seaborn 정리
seaborn
matplotlib을 쉽게 사용하기 위한 고수준(high-level) 라이브러리
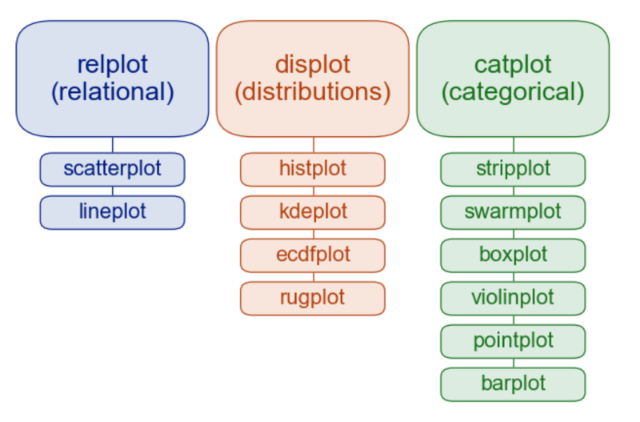
📍 그래프 종류
Relational plots: 두 가지 변수(x, y)의 관계를 나타내기 위한 그래프
-->scatterplot,lineplot,replotDistribution plots: 변수 하나(x or y) 혹은 변수 두개 (x,y)의 값 분포를 나타내기 위한 그래프
-->displot,hisplot,kdeplot,ecdfplot,rugplot,distplotCategorical plots: 범주형 변수 (ex. Male/Female, Yes/No)와 연속형 변수(숫자) 간의 관계를 나타내기 위한 그래프
-->boxplot,barplot,countplot,catplot,stripplot,swarmplot,violinplot,boxenplot,pointtplotRegression plots: 회귀(regression) 분석 결과를 relational p lots과 함께 나타내주는 그래프
-->lmplot,regplot,residplotMatrix plots: 연속형 변수(숫자) 간의 관계 비율을 2차원 메트릭스로 만들고 그 비율에 따라 색을 입혀서 시각화
-->heatmap,clustermapMulti-plot grids: 여러 그래프를 함께 그려 한눈에 비교하기 위한 그래프
-->FacetGrid,pairplot,PairGrid,jointplot,JointGrid
기본
-
사용방법
1. 데이터프레임(pandas 구조)를 삽입해서 그 데이터의 열이름을 x 축, y 축으로 입력하는 방법
sns.scatterplot(x = 'sugarpercent', y = 'winpercent', data = candy_data)
2. 데이터프레임의 열에 바로 접근해서 x 축, y 축으로 입력하는 방법
sns.scatterplot(x = candy_data['sugarpercent'], y = candy_data['winpercent']) -
hue에 범주형 데이터(yes or no)를 입력해 서로 다른 색으로 표시
📘 Relational plots
관계형 그래프
scatterplot
세 가지 파라미터 꼭 필요함(x축 데이터 컬럼명, y축 데이터 컬럼명, 데이터 셋)
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time")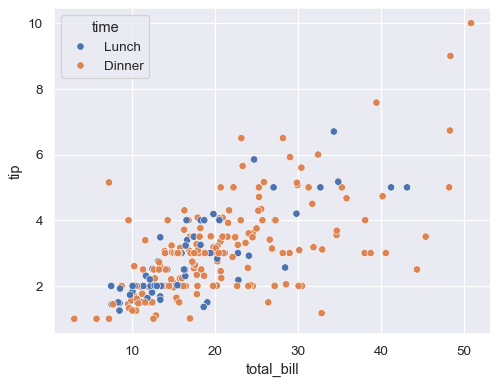
hue: 마커 색으로 범주형 데이터 구분, ex. sns.scatterplot(x='total_bill', y='tip', data=tips, hue='time')style: 마커 모양으로 범주형 데이터 구분
lineplot
may_flights = flights.query("month == 'May'")
sns.lineplot(data=may_flights, x="year", y="passengers")
- 연속적 데이터
- 짙은 선: 추정 회귀선(estimated regression line), 옅은 영역: 신뢰구간(confidence interval)
hue,style,markers=True
📘 Distribution plots
histplot
히스토그램 - 데이터의 빈도
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)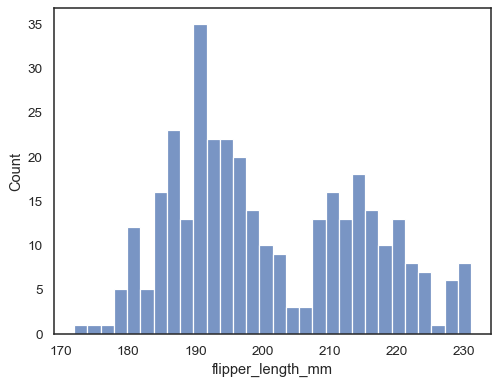
multiple=stackkde=True
kdeplot
sns.kdeplot(data=tips, x="total_bill", hue="time")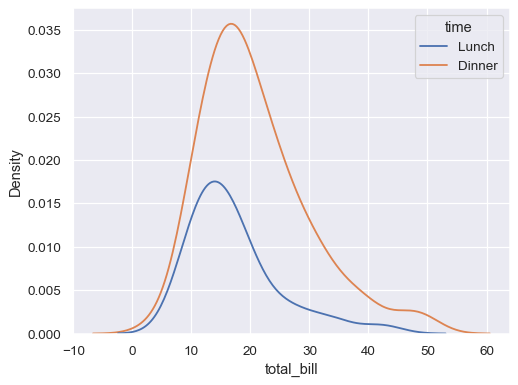
- 밀도 추정(kernal density estimation) 그래프
- histplot: count(절대량), kdeplot: 비율(상대량)
hue,style
displot
- histplot, kdeplot, ecdfplot 모두 그릴 수 있음(default: hist)
kind=: hist, kde, ecdfrow,col: subplot 여러 개 함께 나타낼 수 있음
📘 Categorical plots
barplot
flights_wide = flights.pivot(index="year", columns="month", values="passengers")
sns.barplot(flights_wide)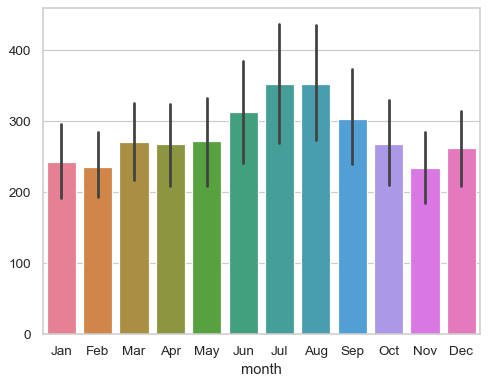
- 이변량(bivariate) 분석을 위한 plot
- x축: 범주형 변수, y축: 연속형 변수
- x, y축 데이터 바꿔서 수평막대그래프 표현가능
- 오차 막대
countplot
sns.countplot(titanic, x="class", hue="survived")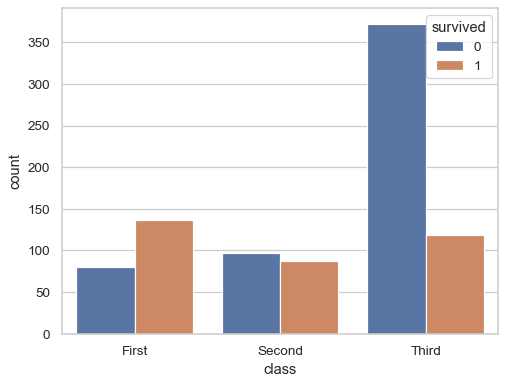
- 동일한 데이터의 개수 count
- hist: 연속형 데이터, countplot: 범주형 데이터
- x, y축 데이터 바꿔서 수평막대그래프 표현가능
boxplot
sns.boxplot(data=titanic, x="class", y="age", hue="alive")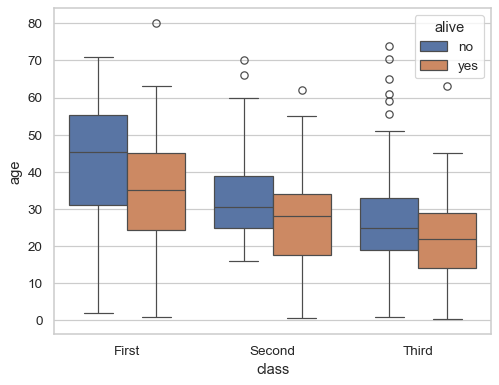
- 변수 1개(x or y축)일 때는 연속형 변수 입력 (범주형 변수는 에러)
- 변수 2개(x and y축)일 때는 연속형 변수와 범주형 변수를 입력
- 데이터 통계치(최대, 최소, 평균, 1사분위수, 3사분위수)를 한번에 표시
- 특정 데이터의 전체적인 분포를 확인하기 좋은 그래프
- outliar 발견하기 좋음
violinplot
sns.violinplot(data=df, x="class", y="age", hue="alive")
- boxplot과 변수 입력 규칙 동일
- 데이터 분포 한 눈에 파악
stripplot
sns.stripplot(data=tips, x="total_bill", y="day", hue="day", legend=False)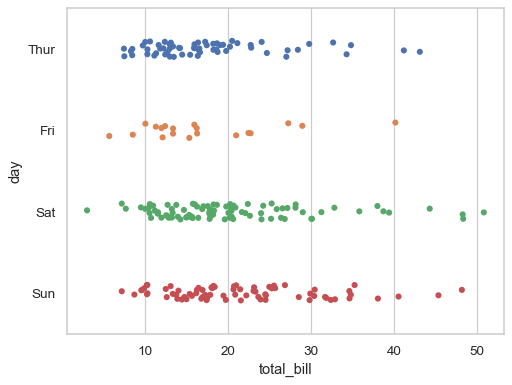
- 연속형 변수와 범주형 변수의 관계를 나타내는 scatterplot(scatterplot은 연속형과 연속형 사이의 관계 나타냄)
swarmplot
sns.swarmplot(data=tips, x="total_bill", y="day", hue="day", legend=False)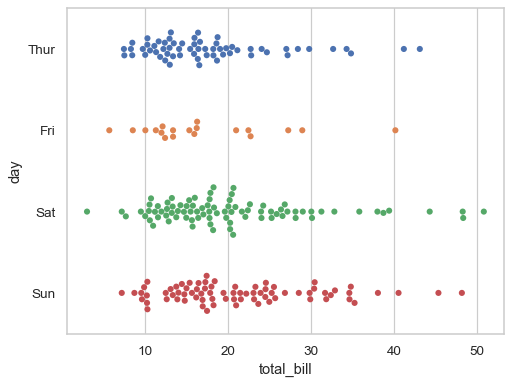
- stripplot과 흡사, 분포 정도 함께 표현
- violinplot과 함께 쓰기도 함
catplot
- 모든 categorical plot 그릴 수 있음
kind: strip(default), swarm, box, violin, boxen, point, bar, countrow,col
📘 Regression plots
regplot
- scatterplot + lineplot
- scatterplot의 경향성을 예측하는 쪽으로 lineplot 그려짐
lmplot
sns.lmplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species")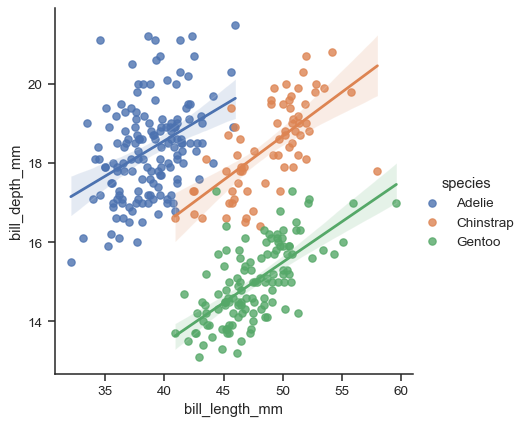
- regplot 상위호환
hue,row,col
📘 Matrix plots
heatmap
sns.heatmap(glue, annot=True)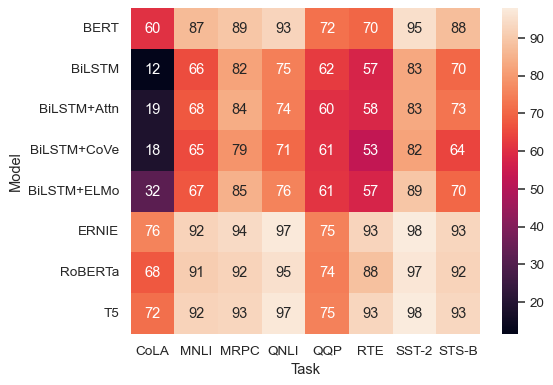
annot=True: 값을 칸 안에 표시해줌
Multi-plot grids
FacetGrid
pairplot
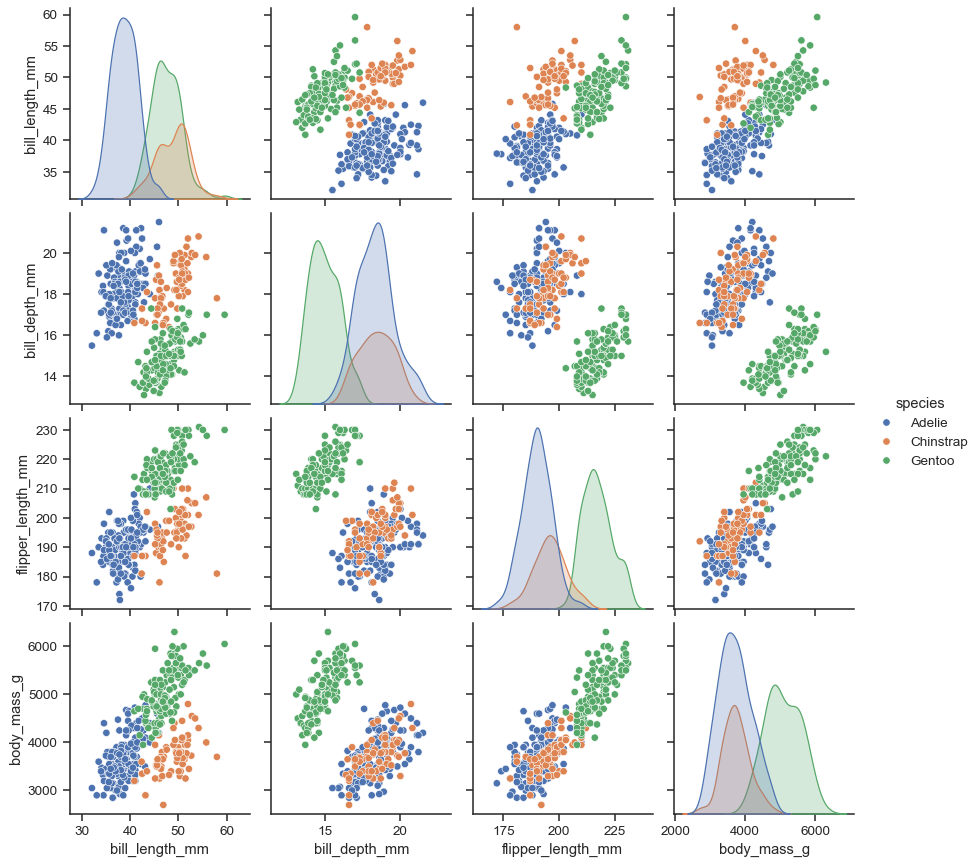
seaborn 공식문서
seaborn color palette
seaborn color palette 공식문서
plotly
import plotly.express as px
- px.histogram
import plotly.graph_object as go
- go.Histogram
- go.Box()
pandas
crosstab
df.hist(bins=n, figsize=())
