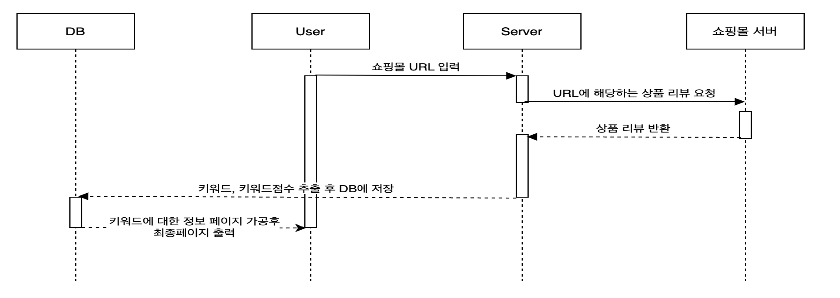
사용자로부터 상품 페이지 url을 입력받아 결과를 출력하는 과정은 다음과 같다.
(1) 상품 페이지 URL이 입력으로 들어옴 -> 해당 리뷰 페이지 크롤링 -> 상품 리뷰, 정보 등 추출
(2) 상품정보와 리뷰를 이용하여 키워드 추출
(3) 키워드별 만족도 계산
(4) 키워드별 만족도를 기반으로 실제 리뷰 추출
(5) AI score 계산 = (해당 키워드 만족도*키워드 리뷰 수/모든 키워드 리뷰 수…모든 키워드에 대해 계산하여 더해줌} /100
(6) DB에 결과(키워드, 만족도, AI Score 등)를 저장하여 사용자에게 웹페이지 전달
(4)번까지 저번 포스팅에서 살펴보았고, 이번 포스팅에서는 (5),(6)번의 과정과 프로젝트 후기를 남기려 한다.
AI Score 계산
# 해당 상품의 키워드 처리
for keyword in ProductKeyword.objects.filter(product_reference_id= product_num):
score=keyword.keyword_score
frequency=keyword.keyword_frequency
name=keyword.keyword
whole_review+=frequency
#AI score 계산 ('_etc'포함하여 계산)
ai_score+=score*frequency
#키워드 이름이 '_etc'(키워드가 포함되지 않은 리뷰들)에 대해서는 처리하지 않음
if name =='_etc':
continue
#만족도가 50이 넘으면 긍정키워드, 글엏지 않으면 부정키워드로 구분
if score > 50 :
pos_keyword.append(keyword)
elif score < 50 :
neg_keyword.append(keyword)
keywords[name] = frequency #워드클라우드를 만들기 위한 딕셔너리
result_keyword.append(keyword) #보여줄 키워드를 제한하기 위해 새로 만든 리스트
result_keyword_cnt+=1
ai_score/=whole_review
ai_score=round(ai_score,1)
product.product_score=ai_score
product.save()
make_wordcloud(keywords, str(product_num))AI Score은 상품의 종합 점수이다. 이 점수는 모든 리뷰의 감성 점수의 평균 이라고 볼 수 있다. Ai Score을 계산할 때에는 키워드가 포함되지 않은 문장의 감성 점수도 포함 한다. 하지만, 결과 화면에 출력될 키워드에는 포함되지 않는다.
그리고 워드 클라우드를 생성하는데, 워드 클라우드란 단어의 빈도수를 시각화 한 것이다. wordcloud 라이브러리를 이용하면 단어의 이름과 빈도수가 담긴 딕셔너리를 통해 쉽게 이미지를 생성할 수 있다.
pos_keyword.sort(key=lambda x: x.keyword_score,reverse=True)
neg_keyword.sort(key=lambda x: x.keyword_score)
context = {
"product": product,
"neg_keyword": neg_keyword[:3],
"neg_keyword_cnt": len(neg_keyword[:3]),
"pos_keyword": pos_keyword[:3],
"pos_keyword_cnt": len(pos_keyword[:3]),
"result_keyword":result_keyword[:(result_keyword_cnt//2)],
"result_keyword_cnt":result_keyword_cnt//2
}결과 화면에 보낼 정보에는 결과적으로 뽑힌 키워드의 절반만 보내준다.(키워드가 너무 많으면 보기에도 안좋고 나온 빈도수가 적은 키워드도 보여지기 때문이다.)
또한, 긍정키워드(만족도가 50이 넘는 키워드), 부정키워드(만족도가 50을 넘지 못하는 키워드) 각각 세가지씩 보내준다.
위 리스트들은 만족도 순으로 정렬되어 순위로 나타난다. 위는 상품테이블 데이터의 일부분이다.
위는 상품테이블 데이터의 일부분이다.
결과 페이지
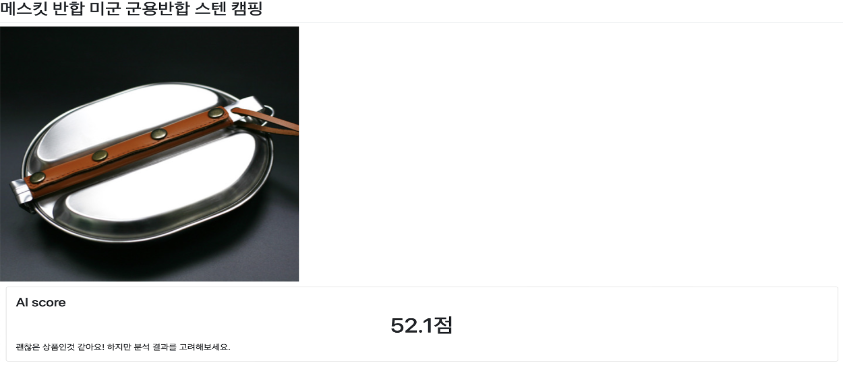

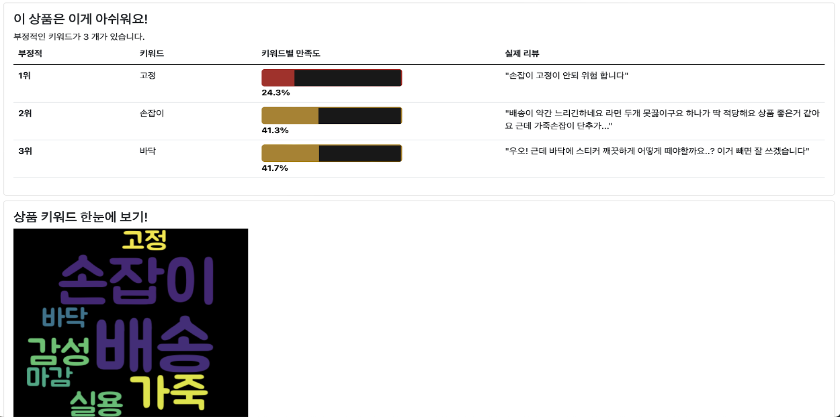
웹 페이지에 상품 페이지 주소를 입력하면 최종적으로 위와 같은 결과 페이지가 나타난다.
상품의 종합 점수를 나타내는 AI Score과 점수에 따른 코멘트, 주요 키워드, 긍정적인 부분, 부정적인 부분, 리뷰 클라우드를 보여준다.
프론트 부분은 많이 신경쓰지 않았기 때문에 부족함이 많지만, 나름대로 깔끔하게 잘 나온것 같다.
정말 많은 상품에 대해 테스트를 해보았다. 대체적으로 상품 평점이 높을수록 AI Score도 높게 나타나는 것을 확인할 수 있었다.
일단 결과물은 나왔지만, 이게 얼마나 정확한지 확인을 하기에는 어려움이 있었다. Ai Score은 Ai가 판단한 리뷰의 감성을 기준으로 한 것이다. Ai가 리뷰마다 측정한 감성 점수를 하나하나 다 확인해 보는것도 너무 오래걸리고, 그 감성 점수 또한 정답이 없기 때문에 대충 내가 판단한 것과 맞는지 정도밖에 확인할 수 없었다.
이러한 부분이 참 애매했다. 하지만 사전에 GRU 모델을 생성하면서 한문장 한문장 입력하는 과정을 통해 대체적으로 정확하다고 느꼈기 때문에, 이 결과도 어느정도 정확할 것이라고 생각한다.
후기
캡스톤 디자인 과목에서 한 학기간 완성한 프로젝트의 결과가 고작 위의 페이지 한 장 뿐이라는게 뭔가 허탈하게 느껴졌다.
프로젝트를 진행하면서 정말 너무너무 어렵고 머리 아팠다.
주제도 사실 처음에는 리뷰 분석이 아니었다.
처음에는 주변 풍경에 어울리는 음악을 틀어주는 웹을 목표로 했었는데, 인공지능을 처음 활용하는 우리에게는 너무 어려운 주제였다.
그리고 상품 리뷰 분석도 사실은 크롬 확장 프로그램을 통한 동작을 목표로 했었다. 하지만 크롬 확장 프로그램을 만드려면 또 프론트 분야(javascript,react 등)에 대해서도 공부해야 했기 때문에, 시간 관계상 웹으로 동작하는 서비스로 방향을 바꾸었다.
사실 장고나 파이썬에 익숙하지 않은것은 힘든 일도 아니었다.
딥러닝을 활용하여 결과물을 만든다는 것이 진짜 너무 어려웠다.
나는 사실 인공지능에 별로 관심이 없었다. 그래서 우리 캡스톤 과목의 주제가 딥러닝 인것도 마음에 안들었었다.
그런데 하면 할수록 인공지능을 활용하지 않으면 현재 시장에서 경쟁력있는 소프트웨어를 만들기가 어렵겠다는 생각이 들었다.
다음 4-1 학기에도 캡스톤과목이 있다. 주제에 대해서는 이번에 했던 주제를 더 깊이있게 진행해도 되고, 새로운 주제를 진행해도 된다고 한다. 다만 딥러닝을 사용해야 한다.
나는 아마 새로운 주제로 다시 시작할 것 같다.
이번 캡스톤 과목에서는 주제를 선정하는데에 꽤 시간을 많이 잡아먹었기 때문에 미리미리 생각좀 해두어야겠다.
그래도 이번에 자연어처리를 해보면서 조금은 딥러닝에 대해 공부가 되었기 때문에 다음에는 좀 더 수월하게 진행할 수 있을것이라 생각한다.
