ONNX : Open Neural Network Exchange로 Tensorflow, Pytorch와 같이 서로 다른 DNN 프레임워크 환경에서 만들어진 모델들을 호환되게 사용할 수 있도록 만들어진 공유 플랫폼
CNN 정리
CNN은 이미지 인식에 뛰어난 신경망 모델
전처리(컨볼루션, 풀링)와 분류 단계로 동작
전처리단계는, 날 것의 이미지 데이터를 가져와서, 분류 장치에 넣기 위해 정제하는 과정임, 전처리 단계 구성요소는 컨볼루션 레이어, 풀링 레이어가 있음
컨볼루션 레이어는 가중치와 편향값(필터)을 적용하여 이미지에서 테두리, 선, 색 등등 시각적인 특징을 감지해냄
컨볼루션은 합성곱으로 이미지 데이터 연산할 때 가중치 갯수 줄여줌 -> 총 연산량 감소
예를 들어, 28x28 이미지를 처리할 때 28x28=784개의 가중치를 찾아야 하는데 5x5 필터로 컨볼루션하면 25개만 찾으면 됌
풀링 레이어는 이미지 2차원 배열에서 지정한 영역의 값을 하나의 값으로 압축함
맥스풀링 많이 쓰는데 가장 큰 값 하나만 가져온 것, 이미지에 큰 영향 안 주면서 연산량 감소
분류 단계는 전처리 단계에서 정제된 이미지를 학습신경망에 넣는 과정임, 결과적으로 신경망에서 나온 결과가 목록의 정확한 label을 선택하는지가 핵심
Tensorflow 이미지 분류 코드
- Tensorflow 및 기타 라이브러리 가져오기
- 데이터세트 다운로드 및 탐색하기
- keras.processing 사용하여 데이터 세트 로드하기
- 데이터 세트 만들기
- 데이터 시각화하기
- 성능을 높이도록 데이터 세트 구성하기
- 데이터 표준화하기
- 모델 만들기
- 모델 컴파일하기
- 모델 요약
- 모델 훈련하기
- 훈련 결과 시각화하기
- 오버피팅 발생했는지 확인, 데이터 더 필요한지 확인
- 오버피팅 막기위해 드롭아웃 사용하기
- 모델 컴파일 및 훈련하기
- 훈련 결과 시각화하기
- 새로운 데이터 예측하기
구글넷 논문 공부
<논문 제목>
GoogLeNet - Going deeper with convolutions
<논문 소개>
구글넷은 2014 이미지 인식대회에서 우승한 CNN 모델
기존 AlexNet보다 네트워크의 depth(22 layer)와 width(각 layer별 unit 수)를 늘려 정확도를 높이면서, 파라미터 수는 줄여 연산량은 감소시킴
구글넷 이후 CNN 모델들 layer가 늘어남
<논문 내용>
구글넷의 차별화된 특징 4가지 - 1x1 Conv, NIN, Inception, Auxiliary Network
- 1x1 Conv :
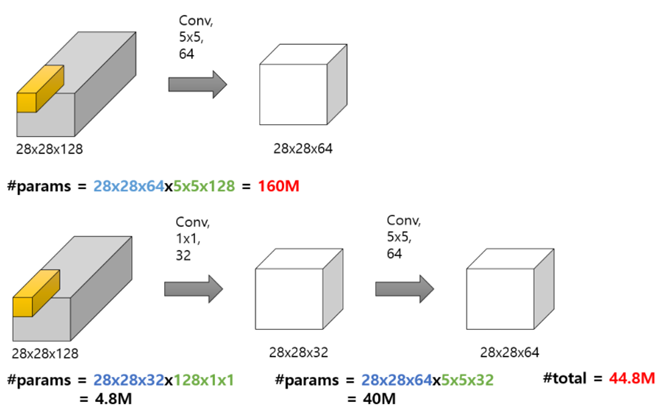
1x1 컨볼루션을 통해 3가지 장점을 얻음
channel 수 감소, 연산량 감소, 비선형적 특징 잘 추출
보통 컨볼루션 레이어를 구성할 때 channel은 하이퍼 파라미터로 우리가 직접 결정
기존에 28x28 channel 128개를 5x5 필터 64개(필터 1개는 입력의 channel 128개에 모두 적용가능한 필터 뭉치)에 컨볼루션 시키면 파라미터 수는 28x28x64(다음 feature map 개수) x 5x5x128(5x5필터로 128번연산) 으로 160M개
근데 1x1 컨볼루션을 중간에 넣어봄, 28x28 feature map 128개를 1x1 필터 32개에 컨볼루션시키면 파라미터 수는 28x28x32(다음 feature map 개수) x 1x1x128(1x1필터로 128번 연산) 으로 4.8M개, 그리고 5x5 필터 64개에 컨볼루션 시키면 channel 64개짜리 28x28 나옴
여기서 알 수 있는 것: 필터의 개수 = 다음 feature map의 개수(이미지 채널 개수)
1x1 conv을 중간에 넣으면 그냥 컨볼루션 시키는 것보다 파라미터 개수(연산량)를 줄일 수 있음, 다만 정보 소실의 가능성 존재
- NIN (Network In Network)
컨볼루션 과정 중간에 MLP(다층 퍼셉트론)을 넣어서 이미지의 비선형적 특징을 더 잘 추출할 수 있도록 함
FC 사용 대신에 GAP 사용으로 파라미터 개수 감소
- Inception
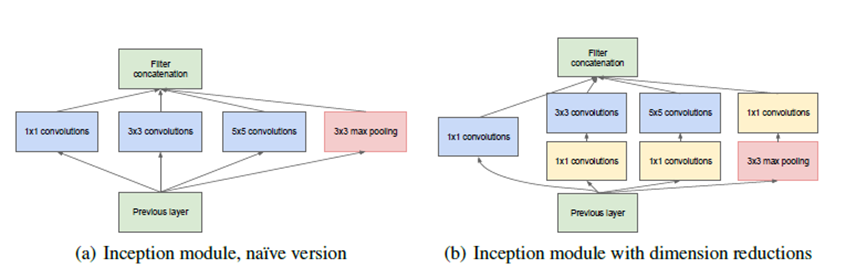
인셉션은 입력에 대해 다양한 크기의 컨볼루션을 사용한 후 합친 것
(더 다양한 이미지 특징 추출 가능 -> 정확도 향상 가능)
다만, 3x3, 5x5 컨볼루션 전에 1x1 컨볼루션을 이용하여 파라미터 개수 감소를 꾀함
옆에 max pooling 부분에서도 인풋 사이즈를 줄이면서 두드러지는 이미지 특징(큰 숫자)들을 뽑을 수 있음
- Auxiliary Network:
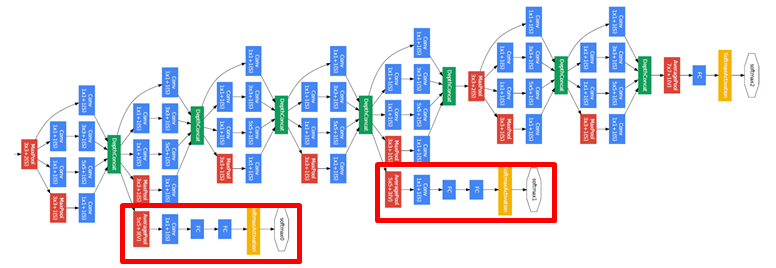
구글넷 구조가 22 layer로 layer을 많이 쌓았기 때문에, 트레이닝 단계에서 back propagation 시에 vanishing gradient 문제가 있음 (역전파 시에 전단계 layer의 가중치를 수정하기 위해 기울기 필요, 근데 층이 많으면 전달할 때 미분 연산을 계속 하게 되면서 기울기 값이 사라져버림)
그래서 구글넷은 모델 중간에 보조 분류기를 만들음 -> 중간중간에 softmax를 두어 중간에서도 역전파하게 만듬 -> 기울기 전달이 잘 되지 않은 하위 layer 트레이닝 가능해짐
