이번 시간에는 크롤링을 해서 받아온 상품의 리뷰를 이용해, 딥러닝 모델을 통한 분석 결과를 도출하기까지 어떤 과정을 거쳤는지 포스팅하려 한다.
먼저, 리뷰를 분석하기 위해 사용되는 딥러닝 모델과 데이터 처리 함수를 구현한 파일 구조는 다음고 같다.
데이터 전처리
우선 크롤링을 완료하면 데이터들을 DataFrame 형태로 저장하여, make_data.py의 make_final_data 함수로 넘겨준다.
여기서 DataFrame은 Pandas에서 제공하는 행과 열로 이루어진 데이터 객체이다. 엑셀과 구조가 유사하다.
make_final_data함수에서는 먼저 크롤링으로 받아온 데이터들의 전처리가 이루어진다.
total_data = dataframe_limit_string_len(total_data, col_name=col_name,str_len = 400)
total_data = dataframe_clean(total_data,col_name)
total_data = dataframe_make_clean_str_col(total_data,col_name=col_name)
total_data.reset_index(drop=True, inplace=True)
total_data = dataframe_cut(total_data,limit_size)
total_data = dataframe_make_tokenized_col(total_data)
total_data['len'] = total_data['tokenized_data'].apply(len)
max_len = max(total_data['len'])
for i in range(max_len, 0, -1):
if len(total_data.loc[total_data['len']>i]) / len(total_data) >0.95:
max_len = i
break먼저 위와 같이 데이터 전처리가 이루어지는데, dataframe_limit_string_len(),dataframe_make_clean_str_col(), dataframe_cut()와 같은 전처리 관련 함수들은 data_preprocess.py 파일에 선언해 두었다.
모든 함수 내부를 포스팅 하기에는 양이 많으므로, 간단히 전처리 과정만 살펴보도록 하겠다.
(1) dataframe_limit_string_len() : 매개변수로 받아온 길이를 기준으로 일정 글자수가 넘는 리뷰는 삭제하여 준다.(너무 길면 감성 분석이 정확하지 않음)
(2) dataframe_clean(): 결측치 제거
(3) dataframe_make_clean_str_col(): 리뷰에서 특수기호를 모두 제거
(4) dataframe_make_tokenized_col(): 리뷰의 감성을 분석하기 위해 mecab 형태소 분석기를 이용하여 리뷰의 문장을 나누어 형태소 단위로 분리한다.
위 과정을 통해 데이터 전처리 단계가 진행된다. 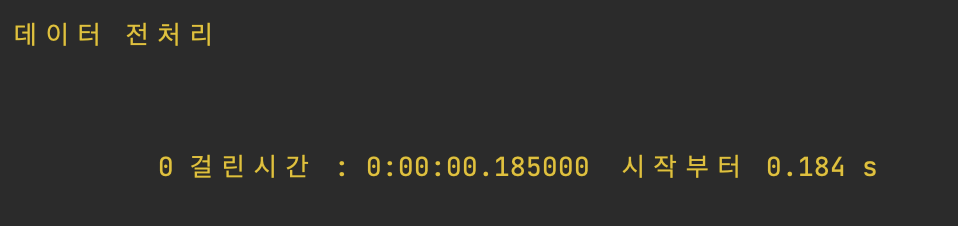
전처리 과정에서 걸리는 시간은 리뷰 250개 기준 0.184초가 나왔다.
형태소 분리기
리뷰로부터의 키워드 추출은 크게 3가지 단계로 나눠진다.
데이터 전처리 -> 키워드 추출 -> 점수평가 및 결과 데이터 가공
이 과정에서 리뷰에 대한 형태소 분석을 통해 문장을 각각의 단어로 나눠주는 역할이 필요하다.
konlpy라이브러리는 이러한 역할을 수행해주는 여러 형태소 분리기를 제공하는데,
Kkma, Komoran, Okt, Mecab이 바로 그것이다.


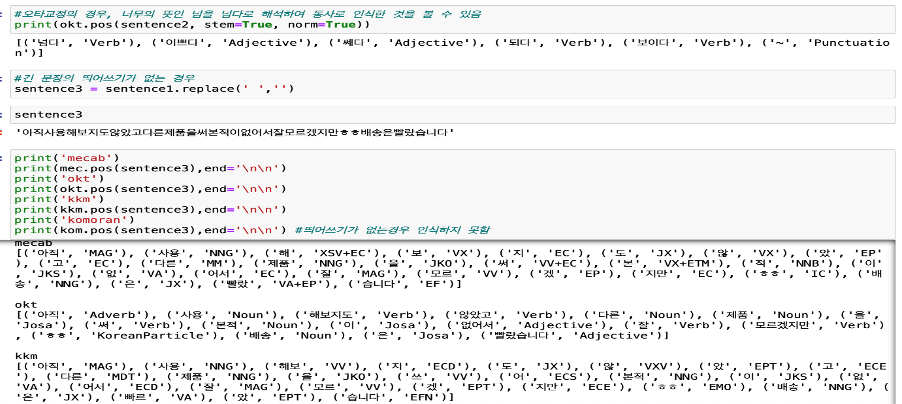
 Mecab은 띄어쓰기가 잘 되지 않고, 오타가 있는 경우에도 무난한 성능을 보였다.
Mecab은 띄어쓰기가 잘 되지 않고, 오타가 있는 경우에도 무난한 성능을 보였다.
Okt는 오타 수정과 형태소 정규화 기능을 제공하나, 명사를 인식하는데 있어 어려움을 보인다.
Kkma는 mecab보다는 아니지만 무난하게 형태소를 분리해 내는 모습을 보여주고, 이것을 일반적인 형태로 바꾸어 출력해주는 역할도 수행한다.
Komoran은 띄어쓰기가 없는 긴 문장에 경우 전혀 인식하지 못하는 모습을 보였고, 오타가 있는 경우에도 형태소를 인식하는데 오류가 많은 모습을 보였다.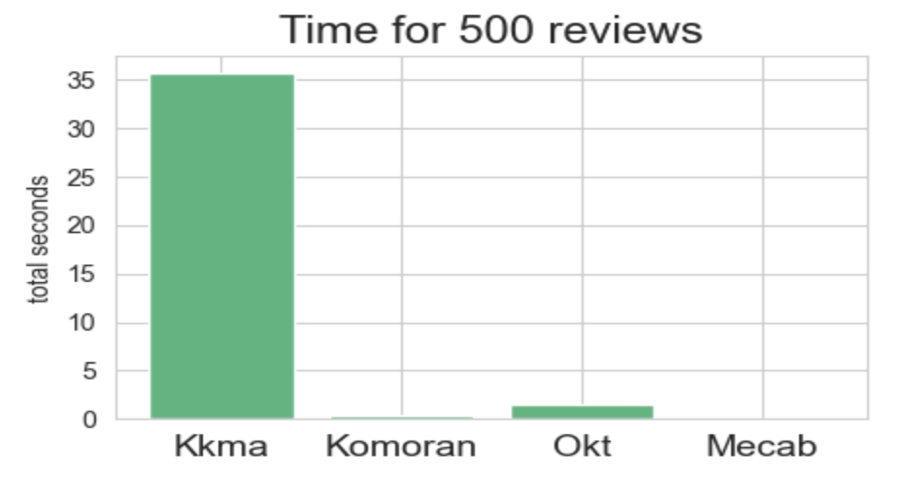
Kkma가 압도적으로 시간이 오래 걸리는 모습을 볼 수 있고, Okt는 시간이 어느정도 걸리는 모습을 보였다. Komoran과 mecab이 가장 빠른 형태소 분리기들이었는데, Komoran은 앞서 언급한 것과 같이 띄어쓰기가 없는 데이터와 오타가 있는 데이터를 다루는데 적합하지 않은 것으로 확인되었고, mecab이 소요시간마저도 더 우위에 있기 때문에 mecab형태소 분리기를 본 프로젝트에 적용하기로 하였다
word2vec 모델
리뷰의 감성을 분석하기 위해 문자 데이터를 벡터화 시켜야하는 작업이 필요하다. 이 또한 형태소 분리와 같이 자주 반복되는 작업 중 한가지 인데, 키워드를 추출하기 위해 단어끼리 유사도를 비교 해야 하고, 학습된 모델에 입력으로 넣기 위해서도 이는 필요한 과정이기 때문이다.
word2vec 모델을 생성하는 과정은 다음과 같다.
def w2v_fintune(tokenized_data):
model_pretrained = gensim.models.Word2Vec.load(os.path.join(Path(__file__).resolve().parent, 'load/only_review.model'))
model_finetuned = Word2Vec(vector_size=200,min_count=0,sg=1)
model_finetuned.build_vocab(tokenized_data)
total_examples = model_finetuned.corpus_count
model_finetuned.build_vocab([list(model_pretrained.wv.key_to_index.keys())], update=True)
model_finetuned.train(tokenized_data, total_examples= total_examples, epochs= 1)
model_finetuned.save(os.path.join(Path(__file__).resolve().parent, 'load/only_review.model'))
return model_finetuned.wv위 코드를 간단히 요약하면, 미리 학습시켜둔 word2vec 모델과 형태소 분석기를 통해 새로 추가된 단어들을 더해 학습시켜 모델을 생성하는 과정이다.
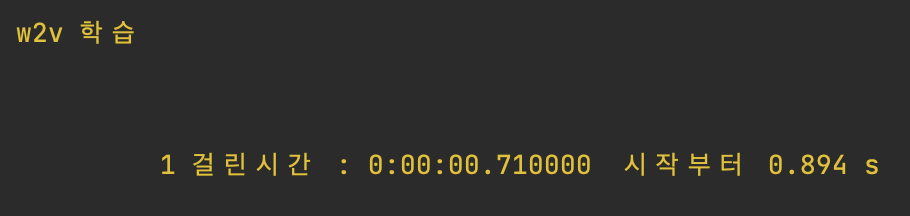
w2v 학습에 걸리는 시간은 리뷰 250개 기준 0.894초가 걸렸다.
워드 임베딩
워드 임베딩 기법에도 여러 종류가 있다. 우리는 그 중 대표적인 word2vector와 fast text 기법을 비교해 보았다.
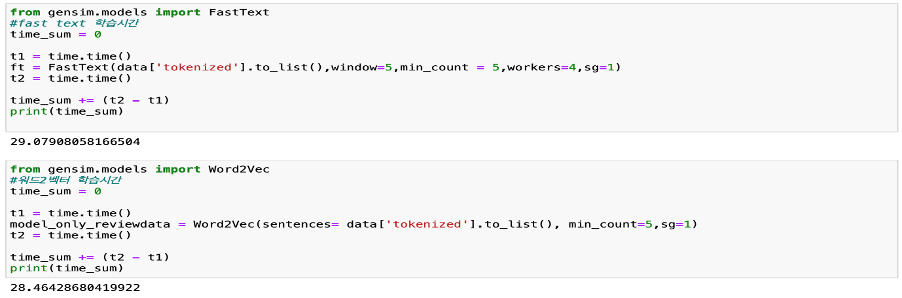 데이터를 학습하는 시간에선 같은 자료(네이버 리뷰 20만개)를 학습함에도 1초의 차이가 나타났다.
데이터를 학습하는 시간에선 같은 자료(네이버 리뷰 20만개)를 학습함에도 1초의 차이가 나타났다.
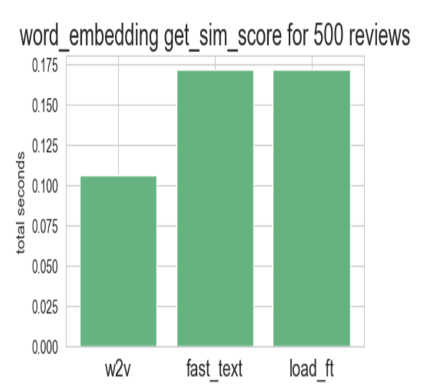 fast_text모델보다 word2vec모델이 훨씬 빠름을 알 수 있다. 이 차이는 word2vec모델에서 학습이되지 않는 단어에 대해서는 임베딩을 진행하지 않기 때문이라고 짐작할 수 있다.
fast_text모델보다 word2vec모델이 훨씬 빠름을 알 수 있다. 이 차이는 word2vec모델에서 학습이되지 않는 단어에 대해서는 임베딩을 진행하지 않기 때문이라고 짐작할 수 있다.
키워드를 선정할 때에는 상품의 이름, 겹치는 단어 그리고 의미 없는 단어 등에 대해서는 무시할 예정이다. 애초에 word2vec에 학습에 무시될 단어는 보지 않는 단어에 속한다. 그러므로 필요 없는 단어에 대해 연산을 수행하기보다 속도적으로 이익인 word2vec모델을 본 프로젝트에서 사용하기로 했다.
이번 포스팅에서는 데이터 전처리 관련 과정에 대해서 알아보았다.
다음 시간에는 전처리까지 완료된 리뷰 데이터로부터 키워드를 추출하는 과정을 알아보도록 하겠다.
