Neural Network
- 회귀 모델과 신경망의 차이
회귀모델은 히든레이어가 없고 신경망은 중간에 히든레이어 존재
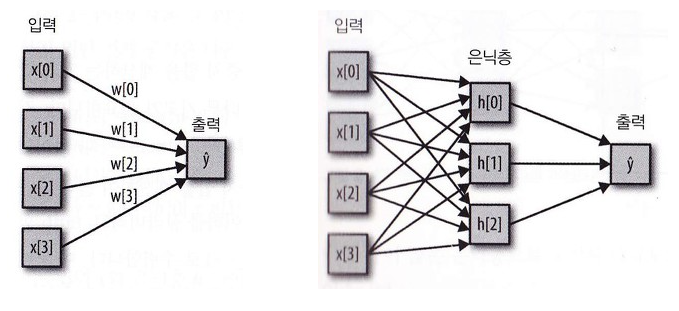
회귀모델 사용 경우)
집값에 영향을 주는 요인을 파악하기 위해 회귀모델로 분석한 결과 주변 공원의 개수가 1만큼의 영향이 있고 지하철역의 유무가 5만큼의 영향이 있으며, 유흥업소의 개수가 -1만큼의 영향이 있다는 결과를 도출하였습니다. 따라서 지하철역의 유무가 집값에 큰 영향이 있으며, 공원의 개수와 유흥업소의 개수는 집값에 반대로 영향을 주지만 그 크기는 비슷한 수준이 있음을 알 수 있었습니다.
하지만 모델의 설명력(정확도)은 70%이기 때문에 다른 케이스에 대해 집값을 추정하면 30%정도는 오차가 발생할 수 있습니다.
즉, 모델과 현상을 설명하긴 좋으나 정확성을 상대적으로 떨어집니다.
신경망 사용 경우)
집값에 영향을 주는 요인을 파악하기 위해 신경망으로 분석한 결과 주변 공원의 개수가 1번 은닉층에서 0.5만큼 영향력이, 2번 은닉층에서 1만큼 영향력이, 3번 은닉층에서 -0.1만큼 영향력이 있고, 1번 은닉층은 집값에 1만큼 영향력이 있고, 2번 은닉층은 3, 3번 은닉층은 -2만큼의 영향력이 있습니다...는 개소리고요.
공원의 개수가 집값에 어떻게 영향을 주는지 말로 설명이 안됩니다.
하지만 모델의 정확도는 95%이기 때문에 다른 케이스에 대해 공원 개수, 지하철역 유무, 유흥업소 개수만 가지고도 집값을 거의 정확하게 맞힐 수 있다는 것은 사실입니다.
즉, 모델과 현상을 설명할 수는 없으나, 어쨌든 결과는 정확합니다.
이렇게 서포트 벡터 머신과 신경망처럼 복잡한 알고리즘은 학습된 모델을 사람이 이해할 수 없고, 따라서 알파고와 이세돌이 대국을 할 때 알파고가 왜 예측하지 못한 방법으로 수를 두는지 그 의도를 파악할 수 없는 것이 바로 이러한 신경망의 특징 때문임을 알 수 있습니다. 인공지능이 인간을 위협하지 않으면서 인간에게 더 많은 지식과 통찰력을 줄 수 있도록 잘 사용되려면 학습된 모델이 어떤 방법으로 작동하는 지 이해할 수 있어야 하는데, 아직까지 이러한 신경망의 거의 유일한 단점은 앞으로의 연구자들에게 도전과제로 남아있습니다.
출처: https://ellun.tistory.com/104 [Ellun's Library]
출처: https://ellun.tistory.com/104 [Ellun's Library]
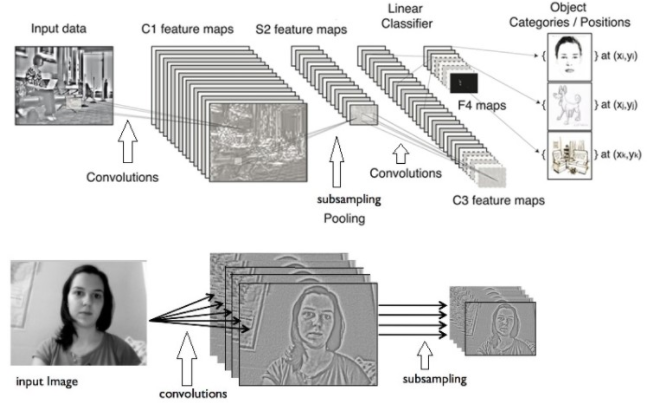
CNN(Convolution Neural Network)
영상 분석에 대해서 머신러닝을 할 때, 입력할 영상정보는 2차원 데이터 그대로 붙이면 학습시간 증가, 망의 크기, 변수 개수가 많아지는 문제가 발생, 이러면 오버피팅, 지역해수렴 등 다양한 문제에 봉착하여 사용이 어려움, 영상데이터를 줄이고 줄여서 1차원 데이터로 만들어 신경망 입력단에 각각 하나씩 매핑되도록 함
그래서 나온 방법이 CNN -> 2차원 데이터를 컨볼루션이랑 서브샘플링으로 특징만 남기고 줄여서 1차원 데이터로 만드는 것
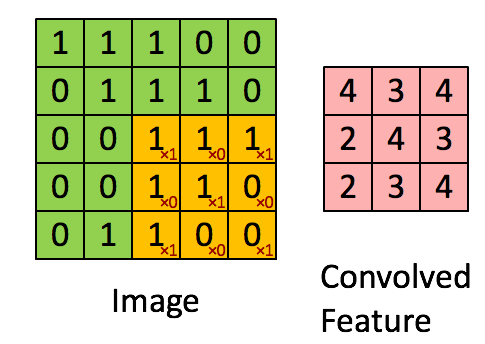
컨볼루션 - nxn 마스크 씌우고 가중치 곱한 후 더한 합을 한 픽셀에 넣는거
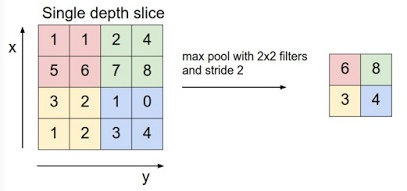
서브샘플링 - max pool(해당 영역의 최대치 선택)기법으로 화면의 크기를 줄임
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import fashion_mnist
# 1. 데이터 가져오기
(train_X, train_Y), (test_X, test_Y) = fashion_mnist.load_data()
train_X, test_X = train_X/255., test_X/255.
train_X = train_X.reshape(-1, 28, 28, 1)
test_X = test_X.reshape(-1, 28, 28, 1)
for c in range(16):
plt.subplot(4, 4, c+1)
plt.imshow(train_X[c].reshape(28, 28), cmap = 'gray')
# 2. 모델 layer 정의
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(input_shape = (28, 28, 1), kernel_size = (3, 3), filters = 16),
tf.keras.layers.Conv2D(32, (3, 3)),
tf.keras.layers.Conv2D(64, (3, 3)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation = 'relu'),
tf.keras.layers.Dense(10, activation = 'softmax')
])
# 3. 모델 컴파일
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy'])
model.summary()
# 4. 모델 트레이닝
training_epochs = 15
h = model.fit(train_X, train_Y, validation_split = 0.2, epochs = training_epochs)
# 5. 모델 평가
score = model.evaluate(test_X, test_Y, verbose = 0)
#---------------
lab = ["T-shirt/top",
"Trouser/pants",
"Pullover shirt",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot"]
d = {}
for i, x in enumerate(lab):
print(i, x)
# create dict and push plt title
d[i] = x
fg_color = 'red'
bg_color = 'black'
plt.figure(figsize = (15, 15))
hypothesis = tf.argmax(model.predict(train_X), 1).numpy()
for c in range(16):
co = train_Y[c] == hypothesis[c]
print(co)
plt.subplot(4, 4, c+1)
plt.imshow(train_X[c].reshape(28, 28), cmap = 'gray')
if co:
plt.title(d[hypothesis[c]])
color = bg_color
else:
plt.title(d[train_Y[c]]+'/'+d[hypothesis[c]])
color = fg_color
# push correct plt title
#plt.title(d[train_Y[c]])
# push predicted plt