🧷 서울시 범죄 분석
import numpy as np
import pandas as pdcrime_raw_data = pd.read_csv('../data/02.crime_in_Seoul.csv' ,encoding='utf-8')
crime_raw_data.head(5)⇊
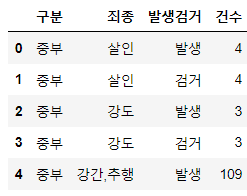
-
데이터 안의 숫자값들중 콤마가 들어가있으면 문자로 인식
-
천단위 구분(thousands=',')이라고 알려주면 콤마를 제거하고 숫자형으로 읽음
-
.notnull()
NaN 값이 아닌 데이터들만 보여줌 -
.isnull()
NaN 값인 데이터들만 보여줌
🖇️ Pandas pivot table
df = pd.read_excel('../data/02. sales-funnel.xlsx')
df.head()pd.pivot_table(df, index=['Name'])⇊
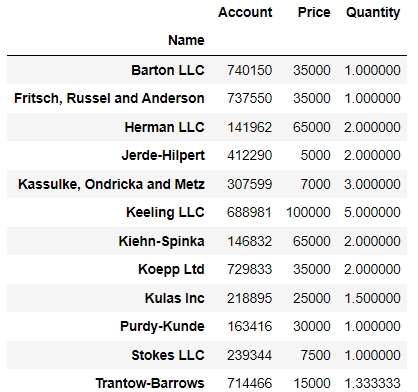
- 간단한 판매 현황표를 Name을 인덱스로 두고 재정렬
pd.pivot_table(df, index=['Name', 'Rep', 'Manager'])⇊
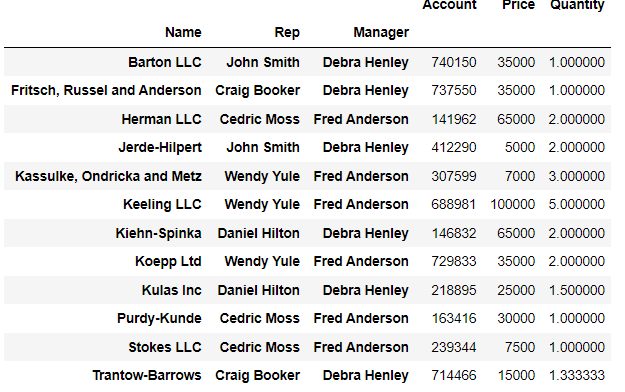
-index 여러개 지정 가능
pd.pivot_table(df, index=['Manager', 'Rep'], values=['Price'])⇊
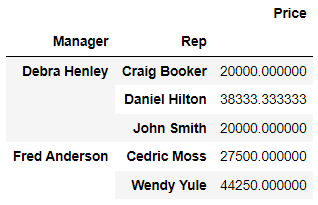
- values 지정 가능
pd.pivot_table(df, index=['Manager', 'Rep'], values=['Price'], aggfunc=np.sum)⇊
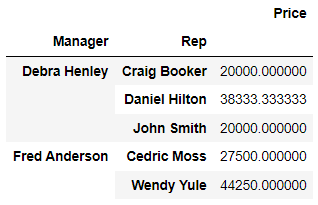
- values에 함수 적용 가능. 디폴트는 평균(mean).
- 합산 등 다른 함수를 적용할 때는 aggfunc 옵션 지정
pd.pivot_table( df, index=['Manager', 'Rep'], values=['Price'], columns=['Product'], aggfunc=[np.sum])⇊
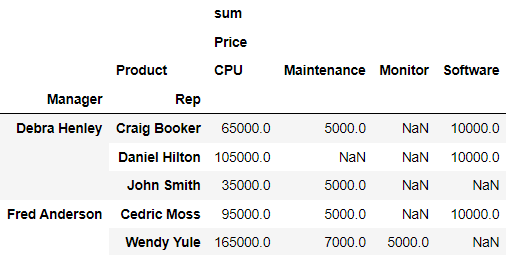
- 분류 지정(columns)
pd.pivot_table(
df,
index=['Manager', 'Rep'],
values=['Price'],
columns=['Product'],
aggfunc=[np.sum],
fill_value=0)⇊
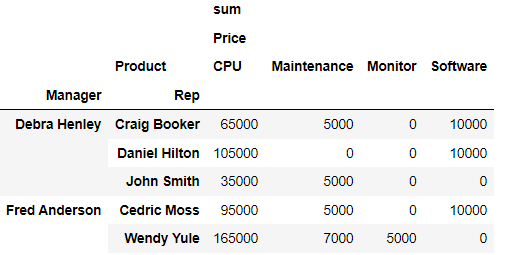
- fill_value로 NaN에 대한 처리 지정
pd.pivot_table(
df,
index=['Manager', 'Rep', 'Product'],
values=['Price', "Quantity"],
aggfunc=[np.sum],
fill_value=0)⇊
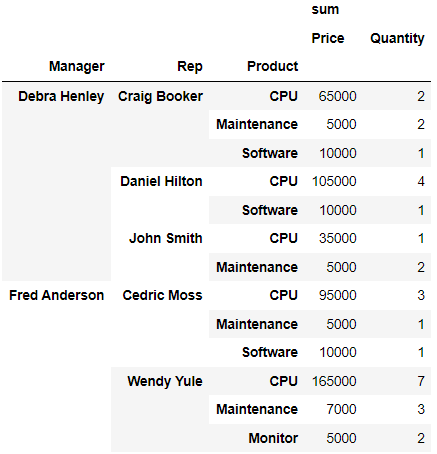
pd.pivot_table(
df,
index=['Manager', 'Rep', 'Product'],
values=['Price', 'Quantity'],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True)⇊
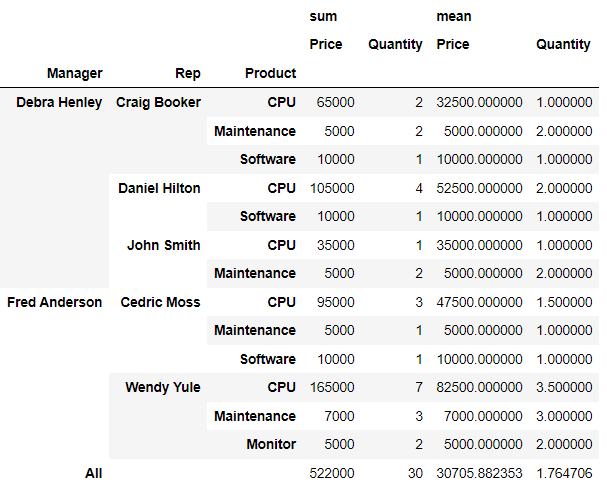
- sum(합계)에 대한것은 Price로 Mean(평균)에 대한것은 Quantity로
- margins : 총계(All) 추가
🖇️ 범죄 현황 데이터에 Pandas pivot table 적용
crime_station = crime_raw_data.pivot_table(
crime_raw_data, index=['구분'], columns=['죄종','발생검거'], aggfunc=[np.sum])
crime_station.head()⇊
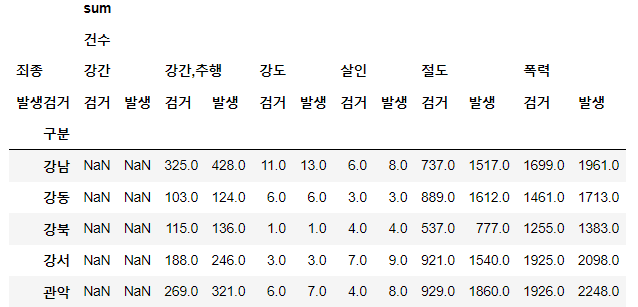
- 이렇게 정리된 데이터의 경우 column이 multi로 잡힘
crime_station.columns⇊
MultiIndex([('sum', '건수', '강간', '검거'),
('sum', '건수', '강간', '발생'),
('sum', '건수', '강간,추행', '검거'),
('sum', '건수', '강간,추행', '발생'),
('sum', '건수', '강도', '검거'),
('sum', '건수', '강도', '발생'),
('sum', '건수', '살인', '검거'),
('sum', '건수', '살인', '발생'),
('sum', '건수', '절도', '검거'),
('sum', '건수', '절도', '발생'),
('sum', '건수', '폭력', '검거'),
('sum', '건수', '폭력', '발생')],
names=[None, None, '죄종', '발생검거'])- Multi Columns Index
- pivot_table을 적용하면 column이나 index가 다중으로 잡힘
crime_station['sum', '건수', '강도', '검거']⇊
구분
강남 11.0
강동 6.0
강북 1.0
강서 3.0
관악 6.0
광진 4.0
구로 1.0
금천 4.0
남대문 3.0
노원 3.0
도봉 1.0
동대문 8.0
동작 1.0
마포 4.0
방배 0.0
서대문 2.0
서부 1.0
서초 5.0
성동 1.0
성북 0.0
송파 6.0
수서 12.0
양천 3.0
영등포 11.0
용산 1.0
은평 2.0
종로 2.0
종암 2.0
중랑 7.0
중부 3.0
혜화 2.0
Name: (sum, 건수, 강도, 검거), dtype: float64- Multi index에 대한 접근
crime_station.columns = crime_station.columns.droplevel([0, 1])
crime_station.columns⇊
MultiIndex([( '강간', '검거'),
( '강간', '발생'),
('강간,추행', '검거'),
('강간,추행', '발생'),
( '강도', '검거'),
( '강도', '발생'),
( '살인', '검거'),
( '살인', '발생'),
( '절도', '검거'),
( '절도', '발생'),
( '폭력', '검거'),
( '폭력', '발생')],
names=['죄종', '발생검거'])- droplevel() : 다중 컬럼에서 특정 컬럼 제거
🖇️ Pip명령과 conda명령
─ pip 명령
- Python의 공식 모듈 관리자
- pip list: 현재 설치된 모듈 리스트 반환
- pip install module_name: 모듈설치
- pip uninstall module_name: 설치된 모듈 제거
─ conda 명령
pip를 사용하면 conda 환경에서 dependency 관리가 정확하지 않을 수 있음.
아나콘다에서는 가급적 conda 명령으로 모듈을 관리하는 것이 좋음
- conda list: 설치된 모듈 list
- conda install module_name: 모듈 설치
- conda uninstall module_name: 모듈 제거
- conda install -c channel_name module_name: 지정된 배포 채널에서 모듈 설치
🖇️ Pandas 반복문 명령- iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들떄 iterrows()라는 옵션을 사용하면 편함
- 받을때, 인덱스와 내용으로 나누어 받는것에 주의
🖇️ Google Maps를 이용하여 데이터 정리
import googlemapsgmaps_key = 'AI....'
gmaps = googlemaps.Client(key=gmaps_key)gmaps.geocode('서울영등포경찰서', language='ko')⇊
[{'address_components': [{'long_name': '608',
'short_name': '608',
'types': ['premise']},
{'long_name': '국회대로',
'short_name': '국회대로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '영등포구',
'short_name': '영등포구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '150-043',
'short_name': '150-043',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 영등포구 국회대로 608',
'geometry': {'location': {'lat': 37.5260441, 'lng': 126.9008091},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5273930802915,
'lng': 126.9021580802915},
'southwest': {'lat': 37.5246951197085, 'lng': 126.8994601197085}}},
'partial_match': True,
'place_id': 'ChIJ1TimJLaffDURptXOs0Tj6sY',
'plus_code': {'compound_code': 'GWG2+C8 대한민국 서울특별시',
'global_code': '8Q98GWG2+C8'},
'types': ['establishment', 'point_of_interest', 'police']}]tmp = gmaps.geocode('서울영등포경찰서', language='ko')
print(tmp[0].get('geometry')['location']['lat'])
print(tmp[0].get('geometry')['location']['lng'])
print(tmp[0].get('formatted_address'))⇊
37.5260441
126.9008091
대한민국 서울특별시 영등포구 국회대로 608- 전체 결과 크기가 1인 list형이라서 tmp[0]로 접근
- 큰 list안의 dict형
- dict형에서 데이터를 얻는 get() 명령 사용
tmp = tmp[0].get('formatted_address')
tmp.split()⇊
['대한민국', '서울특별시', '영등포구', '국회대로', '608']tmp.split()[2]⇊
'영등포구'- 전체 주소에서 필요한 구이름만 가져오기
crime_station['구별'] = np.nan
crime_station['lat'] = np.nan
crime_station['lng'] = np.nan
crime_station.head()⇊
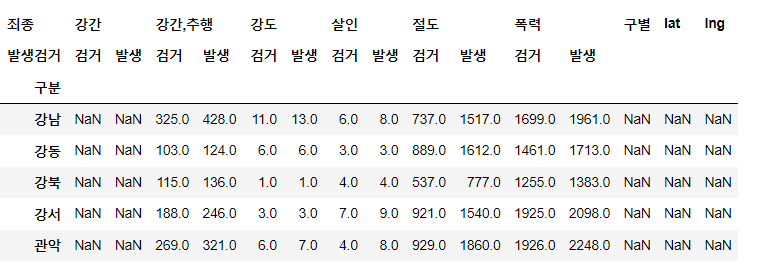
- 경찰서 이름에서 소속된 구이름 얻기
- 구이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용하여 NaN 채우기
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + '경찰서'
tmp = gmaps.geocode(station_name, language = 'ko')
tmp[0].get('formatted_address')
tmp_gu = tmp[0].get('formatted_address')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
crime_station.loc[idx, 'lat'] = lat
crime_station.loc[idx, 'lng'] = lng
crime_station.loc[idx, '구별'] = tmp_gu.split()[2]
print(count)
count = count + 1⇊
0
1
2
3
.
.
.
29
30crime_station.head()⇊
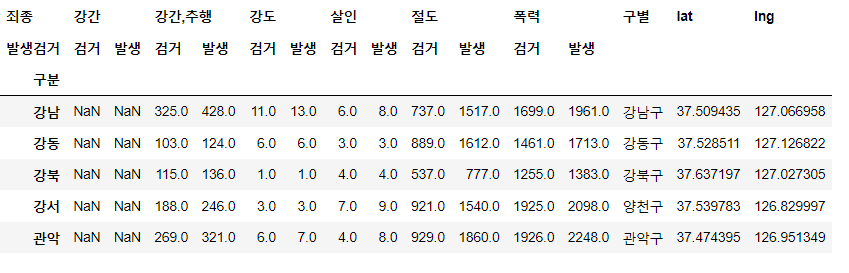
tmp = [
crime_station.columns.get_level_values(0)[n]
+ crime_station.columns.get_level_values(1)[n]
for n in range(0, len(crime_station.columns.get_level_values(0)))
]
crime_station.columns = tmp
crime_station.head()⇊
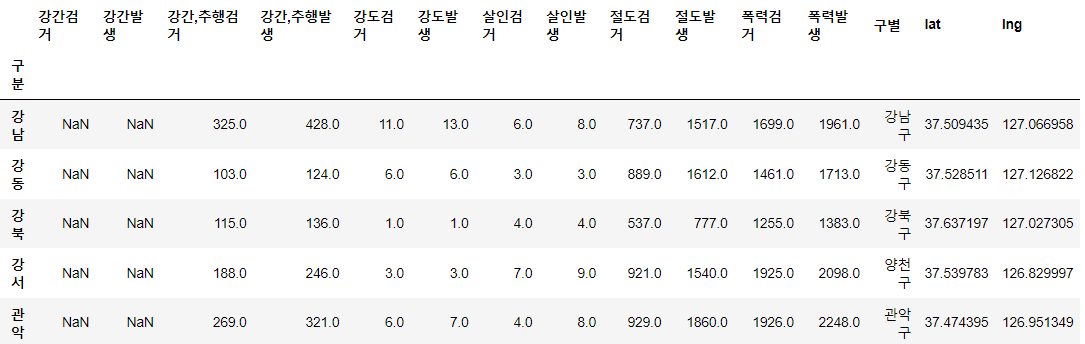
- 두개 컬럼 합치기
crime_station.to_csv('../data/02.crime_in_Seoul_raw.csv', sep=',', encoding='utf-8')- 저장
🖇️ 구별 데이터 생성
crime_anal_station = pd.read_csv(
'../data/02.crime_in_Seoul_raw.csv', index_col=0, encoding='utf-8'
)
crime_anal_station.head()⇊
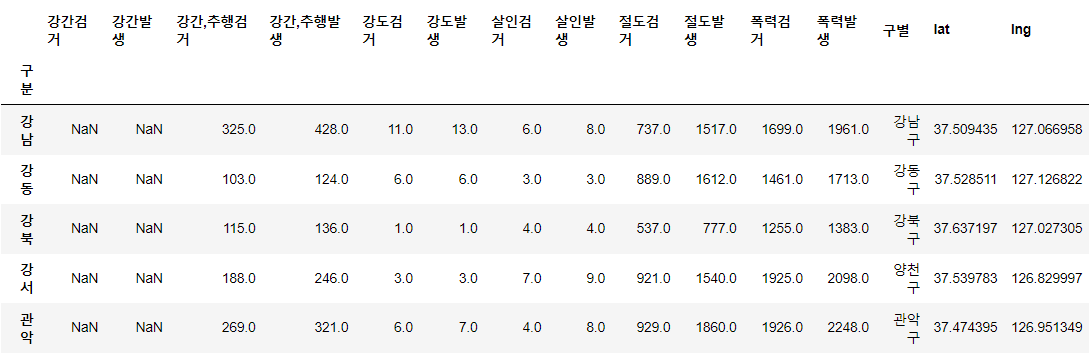
- 데이터 불러오기
- 테스트 코드가 긴 경우 중간부터 다시 작업 가능
crime_anal_gu = pd.pivot_table(crime_anal_station, index='구별', aggfunc=np.sum)
del crime_anal_gu['lat']
del crime_anal_gu['lng']
crime_anal_gu.head()⇊
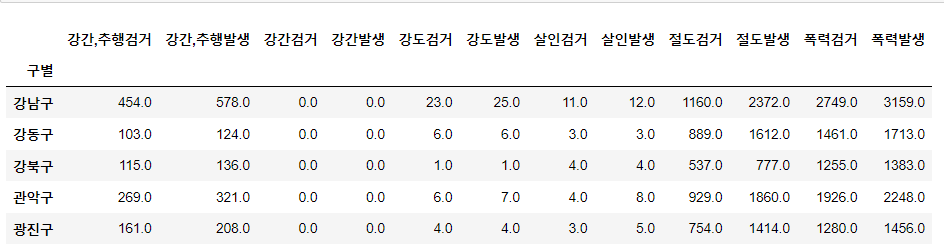
- pivot_table로 구별로 정리
- 필요없는 컬럼 제거
- pivot_table의 func은 sum으로
crime_anal_gu['강도검거'] / crime_anal_gu['강도발생']⇊
구별
강남구 0.920000
강동구 1.000000
강북구 1.000000
관악구 0.857143
광진구 1.000000
구로구 0.500000
금천구 1.333333
노원구 1.000000
도봉구 0.500000
동대문구 1.142857
동작구 1.000000
마포구 1.000000
서대문구 1.000000
서초구 1.000000
성동구 0.250000
성북구 1.000000
송파구 0.857143
양천구 1.000000
영등포구 1.000000
용산구 1.000000
은평구 1.000000
종로구 1.000000
중구 1.000000
중랑구 1.166667
dtype: float64- 검거율 계산
─ div()
crime_anal_gu[['강도검거', '살인검거']].div(crime_anal_gu['강도발생'], axis=0)⇊
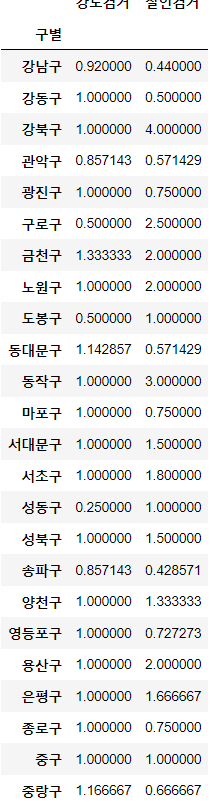
- 다수의 컬럼을 다른 컬럼으로 나누기
num = ['강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[num].div(crime_anal_gu[den].values)⇊
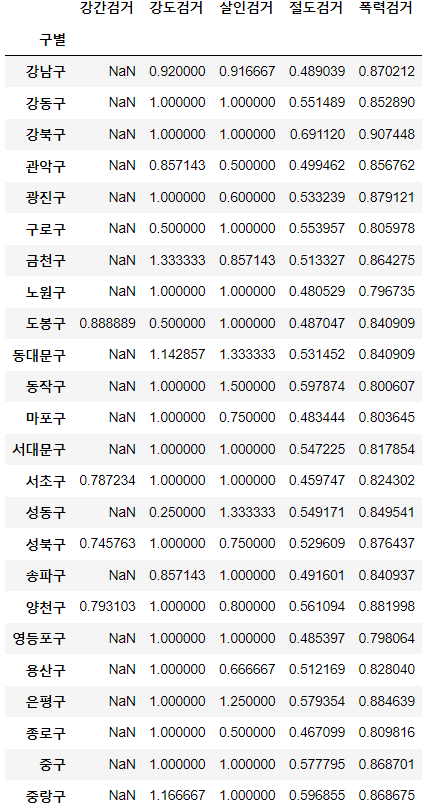
- 다수의 컬럼 / 다수의 컬럼
target = ['강간,추행검거율', '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
num = ['강간,추행검거', '강간검거', '강도검거', '살인검거', '절도검거', '폭력검거']
den = ['강간,추행발생', '강간발생', '강도발생', '살인발생', '절도발생', '폭력발생']
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) * 100crime_anal_gu.head()⇊
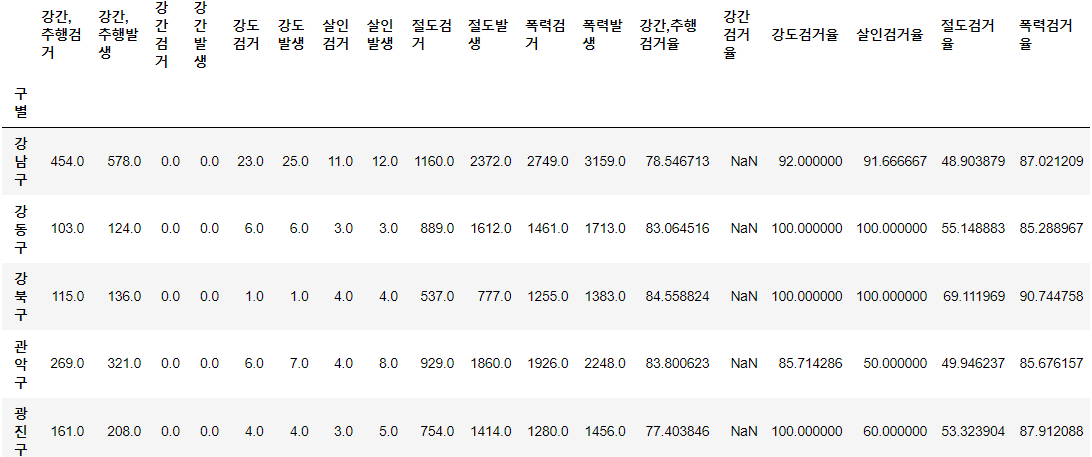
del crime_anal_gu['강간검거']
del crime_anal_gu['강간,추행검거']
del crime_anal_gu['강도검거']
del crime_anal_gu['살인검거']
del crime_anal_gu['절도검거']
del crime_anal_gu['폭력검거']
crime_anal_gu.head()⇊
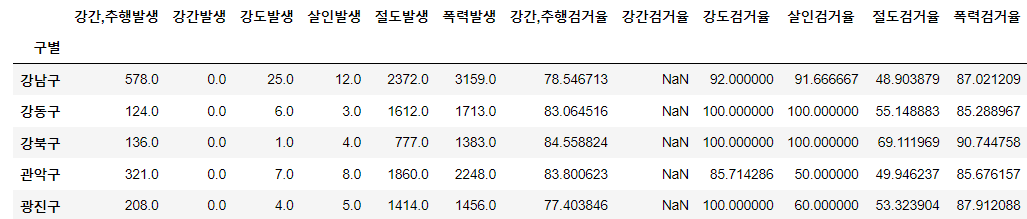
crime_anal_gu.rename(
columns={'강간,추행발생':'강간,추행', '강간발생':'강간', '강도발생':'강도', '살인발생':'살인', '절도발생':'절도', '폭력발생':'폭력'},
inplace=True
)
crime_anal_gu.head()⇊
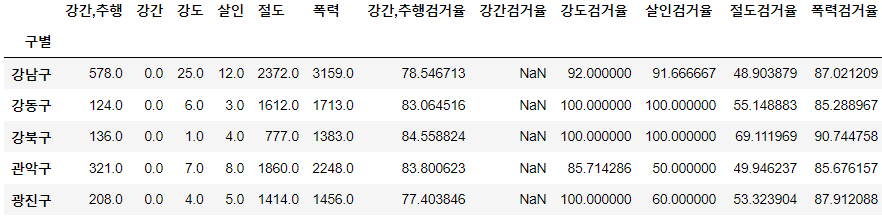
- 컬럼 이름 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100] = 100crime_anal_gu.head()⇊
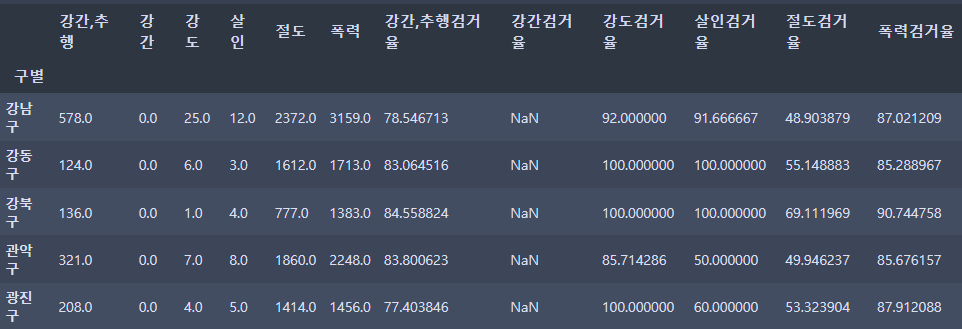
- 100보다 큰 숫자 찾아서 바꾸기
🖇️ 데이터 최종 정리
col = ['살인', '강도', '강간', '절도', '폭력', '강간,추행']
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
crime_anal_norm.head()⇊
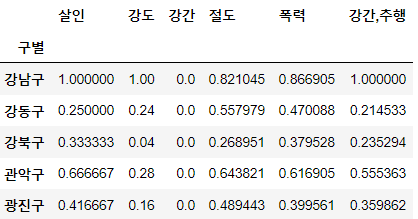
- 본래의 데이터 프레임은 두고, 정규화된 데이터 따로 생성
- 최고값=1, 최소값=0
col2 = ['강간,추행검거율', '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm[col2] = crime_anal_gu[col2]
crime_anal_norm.head()⇊
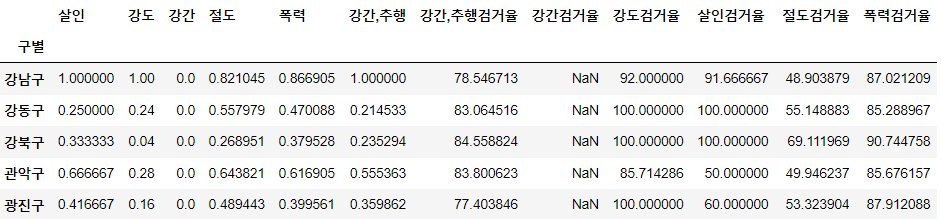
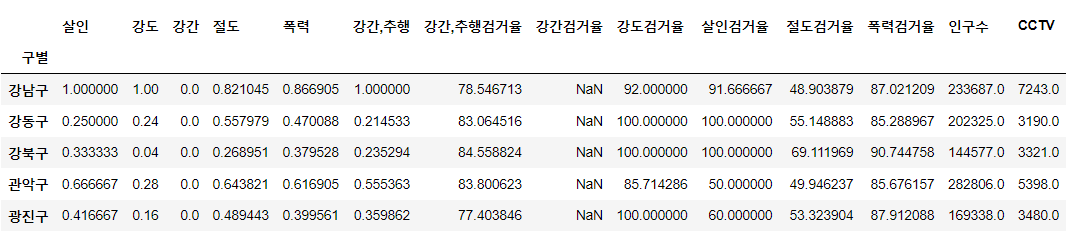
result_CCTV = pd.read_csv(
'..\\data\\01.CCTV_result.csv', encoding='utf-8', index_col='구별'
)
crime_anal_norm[['인구수', 'CCTV']] = result_CCTV[['인구수', '총계']]
crime_anal_norm.head()⇊
col = ['살인', '강도', '강간', '절도', '폭력', '강간,추행']
crime_anal_norm['범죄'] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()⇊
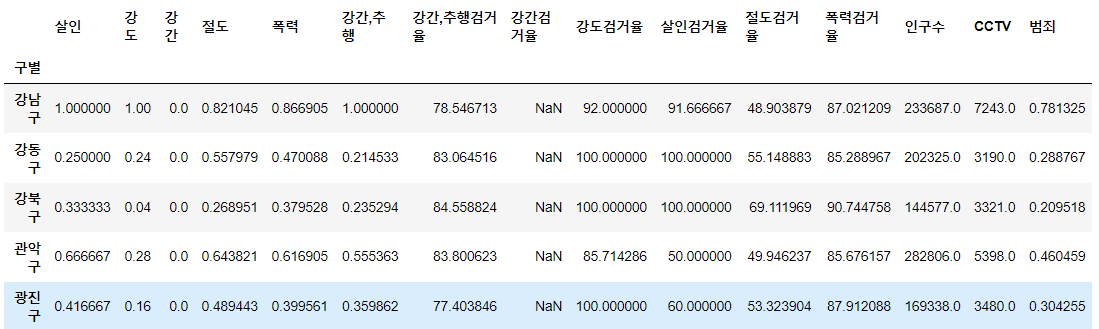
- 정규화된 범죄발생 건수의 전체 평균을 구해서 범죄의 대표값으로 사용
col = ['강간,추행검거율', '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
crime_anal_norm['검거'] = np.mean(crime_anal_norm[col], axis=1)
crime_anal_norm.head()⇊
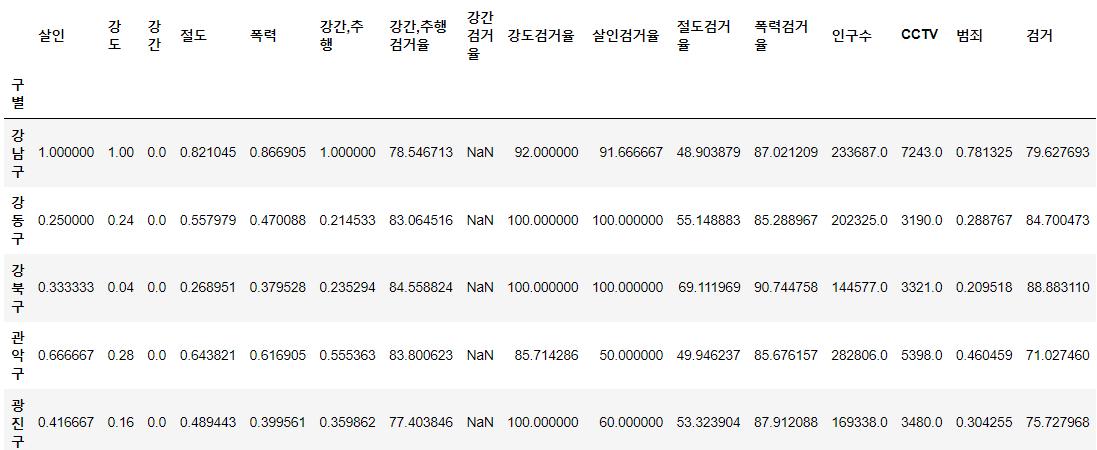
- 검거율 평균을 구해서 검거의 대표값으로 사용
🖇️ np.mean()
np.array([1.000000, 1.00, 0.000000, 0.821045, 0.866905, 1.000000])⇊
array([1. , 1. , 0. , 0.821045, 0.866905, 1. ])np.mean(np.array([1.000000, 1.00, 0.000000, 0.821045, 0.866905, 1.000000]))⇊
0.7813249999999999np.mean(np.array(
[[1.000000, 1.00, 0.000000, 0.821045, 0.866905, 1.000000],
[0.250000, 0.24, 0.000000, 0.557979, 0.470088, 0.214533]]
), axis=1)⇊
array([0.781325 , 0.28876667])np.mean(np.array(
[[1.000000, 1.00, 0.000000, 0.821045, 0.866905, 1.000000],
[0.250000, 0.24, 0.000000, 0.557979, 0.470088, 0.214533]]
), axis=0)⇊
array([0.625 , 0.62 , 0. , 0.689512 , 0.6684965, 0.6072665])- numpy에서 axis=1 :행 , axis=0: 열
