프로젝트 개요
"서울의 GDP는 세계 몇 위야?", "MRC가 뭐야?"
우리는 궁금한 것들이 생겼을 때, 아주 당연하게 검색엔진을 활용하여 검색을 합니다. 이런 검색엔진은 최근 기계독해(MRC, Machine Reading Comprehension) 기술을 활용하며 매일 발전하고 있습니다. 본 대회는 우리가 당연하게 활용하던 검색엔진, 그것과 유사한 형태의 시스템을 만들어 보는 것을 목표로 합니다.
Question Answering(QA)은 다양한 종류의 질문에 대해 대답하는 인공지능을 만드는 연구 분야입니다.
다양한 QA 시스템 중, Open-Domain Question Answering(ODQA)은 주어지는 지문이 따로 존재하지 않고 사전에 구축되어있는 Knowledge resource에서 질문에 대답할 수 있는 문서를 찾는 과정이 추가되기 때문에 더 어려운 문제입니다.

ODQA 모델은 two-stage로 구성되어 있습니다. 첫 단계는 질문에 관련된 문서를 찾아주는 "retriever" 단계이고, 다음으로는 관련된 문서를 읽고 적절한 답변을 찾거나 만들어주는 "reader" 단계입니다. 두 가지 단계를 각각 구성하고 그것들을 적절히 통합하게 되면, 어려운 질문을 던져도 답변을 해주는 ODQA 시스템을 만들 수 있습니다.
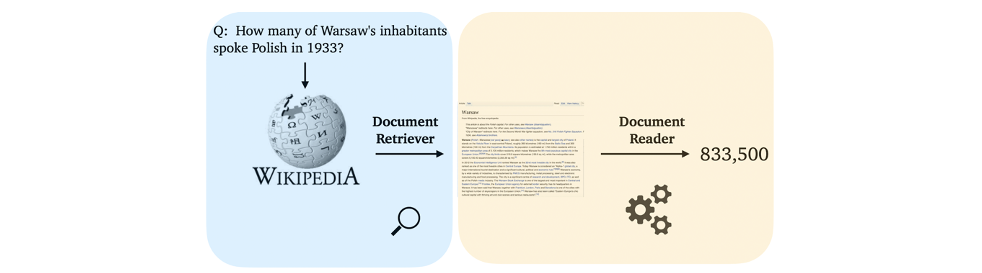
최종적으로 테스트해야하는 결과물은 아래와 같습니다.
- input: Query
- output: 주어진 Query에 알맞는 string 형태의 답안
Machine Reading Comprehension(MRC)
- 기계 독해(MRC)
- 주어진 지문(context)을 이해하고, 주어진 질의(Query/Question)의 답변을 추론하는 문제
- 즉, 인공지능이 사람처럼 문서를 읽고 이해한 후 질문에 정확히 답하는 기술
- MRC 종류
- Extractive Answer
- 질의(question)에 대한 답이 항상 주어진 지문(context)의 segment(or span)으로 존재
- Datasets: SQuAD, KorQuAD, NewsQA, Natural Questions, etc
- Descriptive/Narrative Answer
- 답이 지문 내에서 추출한 span이 아니라, 질의를 보고 생성된 sentence(or free-form)의 형태
- Datasets: MS MARCO, Narrative QA
- Multiple-choice
- 질의에 대한 답을 여러 개의 answer candidates 중 하나로 고르는 형태
- Datasets: MCTest, RACE, ARC, etc
- Extractive Answer
Extraction-based MRC와 Generation-based MRC 중 어떤 것이 현대에 더욱 선호 되고 있을까요?
- 특정 도메인에서는 텍스트에서 정확하게 답을 추출하는 것이 중요하여, 실제 필드에서 Extraction-based MRC가 많이 사용되고 있습니다.
- 하지만, 현대의 연구 흐름을 보면 Generation-based MRC가 주목 받고 있는데, 그 이유는 아래와 같습니다.
- 유연한 답변 생성: Extraction-based MRC는 주어진 텍스트에서 정해진 부분을 추출하는 방식이기에 답변이 텍스트에 명확하게 포함되어야 합니다. 반면, Generation-based MRC는 모델이 문맥을 이해하고 주어진 질문에 대해 자연어로 답변을 직접 생성할 수 있어 유연한 대응이 가능합니다.
- Open-domain QA의 발전: Open-domain QA에서는 주어진 문서에서 명확한 정답을 찾는 것이 어려운 경우가 많은데, Generation-based MRC 모델은 다양한 정보를 종합하여 새로운 문장을 만들어 답을 줄 수 있습니다.
- 대규모 언어 모델의 등장: GPT, Claude와 같은 대규모 언어 모델의 등장으로 자연어 생성 능력이 크게 향상되었습니다.
Challenges in MRC
-
단어들의 구성이 유사하지는 않지만, 동일한 의미의 문장을 이해하려 할 때
- DuoRC (paraphrased paragraph)
- context와 query 간 단어들의 구성이 유사할 때는 답을 찾기 쉬움
- 하지만 context와 query 간 단어들의 구성이 paraphrasing 형태로 주어질 때, 답을 찾기가 어려워짐
- context와 query 간 단어들의 구성이 유사할 때는 답을 찾기 쉬움
- QuoRef (coreference resolution)
- 대명사가 지칭하는 것을 찾아내려할 때, 답을 찾기가 어려워짐
- 대명사가 지칭하는 것을 찾아내려할 때, 답을 찾기가 어려워짐
- DuoRC (paraphrased paragraph)
-
주어진 지문에서는 질문에 대한 답을 찾을 수 없음에도 답을 주려 할 때 (Unanswerable questions)
Article: Endangered Species Act Paragraph: ... Other legislation followed, including the Migratory Bird Conservation Act of 1929, a 1937 treaty prohibiting the hunting of right and gray whales, and the Bald Eagle Protection Act of 1940. These later laws had a low cost to society—the species were relatively rare—and little opposition was raised. Question 1: Which laws faced significant opposition? Plausible Answer: later laws Question 2: What was the name of the 1937 treaty? Plausible Answer: Bald Eagle Protection Act질의에 답변하기 위해 필요한 정보가 주어진 문서 내에 제공되지 않음에도 불구하고 모델은 문서내에서 답을 추출하려는 경향이 있음
- 여러 개의 문서에서 질의에 대한 supporting fact를 찾아야지만 답을 찾을 수 있을 때 (Multi-hop reasoning)
질의에 등장하는 개념, 대상 등의 속성이 여러 문서에 걸쳐서 분포하는 경우 모델은 여러 문서를 보고 어떤 문서에서 근거를 찾을지 판단하는 능력이 있어야 함Doc1: Big Oak Tree State Park is a stat-owned nature preserve ... in the Mississippi Alluvial Plain portion of the Gulf Coastal Plain. Doc2: The Gulf Coastal Plain extends around the Gulf of Mexico in the Southern United States... Doc3: The Southern United States, commonly referred to as the American South, Dixie, or simply the South, is a region of the United States of America. Q: Where Big Oak Tree State Park is located in? A: United States of America Reasoning Hop: (Doc1) Big Oak Tree State Park is in Gulf Coastal Plain. -> (Doc2) Gulf Coastal Plain is in Southern United States. -> (Doc3) Southern United States is in United States of America.
MRC 평가 방법
- For extractive answer and multiple-choice answer datasets
- Exact Match(EM): 모델이 생성한 답변과 정답이 완벽하게 일치하는 비율을 측정
- F1 Score: 모델이 생성한 답변과 정답 사이의 정밀도(Precision)와 재현율(Recall)의 조화 평균을 측정
- Exact Match(EM): 모델이 생성한 답변과 정답이 완벽하게 일치하는 비율을 측정
- For descriptive answer datasets
- 모델이 생성한 문장과 참조 문장의 단어 순서를 고려하여 오버랩하는 부분을 측정- ROUGE Score: 예측한 값과 ground-truth 사이의 overlap recall
- ROUGE-L : 가장 긴 공통부분 열(Longest Common Subsequence)을 기반으로 일치도를 측정
- 참조 문장이 생성된 문장에 얼마나 잘 반영되었는지를 측정하는 지표
- 관련 논문 : https://aclanthology.org/W04-1013/
- BLEU(Bilingual Evaluation Understudy): 예측한 답과 ground-truth 사이의 precision
- BLEU-n : 일치하는 n-gram의 수를 계산하는 n-gram 정밀도를 측정
- 생성된 문장이 참조 문장과 얼마나 유사한지를 측정하는 지표
- 관련 논문 : https://aclanthology.org/P02-1040/
- ROUGE Score: 예측한 값과 ground-truth 사이의 overlap recall
KorQuAD Dataset
- KorQuAD
- LG CNS가 AI 언어지능 연구를 위해 공개한 질의응답/기계 독해 한국어 데이터셋
- 인공지능이 한국어 질문에 대한 답변을 하도록 필요한 학습 데이터셋
- 1,550개의 위키피디아 문서에 대해서 10,649건의 하위 문서들과 크라우드 소싱을 통해 제작한 63,952개의 질의응답 쌍으로 구성되어 있음
- 누구나 데이터를 내려받고, 학습한 모델을 제출하고 공개된 리더보드에 평가를 받을 수 있음
→ 객관적인 기준을 가진 연구 결과 공유가 가능해짐 - 현재 v1.0, v2.0 공개: 2.0은 보다 긴 분량의 문서가 포함되어 있으며, 단순 자연어 문장 뿐 아니라복잡한 표와 리스트 등을 포함하는 HTML 형태로 표현되어 있어 문서 전체 구조에 대한 이해가 필요
- KorQuAD 데이터 수집 과정
- SQuAD v1.0의 데이터 수집 방식을 벤치마크하여 표준성을 확보함
- 대상 문서 수집
- 위키 백과에서 수집한 글들을 문단 단위로 정제, 이미지/표 /URL 제거
- 짧은 문단, 수식이 포함된 문 단 등 제거
- 질문/답변 생성
- 크라우드 소싱을 통해 질의응답 70,000+쌍 생성
- 크라우드 소싱: 생산과 서비스의 과정에 소비자 혹은 대중을 참여시켜 더 나은 제품, 서비스를 만들고 수익을 참여자와 공유하고자하는 방법
- 작업자가 양질의 질의응답 쌍을 생성하도록 상세한 가이드라인을 제시함
- 2차 답변 태깅
- 앞에서 생성한 질문에 대해 사람이 직접 답해보면서 Human performance 측정
- 앞서 질문/답변 생성 과정에 참여한 사람은 참여 불가
- HuggingFace datasets
- HuggingFace에서 만든 datasets는 자연어처리에 사용되는 대부분의 데이터셋과 평가 지표를 접근하고 공유할 수 있게끔 만든 라이브러리
- 접근가능한 모든 데이터셋이 memory-mapped, cached 되어있어 데이터를 로드 하면서 생기는 메모리 공간 부족이나 전처리 과정 반복의 번거로움 등을 피할 수 있음
- KorQuAD 데이터셋의 경우 squad_kor_v1, squad_kor_v2 로 불러올 수 있음
from datasets import load_dataset dataset = load_dataset('squad _kor_v1', split='train')
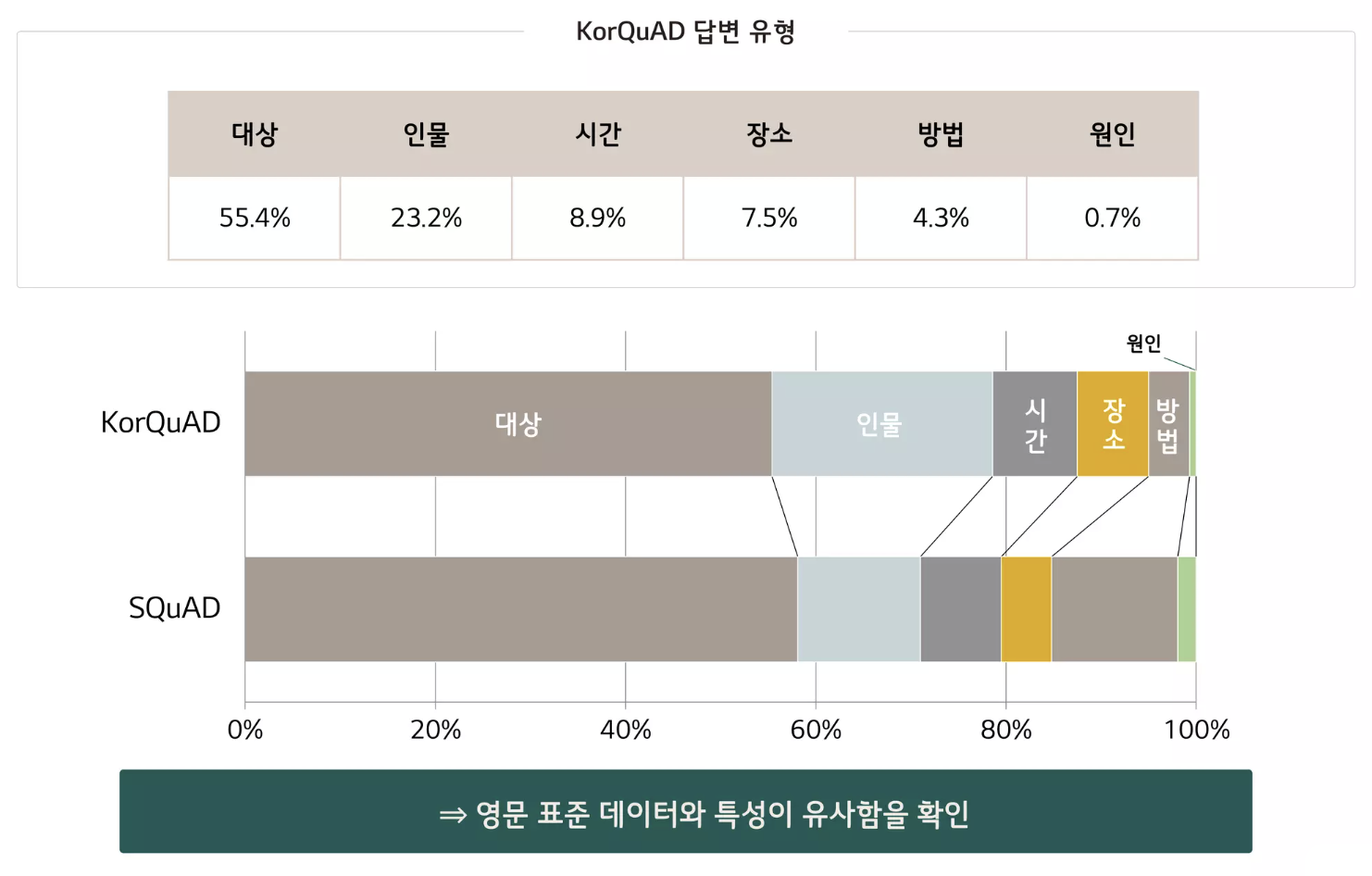
- KorQuAD 통계치

Reference
https://www.lgdlab.or.kr/contents/5
https://www.slideshare.net/slideshow/mrc-korquad-b2b-mrc/134331610#9
