). 이때, fkj(x)는 k번째 클래스에서 j번째 예측 변수의 밀도 함수이다.