MRC vs ODQA
- MRC: 지문이 주어진 상황에서 질의응답
- ODQA: 지문이 따로 주어지지 않으며, 방대한 World Knowledge에 기반해서 질의응답
Retriever-Reader Approach
- Retriever-Reader 접근 방식
- Retriever: 데이터베이스에서 관련있는 문서를 검색(search)
- 입력: 문서셋과 질문(Document corpus, query)
- 출력: 관련성 높은 문서(Document)
- Reader: 검색된 문서에서 질문에 해당하는 답을 찾아냄
- 입력: 문서와 질문 쌍(Retrievered document, query)
- 출력: 답변(Answer)
- Retriever: 데이터베이스에서 관련있는 문서를 검색(search)
- 학습 단계
- Retriever
- Sparse Embedding(TF-IDF, BM25) → 학습 없음
- Dense Embedding → 학습 있음
- Reader
- SQuAD와 같은 MRC 데이터셋으로 학습
- 학습데이터를 추가하기 위해서 Distant supervision 활용
- Distant supervision?
- MRC 데이터셋은 질문-답변과 함께 context도 주어지나, 일반적으로는 질문에 대한 답이 어느 지문에 있는지 알지 못함
- 질문-답변만 있는 데이터셋(CuratedTREC, WebQuestions, WikiMovies)에서 MRC 학습 데이터 만들기
- 위키피디아에서 Retriever를 이용해 관련성 높은 문서를 검색
- 너무 짧거나 긴 문서,질문의 고유명사를 포함하지 않는 등 부적합한 문서 제거
- answer가 exact match로 들어있지 않은 문서 제거
- 남은 문서 중에 질문과 연관성이 가장 높은 단락을 supporting evidence로 사용
- Retriever
- Inference
- Retriever가 질문과 가장 관련성 높은 k개 문서 출력
- Reader는 k개 문서를 읽고 답변 예측
- Reader가 예측한 답변 중 가장 score가 높은 것을 최종 답으로 사용
Issues & Recent Approaches
- Different granularities of text at indexing time
- 위키피디아에서 각 Passage의 단위를 문서, 단락, 또는 문장으로 정의할지 정해야 함
- Retriever 단계에서 몇 개(top-k)의 문서를 넘길지 정해야 함
- Granularity(단위)에 따라 k가 다를 수 밖에 없음
- e.g. article → k=5, paragraph → k=29, sentence → k=78
- Single-passage training vs Multi-passage training
- Single-passage: 현재 우리는 k개의 passage들을 reader가 각각 확인하고 특정 answer span에 대한 예측 점수를 나타내면 가장 높은 점수를 가진 answer span을 고르도록 함
- 이 경우 각 retrieved passage들에 대한 직접적인 비교라고 볼 수 없음
- reader 모델이 passage들을 따로 보는 게 아니라 전체를 한번에 보면 어떨까?
- Multi-passage: retrieved passages 전체를 하나의 passage로 취급하고, reader 모델이 그 안에서 answer span 하나를 찾도록 함
- 문서가 너무 길어지므로 GPU에 더 많은 메모리를 할당, 처리해야 하는 연산량이 많아짐
- Single-passage: 현재 우리는 k개의 passage들을 reader가 각각 확인하고 특정 answer span에 대한 예측 점수를 나타내면 가장 높은 점수를 가진 answer span을 고르도록 함
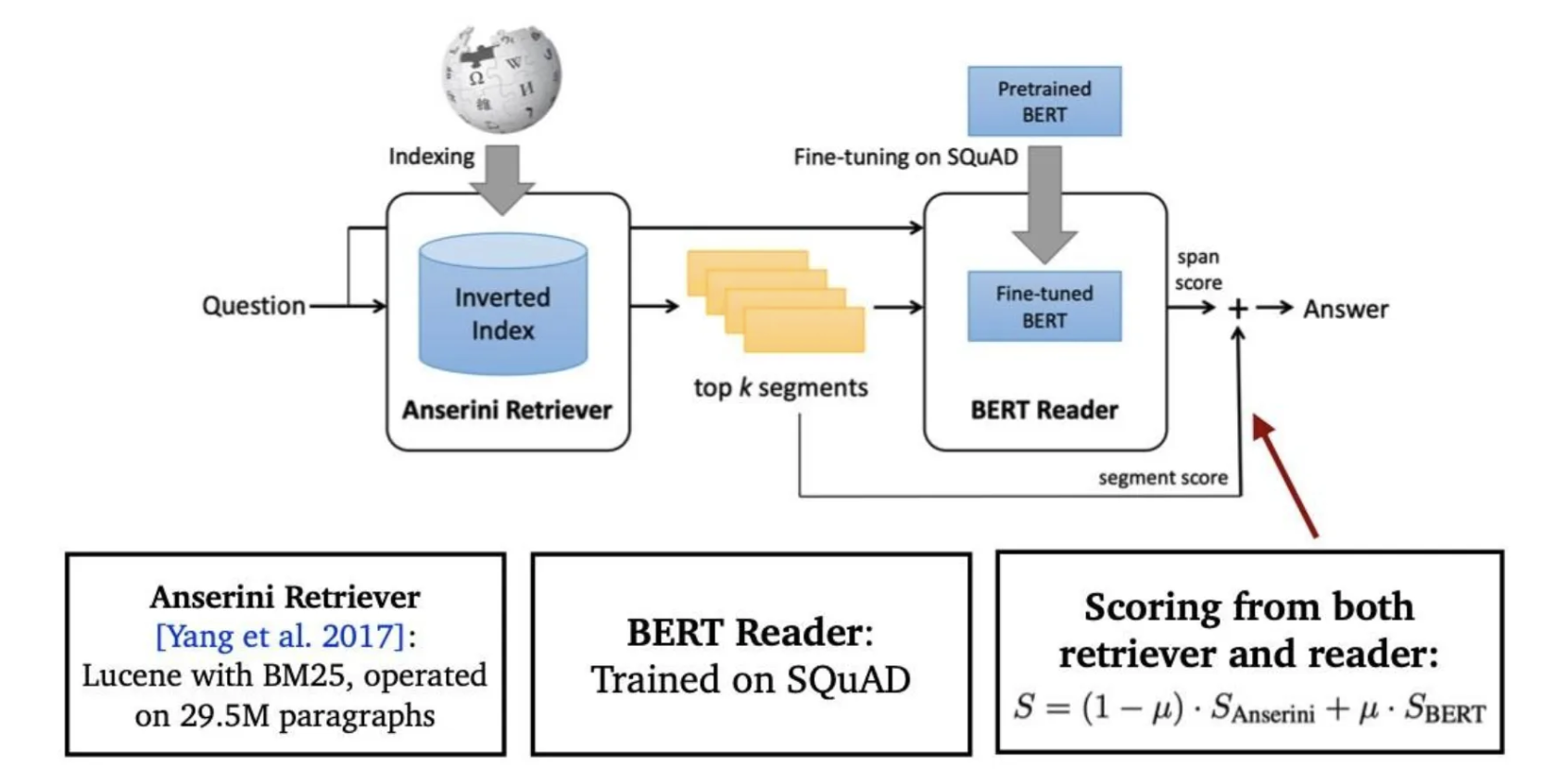
- Importance of each passage
- Retriever 모델에서 추출된 top-k passage들의 retrieval score를 reader 모델에 전달
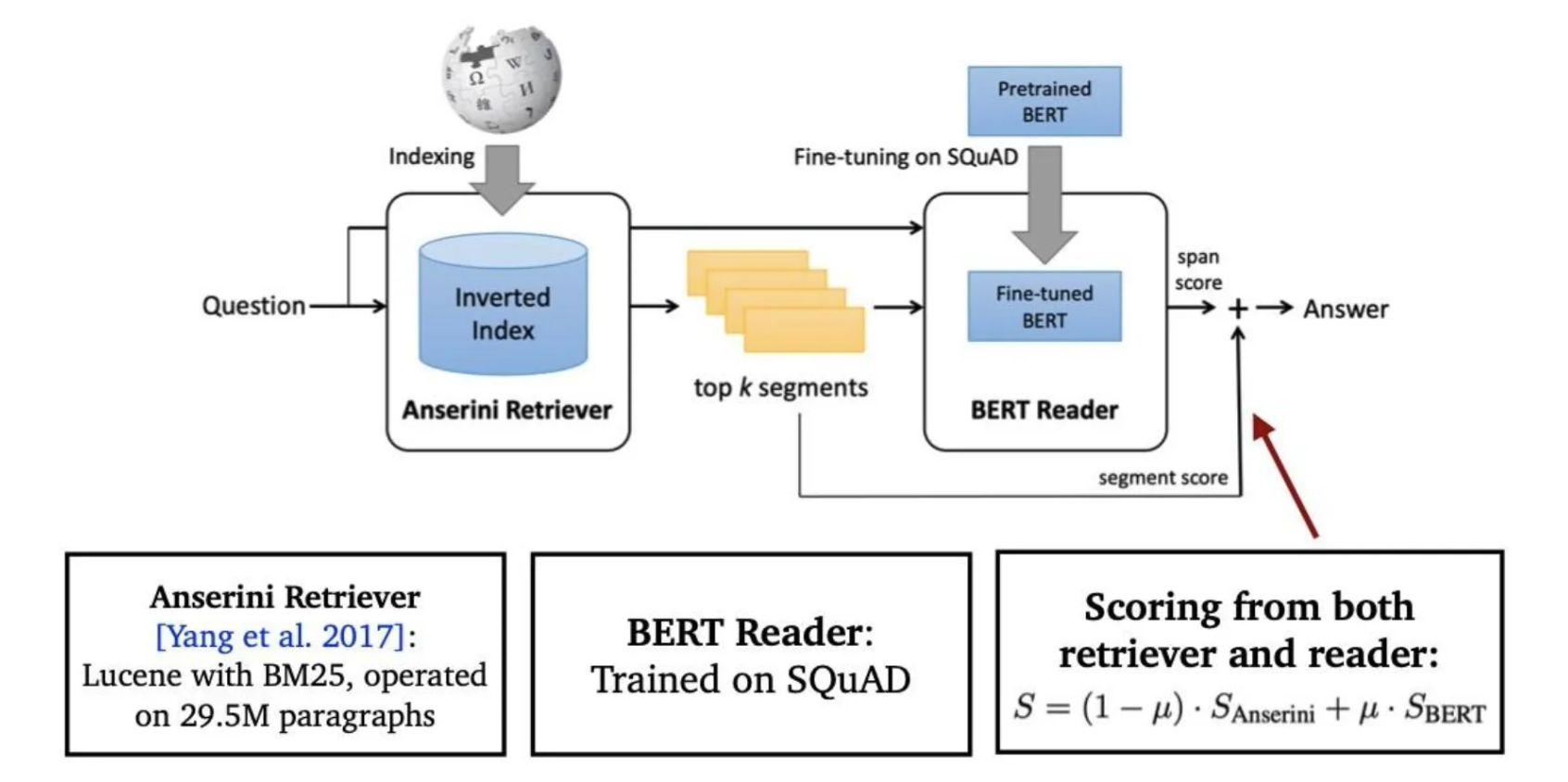
- Retriever 모델에서 추출된 top-k passage들의 retrieval score를 reader 모델에 전달
Reader 모델과 Retriever 모델 연결하기
기계독해와 문서 검색을 연결해 Open-domain question answering(ODQA)를 푸는 방법
Sparse Embedding을 활용한 ODQA 시스템 만들기
Requirements
import random
import numpy as np
from pprint import pprint
from datasets import load_dataset, load_metric
from sklearn.feature_extraction.text import TfidfVectorizer데이터 및 평가지표 불러오기
dataset = load_dataset("squad_kor_v1")Sparse retriever 가져오기
# corpus: train dataset과 validation dataset의 중복 제외 contexts
corpus = list(set([example['context'] for example in dataset['train']]))
corpus.extend(list(set([example['context'] for example in dataset['validation']])))
tokenizer_func = lambda x: x.split(' ') # sparse embedding의 tokenizer는 띄어쓰기 기준
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2))
sp_matrix = vectorizer.fit_transform(corpus)def get_relevant_doc(vectorizer, query, k=1):
# vocab에 없는 이상한 단어로 query 하는 경우 assertion 발생 (예) 뙣뙇?
query_vec = vectorizer.transform([query]) # query embedding vector
assert np.sum(query_vec) != 0, "오류가 발생했습니다. 이 오류는 보통 query에 vectorizer의 vocab에 없는 단어만 존재하는 경우 발생합니다."
result = query_vec * sp_matrix.T # query와 각 context 간의 유사도 계산
sorted_result = np.argsort(-result.data)
doc_scores = result.data[sorted_result]
doc_ids = result.indices[sorted_result]
return doc_scores[:k], doc_ids[:k]""" 1. 정답이 있는 데이터셋으로 검색해보기 """
# random.seed(1)
# sample_idx = random.choice(range(len(dataset['train'])))
# query = dataset['train'][sample_idx]['question']
# ground_truth = dataset['train'][sample_idx]['context']
# answer = dataset['train'][sample_idx]['answers']
""" 2. 원하는 질문을 입력해보기 """
query = input("Enter any question: ") # "미국의 대통령은 누구인가?"
_, doc_id = get_relevant_doc(vectorizer, query, k=1)
""" 결과 확인 """
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id.item()}")
print(corpus[doc_id.item()])
# print(answer)Enter any question: 미국의 대통령은 누구인가?
******************** Result ********************
[Search query]
미국의 대통령은 누구인가?
[Relevant Doc ID(Top 1 passage)]: 4657
영국과 미국의 관계는 대략 400년 정도 소급된다. 1607년 영국은 "제임스타운"이라고 명명된 북미 대륙 최초의 상주 식민지를 세우기 시작하였고, 오늘날 영국과 미국은 가까운 군사적 동맹체다. 양국은 문화적으로 유사할 뿐만 아니라 군사적 연구와 정보 기구를 공유한다. 영국은 미국으로부터 토마호크 미사일이나 트라이던트 미사일과 같은 무기를 구입했고 미국은 영국으로부터 해리어(Harrier)와 같은 장비를 구매했다. 또한 영국에 대규모 군대를 주둔하고 있다. 최근 영국의 총리와 미국의 대통령은 매우 친밀한 모습을 보여주었다. 가령 토니 블레어와 빌 클린턴 및 이후 조지 W. 부시 대통령 간의 관계, 1980년대 마거릿 대처와 로널드 레이건 등의 관계가 그러하다. 현재 영국의 정책은 혈맹 미국과의 관계는 영국의 "가장 중요한 2자간 관계"임을 표명한다.훈련된 MRC(Reader) 모델 가져오기
import torch
from transformers import AutoConfig, AutoModelForQuestionAnswering, AutoTokenizer
model_name = 'sangrimlee/bert-base-multilingual-cased-korquad'
mrc_model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True
)
mrc_model = mrc_model.eval()def get_answer_from_context(context, question, model, tokenizer):
encoded_dict = tokenizer.encode_plus(
question,
context,
truncation=True,
padding="max_length",
max_length=512,
)
non_padded_ids = encoded_dict["input_ids"][: encoded_dict["input_ids"].index(tokenizer.pad_token_id)]
full_text = tokenizer.decode(non_padded_ids)
inputs = {
'input_ids': torch.tensor([encoded_dict['input_ids']], dtype=torch.long),
'attention_mask': torch.tensor([encoded_dict['attention_mask']], dtype=torch.long),
'token_type_ids': torch.tensor([encoded_dict['token_type_ids']], dtype=torch.long)
}
outputs = model(**inputs)
start, end = torch.max(outputs.start_logits, axis=1).indices.item(), torch.max(outputs.end_logits, axis=1).indices.item()
answer = tokenizer.decode(encoded_dict['input_ids'][start:end+1])
return answercontext = corpus[doc_id.item()]
print(context)> 영국과 미국의 관계는 대략 400년 정도 소급된다. 1607년 영국은 "제임스타운"이라고 명명된 북미 대륙 최초의 상주 식민지를 세우기 시작하였고, 오늘날 영국과 미국은 가까운 군사적 동맹체다. 양국은 문화적으로 유사할 뿐만 아니라 군사적 연구와 정보 기구를 공유한다. 영국은 미국으로부터 토마호크 미사일이나 트라이던트 미사일과 같은 무기를 구입했고 미국은 영국으로부터 해리어(Harrier)와 같은 장비를 구매했다. 또한 영국에 대규모 군대를 주둔하고 있다. 최근 영국의 총리와 미국의 대통령은 매우 친밀한 모습을 보여주었다. 가령 토니 블레어와 빌 클린턴 및 이후 조지 W. 부시 대통령 간의 관계, 1980년대 마거릿 대처와 로널드 레이건 등의 관계가 그러하다. 현재 영국의 정책은 혈맹 미국과의 관계는 영국의 "가장 중요한 2자간 관계"임을 표명한다.answer = get_answer_from_context(context, query, mrc_model, tokenizer)
print(answer)> 조지 W. 부시통합해서 ODQA 시스템 구축
def open_domain_qa(query, corpus, vectorizer, model, tokenizer, k=1):
# 1. Retrieve k relevant docs by using sparse matrix
_, doc_id = get_relevant_doc(vectorizer, query, k=1)
context = corpus[doc_id.item()]
# 2. Predict answer from given doc by using MRC model
answer = get_answer_from_context(context, query, mrc_model, tokenizer)
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id.item()}")
pprint(corpus[doc_id.item()], compact=True)
print(f"[Answer Prediction from the model]: {answer}")query = input("Enter any question: ") # "미국의 대통령은 누구인가?"
open_domain_qa(query, corpus, vectorizer, mrc_model, tokenizer, k=1)******************** Result ********************
[Search query]
미국의 대통령은 누구인가?
[Relevant Doc ID(Top 1 passage)]: 4657
('영국과 미국의 관계는 대략 400년 정도 소급된다. 1607년 영국은 "제임스타운"이라고 명명된 북미 대륙 최초의 상주 식민지를 세우기 '
'시작하였고, 오늘날 영국과 미국은 가까운 군사적 동맹체다. 양국은 문화적으로 유사할 뿐만 아니라 군사적 연구와 정보 기구를 공유한다. '
'영국은 미국으로부터 토마호크 미사일이나 트라이던트 미사일과 같은 무기를 구입했고 미국은 영국으로부터 해리어(Harrier)와 같은 장비를 '
'구매했다. 또한 영국에 대규모 군대를 주둔하고 있다. 최근 영국의 총리와 미국의 대통령은 매우 친밀한 모습을 보여주었다. 가령 토니 '
'블레어와 빌 클린턴 및 이후 조지 W. 부시 대통령 간의 관계, 1980년대 마거릿 대처와 로널드 레이건 등의 관계가 그러하다. 현재 '
'영국의 정책은 혈맹 미국과의 관계는 영국의 "가장 중요한 2자간 관계"임을 표명한다.')
[Answer Prediction from the model]: 조지 W. 부시Dense Embedding을 활용한 ODQA 시스템 만들기
Dense Embedding을 만드는 encoder을 학습시키기
# google drive에 올려둔 미리 학습해둔 인코더 불러오기
from transformers import BertModel, BertPreTrainedModel, BertConfig, AutoTokenizer
class BertEncoder(BertPreTrainedModel):
def __init__(self, config):
super(BertEncoder, self).__init__(config)
self.bert = BertModel(config)
self.init_weights()
def forward(self, input_ids,
attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
pooled_output = outputs[1]
return pooled_output
model_checkpoint = 'klue/bert-base'
p_encoder = BertEncoder.from_pretrained(model_checkpoint).to("cuda")
q_encoder = BertEncoder.from_pretrained(model_checkpoint).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)Dense Embedding을 활용하여 passage retrieval 실습해보기
from datasets import load_dataset
dataset = load_dataset("squad_kor_v1")random.seed(2023)
valid_corpus = list(set([example['context'] for example in dataset['validation']]))[:10]
sample_idx = random.choice(range(len(dataset['validation'])))
query = dataset['validation'][sample_idx]['question']
ground_truth = dataset['validation'][sample_idx]['context']
if not ground_truth in valid_corpus:
valid_corpus.append(ground_truth)def to_cuda(batch):
return tuple(t.cuda() for t in batch)def get_relevant_doc(q_encoder, p_encoder, query, k=1):
with torch.no_grad():
p_encoder.eval()
q_encoder.eval()
q_seqs_val = tokenizer([query], padding="max_length", truncation=True, return_tensors='pt').to('cuda')
q_emb = q_encoder(**q_seqs_val).to('cpu') #(num_query, emb_dim)
p_embs = []
for p in valid_corpus:
p = tokenizer(p, padding="max_length", truncation=True, return_tensors='pt').to('cuda')
p_emb = p_encoder(**p).to('cpu').numpy()
p_embs.append(p_emb)
p_embs = torch.Tensor(p_embs).squeeze() # (num_passage, emb_dim)
dot_prod_scores = torch.matmul(q_emb, torch.transpose(p_embs, 0, 1))
rank = torch.argsort(dot_prod_scores, dim=1, descending=True).squeeze()
return dot_prod_scores.squeeze(), rank[:k]Retrieval 결과 확인 전 Ground Truth 확인
print("{} {} {}".format('*'*20, 'Ground Truth','*'*20))
print("[Search query]\n", query, "\n")
pprint(ground_truth, compact=True)******************** Ground Truth ********************
[Search query]
불법행위 당시에는 예견할 수 없었던 새로운 손해 또는 확대된 손해의 예는?
('민법 766조 1항 소정의 손해 및 가해자를 안다고 하는 경우에 손해발생 사실을 안다는 것은 단순히 손해발생의 사실만을 안 때라는 뜻이 '
'아니고 가해행위가 불법행위로써 이를 원인으로 하여 손해배상을 소구할 수 있다는 사실을 안 때 이자, 가해행위와 손해의 발생 사이에 '
'인과관계가 있으며 위법하고 과실이 있는 것까지도 안 때이다. 가해행위와 이로 인한 현실적인 손해의 발생 사이에 시간적 간격이 있는 '
'불법행위에 기한 손해배상채권의 경우, 소멸시효의 기산점이 되는 “불법행위를 한 날"의 의미는 단지 관념적이고 부동적인 상태에서 '
'잠재적으로만 존재하고 있는 손해가 그 후 현실화되었다고 볼 수 있는 때, 다시 말하자면 손해의 결과발생이 현실적인 것으로 되었다고 할 수 '
'있을 때 이고, 후유증 등으로 인하여 불법행위 당시에는 예견할 수 없었던 새로운 손해가 발생하였다거나 예상외로 손해가 확대된 경우에 '
'있어서는 그러한 사유가 판명되었을 때 비로소 새로이 발생 또는 확대된 손해를 알았다고 보아야 한다. 다만, 현실화된 손해의 정도나 '
'액수까지 구체적으로 알아야 하는 것은 아니다.')상위 1개 문서를 추출했을 때 결과 확인
_, doc_id = get_relevant_doc(q_encoder, p_encoder, query, k=1)
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id}")
pprint(valid_corpus[doc_id.item()])******************** Result ********************
[Search query]
불법행위 당시에는 예견할 수 없었던 새로운 손해 또는 확대된 손해의 예는?
[Relevant Doc ID(Top 1 passage)]: tensor([8])
('미국 독립 혁명의 여파로 영국 정부는 영국계 인구가 큰 잔여 식민지들에서 정치적 그리고 사회적 불안에 민감하였다. 1837년에 루이-조셉 '
'파피노가 이끌었던 로어 캐나다 반란과 1837년에서 1838년까지 윌리엄 라이언 매켄지가 이끌었던 어퍼 캐나다 반란을 겪고 난 후, 더럼 '
'경이 영국령 북아메리카의 총독으로 임명한 다음부터 그는 이러한 국정의 문제점들을 연구하며 이런 불길한 사태들을 어떡해 해소하는데 힘썼다. '
'그의 보고서에 토대로 그가 추천하였던 해결책은 어느정도 발전되었던 식민지에게 책임정부를 수행하는 권리를 승인하는 방법이였다. 그 때 당시 '
'책임정부라는 정치적인 용어는 구체적으로 영국의 군주가 임명한 총독이 선출된 의원들로 구성된 식민지 의회의 뜻을 받아주는 정책을 뜻하였다.')상위 5개 문서를 추출했을 때 결과 확인
dot_prod_scores, rank = get_relevant_doc(q_encoder, p_encoder, query, k=5)
for i in range(5):
print(rank[i])
print("Top-%d passage with score %.4f" % (i+1, dot_prod_scores.squeeze()[rank[i]]))
print(valid_corpus[rank[i]])tensor(8)
Top-1 passage with score 89.6241
미국 독립 혁명의 여파로 영국 정부는 영국계 인구가 큰 잔여 식민지들에서 정치적 그리고 사회적 불안에 민감하였다. 1837년에 루이-조셉 파피노가 이끌었던 로어 캐나다 반란과 1837년에서 1838년까지 윌리엄 라이언 매켄지가 이끌었던 어퍼 캐나다 반란을 겪고 난 후, 더럼 경이 영국령 북아메리카의 총독으로 임명한 다음부터 그는 이러한 국정의 문제점들을 연구하며 이런 불길한 사태들을 어떡해 해소하는데 힘썼다. 그의 보고서에 토대로 그가 추천하였던 해결책은 어느정도 발전되었던 식민지에게 책임정부를 수행하는 권리를 승인하는 방법이였다. 그 때 당시 책임정부라는 정치적인 용어는 구체적으로 영국의 군주가 임명한 총독이 선출된 의원들로 구성된 식민지 의회의 뜻을 받아주는 정책을 뜻하였다.
tensor(3)
Top-2 passage with score 82.2686
믿음은 불도의 근본이며 복덕의 모태로써 궁극적인 깨달음에 이르기까지 인도자가 된다는 것으로 信心이 얼마나 중요한 것인지를 설명한 것이다. 믿음은 迷信이나 盲信이 아닌 맑고 깨끗한 淨信이어야 한다고 賢首菩薩은 주장하고 있다. 청정한 믿음에서 모든 공덕이 생기기 때문이다. 믿음을 실현하기 위해서는 청정한 계율을 지키고 바른 법을 따르는 것이다. 그렇게 하면 일체의 모든 것에 대해 집착이 없어져서 완전히 청정해지며, 그로 인해 위없는 마음을 얻을 수 있게 된다는 것이다. 이렇게 중요한 믿음에 대하여 『華嚴經』에는 十信의 명칭이나 십신보살의 실천행에 대해서는 설해지고 있지 않다. 그 이유를 法藏은 十住 내지 十地의 실천행에는 階位가 있을 수 있지만, 믿음에는 계위가 없기 때문에 나열하지 않는다고 설명하고 있다. 『大正藏』9, p.433, “信爲道元功德母 增長一切諸善法 除滅一切諸疑惑 示現開發無上道” 『大正藏』9, p.433. 『探玄記』권4, (『大正藏』35, p.187上), “釋云信不成位故不例也.”"
tensor(0)
Top-3 passage with score 78.2776
1969년 "아시아 각국은 내란이 발생하거나 침략을 받는 경우 스스로 이를 해결해야 한다"는 닉슨 독트린을 발표하였다. 1969년 1월 닉슨 행정부가 수립된 후 미소관계는 상호협조의 시대로 돌입했다. 선거기간 중 "자신이 당선되면 소련을 방문하겠다"고 강조한 닉슨 대통령은 취임연설에서 협상시대의 도래를 희망한 후 곧이어 서독, 영국, 이탈리아 등 서구 우방을 순방했다.(1969년 2월) 이 방문에서 닉슨 대통령은 대소협상에 관한 사전 의견교환을 하고 방소 준비를 착실히 진척시켰다. 외교 정책의 대담한 변화로 1971년 헨리 키신저가 1971년 8월 비밀리에 베이징을 방문해서 저우언라이 총리와 회담을 가졌고, 1972년에는 그 자신이 미국의 대통령으로서는 처음으로 중공을 방문하여 마오쩌둥 과의 미․중 정상회담(2월 21일), 저우언라이와 회담을 가져 훗날의 미국과 중국 사이의 국교 정상화의 길을 열었다. 또한 같은 해에 소련을 방문하여 냉전의 시대에서 대화의 시대로 옮기는 기수가 되었다. 인도차이나 전쟁을 끝맺고자 베트남에서 미군을 철수하였다.
tensor(10)
Top-4 passage with score 69.6240
민법 766조 1항 소정의 손해 및 가해자를 안다고 하는 경우에 손해발생 사실을 안다는 것은 단순히 손해발생의 사실만을 안 때라는 뜻이 아니고 가해행위가 불법행위로써 이를 원인으로 하여 손해배상을 소구할 수 있다는 사실을 안 때 이자, 가해행위와 손해의 발생 사이에 인과관계가 있으며 위법하고 과실이 있는 것까지도 안 때이다. 가해행위와 이로 인한 현실적인 손해의 발생 사이에 시간적 간격이 있는 불법행위에 기한 손해배상채권의 경우, 소멸시효의 기산점이 되는 “불법행위를 한 날"의 의미는 단지 관념적이고 부동적인 상태에서 잠재적으로만 존재하고 있는 손해가 그 후 현실화되었다고 볼 수 있는 때, 다시 말하자면 손해의 결과발생이 현실적인 것으로 되었다고 할 수 있을 때 이고, 후유증 등으로 인하여 불법행위 당시에는 예견할 수 없었던 새로운 손해가 발생하였다거나 예상외로 손해가 확대된 경우에 있어서는 그러한 사유가 판명되었을 때 비로소 새로이 발생 또는 확대된 손해를 알았다고 보아야 한다. 다만, 현실화된 손해의 정도나 액수까지 구체적으로 알아야 하는 것은 아니다.
tensor(7)
Top-5 passage with score 57.3919
1967년 용산구 한남동 힐탑아파트는 당시 선진 기술을 전수받기 위해 우리 정부와 기업이 초청한 외국인들의 거주시설로 지어졌다. 당시 외국 기술자들은 경제발전에 꼭 필요한 존재였기에 최고급 대우를 해주어야 했다. 짧게 머무는 외국인 사업가들은 시내의 조선호텔과 도뀨호텔, 코리아나호텔에서 묵었지만 장기 체류하는 대사관 직원과 상사 주재원들은 호텔에서 머무는것 보다 전용주택을 따로 짓는 것이 더 나았다. 그리하여 정부는 외국인 전용 공동주택을 건설해야 했다. 이런 필요성에서 탄생한 첫 외인아파트가 바로 서울 용산구 한남동에 위치한 힐탑아파트 국내의 아파트 최초로 엘리베이터가 등장하였고 집에서 전화를 받을 수 있는 자동식 전화가 설치되었다. 통조림스프와 감자칩, 스파게티 등의 서양식 음식도 힐탑아파트 내의 외국인전용 매점에서 살 수 있었다. 지상 11층짜리 힐탑아파트는 우리나라 첫 고층아파트라는 수식어를 지니고 있다. 대한주택공사는 일본 다이세이(大成)건설에서 빌린 100만 달러어치 철근과 목재를 이용해 주택공사가 소유하고 있는 한남동 땅에 아파트를 건립하기로 하였다. 1967년 3월 공사를 시작한 후 1년 7개월만에 지하 1층, 지상 11층 120가구 규모의 고층 건축물이 완성되었다. 당시 옥상에는 옥상정원과 아이들을 위한 놀이터가 있었다. 당시 국내 최초로 필로티 구조(건물 전체나 일부를 기둥으로 들어올려 건물을 지상에서 분리시키는 것)를 과감하게 도입하기도 했다. 건물 외벽은 단열효과를 고려해 콘크리트로 마감했다. 꺾어진 아파트는 남향으로 쏟아지는 햇빛을 더 오래 받고 북쪽 판잣집을 가리는 일석이조의 효과를 냈다고 한다. 힐탑아파트의 내부는 당시 62~108m(19~33평)으로 구성됐다. 방이 1개 있는 유형부터 방 3개짜리까지 종류도 다양했다. 내부는 대리석을 깐 현관으로 시작하여 양 옆으로 침실 2개와 넓은 거실 겸 부엌이 있었다. 안쪽으로는 욕실과 또 다른 침실이 있었다. 신발을 신고 다니는데 불편하지 않도록 단 높이를 맞췄고 온돌 대신 중앙 스팀난방을 적용했다. 힐탑아파트는 공간을 넓게 쓸 수 있도록 선반 등 가구 일부를 벽으로 집어 넣었다. 콘크리트로 만든 일종의 붙박이 가구인 셈이다. 또 밖으로 뚫린 발코니는 세대를 분리하면서도 이웃과 이웃을 잇는 역할을 한다. ‘대한민국아파트발굴사’에 따르면 힐탑아파트를 설계한 건축가 안병의 씨는 이렇게 회고했다고 한다.훈련된 MRC 모델 가져오기
import torch
from transformers import AutoConfig, AutoModelForQuestionAnswering, AutoTokenizer
model_name = 'sangrimlee/bert-base-multilingual-cased-korquad'
mrc_model = AutoModelForQuestionAnswering.from_pretrained(model_name).cuda()
mrc_model = mrc_model.eval()
qa_tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)def get_answer_from_context(context, question, model, tokenizer):
encoded_dict = tokenizer.encode_plus(
question,
context,
truncation=True,
padding="max_length",
max_length=512,
)
inputs = {
'input_ids': torch.tensor([encoded_dict['input_ids']], dtype=torch.long),
'attention_mask': torch.tensor([encoded_dict['attention_mask']], dtype=torch.long),
'token_type_ids': torch.tensor([encoded_dict['token_type_ids']], dtype=torch.long)
}
inputs = {k: v.cuda() for k, v in inputs.items()}
outputs = model(**inputs)
start, end = torch.max(outputs.start_logits, axis=1).indices.item(), torch.max(outputs.end_logits, axis=1).indices.item()
if start == 0 and end == 0:
answer = "This is not answerable"
else:
answer = tokenizer.decode(encoded_dict['input_ids'][start:end+1])
return answercontext = valid_corpus[doc_id.item()]
print(context)> 미국 독립 혁명의 여파로 영국 정부는 영국계 인구가 큰 잔여 식민지들에서 정치적 그리고 사회적 불안에 민감하였다. 1837년에 루이-조셉 파피노가 이끌었던 로어 캐나다 반란과 1837년에서 1838년까지 윌리엄 라이언 매켄지가 이끌었던 어퍼 캐나다 반란을 겪고 난 후, 더럼 경이 영국령 북아메리카의 총독으로 임명한 다음부터 그는 이러한 국정의 문제점들을 연구하며 이런 불길한 사태들을 어떡해 해소하는데 힘썼다. 그의 보고서에 토대로 그가 추천하였던 해결책은 어느정도 발전되었던 식민지에게 책임정부를 수행하는 권리를 승인하는 방법이였다. 그 때 당시 책임정부라는 정치적인 용어는 구체적으로 영국의 군주가 임명한 총독이 선출된 의원들로 구성된 식민지 의회의 뜻을 받아주는 정책을 뜻하였다.answer = get_answer_from_context(context, query, mrc_model, qa_tokenizer)
print(answer)> This is not answerable통합해서 ODQA 시스템 구축
def open_domain_qa(query, corpus, p_encoder, q_encoder, mrc_model, tokenizer, qa_tokenizer, k=1):
# 1. Retrieve k relevant docs by usign sparse matrix
_, doc_id = get_relevant_doc(p_encoder, q_encoder, query, k=1)
context = corpus[doc_id.item()]
# 2. Predict answer from given doc by using MRC model
answer = get_answer_from_context(context, query, mrc_model, qa_tokenizer)
print("{} {} {}".format('*'*20, 'Result','*'*20))
print("[Search query]\n", query, "\n")
print(f"[Relevant Doc ID(Top 1 passage)]: {doc_id.item()}")
pprint(corpus[doc_id.item()], compact=True)
print(f"[Answer Prediction from the model]: {answer}")query = input("Enter any question: ") # "대한민국의 대통령은 누구인가?"
open_domain_qa(query=query,
corpus=valid_corpus,
p_encoder=p_encoder,
q_encoder=q_encoder,
mrc_model=mrc_model,
tokenizer=tokenizer,
qa_tokenizer=qa_tokenizer,
k=1)******************** Result ********************
[Search query]
대한민국의 대통령은 누구인가?
[Relevant Doc ID(Top 1 passage)]: 8
('미국 독립 혁명의 여파로 영국 정부는 영국계 인구가 큰 잔여 식민지들에서 정치적 그리고 사회적 불안에 민감하였다. 1837년에 루이-조셉 '
'파피노가 이끌었던 로어 캐나다 반란과 1837년에서 1838년까지 윌리엄 라이언 매켄지가 이끌었던 어퍼 캐나다 반란을 겪고 난 후, 더럼 '
'경이 영국령 북아메리카의 총독으로 임명한 다음부터 그는 이러한 국정의 문제점들을 연구하며 이런 불길한 사태들을 어떡해 해소하는데 힘썼다. '
'그의 보고서에 토대로 그가 추천하였던 해결책은 어느정도 발전되었던 식민지에게 책임정부를 수행하는 권리를 승인하는 방법이였다. 그 때 당시 '
'책임정부라는 정치적인 용어는 구체적으로 영국의 군주가 임명한 총독이 선출된 의원들로 구성된 식민지 의회의 뜻을 받아주는 정책을 뜻하였다.')
[Answer Prediction from the model]: This is not answerable
🌱 🐜