이번에는 전처리가 완료된 리뷰 데이터를 통해서, 상품 리뷰의 키워드를 추출하고, 리뷰의 감성을 분석하여 키워드 별 만족도를 계산하는 과정에 대해서 알아보도록 하겠다.
키워드 추출
키워드를 추출하기 전에 먼저, 리뷰 세트마다 tf-idf를 적용하여 단어별 중요도를 뽑아야 한다.
tf-idf란 단어의 빈도와 역 문서 빈도를 사용하여 단어들마다 중요한 정도에 따라서 가중치를 부여하는 방법이다.
tfidfv = TfidfVectorizer(stop_words=stopwords, tokenizer=mecab_tokenizer, \
ngram_range=(1, 3), min_df=3, sublinear_tf=True)
tfidf = tfidfv.fit_transform(data_frame[col])
word2id = dict()
for idx, feature in enumerate(tfidfv.get_feature_names()):
word2id[feature] = idx위 과정을 통해 단어별 중요도를 구할 수 있다.
다음으로 키워드를 추출한다.
너무나 고맙게도 KRWordRank 라는 한국어 키워드 추출기를 사용해서 쉽게 키워드를 추출할 수 있었다.
entire_txt = data_frame[col].apply(normalize)
min_count = 3
max_length = 10
wordrank_extractor = KRWordRank(min_count, max_length)
beta = 0.85 # PageRank의 decaying factor beta
max_iter = 10
keywords, rank, graph = wordrank_extractor.extract(entire_txt, beta, max_iter)위와 같이 키워드가 될 단어의 길이를 설정한 후 KRWordRank를 이용해 키워드를 추출할 수 있었다.
이렇게 뽑힌 키워드를 또다시 걸러내야 하는데, 이번에는 아까 tf-idf로 얻었던 단어의 중요도를 이용할 것이다.
for i in range(len(entire_txt)):
for w,r in sorted(keywords.items(), key=lambda x: x[1], reverse=True):
if w in word2id and w in wv:
if tfidf[i, word2id[w]] > _IMPORTANCE_ and mecab_pos(w)[0][1] in get_words:
keyword[w] = 0위 코드는 미리 지정한 단어의 중요도(0.2)에 따라 키워드를 걸러내는 과정이다.
그리고 이렇게 걸러진 키워드 중 또 다시 필요없는 단어를 제거해 주었다. 제거하려는 키워드는 Word2Vec에 포함되지 않은 단어, 불용어, 상품 이름이 포함된 단어이다.
원래는 상품 이름이 포함된 단어를 제거하지 않았는데, 키워드 추출을 테스트 해보니 자꾸 상품 이름이 키워드로 뽑혔기 때문에 제거해주었다. 예를 들어 상품이름이 "살림백서 실내건조 일반용 세탁세제 본품"이라고 하면, "역시 살림백서 좋아요"와 같은 리뷰가 너무 많았기 때문에 자꾸 키워드로 뽑혔다. 그래서 상품 이름에 해당되는 단어는 제거해 주었다.
키워드 만족도 계산
추출된 키워드의 만족도 계산에 대한 설명은 다음과 같다.
• GRU모델을 통해 리뷰 데이터에 대한 감성 분석 (감성 분석 1회 실행 시 소요시간 약 0.2초)
• 코사인 유사도가 0.9이상인 단어에 대해서도 해당 키워드에 대한 만족도에 반영
• 키워드 만족도 = 해당 키워드에 대한 모든 리뷰 점수의 합 / 해당 키워드 빈도수
리뷰에 대한 감성 분석은 GRU 모델을 사용했다. 깃허브에서 얻어온 네이버 영화 리뷰 20만건과 네이버 쇼핑몰 리뷰데이터 20만건의 데이터셋을 학습시킨 감성분석 모델을 생성하였다.
이 모델을 통해 리뷰에 대한 감성분석을 실행한다.
#GRU Model을 이용해서
#새로 들어온 문장에 대해서 데이터 전처리 이후
#0~1사이의 예측값(1: 긍정 0: 부정)을 100을 곱해 반환
def get_sentence_score(new_sentence, max_len = 80):
sentence = tok_concat_str(new_sentence)
if len(sentence) ==0:
return -999
encoded = GRU_tokenizer.texts_to_sequences([sentence])
pad_new = pad_sequences(encoded, maxlen = max_len)
score = float(GRU_model.predict(pad_new, verbose= 0))
return score * 100이 함수를 통해 리뷰마다 감성 분석을 진행한다.
점수 측정은 키워드가 포함된 리뷰, 키워드가 포함되지 않은 리뷰로 나누어서 측정한다. 키워드가 포함되지 않은 리뷰에 대한 점수는 상품에 대한 종합점수 측정인 "AI Score"에 반영된다.
for w in keyword_list:
keyword_score_sum[w] = ret_sentence_keyword[w].sum()
keyword_freq[w] = len(ret_sentence_keyword[ret_sentence_keyword[w] != 0].index)
if keyword_freq[w] == 0:
del keyword_freq[w]
del keyword_score_sum[w]
del ret_sentence_keyword[w]
else:
keyword_score[w] = keyword_score_sum[w] / keyword_freq[w]
if keyword_score[w] > 100:
keyword_score[w] = 100이렇게 측정된 각 키워드가 포함된 문장의 점수의 합을 키워드가 포함된 문장의 빈도수로 나누어 키워드 만족도를 계산해 준다.
키워드가 포함되지 않은 리뷰들은 "_etc"라는 키워드로 지정하여 따로 만족도를 계산해 둔다.
또한, 측정된 키워드 만족도와 가장 비슷한 만족도를 가진 예시 리뷰 하나도 저장하여 둔다.
이렇게 리뷰 감성을 통한 키워드 별 만족도를 데이터프레임으로 생성하여 넘겨준 후, db에 저장한다.
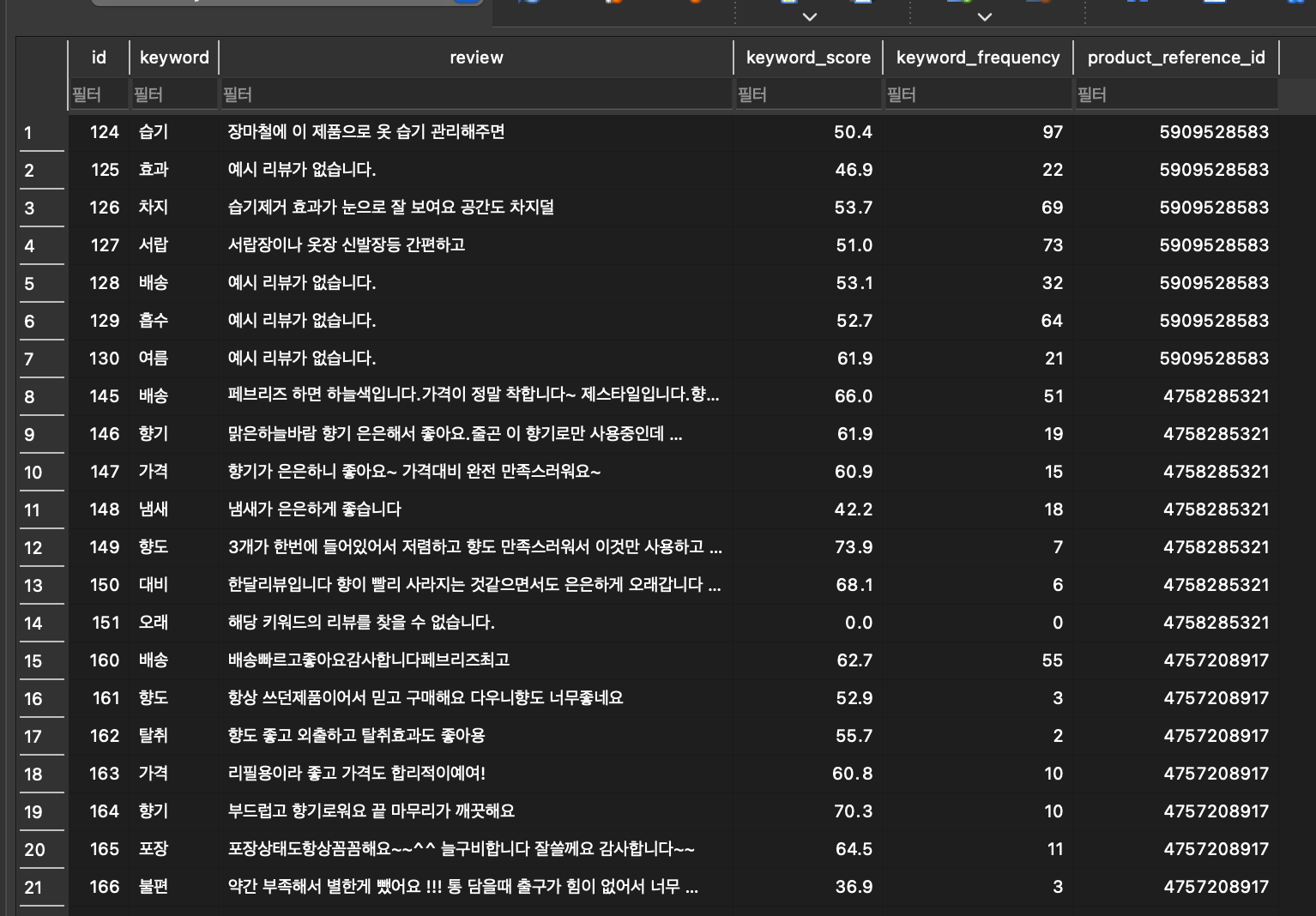
위는 키워드별 만족도가 저장된 테이블의 데이터 일부이다.
리뷰 250개 기준 22.22초가 소요되었다. 감성 분석 1회당 시간이 많이 소요되기 때문에, 많은 수의 리뷰를 참고하는 것은 무리가 있었다.
감성 분석에 소요되는 시간을 줄이는 모델을 분명 만들 수 있을 테지만, 아직 우리 능력으로는 해결할 수가 없었다..
감성 분석 모델
우리의 목표는 사용자가 리뷰 분석을 요청했을 때 최대한 빠르게 결과를 제공하는 것이 우선순위 였기 때문에, 여러 인공지능 모델의 성능과 속도를 측정하여 비교해 볼 필요가 있었다.
자연어 처리 모델 중 순차적 모델이 앞뒤 문맥을 최소한 파악하므로 이 중에서 간단한 모델 2가지 LSTM모델과 이를 경량화한 GRU모델을 비교해보았다.
속도에 민감하기 때문에 경량화한 GRU를 섣불리 고를 수도 있었지만, 정확도가 낮다면 의미가 많이 퇴색되기 때문에 너무 낮은 정확도는 피하고, 속도 비교는 직접 해봐야한다고 생각하기 때문에 실험을 진행했다.
실험은
(1)GRU 모델- 옵티마이저로 Adam, active function으로 sigmoid 함수 적용
(2)GRU 모델- 옵티마이저로 Adam, active function으로 relu함수 적용
(3)LSTM 모델- 옵티마이저로 Adam, active function으로 sigmoid 함수 적용
(4)LSTM 모델- 옵티마이저로 Adam, active function으로 relu함수 적용
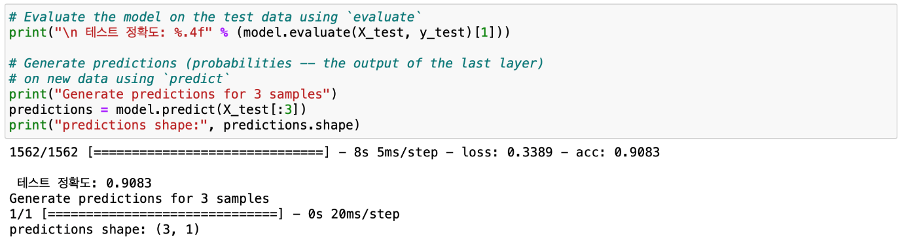
결과적으로 (1)번 실험이 성능도 준수하고 속도 또한 가장 빨랐기 때문에 프로젝트에 적용되었다.
이번 시간에는 전처리된 데이터를 통한 리뷰의 키워드 추출과 GRU 모델을 이용한 리뷰의 감성 분석 과정에 대해 살펴보았다.
다음은 최종 결과물과 프로젝트 후기에 대한 포스팅을 하겠다.
