
💡 Merge Two Sorted Lists
You are given the heads of two sorted linked lists list1 and list2.
Merge the two lists in a one sorted list. The list should be made by splicing together the nodes of the first two lists.
Return the head of the merged linked list.
Example 1:
Input: list1 = [1,2,4], list2 = [1,3,4]
Output: [1,1,2,3,4,4]Example 2:
Input: list1 = [], list2 = []
Output: []Example 3:
Input: list1 = [], list2 = [0]
Output: [0]Constraints:
- The number of nodes in both lists is in the range
[0, 50]. -100 <= Node.val <= 100- Both
list1andlist2are sorted in non-decreasing order.
Solution
순수 나의 실력으로 푼 알고리즘은 이렇다
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode *curr1 = list1;
ListNode *curr2 = list2;
ListNode *head;
if (!list1) return list2;
if (!list2) return list1;
if (list1->val <= list2->val) {
head = curr1;
curr1 = curr1->next;
} else{
head = curr2;
curr2 = curr2->next;
}
ListNode *cur = head;
while (curr1 || curr2) {
if (!curr1) {
cur->next = curr2;
break;
}
if (!curr2) {
cur->next = curr1;
break;
}
if (curr1->val <= curr2->val) {
cur->next = curr1;
cur = cur->next;
curr1 = curr1->next;
} else {
cur->next= curr2;
cur = cur->next;
curr2 = curr2->next;
}
}
return head;
}
}; .
.
.
코드가 길고,, 그냥 직관적이다
답안을 보자
.
.
엥 똑같네 ㅎ (굳
💡 Reorder List
You are given the head of a singly linked-list. The list can be represented as:
L0 → L1 → … → Ln-1 → LnReorder the list to be on the following form:
L0 → Ln → L1 → Ln-1 → L2 → Ln-2 → …You may not modify the values in the list's nodes. Only nodes themselves may be changed.
Example 1:
Input: head = [1,2,3,4]
Output: [1,4,2,3]Example 2:
Input: head = [1,2,3,4,5]
Output: [1,5,2,4,3]Constraints:
- The number of nodes in the list is in the range
[1, 5 * 104]. 1 <= Node.val <= 1000
Solution
- 가운데 노드를 찾고
- 반으로 나눠서
- 2nd half를 reverse해서
- merge!
... 아우 이거 포인터 되게 헷갈린다
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
void reorderList(ListNode* head) {
if (head == NULL) return;
ListNode *prev = NULL; // used to divide the list in half
ListNode *slow = head; // when this run in speed 1
ListNode *fast = head; // this will run in speed 2
while (fast && fast->next) {
prev = slow;
slow = slow->next;
fast = fast->next->next;
}
prev->next = NULL;
// 이렇게 리스트를 반으로 나누면 홀수 리스트의 경우엔 list2가 1개 더 많은 element를 가진다
ListNode *list1 = head;
ListNode *list2 = reverse(slow);
merge(list1, list2);
}
private:
ListNode *reverse(ListNode *head) {
ListNode *prev = NULL;
ListNode *curr = head;
ListNode *next = head->next;
while (curr) {
next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}
void merge(ListNode *list1, ListNode *list2) {
while (list1) {
ListNode *p1 = list1->next;
ListNode *p2 = list2->next;
list1->next= list2;
if (p1 == NULL) break;
list2->next = p1;
list1 = p1;
list2 = p2;
}
}
};💡 Remove Nth Node From End of List
Given the head of a linked list, remove the nth node from the end of the list and return its head.
Example 1:
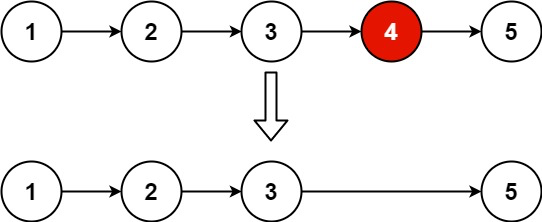
Input: head = [1,2,3,4,5], n = 2
Output: [1,2,3,5]Example 2:
Input: head = [1], n = 1
Output: []Example 3:
Input: head = [1,2], n = 1
Output: [1]Solution
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
// Create 2 pointers "n" apart, iterate until end, will be at nth
ListNode *p1 = head;
ListNode *p2 = head;
for (int i = 0; i < n; i++) {
// make p2 "n" apart from p1
ListNode *temp = p2;
p2 = temp->next;
}
if (p2 == NULL) {
// the head is what we need to remove
return head->next;
}
// increment the pointer until p2->next reaches NULL
// then p1 will be (n-1)th node from the end
while (p2->next != NULL) {
ListNode *p1_temp = p1;
ListNode *p2_temp = p2;
p1 = p1_temp->next;
p2 = p2_temp->next;
}
// remove p1->next
p1->next = p1->next->next;
return head;
}
};💡 Copy List with Random Pointer
A linked list of length n is given such that each node contains an additional random pointer, which could point to any node in the list, or null.
Construct a deep copy of the list.
Return the head of the copied linked list.
The linked list is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representing Node.valrandom_index: the index of the node (range from0ton-1)that the random pointer points to, ornullif it does not point to any node.
Your code will only be given the head of the original linked list.
Example 1:
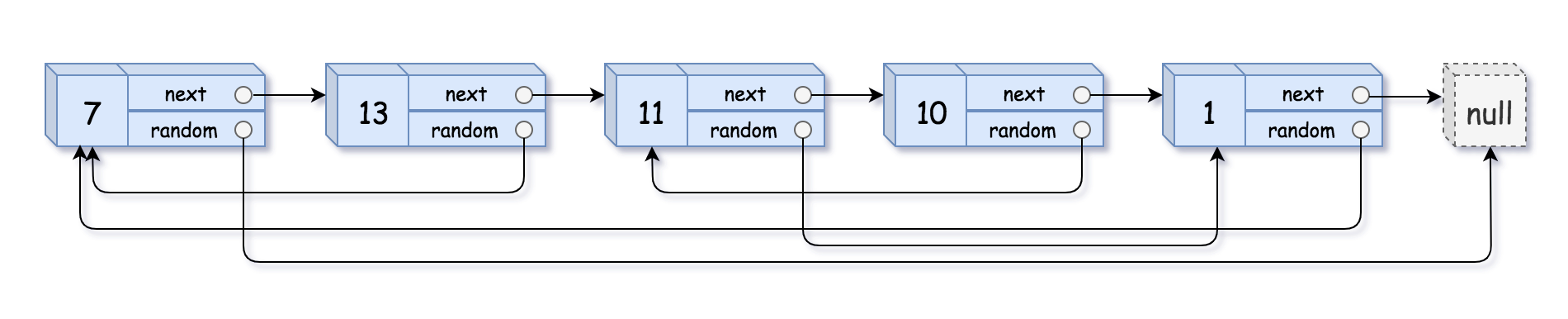
Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]Example 2:

Input: head = [[1,1],[2,1]]
Output: [[1,1],[2,1]]Example 3:

Input: head = [[3,null],[3,0],[3,null]]
Output: [[3,null],[3,0],[3,null]]Solution
내가 혼자 짜던 코드랑 아이디어는 같은데,
random clone을 만들 때 아직 안만들어진 Node * 가 들어가면 null로 결과값이 나와서
getCloneNode 함수를 만들어서 새로 만들 node가 next이든 random이든 제약을 받지 않도록 하자
class Solution {
public:
Node* copyRandomList(Node* head) {
if (head == NULL) {
return NULL;
}
Node* oldNode = head;
Node* newNode = new Node(oldNode->val);
visited[oldNode] = newNode;
while (oldNode != NULL) {
newNode->next = getClonedNode(oldNode->next);
newNode->random = getClonedNode(oldNode->random);
oldNode = oldNode->next;
newNode = newNode->next;
}
return visited[head];
}
private:
unordered_map<Node*, Node*> visited;
Node* getClonedNode(Node* node) {
if (node == NULL) {
return NULL;
}
if (visited.find(node) != visited.end()) {
return visited[node];
}
visited[node] = new Node(node->val);
return visited[node];
}
};💡 Two Numbers
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
Example 1:
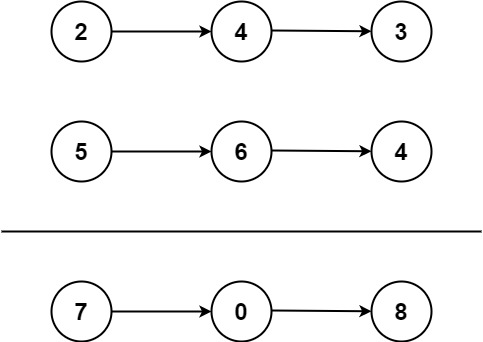
Input: l1 = [2,4,3], l2 = [5,6,4]
Output: [7,0,8]
Explanation: 342 + 465 = 807.Example 2:
Input: l1 = [0], l2 = [0]
Output: [0]Example 3:
Input: l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
Output: [8,9,9,9,0,0,0,1]Solution
10올림을 어떻게 하느냐,,,
reverse linked list로 되어있으니까 첫번째 node부터 가면 자연스레 1의 자리수부터 계산하게되니 .. 쉽네!
음 내가 짠거랑 로직 자체는 비슷한데 ,,
몇가지 efficient 한 코드를 유의하자
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* dummy = new ListNode();
ListNode* curr = dummy; // efficient
int carry = 0;
while (l1 || l2) {
int val1 = (l1) ? l1->val : 0;
int val2 = (l2) ? l2->val : 0;
int sum = val1 + val2 + carry;
carry = sum / 10; // efficient
curr->next = new ListNode(sum % 10); // efficient
curr = curr->next;
if (l1 != NULL) {
l1 = l1->next;
}
if (l2 != NULL) {
l2 = l2->next;
}
}
if (carry == 1) { // 마지막꺼 올림 깜빡하지 않도록~
curr->next = new ListNode(1);
}
return dummy->next; // efficient
}
};💡 Linked List Cycle
Given head, the head of a linked list, determine if the linked list has a cycle in it.
There is a cycle in a linked list if there is some node in the list that can be reached again by continuously following the next pointer. Internally, pos is used to denote the index of the node that tail's next pointer is connected to. Note that pos is not passed as a parameter.
Return true if there is a cycle in the linked list. Otherwise, return false.
Example 1:
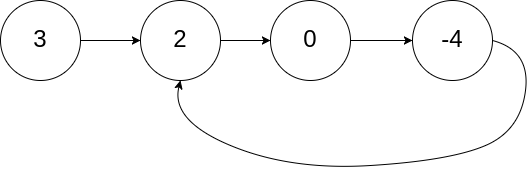
Input: head = [3,2,0,-4], pos = 1
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 1st node (0-indexed).Example 2:
Input: head = [1,2], pos = 0
Output: true
Explanation: There is a cycle in the linked list, where the tail connects to the 0th node.Example 3:
Input: head = [1], pos = -1
Output: false
Explanation: There is no cycle in the linked list.Solution
뭐,, hash set 쓰는 방법이 제일 먼저 떠오르지만 ,,
Floyd's Tortoise & Hare 이라는 알고리즘이 있나부다 ,,
이걸쓰면 space complexity가 O(1)에 풀수 있나부다 ,,,
함 보자 ..
slow pointer → shifted by one
fast pointer → shifted by two
만약 사이클이 존재한다면 slow == fast 인 순간이 올 거래 ,, 그것도 in linear time!
왜??
왜냐면 ,, slow pointer 와 fast pointer 사이의 갭이 10이라고 치고,
slow는 +1씩 가고, fast는 +2씩 가니까
5 +1-2 +1-2 ... so on and this will eventually reach 0 (where slow == fast ! !
why is this linear?
think about the maximum possible gap between slow and fast
it would be number of nodes!
then {number of nodes} +1-2 +1-2 ... so this is linear!
wow
class Solution {
public:
bool hasCycle(ListNode *head) {
bool hasCycle(ListNode *head) {
if (head == NULL) {
return false;
}
ListNode* slow = head;
ListNode* fast = head;
while (fast->next != NULL && fast->next->next != NULL) {
slow = slow->next;
fast = fast->next->next;
if (slow == fast) {
return true;
}
}
// when fast and slow are both null, then there is no cycle!
return false;
}
}
};💡 Find Duplicate Number
Given an array of integers nums containing n + 1 integers where each integer is in the range [1, n] inclusive.
There is only one repeated number in nums, return this repeated number.
You must solve the problem without modifying the array nums and uses only constant extra space.
Example 1:
Input: nums = [1,3,4,2,2]
Output: 2Example 2:
Input: nums = [3,1,3,4,2]
Output: 3Solution
위에 설명한 Floyd's Tortoise & Hare 알고리즘을 쓰면 되겠다!
싸이클이 있다고 가정하고 계속 돌면서
slow 와 fast가 가르키는 값이 같으면 그것이 duplicate!
.. 어 근데 인풋이 vector네..?
자자 ,, 생각해보자
vector에 있는 value들을 pointer로 생각해보면 !
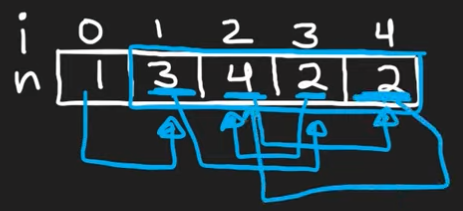
약간 이런식으로 그 value의 index이외 중 하나를 가르킬 것이다
그리고 vector엔 duplicate이 있으니까 cycle이 있을것!
그리고 그 싸이클은 항상 이런식으로 두개의 node만 사이클 하는 형식일 것이다!
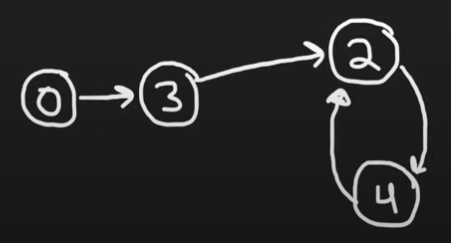
그리고, 중요한것은
들어오는 포인터가 2개인 node가 중복인 숫자라는 것이다 (also it is the start of the cycle)
(위의 그림에선 2가 되겠다)
class Solution {
public:
int findDuplicate(vector<int>& nums) {
// slow and fast are always in-bound
int slow = nums[0];
int fast = nums[nums[0]];
// finding the intersection point of the two runners
while (slow != fast) {
slow = nums[slow];
fast = nums[nums[fast]]; //advancing fast twice!
}
// fast and slow intersects
// finding the entrance to the cycle
slow = 0;
while (slow != fast) {
slow = nums[slow];
fast = nums[fast];
}
return slow;
}
};.. 아우 헷갈려
💡 LRU cache
Design a data structure that follows the constraints of a Least Recently Used (LRU) cache.
Implement the LRUCache class:
LRUCache(int capacity)Initialize the LRU cache with positive size capacity.int get(int key)Return the value of the key if the key exists, otherwise return -1.void put(int key, int value)Update the value of the key if the key exists. Otherwise, add the key-value pair to the cache. If the number of keys exceeds the capacity from this operation, evict the least recently used key.
The functions get and put must each run in O(1) average time complexity.
Solution
Hashmap + doubly linked list
left = LRU, right = MRU
get: update to MRU
put: update to MRU
remove LRU if full
class Node {
public:
int k;
int val;
Node* prev;
Node* next;
Node(int key, int value) {
k = key;
val = value;
prev = NULL;
next = NULL;
}
};
class LRUCache {
private:
int cap;
unordered_map<int, Node*> cache; // {key -> node}
Node* left;
Node* right;
public:
LRUCache(int capacity) {
cap = capacity;
// 양 끝은 모두 placeholder이다 (just to be free from handling null pointer )
left = new Node(0, 0);
right = new Node(0, 0);
left->next = right;
right->prev = left;
}
int get(int key) {
if (cache.find(key) != cache.end()) {
remove(cache[key]);
insert(cache[key]);
return cache[key]->val;
}
return -1;
}
void put(int key, int value) {
if (cache.find(key) != cache.end()) {
remove(cache[key]);
}
cache[key] = new Node(key, value);
insert(cache[key]);
if (cache.size() > cap) {
// delete LRU from map & remove from list
// since left is a place holder, left->next is the LRU
cache.erase(left->next->k);
remove(left->next);
}
}
private:
// remove node from list
void remove(Node* node) {
Node* prev = node->prev;
Node* next = node->next;
prev->next = next;
next->prev = prev;
}
// insert node at right
void insert(Node* node) {
Node* prev = right->prev;
Node* next = right; // the placeholder
prev->next = node;
next->prev = node;
node->prev = prev;
node->next = next;
}
};