목차
이론
-
머신러닝 시작하기
-
데이터 핸들링1
-
데이터 핸들링2
-
사이킷런 살펴보기
5. 지도학습(분류)
-
지도학습(회귀)
-
비지도학습
-
자연어 처리
-
이미지 처리
프로젝트
- 머신러닝 프로젝트
**학습목표**
1.지도학습(분류) 모델을 사용할 수 있습니다.
2.하이퍼파라미터의 종류를 알고, 하아퍼파라미터 값을 조절할 수 있습니다.
3.다양한 평가 지표를 사용하여 모델을 평가할 수 있습니다.지도학습(supervised Learning)
:데이터에 대한 Label(결과)이 주어진 상태에서 학습시키는 방법
1. 분류모델
1. 의사결정나무(Decision Tree)
:의사결정나무는 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙들의 조합으로 나타내며, 그 모양이 ‘나무’와 같다고 해서 의사결정나무라 불림. 질문을 던져서 대상을 좁혀나가는 ‘스무고개’ 놀이와 비슷한 개념
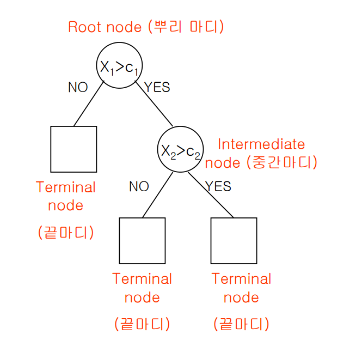
*terminal node(=leaf node): 자식노드가 없는 노드, 말단노드 라고도 한다.
- root node에서 분기가 거듭될 수록 그에 해당하는 데이터의 개수는 줄어듦
- terminal node에 속하는 데이터의 개수를 합하면 root node의 데이터수와 일치
=>terminal node 간 교집합이 없다는 뜻- terminal node의 개수는 분리된 집합의 개수
=> 위 그림처럼 terminal node가 3개라면 전체 데이터가 3개의 부분집합으로 나눠짐- 의사결정나무는 분류(classification)와 회귀(regression) 모두 가능
=>범주나 연속형 수치 모두 예측할 수 있음.
-
의사결정나무의 분류 과정
terminal node에서 가장 빈도가 높은 범주(=최빈값)에 새로운 데이터를 분류. 운동경기 예시를 기준으로 말씀드리면 날씨는 맑은데 습도가 70을 넘는 날은 경기가 열리지 않을 거라고 예측 -
회귀의 경우 해당 terminal node의 종속변수(y)의 평균을 예측값으로 반환하며, 예측값의 종류는 terminal node 개수와 일치. terminal node 수가 3개뿐이라면 새로운 데이터가 100개, 아니 1000개가 주어진다고 해도 의사결정나무는 딱 3종류의 답만을 출력하게 됨
Q1. 한번 분기 때마다 변수 영역을 두 개로 구분하는 모델이라는데 어떤 기준으로 영역을 나누게 되나?
=> 정보획득(information gain)이 최대가 되는 방향으로 학습을 진행
= 순도(homogeneity)가 증가하는 방향
= 불순도(impurity) 또는 불확실성(Uncertainty)이 최대한 감소하는 방향
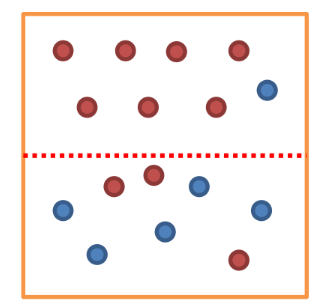
* 어떤 데이터가 균일한 정도를 나타내는 지표(= 순도 계산하는 방식)
1) 엔트로피(entropy)
: m개의 레코드가 속하는 A영역에 대한 엔트로피는 아래와 같은 식으로 정의
(Pk=A영역에 속하는 레코드 가운데 k 범주에 속하는 레코드의 비율)
위 그림의 엔트로피를 구하면, 전체 16개(m=16) , 빨간색동그라미(범주1)=10개, 파란색(범주2)=6개
≈ 0.95
여기서 a영역에 빨간색 점선을 그어 두개 부분집합 R1, R2로 분할한다고 가정해보면, 두개 이상에 대한 엔트로피 공식은 아래 식과 같음. 분할 후 A영역의 엔트로피를 아래와 같이 각각 구할 수 있음
≈ 0.75
분기전 엔트로피가 0.95 였는데 분할한 뒤에 0.75가 됨. (엔트로피 감소=불확실성 감소 = 정보 획득)한 걸로 봐서 모델은 두 개의 부분집합으로 나누게 됨.
참고로, A영역에 속한 모든 레코드가 동일한 범주에 속할 경우 엔트로피는 0임.
반대로 범주가 둘 뿐이고 반반 섞여있을 경우는 엔트로피 1로 불확실성이 최대가 됨.
2) 지니계수(gini Index)
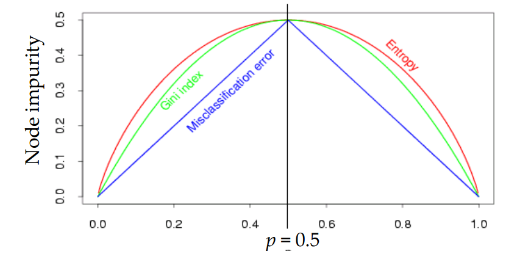
범주가 두 개일 때 한쪽 범주에 속한 비율(p)에따른 불순도의 변화량을 그래프로 나타낸 그림
비율이 0.5(각각 반반씩 섞여있는 경우)일때 불순도가 최대임.
Q2. 데이터셋을 나눌때 X_train의 X는 대문자로 y_train의 y는 소문자로 나타내는 이유가 있나?
=> X는 대문자를 사용하고, y는 소문자를 사용하는 이유는 X = 행렬 y는 벡터이기 때문이다. X_train은 train데이터의 행렬을 뜻한다. y_train은 train데이터의 벡터를 뜻한다.
<실습>
#1. 라이브러리 불러오기
import pandas as pd #데이터프레임 만들기 위해 사용
from sklearn.model_selection import train_test_split
#데이터셋을 학습데이터,테스트데이터로 나누기 위해 train_test_split 사용
from sklearn.metrics import accuracy_score
#학습결과를 평가하기 위해 정확도로 평가
#2. 데이터 불러오기(ex)유방암데이터)
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
def make_dataset():
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['target']=cancer.target
X_train, X_test, y_train, y_test = train_test_split(
df.drop('target',axis=1),df['target'],test_size=0.5, random_state=1004)
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = make_dataset() # 튜플 언패킹
----------------------데이터 전처리 과정----------------------------
#3.의사결정모델
from sklearn.tree import DecisionTreeClassifier # 모델 선정
model = DecisionTreeClassifier(
criterion = 'entropy',
max_depth = None,
min_samples_split = 2,
min_samples_leaf = 2,
random_state=0)
model.fit(X_train, y_train) # 학습
pred = model.predict(X_test) # 예측
accuracy_score(y_test, pred) # 평가
# 의사결정트리 하이퍼파라미터
# criterion = 'entropy' 불순도 지표
# max_leaf_node =3, 리프노드의 최대 개수
# max_depth = None, 트리의 최대 깊이, Default=None, 완벽하게 클래스 값이 결정될 때까지 분할 또는 min_samples_split 보다 작아질때까지 분할
# min_samples_split노드를 분할하기 위한 최소한의 샘플 데이터 수, Default=2, 작게설정할수록 분할 노드가 많아져 과적합 가능성이 증가함
# min_samples_leaf 리프노드가 되기위한 최소한의 샘플 데이터 수, 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요
# max_feature = None, 최적의 분할을 위해 고려할 최대 feature 개수, Default=None(데이터 셋의 모든 피처를 사용)
##int형으로 지정 →피처 갯수
##float형으로 지정 →비중
##sqrt 또는 auto : 전체 피처 중 √(피처개수) 만큼 선정
##log : 전체 피처 중 log2(전체 피처 개수) 만큼 선정
#추가학습)시각화 (pip install graphviz 설치해야함)
from sklearn.tree import export_graphviz
# export_graphviz( )의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(model, out_file="tree.dot", class_names = cancer.target_names,
feature_names = cancer.feature_names, impurity=True, filled=True)
print('===============max_depth의 제약이 없는 경우의 Decision Tree 시각화==================')
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphiviz 가 읽어서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
2. 랜덤포레스트
: 같은 데이터에 의사결정나무 여러개를 동시에 적용해서 학습 성능을 높이는 앙상블 기법
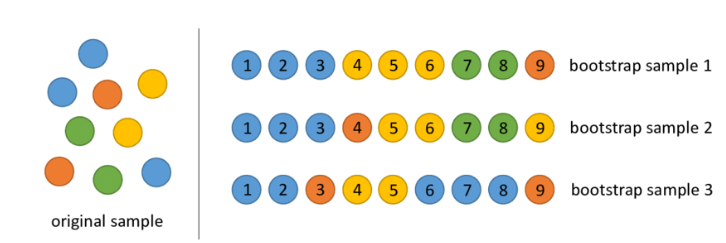
: 동일한 데이터로부터 복원추출을 통해 30개 이상의 데이터 셋을 만들어 각각에 의사결정나무를 적용한 뒤 학습 결과를 취합하는 방식
:여기서 각각의 나무들은 전체 변수 중 일부만 학습, 개별 트리들이 데이터를 바라보는 관점을 다르게 해 다양성을 높이려는 시도
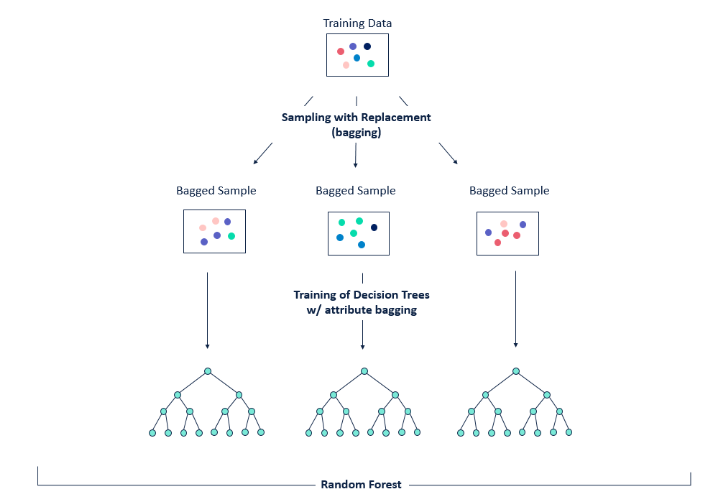
- 앙상블 : 상대적으로 약한 여러개의 머신러닝 알고리즘을 결합해 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것을 목표로 함
1) 보팅(voting): 여러개의 분류기가 투표를 통해 최종 예측 결과를 결정
알고리즘: 하드보팅, 소프트보팅
2) 배깅(Bagging): Bootstrap Aggregating의 약자로, 보팅(Voting)과는 달리 동일한 알고리즘으로 여러 분류기를 만들어 보팅으로 최종 결정하는 알고리즘
알고리즘: 랜덤포레스트
3) 부스팅(Boosting) : Bagging의 경우 각각의 분류기들이 학습시 상호영향을 주지 않은 상황에서(독립적) 학습이 끝난 다음 결과를 종합하는 기법이라면, Boosting은 여러개의 분류기가 순차적으로 학습을 수행
알고리즘: GBM, xgboost
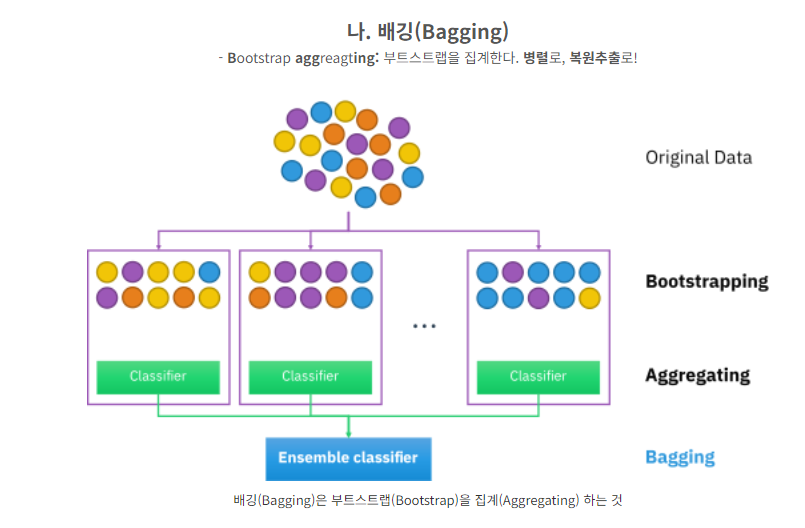
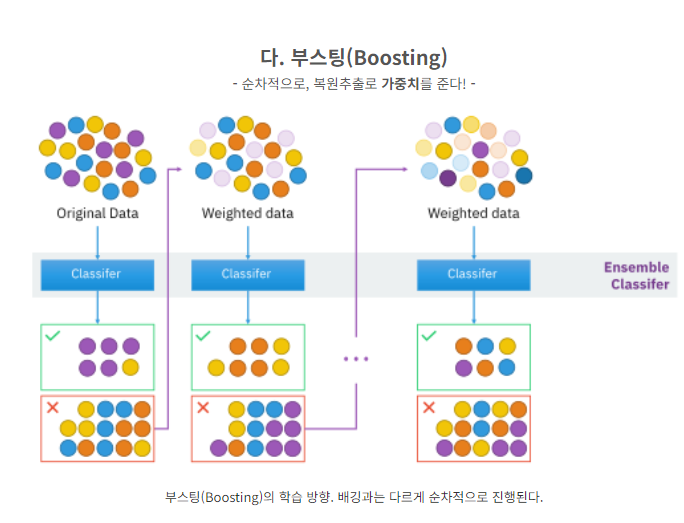
- 부트스트랩 샘플링 : 전체 데이터셋에서 일부 데이터의 중첩을 허용
<실습>
*데이터 전처리 과정은 위와 동일
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(
n_estimators=500,
#결정트리의 갯수를 지정, Default =100, 갯수를 늘리면 성능 좋아지는것 대비 시간이 걸림
max_features=auto
# Default = 'auto' (의사결정트리에서는 default가 none이었음)
max_depth=5,
random_state=0
)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
# 랜덤포레스트 하이퍼파라미터(그외 의사결정트리 파라미터와 동일)
# n_estimators 결정트리의 갯수를 지정, Default =100, 갯수를 늘리면 성능 좋아지는것 대비 시간이 걸림
# max_features=auto Default = 'auto' (의사결정트리에서는 default가 none이었음)
3. xgboost(eXtreme Gradient Boosting)
: 트리기반의 알고리즘 앙상블
<실습>
*데이터 전처리 과정은 위와 동일
from xgboost import XGBClassifier
model = XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss',
booster = 'gbtree',
objective = 'binary:logistic',
max_depth = 5,
learning_rate = 0.05,
n_estimators = 500,
subsample = 1,
colsample_bytree = 1,
n_jobs = -1
# xgboost 하이퍼파라미터
# - booster(기본값 gbtree): 부스팅 알고리즘 (또는 dart, gblinear)
# - objective(기본값 binary:logistic): 이진분류 (다중분류: multi:softmax)
# - max_depth(기본값 6): 최대 한도 깊이
# - learning_rate(기본값 0.1): 학습률
# - n_estimators(기본값 100): 트리의 수, learning_rate를 낮추면 n_estimators 값은 올려줘야함
# - subsample(기본값 1): 훈련 샘플 개수의 비율
# - colsample_bytree(기본값 1): 특성 개수의 비율
# - n_jobs(기본값 1): 사용 코어 수 (-1: 모든 코어를 다 사용)
)
model.fit(X_train, y_train)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
# 조기종료
model = XGBClassifier(random_state=0, use_label_encoder=False, eval_metric='logloss',
learning_rate = 0.05,
n_estimators = 500)
eval_set = [(X_test, y_test)]
model.fit(X_train, y_train, eval_set=eval_set, early_stopping_rounds=10)
pred = model.predict(X_test)
accuracy_score(y_test, pred)
#early_stopping_rounds 파라미터 : 조기 중단을 위한 라운드를 설정
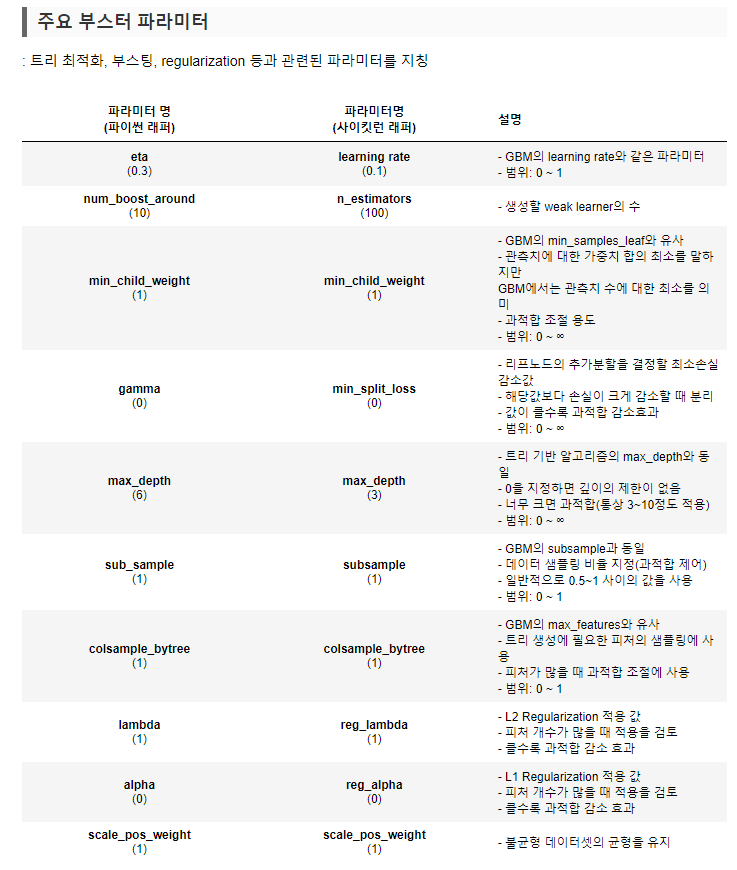

분류 모델별 장단점 정리
| 구분 | 장점 | 단점 |
|---|---|---|
| 의사결정나무 | 장점 | 단점 |
| 랜덤포레스트 | 장점 | 단점 |
| xgboost | 장점 | 단점 |
2. 교차검증 (CV, Cross Validation)
:교차 검증은 train set을 train set + validation set으로 분리한 뒤, validation set을 사용해 검증하는 방식
- 장단점
-
장점:
1) 모든 데이터셋을 훈련에 활용할 수 있다.
-정확도를 향상시킬 수 있다.
-데이터 부족으로 인한 underfitting을 방지할 수 있다.
2) 모든 데이터셋을 평가에 활용할 수 있다.
-평가에 사용되는 데이터 편중을 막을 수 있다.
-평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다. -
단점
1) Iteration 횟수가 많기 때문에, 모델 훈련/평가 시간이 오래 걸린다- 종류
1) K-Fold Cross Validation ( k-겹 교차 검증 )
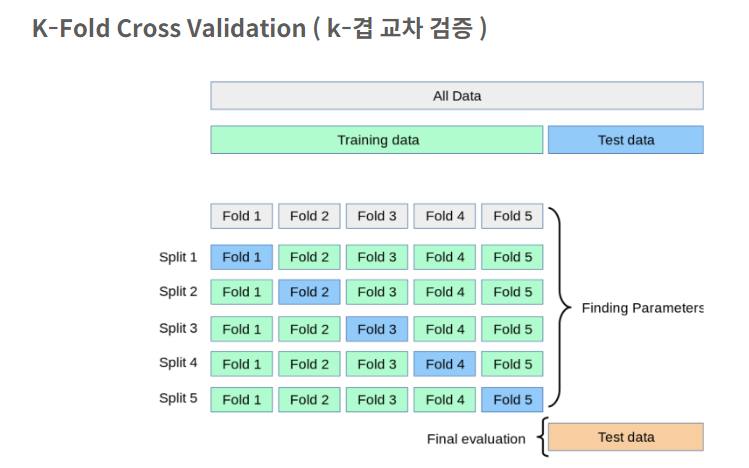
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예시로 load_breast_cancer 데이터셋을 사용
data = load_breast_cancer()
X = data.data
y = data.target
model = DecisionTreeClassifier(random_state=0)
kfold = KFold(n_splits=5) #전체 데이터 셋을 5개로 분할
for train_idx, test_idx in kfold.split(X): #5개로 분할된 데이터셋을 또 분할해서 각각 인자의 인덱스를 받아옴
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y,iloc[train_idx], y,iloc[test_idx]
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(accuracy_score(y_test, pred))
2) Stratified K-Fold Cross Validation ( 계층별 k-겹 교차 검증 )
# StratifiedKfold : 불균형한 타겟 비율을 가진 테이터가 한쪽으로 치우치는 것을 방지
#데이터를 나눌때 y값을 입력해서 확인하면서 데이터를 나눔
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFold #StratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 예시로 load_breast_cancer 데이터셋을 사용
data = load_breast_cancer()
X = data.data
y = data.target
model = DecisionTreeClassifier(random_state=0)
kfold = StratifiedKFold(n_splits=5) #StratifiedKFold
for train_idx, test_idx in kfold.split(X, y):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model.fit(X_train, y_train)
pred = model.predict(X_test)
print(accuracy_score(y_test, pred))
# 사이킷런을 활용하여 Stratified K fold
def make_dataset2():
bc = load_breast_cancer()
df = pd.DataFrame(bc.data, columns=bc.feature_names)
df['target'] = bc.target
return df.drop('target', axis=1), df['target']
X, y = make_dataset2()
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
model = DecisionTreeClassifier(random_state=0)
kfold = StratifiedKFold(n_splits=5)
scores = cross_val_score(model, X, y, cv = 3) # 교차검증 사용함수 cv=3 대신에 cv=kfold 라고 하면 StratifiedKFold로 사용 가능
scores 3. 평가(분류)
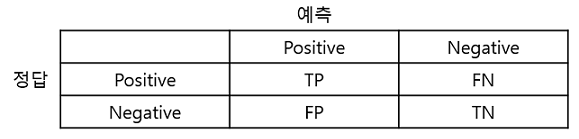
1.Confusion Matrix(혼동 행렬, 오차 행렬)
: 분류 모델(classifier)의 성능을 측정하는 데 자주 사용되는 표로 모델이 두 개의 클래스를 얼마나 헷갈려하는지 알 수 있다.