1. Deep Learning
2. 다층 퍼셉트론 (multi-layer perceptron), MLP
3. AutoRec
1. Deep Learning
- 딥러닝의 장점
- Nonlinear Transform : 데이터가 가진 비선형의 특징을 효과적으로 나타내고 모델링할 수 있다.
-> 복잡한 유저-아이템 상호작용 모델링 - 전통적인 모델이 표현할 수 없는 복잡한 상호작용을 학습하게 한다.
- 주어진 raw 데이터로부터 feature representation을 학습한다.
- 다양한 종류의 데이터를 feature로 사용할 수 있다.
- Sequence Modeling : 음성, 자연어 처리 등에서 좋은 성능을 보인다.
- Nonlinear Transform : 데이터가 가진 비선형의 특징을 효과적으로 나타내고 모델링할 수 있다.
2. 다층 퍼셉트론 (multi-layer perceptron), MLP
-
다층 퍼셉트론 (multi-layer perceptron, MLP) : 여러 개의 노드로 이루어진 layer를 순차적으로 쌓은 구조 (feed-forward neural network)
-
기존 MF의 한계
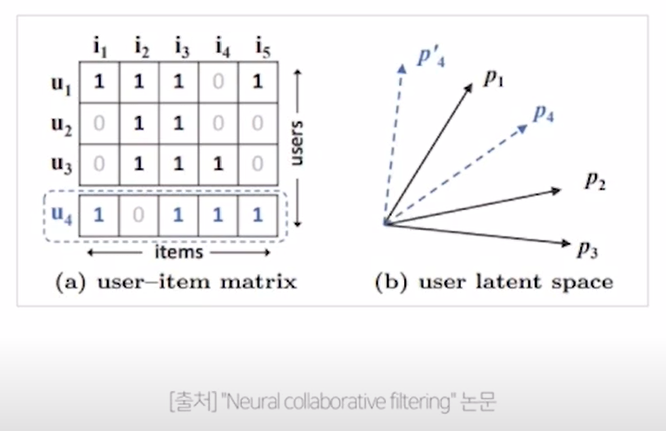
- 유저 4는 가장 유사한 유저 1과 제일 가까운 위치에 놓여야 한다. 그래서 공간으로 표현하면 우측의 파란 점선처럼 놓이게 된다.
다음으로 유사한 유저 3이 이론적으로는 p4 / p'4 다음으로 가까워야 하지만 덜 비슷한 유저 2보다도 멀리 놓이게 된다는 모순이 발생한다.
- 유저 4는 가장 유사한 유저 1과 제일 가까운 위치에 놓여야 한다. 그래서 공간으로 표현하면 우측의 파란 점선처럼 놓이게 된다.
-
Neural Collaborative Filtering : MF(linear model)에 MLP layer를 적용한 기법
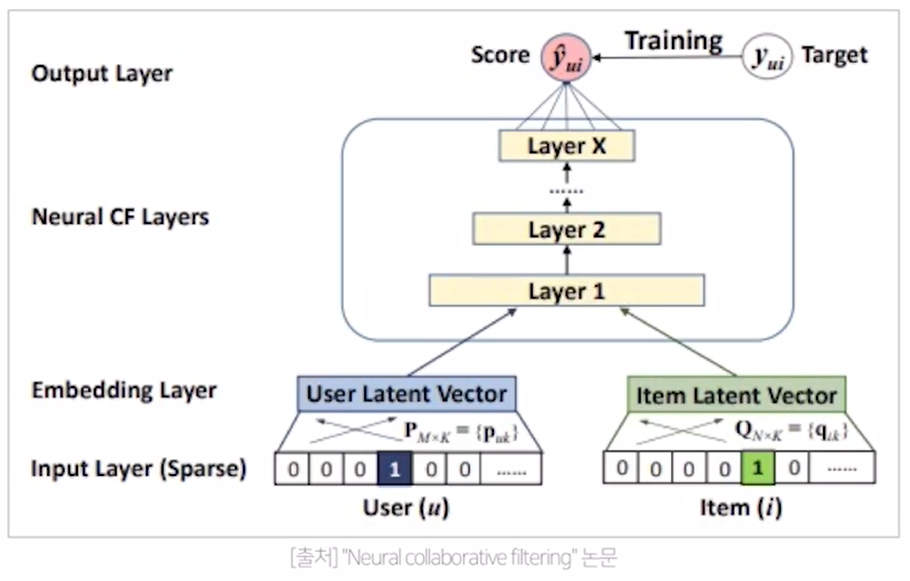
- input layer : 유저와 아이템의 one-hot encoding vector
- embedding matrix를 통하여 각각의 유저와 아이템이 dense한 형태로 embedding
- neural collaborate layers : 일반적인 MLP layer와 동일
-> 각각의 user latent vetcor / item latent vector를 구한 이후에 이 둘을 concat해서 첫 번째 레이어를 만든다.
-> layer를 계속 쌓아서 feed-forward neural network 형태로 만든다.
-> 마지막의 layer X에서 y hat(유저와 아이템에 대한 rating과의 차이)을 구한다. - 마지막 layer의 activation function을 거쳐서 target은 0 or 1
-
Neural Collaborative Filtering의 최종 모델
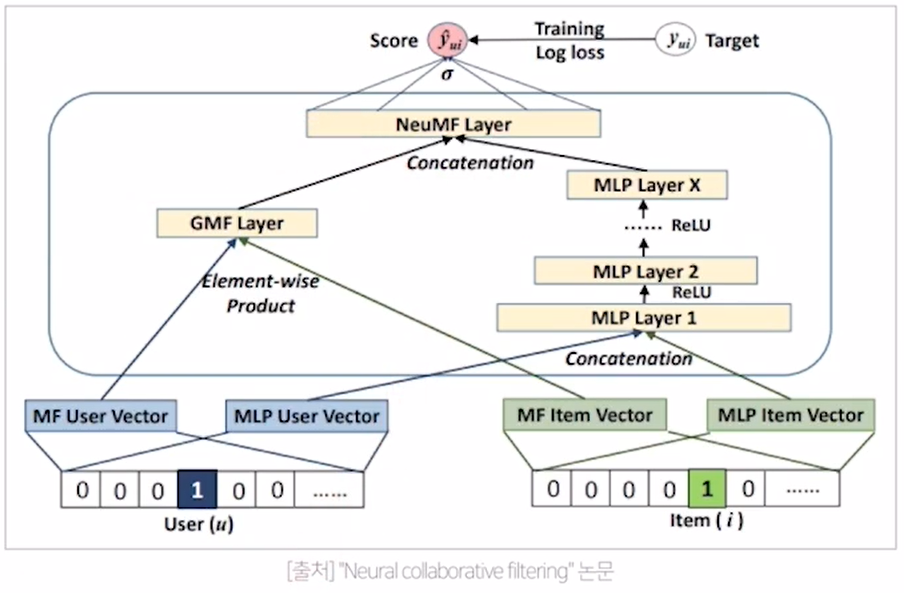
- GMF(MF를 일반화한 모델)와 MLP의 각각의 장점은 살리고 단점은 보완하기 위해서 GMF layer, MLP layer를 따로 만든다.
- GMF의 user embedding과 MLP의 user embedding은 다른 embedding layer를 사용한다.
3. AutoRec
-
AutoRec (Autoencoders Meet Collaborative Filtering) : 기존의 auto encoder를 collaborative filtering에 적용하여 유저와 아이템에 대한 embedding을 더 잘 표현하고 복잡도는 낮춘 모델
-> 유저와 아이템의 embedding을 auto encoder를 활용해 더 좋은 representation을 만들 수 있다. -
non-linear activation function을 사용하기 때문에 더 복잡한 유저와 아이템의 상호작용을 표현할 수 있다.
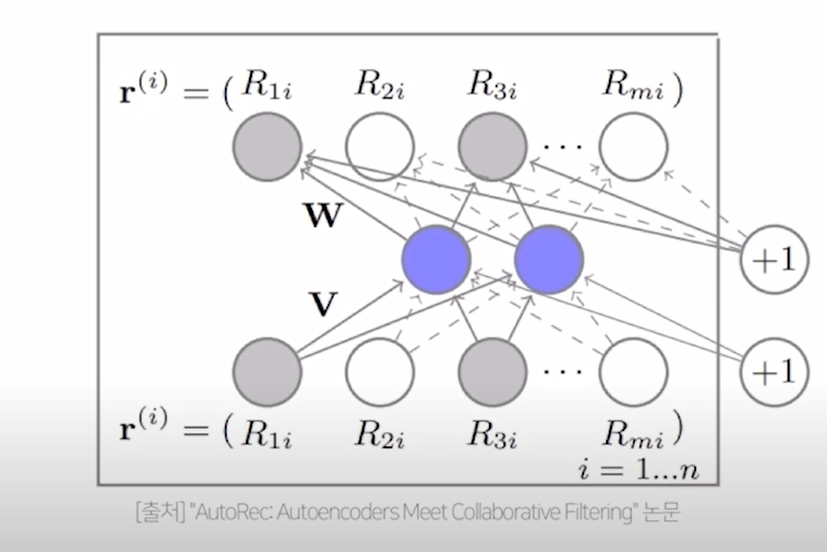
- input & output은 각각의 아이템의 rating vector, 개별 유저의 평점으로 이루어져 있으므로 m차원 (유저 전체의 수)
- rating vector는 V(encoder의 가중치행렬)와 곱해진 뒤 dense representation으로 표현 (그림 상 보라색 영역)
- 위의 과정에서 생성된 dense representation은 W(decoder의 가중치행렬)과 곱해진 뒤 다시 원래의 rating matrix인 m차원의 아이템 벡터로 복원
- 학습 방법
- 기존의 rating과 reconstructed rating의 RSME (둘의 차이의 제곱에 루트를 씌운 값)을 최소화하는 방향으로 학습
- 관측된 데이터만 학습, 관측된 데이터의 loss만으로 파라미터 업데이트
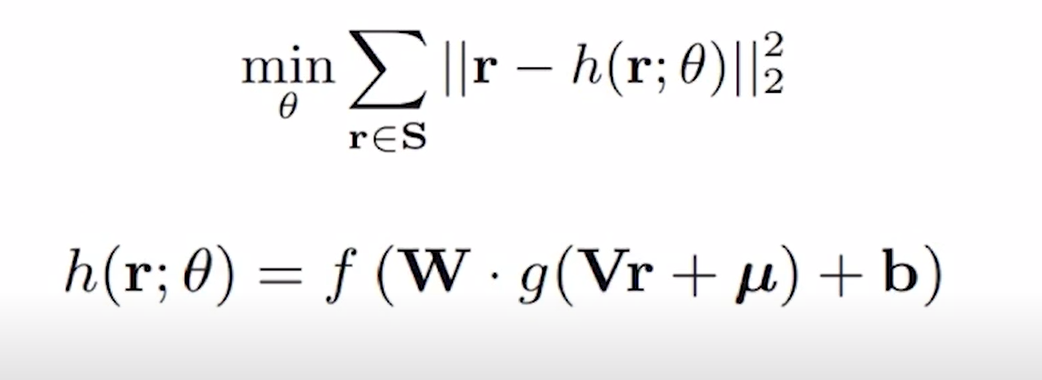
-> h : autoencoder function
-> V : encoder의 가중치 매트릭스
-> g : activation function
-> W : decoder의 매트릭스
