1. Word2Vec
(1) 개요
(2) 학습 방법2. Item2Vec
(1) 개요
(2) 학습 과정3. Approximate Nearest Neighbor (ANN)
1.Word2Vec
(1) 개요
- 임베딩 (Embedding) : 주어진 데이터를 그보다 낮은 차원의 벡터로 만들어 표현하는 방법
- Sparse Representation : 아이템의 전체 수와 차원의 수가 같음, one-hot encoding 또는 multi-hot encoding으로 표현
- Dense Representation : 아이템의 전체 수보다 작은 차원, 실수값으로만 이루어진 벡터로 표현
- 워드 임베딩 (Word Embedding) : NLP 분야에서 텍스트를 분석하기 위해 단어를 dense한 임베딩으로 표현하는 방법
- input과 output 사이에 하나의 layer로만 이루어진 가장 간단한 모델
- 대량의 문서 dataset을 벡터 공간에 투영하면 각각의 단어가 압축된 형태로 dense한 embedding이 된다.
- 모델의 structure 자체가 간단하기 때문에 효율적
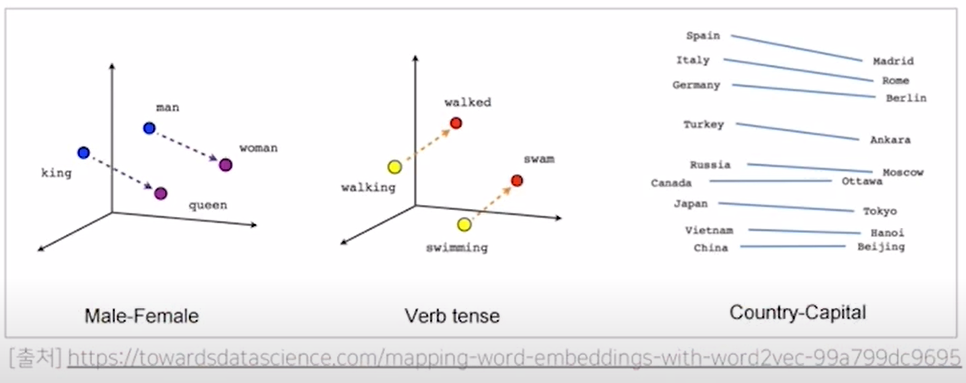
-> 각 단어의 embedding 관계를 보면, 'Male-Female' 그림에서 (king, queen)과 (man, women)이 매우 유사하다. 단어는 embedding하면서 의미의 유사도를 학습하므로 두 벡터가 거의 동일한 값을 가지게 된다.
(2) 학습 방법
- Continuous Bag of Words (CBOW) : 가운데에 위치한 단어를 앞뒤 n개의 단어를 사용해서 예측하는 방법
- 학습 파라미터는 다음의 두가지이다. (V : 단어의 총 개수, M : 임베딩 벡터 사이즈)
- 학습 파라미터는 다음의 두가지이다. (V : 단어의 총 개수, M : 임베딩 벡터 사이즈)
- Skip-Gram : CBOW의 입력층과 출력층이 반대로 된 모델, 수행하는 과정은 동일하다.
-> 주어진 단어로, 예측해야 하는 주변 단어들을 classification하는 multi-class classification
- Skip-Gram with Negative Sampling (SGNS) : Skip-Gram에서 입력과 레이블이었던 단어들을 모두 입력값으로 바꾸고, 입력값들이 서로 주변에 있다면 1, 없다면 0을 예측하는 binary classification
- 최종적으로 추천 모델에 사용할 Item2Vec의 학습 방법과 동일
- 'Negative Sampling' 인 이유?
-> Skip-Gram의 입력과 레이블을 SGNS에서 모두 입력값으로 바꾸면 자동으로 레이블은 1을 예측함으로 모든 레이블이 1만 존재, 주변에 있지 않은 데이터는 Skip-Gram에서 사용하지 않았기 때문에 주변에 있지 않은 단어들을 강제로 sampling해야 함 (이 경우에 레이블은 0)
-> Negative Sampling의 개수는 모델의 하이퍼 파라미터가 된다. - 중심 단어와 주변 단어가 임베딩 파라미터를 따로 가진다.
2. Item2Vec
(1) 개요
- Item2Vec
- Word2Vec의 SGNS에서 영감을 받은 모델, 자연어 처리의 word가 아니라 추천 시스템에서 사용할 item을 embedding
- 유저가 소비한 아이템 리스트 -> 문장 / 리스트의 각각의 아이템 -> 단어로 데이터를 바꿔서 사용
- 유저를 식별하지 않고 개별 유저가 소비한 아이템만을 학습 데이터로 사용
(2) 학습 과정
-
학습 데이터 생성 : 유저 혹은 세션별로 소비한 아이템의 집합과 그 집합의 아이템 (집합의 아이템끼리는 서로 유사하다고 가정)
- 기존의 Skip-Gram과 달리 공간적인 정보를 무시하고 가능한 모든 집합에 대한 positive sample 생성
- 어떻게 문장(아이템 리스트)과 단어(아이템)을 구성하는지가 각각의 서비스에서 추천의 품질을 좌우하게 됨
3. Approximate Nearest Neighbor (ANN)
-
Nearest Neightbor (NN) : 주어진 vector space에서 원하는 query vector와 가장 유사한 vector를 찾는 알고리즘
-
추천 모델 서빙 -> Nearest Neighbor Search : 주어진 query vector의 가장 인접한 이웃을 찾아주는 것
-
ANNOY (ANN의 라이브러리) : 주어진 벡터들을 여러 개의 부분집합으로 나누고 트리 형태로 구성해서 효율적인 탐색을 함
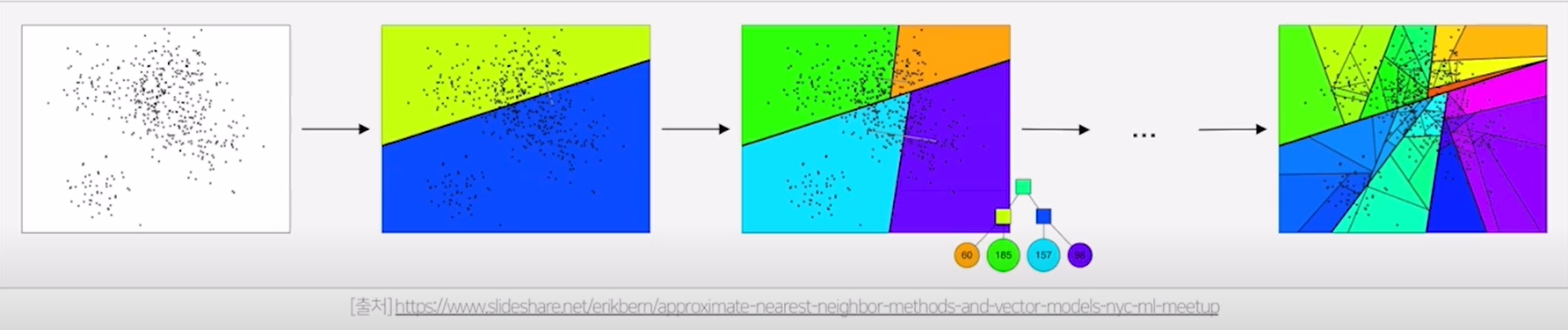
- 탐색 과정
-
임의의 두 벡터를 선택하여 그 사이의 hyperplane으로 공간을 나눠 부분집합을 만든다.
-
부분집합에 있는 벡터의 개수를 노드로 해서 binary tree를 생성한다.
-
부분집합의 점이 K개를 초과한다면 해당 집합에서 또 공간을 나누고 트리를 생성한다.
- 문제점과 해결 방안
가장 근접한 벡터가 다른 노드에 있을시 그 벡터가 후보 집합에 포함되지 않는다.
-> 가까운 다른 노드를 탐색하거나 binary tree를 여러개 생성하여 병렬탐색하여 해결
