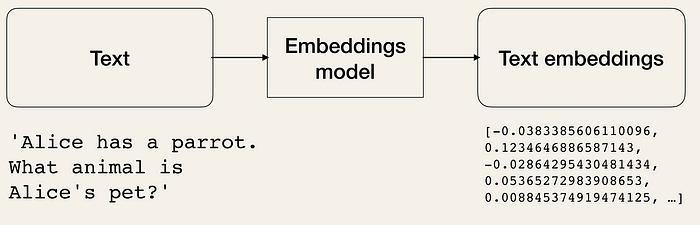
Text Embedding이란?
Text Embedding은 단어, 문장 또는 문서와 같은 텍스트 데이터를 실수 벡터로 표현하는 기술이다. 이 과정을 통해 텍스트의 의미적, 문맥적 정보를 기하학적 공간에 매핑하여 컴퓨터가 이해하고 처리할 수 있게 된다. 이러한 실수 벡터는 단어의 유사성을 반영하기 때문에 유사한 단어끼리 비슷한 형태를 가지게 된다.
챗봇, 기계 번역, 추천 시스템, 문서 요약 등 셀 수 없이 많은 분야에 응용이 가능하지만, 이번 포스트에서는 간단한 예제로 단순히 벡터를 비교하여 입력한 키워드와 유사한 검색 결과가 나오는 것까지만 다룰 것이다.
개발 환경
- Front-end : Front-end는
Vue와Vuetify,Typescript를 사용하여 구현했다. Front-end 쪽은 다른 프레임워크를 사용해도 무방하다. - Back-end : Back-end는 AI 관련 라이브러리가 풍부하고 문법이 쉬운
Python을 택했다. 또한,AWS Lambda+AWS API Gateway로 severless 환경을 구축했다. - Database : Database의 경우에는
MongoDB Atlas를 사용했다. 무료로 사용 가능하고, 서울에도 있는 데이터센터에 의해 접근 속도가 빠르며, 무엇보다 벡터 연산을 지원하기 때문이다. - Model : AI 모델은 serverless 환경을 고려하여 별도의 설치가 필요 없고 가격도 저렴한
openAI의 API를 사용했다.
구현 방법
AI Text Embedding을 활용한 검색 기능의 플로우차트는 대략 다음과 같다.
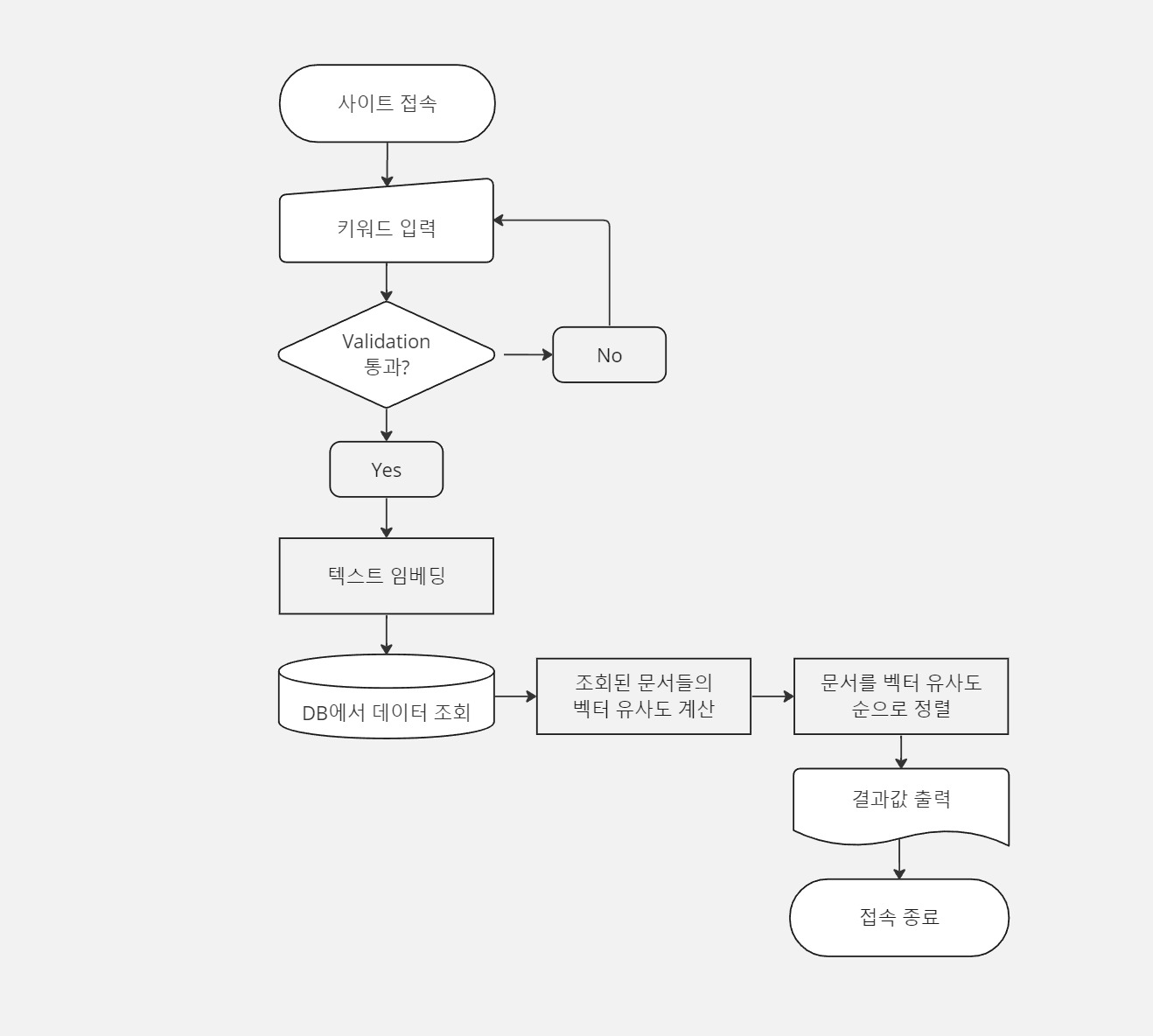
- 사용자 쿼리 입력: 사용자가 검색어를 입력한다.
- 텍스트 임베딩: 입력된 검색어를 AI Text Embedding 모델을 사용하여 벡터로 변환한다.
- 데이터베이스 조회: 저장된 문서들의 임베딩 벡터를 데이터베이스에서 조회한다.
- 유사도 계산: 벡터 연산을 통하여 검색어의 벡터와 문서 벡터들 간의 유사도를 계산한다.
- 순서 정렬: 계산된 유사도에 따라 문서들을 정렬하여 가장 관련성 높은 문서들을 사용자에게 반환한다.
1. 사용자 쿼리 입력
// vue.js
<v-form @submit.prevent="searchFruit">
<v-text-field
class="mt-4"
v-model="keyword"
label="검색할 과일을 입력해주세요."
/>
<v-btn class="mt-2" type="submit" block>Submit</v-btn>
</v-form>
const keyword = ref<string>("");
async function searchFruit(){
const response = await fetch(`${apiGatewayUrl}?s=${keyword.value}`);
const result = await response.json();
fruitList.value = result.data;
console.log("fruit List", result);
}client-side에서 사용자가 입력한 키워드는 searchFruit() 내부에 있는 fetch 함수를 통해, 미리 지정된 API Gateway URL로 전달이 된다. 해당 URL이 호출되면 AWS Lambda에서 entry point로 지정한 lambda_handler 함수가 실행이 된다. 아래의 코드는 파이썬으로 작성한 백엔드 함수 코드이다.
# in AWS Lambda
import json
import requests
from pymongo import MongoClient
mongo_uri = "<MONGO_URI>"
open_api_key = "<OPEN_API_KEY>"
client = MongoClient(mongo_uri)
def lambda_handler(event, context): # 특정 API GateWay URL이 호출되면 실행
db = client['shop']
collection = db['product_items']
keyword = event['search-text']
embedding = searchKeyword(keyword) # 키워드를 openAI의 API를 통해 벡터로 변환
result = list(searchOneData(embedding, collection)) # DB에서 벡터와 유사도가 높은 결과값을 출력
return {
"statusCode": 200,
"keyword": keyword,
"data": result
}lambda_handler 함수가 실행되면서 mongoDB와의 연동을 준비하고, 성공적으로 연동이 되면 searchKeyword() 함수를 호출한다. 이 때, event 객체 안에 있던 검색어 또한 같이 전달한다.
2. 텍스트 임베딩
def searchKeyword(keyword):
response = requests.post("https://api.openai.com/v1/embeddings", headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {open_api_key}",
},
json={
"input": keyword,
"model": "text-embedding-3-large",
"encoding_format": "float"
})
embedding = json.loads(response.text)['data'][0]['embedding']
return embeddingkeyword를 openAI embedding API의 body에 넣어 호출하면 벡터로 변환된 값을 반환한다. 키워드로부터 변환된 벡터는 부동소수점 배열 형태를 띈다.
3. 데이터베이스 조회 및 결과 반환
남은 단계에서는 데이터베이스를 조회하고, 각각의 아이템과 입력한 벡터의 유사도를 비교하고, 유사도가 높은 순서대로 반환하는 과정이 필요하다. 다행히도 MongoDB는 벡터 연산을 지원하기 때문에 앞서 말한 과정들을 한번에 처리할 수 있다.
def searchOneData(embedding, collection):
return collection.aggregate([ # 여러 문서를 처리하고 계산된 결과를 반환하는 함수
{
"$vectorSearch": {
"index": "embedding",
"path": "embedding",
"queryVector": embedding,
"numCandidates": 100, # 후보 문서의 수
"limit": 5 # 최대 5개
}
},
{
"$project": {
"_id": 0, # 테이블에서 name, seq, score만 가져와서 문서를 반환함
"name": 1,
"seq": 1,
"score": {
"$meta": "vectorSearchScore" # 이전 단계에서 계산된 벡터 검색 점수를 현재 문서의 score 필드로 반환
}
}
},
{
"$match": {
"score": { "$gte": 0.5 } # 유사도 점수 0.5 이상인 문서 필터링
}
}
])aggregate() 함수는 여러 문서를 한번에 처리하고 계산된 결과를 반환하는 함수이다. 해당 함수는 파이프라인을 통해 결과값을 계산하고 걸러내는데 각각의 단계는 다음과 같다.
1. $vectorSearch 단계
벡터 연산이 이루어지는 단계이다.
- index: 사용할 벡터 인덱스의 이름을 지정한다. 여기서는 "embedding"이라는 이름의 인덱스를 사용했다.
- path: 문서 내에서 벡터 데이터가 위치하는 필드의 경로. 여기서도 "embedding" 필드를 사용한다.
- queryVector: 검색할 벡터. embedding 변수에 저장된 벡터 값을 사용하여 쿼리를 진행한다.
- numCandidates: 검색 과정에서 고려할 최대 후보 문서의 수를 말한다. 여기서는 100개의 문서를 후보로 설정했다.
- limit: 최종 결과로 반환할 문서의 수를 제한한다. 여기서는 상위 5개 문서만 반환한다.
2. $project 단계
각 문서의 특정 필드만 선택하여 반환하는 단계이다.
- _id: 문서의 ID 필드를 제외하고, name 및 seq 필드를 포함시킨다.(1은 포함을 의미하고 0은 제외를 의미함).
- score: 검색 결과의 점수를 포함한다. "$meta": "vectorSearchScore"를 사용하면, 이전 단계에서 계산된 벡터 검색 점수를 현재 문서의 score 필드로 포함시켜 반환하도록 설정할 수 있다.
3. $match 단계
특정 조건을 만족하는 문서만 필터링하는 단계이다. 여기서는 문서의 유사도 점수가 0.5 이상인 것만 포함시키게끔 필터링 조건을 걸었다.
따라서 위의 코드는 "embedding" 벡터 인덱스를 사용하여 주어진 벡터와 유사한 문서를 검색하고, 그 중 점수가 0.5 이상인 상위 5개 문서의 이름, 순서, 점수만을 반환한다는 뜻이다.
실행 결과
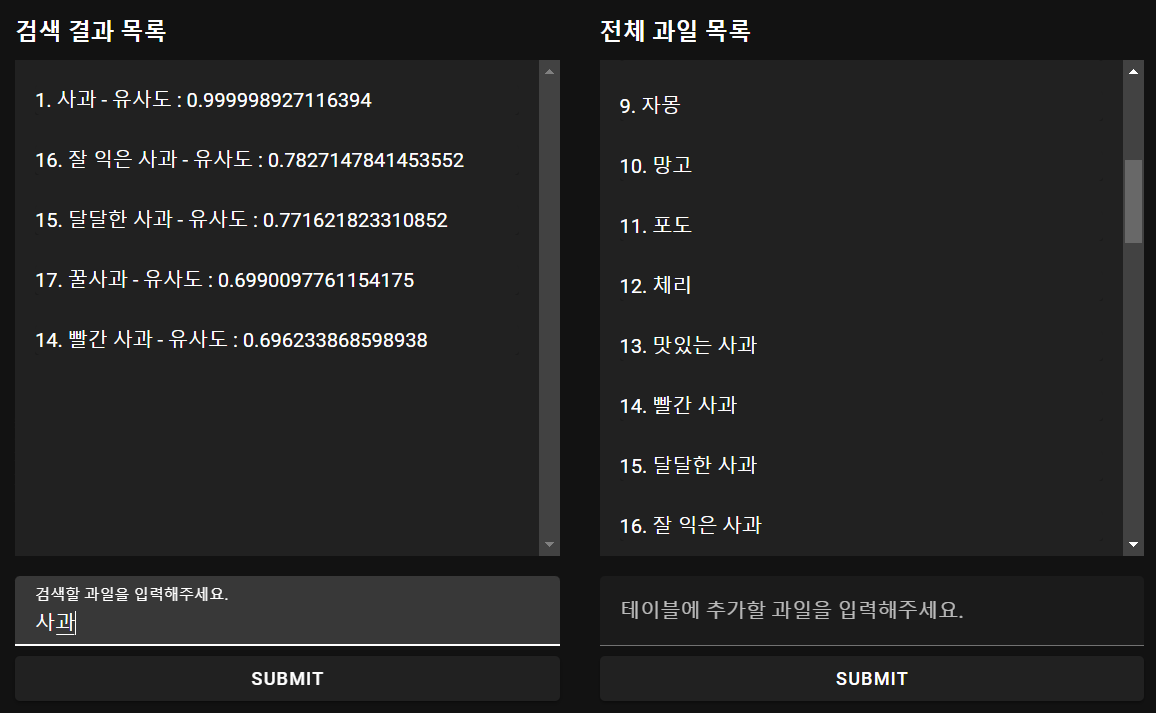
사진처럼 "사과"로 검색했을 때 유사도가 높은 순으로 검색되는 것을 확인할 수 있다. 아래의 gitHub page에서 직접 테스트 해볼 수 있다.
샘플 코드
참고 자료
Open AI - API Reference
MongoDB - Aggregation Pipeline
Using OpenAI Latest Embeddings in a RAG System With MongoDB
AWS Lambda + API Gateway로 Serverless API 환경 구성하기
AWS Lambda 기초 개념 및 간단 사용
