TinyBERT : Distilling BERT for Natural Language Understanding
TinyBERT: Distilling BERT for Natural Language Understanding
-
참고한 논문 정리 블로그
📃 TinyBERT: Distilling BERT For Natual Language Understanding 리뷰
[논문리뷰] Tinybert: Distilling bert for natural language understanding
TinyBERT Overview
[세 가지 Loss 사용]
Transformer distillation에서 세 가지 loss 함수를 적용하여 다음의 representation을 학습
1) 임베딩 레이어의 아웃풋
2) Transformer layer에 있는 히든 벡터와 어텐션 행렬
: Teacher BERT가 학습한 attention weight는 언어학적인 지식을 포함
이 지식은 구문이나 상호참조 정보 등 NLU에 필수적인 정보들을 포함함
3) 예측 레이어의 아웃풋 로짓
[두 단계의 distillation 진행]
1) general distillation
: TinyBERT는 선생님의 행동을 모사하게 되고, 그 결과 general TinyBERT를 얻을 수 있음
2) task-specific distillation
: Step 1에서 얻은 general 모델을 시작점으로 하여
-
Data augmentation
-
augment된 데이터셋에 대해 fine-tuning 하는 단계를 거쳐 좋은 모델을 얻음
[결과]
-
4개 층으로 이루어진 TinyBERT 모델은 GLUE 벤치마크에서 BERT_base의 96.8% 성능 유지
-
이는 BERT_base보다 7.5배 작고 9.4배 빠른 모델
-
6개 층으로 이루어진 TinyBERT 모델의 경우 Teacher 모델에서 성능 감소가 없었음
- TinyBERT 4의 경우, 4 레이어를 사용한 다른 경량화 모델 대비 속도가 빠르면서 성능이 가장 유지된다.
- 6개 레이어를 사용한 TinyBERT 6의 경우, 파라미터가 40%감소 & 속도가 2배 빨라지면서도 BERT_base 성능을 유지한다.
TinyBERT는 Transformer Distillation을 사전학습과 태스크 특화된 fine-tuning 단계에서 둘 다 진행하여 BERT에 있는 general domain의 지식 뿐만 아니라 task-specific 지식까지 학습 가능
TinyBERT in Detail
1. Three-types of loss functions
→ Three New Transformer Distillation method
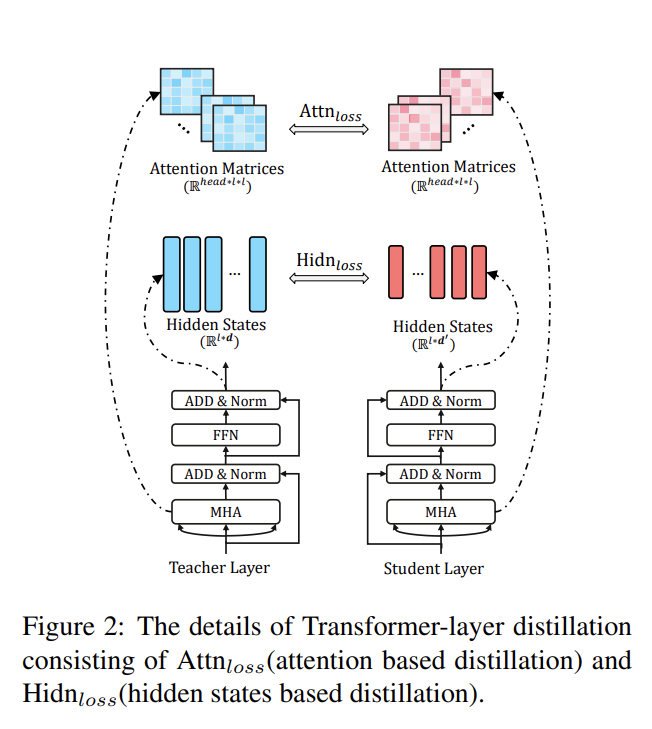
Problem Formulation
-
Teacher가 N개의 Transformer Layer
-
Student가 M개의 Transformer Layer
→ N과 M은 N>M으로 다르기 때문에 N에서 적절한 M개의 Layer를 선택하는
N=g(M)의 함수g를 잘 선정할 필요가 있음→
0 = g(0),N+1 = g(M+1) -
Student model에서 embedding Layer index는 0, prediction Layer는 M+1이 됨
-
Distillation은 아래식을 최소화
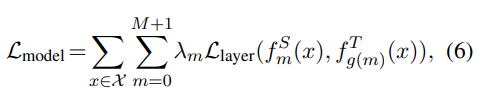
-
은 해당 모델 레이어에 대한 loss (예. Transformer레이어 / 임베딩 레이어)
-
는 m번째 레이어의 행동함수 (행동함수 : student가 teacher network의 행동을 묘사할 수 있도록 하는 함수)
-
은 m번째 레이어 distillation의 중요도를 나타내는 가중치
-
Three types of Loss
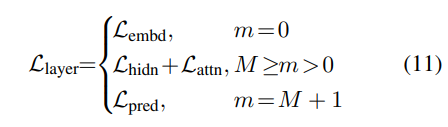
1) Transformer-layer distillation
- attention based distillation
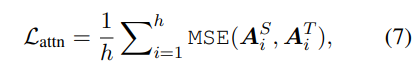
- hidden states based distillation
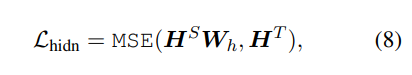
→ capture rich linguistic knowledge (cf. syntax, coreference information)
2) Embedding-layer distillation
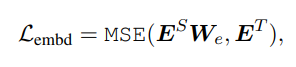
3) Prediction-layer distillation
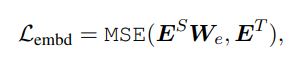
- teacher/student 모델의 로짓에 대해 soft cross-entropy loss를 사용
t= temperature value (t=1사용)
2. Two-stage learning
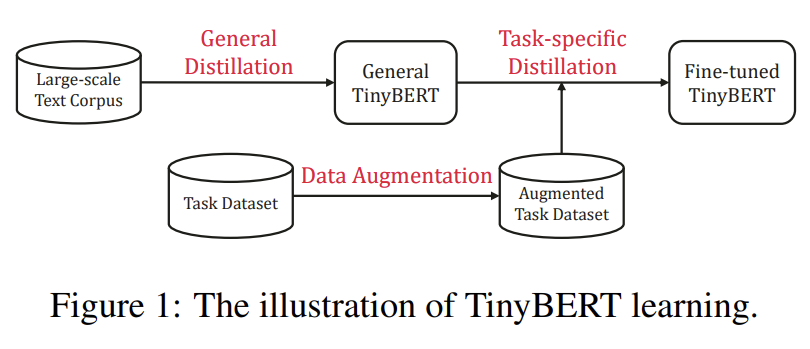
1) First stage = General Distillation Stage
- Teacher : original BERT without fine-tuning
- Student : general TinyBERT
- used as the initializeation of student model for the further distillation
- Pre-trained BERT로부터 rich-knowledge embedded 학습하여 일반화의 성능 높임
- Transformer distillation method 중, prediction layer distillation은 downstream task 수행에 있어 별다른 성능 향상이 없어 사용하지 않음
2) Second stage = Task-specific Distillation Stage
-
re-perform the proposed Transformer distilation on an augmented task-specific dataset
-
Teacher : fine-tuned BERT
-
Student : TinyBERT
-
augmented dataset을 활용하여 distillation 진행
-
어떤 token을 다음 두 가지 방법으로 구해진 token으로 대체하여 augmentation 수행
1) masking을 하고 BERT로 예측된 token
2) Glove의 embedding에서 유사한 token
-
Appendix
1) tiny bert model을 M=4, d=312, intermeidate_size=1200, h=12로 잡아서 진행
2) N개의 teacher layer에서 M개의 student Layer를 뽑는 방식의 함수인 N=g(M)으로, g(M)=3xM 을 사용 (TinyBERT4 learns from every 3 layers of BERT_BASE)
