
📍 바이트 저장 순서
컴퓨터는 데이터를 메모리에 저장할 때 Byte 단위로 나눠서 저장한다. 따라서 연속되는 바이트를 순서대로 저장해야하는데, 이것을 바이트 저장 순서(Byte Order)라고 한다. 이때 바이트가 저장된 순서에 따라 빅 엔디안, 리틀 엔디안 두가지 방식으로 나눌 수 있다.
📍 빅 엔디안(Big Endian)
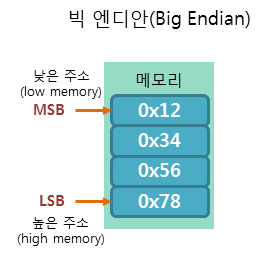
- 빅엔디안 방식은 가장 높은 유효 바이트(MSB, Most Significant Byte)를 가장 낮은 메모리 주소에 저장
- 즉, 데이터의 상위 바이트가 낮은 메모리 주소에 위치하고, 하위 바이트가 높은 메모리 주소에 위치하는 방식
- ex. 4바이트 데이터 '0x12345678'이 있다면 메모리에는 순서대로 '12 34 56 78'로 저장
- SPARC 아키텍처, IBM의 일부 시스템 등에서 사용
- 빅 엔디안을 적용하는 대표적인 CPU는 Sparc
📍 리틀 엔디안(Little Endian)
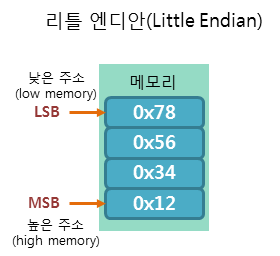
- 리틀엔디안 방식은 가장 낮은 유효 바이트(LSB, Least Significant Byte)를 가장 낮은 메모리 주소에 저장
- 즉, 데이터의 하위 바이트가 낮은 메모리 주소에 위치하고, 상위 바이트가 높은 메모리 주소에 위치하는 방식
- ex. 4바이트 데이터 '0x12345678'이 있다면 메모리에는 순서대로 '78 56 34 12'로 저장
- 대다수의 x86 계열 프로세서와 일부 ARM 프로세서에서 사용
- 리틀 엔디안을 적용하는 대표적인 CPU는 Intel
LSB(Least Significant Bit, 가장 낮은 유효바이트)이진수에서 가장 오른쪽에 있는 바이트를 나타낸다.
이진수는 0과 1로 구성된 숫자 체계를 사용하며, LSB는 이진수의 가장 작은 자리 수로서 데이터의 가장 낮은 값을 나타낸다.
📖 정리
컴퓨터 CPU의 데이터를 저장할때
상위 바이트 즉, 큰 쪽을 먼저 저장하는 것을 빅 엔디안(Big Endian)
하위 바이트 즉, 작은 쪽을 먼저 저장하는 것을 리틀 엔디안(Little Endian)같은 엔디안 사이에서의 통신은 문제가 되지 않지만, 다른 방식의 엔디안 사이에서 통신을 하면 문제가 발생한다.
이러한 문제를 방지하기 위해 네트워크에서는 빅 엔디안으로 통일하도록
되어있다.
📍 리틀 엔디안 ↔ 빅 엔디안 변환
바이트의 순서를 역순으로 조정하면 된다!
📖 변환방법
① 바이트 배열로 변환 : 데이터를 바이트 배열로 변환한다. 이 과정에서 바이트배열의 인덱스를 사용하여 데이터를 접근
② 바이트 배열의 순서 변경 : (C#에서는) 리틀엔디안에서는 바이트 배열의 순서를 그대로 사용하고, 빅엔디안에서는 바이트배열을 거꾸로 사용한다.(상황에 맞게 배열)
③ 바이트 배열을 다시 데이터 타입으로 변환 : 바이트 배열을 다시 필요한 데이터 타입(정수, 부동소수점 등)으로 변환
📁 코드에서 변환방법
- 빅 엔디안(Big-Endian) 변환 함수
- htos(host to network short) : 16비트 수량을 리틀 엔디안에서 빅 엔디안으로 변환
- htonl(host to network long) : 32비트 수량을 리틀 엔디안에서 빅 엔디안으로 변환
- 리틀 엔디안(Little-Endian) 변환 함수
- ntohs(network to host short) : 16비트 수량을 빅 엔디안에서 리틀 엔디안으로 변환
- ntohl(network to host long) : 32비트 수량을 빅 엔디안에서 리틀 엔디안으로 변환

언어는 거들 뿐...