Dense Embedding
- Dense Embedding(밀집 임베딩): 저차원의 벡터에서 모든 값이 실수로 채워져 있고, 각 차원에 의미 있는 정보가 압축되어 표현된다. 벡터의 대부분의 원소가 0이 아닌 값을 가진다.
- 대표적인 예
- Word2Vec, GloVe: 단어를 저차원 실수 벡터로 임베딩하여, 단어 간의 의미적 유사성을 벡터 공간에서 가까운 거리로 표현한다.
- Transformer 기반 모델 (BERT, RoBERTa, SBERT 등): 문장 단위의 dense embedding을 생성하여, 문장 간의 의미적 유사성을 실수 벡터로 나타낸다.
- 장점: 단어/문장의 의미를 압축하여 더 적은 차원으로 효율적으로 표현할 수 있고, 의미적 유사성을 잘 반영한다. 유사한 의미를 가진 문장은 벡터 공간에서 가깝게 위치하고, 서로 다른 의미를 가진 문장은 벡터 공간에서 멀게 위치한다.
- 단점: 결과 해석이 직관적이지 않으며, 학습에 더 많은 계산 리소스가 필요할 수 있다.
Overview
Dense Embedding은 질문과 문서의 의미적 유사성을 기반으로 검색하는 기법이다. 이를 위해 인코더를 훈련하여 질문과 문서 각각의 벡터 표현을 생성하고, 이 벡터들 간의 유사도를 계산한다.
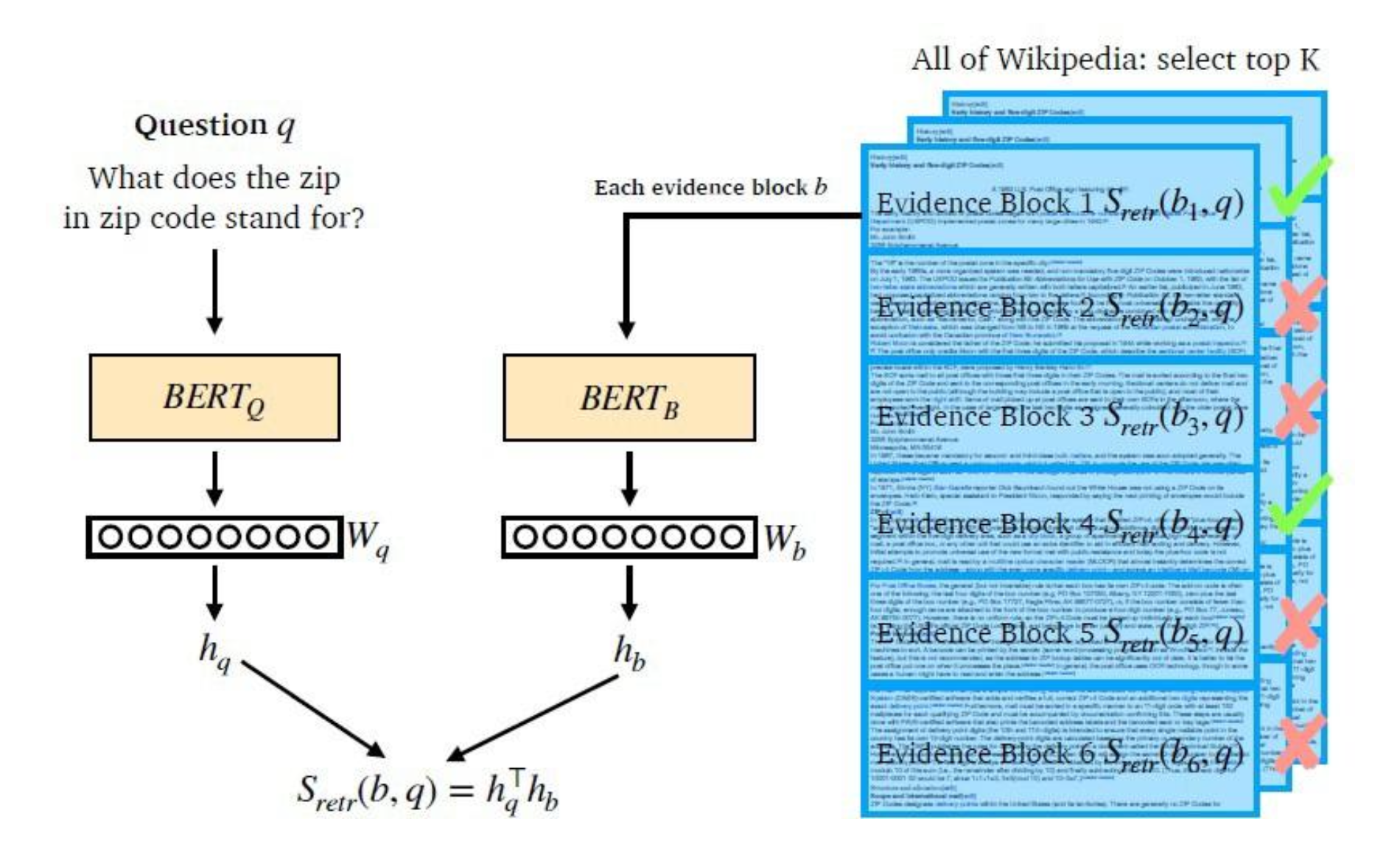
Dense Embedding 생성 과정
- 질문 (): 문장을 인코더로 인코딩하여, [CLS] 토큰에 해당하는 벡터를 로 변환한다.
- 문서 (): 문서도 동일한 방식으로 인코딩하여, [CLS] 토큰에 해당하는 벡터를 로 변환한다.
- 유사도 계산: 질문과 문서 벡터의 내적(dot product)을 통해 두 벡터의 유사도를 측정한다.이 때, 와 의 크기는 동일해야 한다.
Dense Encoder 훈련
Dense Encoder 훈련의 목표는 질문과 관련된 문서의 벡터 간 거리를 줄이는 것이다. 이를 통해 질문과 문서 간 높은 유사도를 가진 벡터를 학습하게 된다.
- Dense Encoder
- BERT와 같은 pre-trained language model(PLM)이 자주 사용되며, [CLS] 토큰의 출력을을 벡터로 활용한다.
- 그 외 다양한 신경망 구조를 적용할 수도 있다.
- Negative Sampling
- 연관된 질문과 문서 간의 벡터 거리를 좁히는 것이 목표임 → Positive pair
- 연관되지 않은 질문과 문서 간의 벡터 거리는 멀어야 함 → Negative sampling
- Random Negative Sampling: 코퍼스에서 랜덤하게 샘플링
- Hard Negative Sampling: 높은 TF-IDF 스코어를 가지지만 답을 포함하지 않는 헷갈리는 문서 샘플링
- 손실 함수
- Negative Log-Likelihood Loss (NLL Loss): Positive 문서에 대한 확률을 최대화하는 방식으로 학습된다.
- 평가 지표
- Top-k Retrieval Accuracy: 뽑힌 k개의 문서 중에서 답을 포함하는 문서가 있는 비율을 계산한다.
Dense Encoder 기반 Passage Retrieval
-
Dense Encoding을 통한 문서 검색
질문과 문서를 각각 Dense Embedding으로 변환한 후, 질문 벡터에 가장 가까운 순서대로 문서의 순위를 매긴다. -
Retrieval에서 Open-Domain QA로
검색된 문서에서 MRC/Reader 모델을 사용해 최종적으로 답을 추출한다. -
더 나은 Dense Encoding을 만드는 방법
-
학습 방식 개선: DPR(Dense Passage Retrieval)과 같은 고도화된 학습 방법을 사용하는 방법
-
모델 개선: 더 크고 정확한 Pretrained 모델(BERT보다 큰 모델)을 사용하는 방법
-
데이터 개선: 더 많은 데이터, 더 나은 전처리 과정을 통해 성능을 향상시키는 방법
-
DPR(Dense Passage Retrieval)
Overview
DPR은 추가적인 사전 훈련 없이 적은 수의 질문-패시지(Q, P) 쌍으로도 좋은 Dense Embedding 모델을 구현하는 방법론이다. Reader보다 Retrieval 성능 향상에 초점을 맞추고, M개의 패시지를 저차원 공간에 인덱싱하여 효과적으로 상위 k개의 패시지를 추출한다. 위에서 문서(b)라고 언급된 내용을, 지금부터는 패시지(p)라는 용어로 사용하려 한다.
DPR은 BERT와 Dual-Encoder 구조를 기반으로 한다. 여기서 질문 인코더는 , 문서 인코더는 로 표현한다.
주어진 질문 Q에 대한 임베딩과 패시지 P에 대한 임베딩의 유사도를 각 패시지에 대하여 계산한다.
-
인코더 (Encoder)
BERT 인코더를 사용하여 [CLS] token에 해당하는 벡터의 hidden embedding을 반환한다.이때 Hidden dimension size는 768이다.
-
-
추론 (Inference)
모든 패시지를 로 임베딩한 후 FAISS(벡터 간 유사도를 빠르게 계산할 수 있게 해주는 라이브러리)를 사용해 임베딩 벡터를 계산하고, 인덱스를 달아준다. 이 인덱스를 통해 주어진 질문에 대해 가까운 패시지 벡터 k개를 빠르게 반환한다.
Training
DPR의 학습 목적은 유사도가 높은 질문-문서(Q, P) 쌍이 가까이 위치하고, 유사도가 낮은 쌍은 멀리 위치하도록 벡터 공간을 구성하는 것이다. 이는 더 나은 임베딩 함수를 학습함으로써 가능하다.
-
학습 데이터
데이터는 다음과 같이 구성된다.여기서 는 질문, 는 positive passage, 는 negative passage를 의미한다.
-
손실 함수
Negative log likelihood(NLL) 손실 함수는 다음과 같이 정의된다.
Positive and negative passages
- 하나의 질문에 대한 negative passage는 너무 많다.
- High-quality 인코더를 만들기 위해서는 negative sample을 신중하게 선택해야 한다.
- negative sample의 type
- Random : 코퍼스에서 랜덤하게 선택
- BM25 : 질문에 대한 정답은 포함하지 않으면서, 질문과 높은 유사도를 가지는 패시지 선택
- Gold : 다른 질문들에 대한 positive passage() 집합
- negative sample의 type
- 최고 성능의 모델은 동일한 미니 배치에서의 Gold passages와 하나의 BM25 negative passage를 사용한다. 특히 동일한 미니 배치의 Gold passages를 negative sample로 재사용하면 계산을 효율성을 높이면서 뛰어난 성능을 달성할 수 있다.
In-batch Negatives
- 미니배치 하나에 개의 질문이 포함된다고 가정하자.
- 각 질문은 하나의 positive passage를 가진다.
- Batch size , embedding size 에 대하여 다음과 같이 표현된다.
- → Q의 행은 의 임베딩 벡터
- → Pᵀ의 열은 의 임베딩 벡터로, 에 대응된다.
- 따라서 의 식이 나타내는 것은 다음과 같다.
- 대각 원소: Positive sample similarity
- 나머지 원소: Negative sample similarity - In-batch Negatives의 장점은 다음과 같다.
- 효율성: Similarity matrix를 학습 시 재사용하여, 미니배치안에 있는 쌍을 효율적으로 학습한다.
- 비용 절감: Negative sampling 시 별도의 계산 없이 다른 질문에 대응하는 패시지들을 negative samples로 사용하므로 계산 비용을 줄일 수 있다. (그냥 다른 q에 대응하는 p들(B-1개)을 negative sample로 사용하니까)
- 성능 개선 효과: In-batch Negative sampling은 성능 개선에도 기여한다.
BERT를 활용한 Dense Passage Retrieval 실습
- KorQuAD train 데이터셋을 활용해서 Dense Encoder을 학습시킬 수 있다.
- Dense Encoder를 통해 Dense Embedding을 만들 수 있다.
- Dense Embedding을 활용하여 passage retrieval를 진행할 수 있다.
데이터셋 및 토크나이저 준비
from datasets import load_dataset
dataset = load_dataset("squad_kor_v1")from transformers import AutoTokenizer
import numpy as np
# BERT를 encoder로 사용하므로, huggingface에서 제공하는 bert기반 tokenizer 활용
model_checkpoint = "bert-base-multilingual-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)tokenized_input = tokenizer(dataset['train'][0]['context'], padding="max_length", truncation=True)
tokenizer.decode(tokenized_input['input_ids'])
Dense encoder (BERT) 학습 시키기
- HuggingFace BERT를 활용하여 question encoder, passage encoder 학습
from tqdm import tqdm, trange
import argparse
import random
import torch
import torch.nn.functional as F
from transformers import BertModel, BertPreTrainedModel, AdamW, TrainingArguments, get_linear_schedule_with_warmup
torch.manual_seed(2023)
torch.cuda.manual_seed(2023)
np.random.seed(2023)
random.seed(2023)Training Dataset 준비하기 (question, passage pairs)
# Use subset (128 example) of original training dataset
sample_idx = np.random.choice(range(len(dataset['train'])), 128)
training_dataset = dataset['train'][sample_idx]from torch.utils.data import (DataLoader, RandomSampler, TensorDataset)
# question, context tokenization
q_seqs = tokenizer(training_dataset['question'], padding="max_length", truncation=True, return_tensors='pt')
p_seqs = tokenizer(training_dataset['context'], padding="max_length", truncation=True, return_tensors='pt')# 학습시 용이하도록 형태를 만들어준다
train_dataset = TensorDataset(p_seqs['input_ids'], p_seqs['attention_mask'], p_seqs['token_type_ids'],
q_seqs['input_ids'], q_seqs['attention_mask'], q_seqs['token_type_ids'])TensorDataset을 사용해질문(question)과 문맥(context) 데이터를 하나로 묶어서 학습에 필요한 입력 형태로 변환하는 과정- p_seqs는 문맥(context)의 입력 데이터이고, q_seqs는 질문(question)의 입력 데이터
- 각각의 데이터에는 input_ids, attention_mask, token_type_ids가 포함
- input_ids: 토큰화된 텍스트의 인덱스
- attention_mask: 패딩이 아닌 실제 토큰 위치를 1로 표시
- token_type_ids: 세그먼트 정보를 나타내며, 질문과 문맥을 구분(질문은 0, 문맥은 1)
- TensorDataset은 이 모든 데이터를 하나의 데이터셋으로 병합
BertEncoder 정의 후, question encoder, passage encoder에 pre-trained weight 불러오기
class BertEncoder(BertPreTrainedModel):
def __init__(self, config):
super(BertEncoder, self).__init__(config)
self.bert = BertModel(config)
self.init_weights()
def forward(self, input_ids,
attention_mask=None, token_type_ids=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
pooled_output = outputs[1] # [cls]의 embedding
return pooled_outputBertEncoder: Dense Passage Retrieval(DPR)에서 질문(query)과 문맥(passage)의 임베딩을 추출하기 위해 BERT 모델을 인코더로 사용하는 과정
class BertEncoder(BertPreTrainedModel):BertPreTrainedModel클래스를 상속받아 BERT 기반 인코더를 정의한 클래스- 이 클래스는 사전 학습된 BERT 모델을 기반으로 질문과 문서의 임베딩을 생성한다.
def __init__(self, config):super(BertEncoder, self).__init__(config)super()는 부모 클래스의 생성자를 호출하는 데 사용되며, 이 코드는 BertEncoder 클래스가 BertPreTrainedModel의 속성들을 상속할 수 있도록 설정하는 과정이다.- 부모 클래스의
__init__메서드를 호출하여 BERT 모델과 관련된 기본 설정을 초기화한다.
self.bert = BertModel(config)BertPreTrainedModel은 BERT처럼 사전 학습된 모델을 다룰 때 사용하는 추상 클래스로, 이를 상속받아 구체적인 BERT 모델(BertModel)을 구현한다.config는 BERT 모델의 구성 정보를 담고 있는 객체로, 모델의 하이퍼파라미터들(hidden size, number of layers, attention heads 등)이 포함되어 있다.- 이렇게 초기화된 BERT 모델은
self.bert에 저장되어, 이후에 모델의 순전파 과정에서 사용할 수 있게 된다.
self.init_weights()- BERT 모델의 가중치를 새로 초기화하는 함수로, 처음부터 학습할 경우 필요한 과정이다.
- 가중치를 무작위로 설정하거나 특정 초기값으로 설정한다.
def forward(self, input_ids, attention_mask, token_type_ids):- 이 메서드는 모델의 순전파 과정(Forward Pass)을 정의한다.
outputs = self.bert(): BERT 모델에 입력을 넣어 임베딩을 추출하며, 두 가지 값으로 구성된다.outputs[0]: 각 토큰의 임베딩 (토큰별 임베딩)outputs[1]:[CLS]토큰의 임베딩 (문서 전체 또는 질문의 임베딩)
pooled_output: 질문이나 문서 전체를 대표하는 임베딩으로 많이 사용되는[CLS]토큰의 임베딩을 사용한다.
# load pre-trained model on cuda (if available)
p_encoder = BertEncoder.from_pretrained(model_checkpoint)
q_encoder = BertEncoder.from_pretrained(model_checkpoint)
if torch.cuda.is_available():
p_encoder.cuda()
q_encoder.cuda()- 질문과 문서를 임베딩하기 위해 두 개의 BERT 인코더 모델을 정의한다.
p_encoder: passage(문서)를 인코딩하기 위한 BERT 모델q_encoder: question(질문)을 인코딩하기 위한 BERT 모델
Train function 정의 후, 두 개의 encoder fine-tuning 하기 (In-batch negative 활용)
def train(args, dataset, p_model, q_model):
# Dataloader
train_sampler = RandomSampler(dataset)
train_dataloader = DataLoader(dataset, sampler=train_sampler, batch_size=args.per_device_train_batch_size)
# 옵티마이저에서 weight decay를 적용하지 않을 파라미터 정의
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in p_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in p_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0},
{'params': [p for n, p in q_model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': args.weight_decay},
{'params': [p for n, p in q_model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total)
# Start training!
global_step = 0
p_model.zero_grad()
q_model.zero_grad()
torch.cuda.empty_cache()
# Epoch 반복
train_iterator = trange(int(args.num_train_epochs), desc="Epoch")
# Batch 반복
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
q_encoder.train()
p_encoder.train()
if torch.cuda.is_available():
batch = tuple(t.cuda() for t in batch)
p_inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'token_type_ids': batch[2]
}
q_inputs = {'input_ids': batch[3],
'attention_mask': batch[4],
'token_type_ids': batch[5]}
p_outputs = p_model(**p_inputs) # (batch_size, emb_dim)
q_outputs = q_model(**q_inputs) # (batch_size, emb_dim)
# 학습 목표: 현재 question과 현재 example 안에 있는 passage similarity는 최대화하면서, 현재 question과 다른 passage 간의 embedding similarity는 최소화 시킬 것(in-batch negative)
# Calculate similarity score & loss
sim_scores = torch.matmul(q_outputs, torch.transpose(p_outputs, 0, 1)) # (batch_size, emb_dim) x (emb_dim, batch_size) = (batch_size, batch_size)
# target: position of positive samples = diagonal element
targets = torch.arange(0, args.per_device_train_batch_size).long()
if torch.cuda.is_available():
targets = targets.to('cuda')
sim_scores = F.log_softmax(sim_scores, dim=1)
loss = F.nll_loss(sim_scores, targets)
loss.backward()
optimizer.step()
scheduler.step()
q_model.zero_grad()
p_model.zero_grad()
global_step += 1
torch.cuda.empty_cache()
return p_model, q_model-
Optimizer 설정
no_decay: 옵티마이저에서 weight decay를 적용하지 않을 파라미터 정의- 주로 bias나 LayerNorm의 파라미터는 weight decay를 하지 않는 것이 일반적이다.
optimizer_grouped_parameters:p_model와q_model의 파라미터를 그룹화하여 옵티마이저에 전달weight_decay는 특정 파라미터에서 가중치 감소(regularization)를 적용할지 여부를 설정한다.no_decay리스트에 포함된 파라미터들에는 weight decay를 적용하지 않음no_decay리스트에 포함되지 않은 나머지 파라미터들에게만 weight decay를 적용
optimizer = AdamW(): AdamW 옵티마이저를 사용하여 모델을 업데이트
-
Scheduler 설정
-
t_total: 전체 학습 과정에서의 총 업데이트 횟수로, 학습 스케줄링과 learning rate 조정을 위해 전체 학습 과정에서의 총 업데이트 횟수를 계산한다. -
scheduler = get_linear_schedule_with_warmup(): 학습 초기에는 learning rate를 천천히 증가시키고, 이후에는 선형으로 감소시키는 learning rate 스케줄러warmup_steps: 초기 학습 단계에서 learning rate를 서서히 증가시키는 단계training_steps: 전체 학습 과정에서 스케줄러가 몇 번의 업데이트 동안 learning rate를 변화시킬지를 정의하는 값
-
-
모델 학습 초기화
p_model.zero_grad(),q_model.zero_grad()- 모델의 모든 파라미터에 대해 이전에 계산된 그래디언트를 초기화하는 과정
- 일반적으로 PyTorch에서는 역전파(backpropagation)를 통해 그래디언트를 계산하고, 이를 통해 모델의 파라미터를 업데이트한다. 그러나 기본적으로는 모델의 그래디언트가 누적되기 때문에, 매 스텝마다 그래디언트를 초기화하지 않으면 이전의 그래디언트가 계속 누적되어 잘못된 업데이트가 발생할 수 있다.
- 따라서 매 에폭 시작 시나 각 업데이트 사이에
zero_grad()를 호출하여 그래디언트를 초기화함으로써, 올바른 그래디언트 계산과 파라미터 업데이트가 이루어지도록 한다.
torch.cuda.empty_cache()- GPU 메모리를 비워서 다음 연산을 위한 공간을 확보한다.
-
Epoch 반복 (
train_iterator)trange(int(args.num_train_epochs), desc="Epoch")- 에폭마다 학습 과정을 반복하며, 몇 번째 에폭인지 출력한다.
-
Batch 반복 (
epoch_iterator)tqdm(train_dataloader, desc="Iteration")- 매 배치마다 진행 상황을 출력하며 데이터셋을 순회한다.
-
모델 훈련 (Forward Pass)
q_encoder.train(),p_encoder.train(): 인코더 모델을 훈련 모드로 설정batch = tuple(t.cuda() for t in batch): 데이터를 GPU로 이동p_inputs,q_inputs: passage와 question에 대한 입력 데이터 설정input_ids,attention_mask,token_type_ids: BERT 모델에서 사용하는 입력 형식
p_outputs,q_outputs: 각각 passage 모델(p_model)과 question 모델(q_model)에서 입력 데이터를 처리하여 임베딩(embedding)을 생성하는 과정p_outputs = p_model(**p_inputs): passage encoder(p_model)에 입력 데이터를 전달하여 passage embedding을 얻는다.q_outputs = q_model(**q_inputs): question encoder(q_model)에 질문 데이터를 전달하여 question embedding을 얻는다.- 결과적으로 passage와 question 각각의 임베딩을 생성하여, 이후의 유사도 계산 및 손실(loss) 계산에 사용됨
-
In-batch Negative Sampling & Similarity 계산
sim_scores = torch.matmul(q_outputs, torch.transpose(p_outputs, 0, 1))- 질문 임베딩과 passage 임베딩 간의 코사인 유사도를 계산한다.
- 각 행은 질문에 대한 passage의 유사도 값이다.
targets = torch.arange(0, args.per_device_train_batch_size).long()- 정답 레이블을 생성한다. 각 질문과 해당하는 정답 패시지의 유사도는 대각선에 위치한다.
[0, 1, 2, ...]처럼 생성되며, 이는 정답 패시지의 위치를 나타낸다.
-
손실 함수 계산 (Negative Log Likelihood Loss)
sim_scores = F.log_softmax(sim_scores, dim=1): 유사도 행렬에 log softmax를 적용하여 확률 분포를 만든다.loss = F.nll_loss(sim_scores, targets): 정답 passage(대각선)와 다른 passage들 사이의 유사도 차이를 최대화하는 방식인 Negative Log Likelihood (NLL) Loss를 계산한다.
-
Backpropagation 및 Optimizer Step
loss.backward(): 손실에 대한 역전파를 수행하여 그래디언트를 계산optimizer.step(): 옵티마이저를 통해 모델의 파라미터를 업데이트scheduler.step(): 스케줄러를 통해 learning rate를 조정q_model.zero_grad(),p_model.zero_grad(): 그래디언트를 초기화하여 다음 배치에 영향을 미치지 않도록 함torch.cuda.empty_cache(): GPU 메모리를 비워 다음 배치를 처리할 수 있도록 함
args = TrainingArguments(
output_dir="dense_retireval",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
num_train_epochs=2,
weight_decay=0.01
)p_encoder, q_encoder = train(args, train_dataset, p_encoder, q_encoder)- Dense Encoder는 훈련이 필요하다.
- passage 인코더와 question 인코더가 생성하는 임베딩 벡터는 인코더의 훈련이 진행됨에 따라 변한다.
- 훈련 과정에서 임베딩 벡터의 변화
- 가중치 업데이트: 인코더 모델(p_model, q_model)의 가중치가 훈련 과정에서 손실(loss) 계산을 통해 업데이트된다. 이 업데이트 과정은 모델이 더 나은 예측을 할 수 있도록 조정된다.
- 역전파(Backpropagation): 그래디언트 계산을 통해, 모델은 예측이 잘못된 부분에 대해 가중치를 조정한다. 이로 인해 passage와 question에 대한 임베딩 벡터가 변화하게 된다.
- 다양한 입력 데이터: 각 에폭(epoch)에서 다양한 데이터 배치(batch)가 모델에 입력되므로, 모델은 점진적으로 더 많은 정보를 학습하고 이를 반영하여 임베딩을 업데이트한다.
- 임베딩의 의미 변화
- 훈련이 진행됨에 따라 모델은 passage와 question의 의미를 더 잘 이해하게 되고, 결과적으로 생성하는 임베딩 벡터는 더 구체적이고 의미 있는 표현으로 변한다.
- 이러한 임베딩 벡터의 변화는 모델이 passage와 question 간의 유사도를 더 정확하게 계산할 수 있도록 돕는다. 즉, 관련된 passage와 question 간의 임베딩 벡터는 가까워지고, 관련이 없는 경우는 멀어지는 방향으로 학습된다.
- 훈련 과정에서 임베딩 벡터의 변화
- 이러한 변화는 모델이 질문과 관련된 passage를 더 잘 이해하고 유사도 계산에서 성능을 향상시키는 데 기여한다.
Dense Embedding을 활용하여 passage retrieval 실습해보기
valid_corpus = list(set([example['context'] for example in dataset['validation']]))[:10]
sample_idx = random.choice(range(len(dataset['validation'])))
query = dataset['validation'][sample_idx]['question']
ground_truth = dataset['validation'][sample_idx]['context']
if not ground_truth in valid_corpus:
valid_corpus.append(ground_truth)
print(f"Query: {query}")
print(f"Grount Truth: {ground_truth}")> Query: 갤럭시 S6엣지와 비교했을 때 S7엣지에서 증가 된 배터리 용량은?
> Grount Truth: 배터리 용량은 내장형 3600 mAh이다. 이는 디스플레이 크기를 키우면서 내부적으로 활용할 수 있는 공간이 늘었고 기기 두께도 상대적으로 두꺼워졌기 때문으로 전작인 갤럭시 S6 엣지와 비교할 때 약 1000 mAh가량 증가한 수치이며 갤럭시 S6 엣지+와 비교할 때도 약 600 mAh가량 증가한 수치로, 배터리 타임은 갤럭시 노트4 대비 약 70% 정도 오른 수준으로 체감된다고 한다. 또한, 전작인 갤럭시 S6 엣지와 마찬가지로 삼성전자 Adaptive fast charging 고속충전 솔루션과 자기유도 방식인 Qi 규격과 자기유도 방식이나, 최근 자기공진 방식의 A4WP와 호환성을 강화한 PMA 규격을 만족하는 무선충전 솔루션을 내장했으며 갤럭시 S6 엣지+의 고속 무선충전 기술까지 도입했다.하지만 누가 업데이트이후로 노트7사건으로 출력량을 완전히 줄여버려서 고속무선충전이라는 말도 의미 없어진것 같다.앞서 학습한 passage encoder, question encoder을 이용해 dense embedding 생성
def to_cuda(batch):
return tuple(t.cuda() for t in batch)
with torch.no_grad():
p_encoder.eval() # eval mode로 변환
q_encoder.eval() # eval mode로 변환
# question tokenization
q_seqs_val = tokenizer([query], padding="max_length", truncation=True, return_tensors='pt').to('cuda')
# question embedding 계산
q_emb = q_encoder(**q_seqs_val).to('cpu') #(num_query, emb_dim)
# passage embedding 계산
p_embs = []
for p in valid_corpus:
p = tokenizer(p, padding="max_length", truncation=True, return_tensors='pt').to('cuda') # 각 passage tokenization
p_emb = p_encoder(**p).to('cpu').numpy() # 각 passage embedding 구하고 p_embs에저장
p_embs.append(p_emb)
p_embs = torch.Tensor(p_embs).squeeze() # (num_passage, emb_dim)
- PyTorch 모델을 평가 모드로 설정하고, 평가 과정에서 불필요한 연산을 줄이는 작업
torch.no_grad(): 그래디언트(Gradient) 계산을 비활성화하여 메모리 사용량을 줄이고, 연산 속도를 높임.eval(): 모델을 평가 모드로 전환하여 드롭아웃(dropout)이나 배치 정규화(batch normalization) 같은 학습 시 사용하는 기능을 비활성화
print(p_embs.size(), q_emb.size())
> torch.Size([10, 768]) torch.Size([1, 768])passage 10개,embedding size 768question 1개,embedding size 768
생성된 embedding에 dot product를 수행 ⇒ Document들의 similarity ranking을 구함
dot_prod_scores = torch.matmul(q_emb, torch.transpose(p_embs, 0, 1))
dot_prod_scores.size() # torch.Size([1, 10]): [1, 768] x [768, 10] = [1, 10]rank = torch.argsort(dot_prod_scores, dim=1, descending=True).squeeze()
print(dot_prod_scores)
print(rank)
> tensor([[17.7401, 18.0048, 17.8603, 18.0238, 18.0781, 18.1710, 17.8856, 17.8471, 18.0024, 18.1475]])
> tensor([5, 9, 4, 3, 1, 8, 6, 2, 7, 0])Top-5개의 passage를 retrieve 하고 ground truth와 비교하기
k = 5
print("[Search query]\n", query, "\n")
print("[Ground truth passage]")
print(ground_truth, "\n")
for i in range(k):
print("Top-%d passage with score %.4f" % (i+1, dot_prod_scores.squeeze()[rank[i]]))
print(valid_corpus[rank[i]])[Search query]
갤럭시 S6엣지와 비교했을 때 S7엣지에서 증가 된 배터리 용량은?
[Ground truth passage]
배터리 용량은 내장형 3600 mAh이다. 이는 디스플레이 크기를 키우면서 내부적으로 활용할 수 있는 공간이 늘었고 기기 두께도 상대적으로 두꺼워졌기 때문으로 전작인 갤럭시 S6 엣지와 비교할 때 약 1000 mAh가량 증가한 수치이며 갤럭시 S6 엣지+와 비교할 때도 약 600 mAh가량 증가한 수치로, 배터리 타임은 갤럭시 노트4 대비 약 70% 정도 오른 수준으로 체감된다고 한다. 또한, 전작인 갤럭시 S6 엣지와 마찬가지로 삼성전자 Adaptive fast charging 고속충전 솔루션과 자기유도 방식인 Qi 규격과 자기유도 방식이나, 최근 자기공진 방식의 A4WP와 호환성을 강화한 PMA 규격을 만족하는 무선충전 솔루션을 내장했으며 갤럭시 S6 엣지+의 고속 무선충전 기술까지 도입했다.하지만 누가 업데이트이후로 노트7사건으로 출력량을 완전히 줄여버려서 고속무선충전이라는 말도 의미 없어진것 같다.
Top-1 passage with score 18.1710
배터리 용량은 내장형 3600 mAh이다. 이는 디스플레이 크기를 키우면서 내부적으로 활용할 수 있는 공간이 늘었고 기기 두께도 상대적으로 두꺼워졌기 때문으로 전작인 갤럭시 S6 엣지와 비교할 때 약 1000 mAh가량 증가한 수치이며 갤럭시 S6 엣지+와 비교할 때도 약 600 mAh가량 증가한 수치로, 배터리 타임은 갤럭시 노트4 대비 약 70% 정도 오른 수준으로 체감된다고 한다. 또한, 전작인 갤럭시 S6 엣지와 마찬가지로 삼성전자 Adaptive fast charging 고속충전 솔루션과 자기유도 방식인 Qi 규격과 자기유도 방식이나, 최근 자기공진 방식의 A4WP와 호환성을 강화한 PMA 규격을 만족하는 무선충전 솔루션을 내장했으며 갤럭시 S6 엣지+의 고속 무선충전 기술까지 도입했다.하지만 누가 업데이트이후로 노트7사건으로 출력량을 완전히 줄여버려서 고속무선충전이라는 말도 의미 없어진것 같다.
Top-2 passage with score 18.1475
스기우라는 파혼이 황실사에 나쁜 선례를 남길 것이며, 황태자 히로히토의 앞길에도 흠으로 남을 것이라고 주장하며 궁내성 관료들을 설득했다. 하지만 이것이 여의치 않자 스기우라는 구니노미야의 인척인 시마즈 씨 출신의 화족들을 동원했다. 그러나 야마가타와 하라가 황실의 장래를 염려하고 있다는 것과 그것의 정당성에 밀려 궁내 여론을 돌리지는 못했다. 그러던 중 오쿠보 도시미치의 차남으로 사쓰마 파의 중심 인사 중 하나였던 마키노 노부아키가 파리에서 평화 회담을 마치고 귀국하자, 스기우라의 제자이자 야하타 제철소의 장관이었던 시라니 다케시가 마키노를 설득하려 했지만 원하는 언질을 받아내지 못했고 야마모토 곤노효에도 스기우라의 간청을 들어주지 않았다.
Top-3 passage with score 18.0781
이듬해인 1968년 6월 17일, 박정희가 향토 예비군을 설치하자 그는 예비군 폐지안을 대표발의하였다. 6월 17일에 김영삼을 포함한 의원 41명은 향토예비군법 폐지안을 발표하였다. 박정희의 장기집권을 말하며 3선 개헌을 강도높게 비판하자, 공화당과 우익 인사들은 그를 좌파라며 공격했다. 그러자 김영삼 측에서는 1960년 당시 어머니가 무장공비에게 살해된 것을 들어, 만약 김영삼이 좌익이라면 무장공비들이 그의 어머니를 살해했겠느냐며 맞대응하였다. 같은 해에는 정치학도 서석재를 발탁하여 자신의 비서관으로 채용한다. 이후 서석재는 김영삼을 따랐고, 후일 1994년에는 김영삼의 리더십에 반발하는 군사 정권세력에 맞서 전직 대통령 비자금 사건을 폭로하여 군사 정권 세력을 몰락시키고, 신한국당에서 군사정권 세력을 축출, 타도하는데 기여한다.
Top-4 passage with score 18.0238
방탄소년단은 2013년 데뷔 이후 2년여 동안 학교 3부작 시즌제 앨범(2013~2014)을 발표했고, ‘꿈 없어졌지/ 숨 쉴 틈도 없이/ 학교와 집 아니면 PC방이 다인 쳇바퀴/ 같은 삶들을 살며 일등을 강요’("N.O") 등의 가사를 통해 현재의 교육 현실이나, 청소년의 꿈에 대해 본인들이 생각하는 메시지를 전달했다. 이후 청춘 2부작 시즌제 앨범(2015)를 통해서는 n포 세대("쩔어"), 수저론, 열정 페이("뱁새") 등 청춘들이 공감할 만한 소재를 다뤘다(청춘 2부작). 이처럼 꾸준히 성장한 모습을 보여준 방탄소년단은 《화양연화》 발표 이후가 전환점이 됐다는 평을 받고 있다. 또 “곡에 우리들의 이야기를 담아내며 진정성 있는 이야기를 하고 싶다”라고 밝힐만큼 각 세대별로 공감대 있는 가사를 전달하는 것을 목표로 두며 방탄소년단 앨범은 멤버들이 직접 작사작곡에 참여하고 있다. 특히 슈가와 RM은 연습생 시절부터 작사작곡, 프로듀싱을 맡아 해온 실력파 아이돌로 인정 받고 있다.
Top-5 passage with score 18.0048
영국의 방송 매체 BBC는 방탄소년단에 대해 ‘BTS: 케이팝 왕자들의 지속적인 힘’이라는 기사를 통해 “싸이가 2012년 강남 스타일로 엄청난 성공을 거뒀지만, 그 인기는 곧 잠잠해졌다. 그러나 방탄소년단은 어느 케이팝 스타도 하지 못했던 악명 높은 미국 시장을 점령했다”며 방탄소년단이 지난해 5월 빌보드 뮤직 어워즈의 ‘톱 소셜 아티스트’ 부문에서 저스틴 비버를 제친 점을 비롯해 지난해 ‘빌보드 200’차트와 미국 아이튠즈 차트 등을 휩쓸고 “방탄소년단은 소셜미디어에서도 역사를 다시 썼다”고 평가했으며, 방탄소년단이 큰 인기를 끄는 비결로 세심하게 유지하는 팬과의 소통을 꼽으며 방탄소년단의 인기 비결을 집중 분석하기도 했다.Dense Embedding은 질문과 패시지를 동일한 벡터 공간에 임베딩한 후 유사도를 계산하는 방식으로 단순히 검색어가 포함된 문서뿐만 아니라, 문맥적 유사성이 높은 패시지를 검색할 수 있다. 이로 인해 정보 검색의 정밀도가 대폭 향상되었으며, 답변의 질 또한 높아졌다. FAISS와 같은 라이브러리를 통해 대규모 패시지 집합에서 유사도를 빠르게 계산하고, 높은 성능의 검색을 가능하게 하기도 한다. 하지만 Dense Embedding에도 한계가 존재한다. 모든 패시지를 임베딩하고 이를 빠르게 검색하기 위해 추가적인 인덱싱 작업이 필요한데, 특히 대규모 데이터셋을 다룰 때는 FAISS와 같은 라이브러리를 사용하더라도 연산 자원이 많이 소모된다. 또한, Dense Embedding 모델이 학습된 도메인에 특화된 성능을 보이는 경우가 많기 때문에, 새로운 도메인에 적용하려면 추가적인 학습이나 파인튜닝이 필요할 수 있다.
Dense Embedding은 현대 정보 검색에서 기존의 한계를 뛰어넘어, 더 정교하고 의미 기반의 검색을 가능하게 한다. 위와 같은 한계점이 존재함에도 불구하고, 그만큼 더 나은 검색 품질을 보장하기 때문에 앞으로도 다양한 검색 시스템에서 중요한 역할을 할 것으로 기대된다. 현재의 연구도 이러한 Dense Retrieval의 한계를 극복하는 방향으로 진행되고 있어, 앞으로 더 빠르고 정확한 검색 결과를 기대할 수 있다.
