1. 단일값만 저장하는 변수
x <- 100
x
class(x) # 변수 타입
typeof(x) # 변수 타입
str(x) # 변수 타입, 값
mode(x) # 변수 타입2. vector(벡터)
- python 에서의 list 와 비슷하다.
- 같은 데이터 타입을 갖는 1차원 배열 구조이다.
- c() : combine value
- 벡터는 중첩할 수 없다.
- 데이터 변환 규칙(integer < double(numeric) < character)
x <- c(10,20,30,40,50)
x
class(x)
typeof(x)
str(x)
mode(x)
y <- c(10L, 20, '삼십')
class(y) # 벡터는 같은 데이터 타입을 갖기 때문에 힘이 가장 큰 character로 전부 변환된다.
typeof(y)
str(y)
mode(y)
z <- c(1,2,3,c(4,5))
z # 1 2 3 4 5 : 중첩이 불가능하기 때문에 벡터 안에 들어있는 벡터는 풀려서 나온다.c(컬럼=값, 컬럼=값)
x <- c("국어"=90,"산수"=80,"영어"=90)
x
names(x) # 컬럼 이름 확인y <- c("과목"=c(70,80,90))
y
names(y) <- c("국어","수학","영어") # 컬럼 이름 수정인덱싱
: R에서의 인덱싱은 0이 아닌 1부터 시작한다.
names(y)[1]
names(y)[2]
names(y)[3]
names(y)[3] <- "과학"
names(y)[3] <- NA
y
names(y)[3] <- NULL # 오류 발생
names(y) <- NA
y
names(y) <- NULL # 컬럼 이름 초기화, 컬럼 이름 삭제
y
벡터 길이
length(y)
NROW(y)
y[1]
y[2]
y[3]
y[length(y)] # 제일 끝에 있는 값
y[NROW(y)]
y[-1] # 1번 인덱스를 제외
y[-2] # 2번 인덱스를 제외
y[c(1,3)] # 1, 3번 인덱스
y[c(-1,-3)] # 1, 3번 인덱스만 제외
names(y) <- c("국어","수학","영어")
y['국어']
y[c('국어','영어')]
y[-'국어'] # 컬럼 이름을 이용해서 제외시키면 오류 발생
y[-c('국어','영어')] # 컬럼 이름을 이용해서 제외시키면 오류 발생슬라이싱
: R에서의 슬라이싱은 python과 달리 끝인덱스 그대로를 받는다. (시작인덱스:끝인덱스)
y[1:2]
y[1:3]
y[2:] # 오류 발생. 시작인덱스:끝인덱스를 꼭 지정해야 한다.연속되는 값을 표현하는 방법
x <- 1:100
x <- c(1:100000)
xoptions()
: 화면에 출력할 수 있는 수를 조절하는 방법
options(max.print=10000)
x
options(max.print=10000) # 기본값
xseq()
: 자동 일련번호를 생성하는 함수. (시작값,종료값,증가분)
seq(1,1000,1)
seq(1,1000,2)
seq(10,1,-1) # 역순도 가능
x <- c(2,4,6,8,10,12)
length(x)
NROW(x)
seq(1,length(x),1)
1:length(x)
1:NROW(x)
seq_along(x) # 벡터 변수 길이 만큼 시퀀스값을 생성rep()
: 반복되는 값을 생성하는 함수
rep(1:10,times=2) # times = n : 시작과 종료까지를 n번 반복
rep(1:10,each=2) # each = 2 : 각각의 숫자를 n번 반복
rep(1:10,times=2,each=2)
x <- 10:15
x[2] <- 16
x 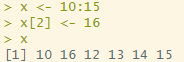
x[2] <- NA
x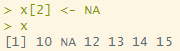
x <- NULL
x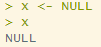
x <- 10:15
x[7] <- 16 # 벡터에 값을 추가
x[9] <- 17
x # 8번 인덱스는 결측값
벡터 변수 제일 뒤에 새로운 값을 추가
x[length(x)+1] <- 19
x 
length(x)
append(x,20,after=length(x)) # append(벡터변수, 새로운 값, after=인덱스번호)
# 미리보기. x라는 벡터 변수 제일 뒤에 20 이라는 값을 추가!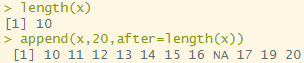
x <- append(x,20,after=length(x))
x
x <- append(x,21,after=1) # 1번 인덱스 뒤에 21 이라는 값을 추가!
x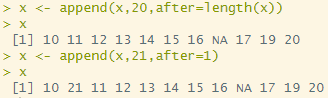
x 라는 변수 안에 모든 값들에 일괄적으로 연산 적용 가능
x <-10:15
x[1]+100
x+100
x-100
x*100
x/2
x%/%2
x%%2
x^2서로 다른 벡터 변수의 값을 비교
x <- c(1,2,3)
y <- c(1,2,3)
z <- c(1,2,4)
x == y # 벡터 변수 안에 있는 인덱스 끼리 값을 비교 / TRUE TRUE TRUE
x == z # 벡터 변수 안에 있는 인덱스 끼리 값을 비교 / TRUE TRUE FALSEidentical()
: 각 인덱스에 있는 값을 비교해서 전부 일치하면 TRUE, 아니면 FALSE 를 리턴하는 함수.
identical(x,y) # TRUE
identical(x,z) # FALSEx <- c(1,2,3,4,4)
y <- c(1,2,3,4)
x == y # 벡터 변수의 길이가 틀리면 경고 메시지가 발생
identical(x,y)setequal()
: 집합 개념으로 비교하는 함수(중복을 제거)
setequal(x,y)x <- c(1,2,3,4,4)
y <- c(4,2,3,1)
x == y
identical(x,y) # FALSE
setequal(x,y) # TRUE / 집합 개념이므로 순서가 다르거나 인덱스 갯수가 달라도 일치한다고 리턴집합함수
x <- c(1,2,3,4)
y <- c(1,4,6)
union(x,y)
: 합집합(중복 제거). 중복을 포함하는 union all을 하려면 z <- c(x,y)
intersect(x,y)
: 교집합
setdiff(x,y)
: 차집합. 반대는 setdiff(y,x)
%in%
: 주어진 값이 벡터 또는 리스트에 속하는지 여부를 확인할 때 사용하는 연산자.
x <- c('a','b',NA,'a','b','d',NA)
'a' %in% x # TRUE
x[x=='a'] # NA를 포함시켜서 찾는다 / "a" NA "a" NA
x[x%in%'a'] # NA를 제외시켜서 찾는다 / "a" "a"
x[x=='a' | x=='b'] # NA를 포함시켜서 찾는다 / "a" "b" NA "a" "b" NA
x[x%in%'a' | x%in%'b'] # NA를 제외시켜서 찾는다 / "a" "b" "a" "b"which
: 조건에 해당하는 인덱스를 찾는 함수
x <- c('a','b',NA,'a','b','d',NA)
which(x=='a')
x[which(x=='a')]
which(x %in% 'a')
x[which(x %in% 'a')]
is.na(x)
x[is.na(x)]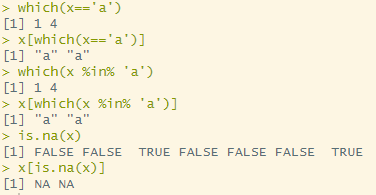
which(is.na(x)) # NA가 있는 인덱스를 찾는 방법
x[which(is.na(x))] <- 'c' # NA를 찾아서 동일한 값으로 수정
x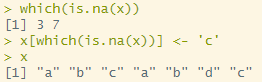
x 변수에 NA는 제외
x <- c('a','b',NA,'a','b','d',NA)
x[!is.na(x)] # !는 not 의미
x[which(is.na(x))] # x[c(3,7)]
x[-which(is.na(x))] # x[-c(3,7)]
정렬
x <- c(8,7,9,3,2,4,6,5,1)
sort(x)
sort(x,decreasing=FALSE) # 오름차순 정렬, 기본값, 미리보기
sort(x,decreasing=TRUE) # 내림차순 정렬연속된 숫자를 생성할 때에도 어떻게 만드냐에 따라 정수형인지, 실수형인지 달라진다.
x <- 1:5 # 정수
y <- c(1:5) # 정수
z <- c(1,2,3,4,5) # 실수
s1 <- seq(1,5) # 정수
s2 <- seq(1,5,1) # 실수
str(x)
str(y)
str(z)
str(s1)
str(s2)x == z # TRUE TRUE TRUE TRUE TRUE / 값으로만 비교했을 때는 동일한 것 같아 보이지만
setequal(x,z) # TRUE
identical(x,z) # FALSE / 벡터의 길이, 인덱스의 값, 데이터 타입도 동일해야만 완전히 동일한 값으로 본다.
setequal(s1,s2) # TRUE
identical(s1,s2) # FALSE / 벡터의 길이, 인덱스의 값, 데이터 타입도 동일해야만 완전히 동일한 값으로 본다.setequal(as.numeric(s1),s2) # TRUE
identical(s1,as.integer(s2)) # TRUE / 형변환하면 동일하게 나온다.
3. list
: 서로 다른 데이터 타입을 갖는 벡터를 저장하거나 다른 리스트를 저장할 수 있는 구조.
list(key=value, key=value)x <- list(name='홍길동',age=20,addr='강남구',pn='010-1000-0001')
str(x)
class(x)
typeof(x)
mode(x)
x$name
x$age
typeof(x$name)
typeof(x$age) 인덱싱
x[1] # key, value
x[2]
x[[1]] # value
x[[2]]
x[-1] # 1번 인덱스 제외슬라이싱
x[1:2]list key, value 추가, 수정, 삭제
list key, value 추가
x$sal <- 1000list value 수정
x$sal <- 10000list key, value 삭제
x$sal <- NULLlist 중첩할 수 있다
y = list(a=list(d=c(1,2,3)),
b=list(d=c(1,2,3,4)))
y$a
y$a$d
y$b
y$b$d
list key 확인
names(y)
names(y)[1]
names(y$a) # a라는 key 안에 keylist key 수정
names(y)[1] <- 'A'
names(y)[2] <- 'B' # 위와 같이 개별로 수정하거나
names(y) <- c('A','B') # 한꺼번에 수정할 수 있음
names(y$A) <- 'D'
names(y$B) <- 'E'list 값 수정
y$A$D <- 1:10is.list()
: list 자료형 체크 함수.
is.list(y)unlist()
: list 변수를 벡터 변수로 변환하는 함수. 컬럼 이름은 key 값으로.
unlist(y)4. matrix(행렬)
: 수나 문자를 직사각형 형태로 나타낸 자료형. 벡터처럼 한가지 유형의 타입만 저장한다. 행(가로), 열(세로) 구성된다.
matrix(c(1:9))
matrix(c(1:9),nrow=3) # nrow : 행의 수
matrix(c(1:9),ncol=3) # ncol : 열의 수
matrix(1:10,nrow=2,ncol=5)m <- matrix(1:12,nrow=6,ncol=2)
str(m)
class(m)
typeof(m) # integer
mode(m) # numericis.integer(m)
is.numeric(m)
is.list(m)
is.character(m)
is.logical(m)
is.matrix(m) # matrix 자료형 체크하는 함수dim(m) # 6 2 / 행렬의 크기 6*2, 행의 수*열의 수
NROW(m) # 행의 수
dim(m)[1] # 행의 수
nrow(m) # 행의 수
dim(m)[2] # 열의 수
ncol(m) # 열의 수length(m) # 행렬안에 들어있는 값들의 수
x <- 1:9 # x는 벡터
length(x)
NROW(x)
nrow(x) # NULL / 소문자 nrow는 벡터에서는 수행되지 않음
matrix(x,ncol=3)
matrix(x,ncol=3,byrow=FALSE) # byrow=FALSE 열 기준으로 값을 채움, 기본값
matrix(x,ncol=3,byrow=TRUE) # byrow=TRUE 행 기준으로 값을 채움dimnames
: 행 이름, 열 이름을 지정할 수 있는 옵션
m <- matrix(1:4,nrow=2,ncol=2,byrow=T,
dimnames=list(c('row1','row2'),c('col1','col2')))
dimnames(m) # 행렬의 이름 확인
class(dimnames(m))
dimnames(m)[1] # 행 이름
dimnames(m)[[1]]
rownames(m)
dimnames(m)[2] # 열 이름
dimnames(m)[[2]]
colnames(m)행 이름 수정
rownames(m) <- c('r1','r2')열 이름 수정
colnames(m) <- c('c1','c2')
전치행렬
: 행과 열의 위치를 바꾼 행렬
cell <- 1:9
rname <- c('a','b','c')
cname <- c('c1','c2','c3')
m <- matrix(cell,nrow=3,byrow=T,dimnames=list(rname,cname))
t(m) # 전치 행렬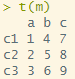
행렬 인덱싱
m[1,1] # [행 인덱스, 열 인덱스]
m[2,1]
m[2,] # [행 인덱스, ] : 행만 뽑아내기
m[,3] # [열 인덱스, ] : 열만 뽑아내기
m[-1,] # 특정한 행 인덱스 제외
m[,-1] # 특정한 열 인덱스 제외
m[-1,-2] # 특정한 행, 열 인덱스 제외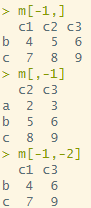
m[c(1,3),] # 특정한 행 인덱스 추출
m[,c(1,3)] # 특정한 열 인덱스 추출
행렬 연산
m+100
m-100
m*10
m/2
m%/%2
m%%2
m^2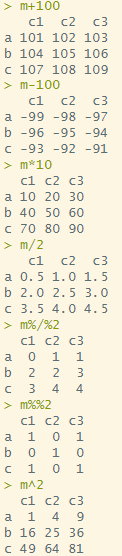
행렬은 같은 위치에 있는 성분끼리 연산 작업을 수행한다.
x <- matrix(1:4,ncol=2)
y <- matrix(5:8,ncol=2)
x+y
x-y
x*y
x/y
x%/%y
x%%y
x^y

행렬의 곱
dim(x)
dim(y) # dim의 갯수가 맞아야 곱이 가능함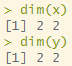
x%*%y
정방행렬(square matrix)
: 같은 수의 행과 열을 가지는 행렬.
2*2, 3*3, 4*4항등행렬(identity matrix), 단위행렬(unit matrix)
: 대각성분이 모두 1이고 그 이외의 성분이 0인 정방행렬.
diag(4)
diag(2)
diag(3)
diag(2) # 대각성분이 1인, 2행 2열대각행렬(diagonal matrix)
: 대각성분이 0이 아닌 정방행렬.
diag(2,nrow=3) # 대각성분이 2인, 3행 3열
diag(7,nrow=5)역행렬(invertible matrix)
: 행렬과 역행렬의 곱으로 단위행렬이 만들어진다.
x
solve(x) # 역행렬
x%*%solve(x) # 행렬 x 역행렬
행렬의 결합
cbind(x,y) # 열 결합(두 행렬의 행의 갯수가 맞아야 함)
rbind(x,y) # 행 결합(두 행렬의 열의 갯수가 맞아야 함)
5. array(배열)
: 같은 데이터 타입을 갖는 3차원 배열 구조.
matrix
x <- array(1:9,dim=c(3,3)) # dim=c(행,열)
x
class(x)
str(x)
mode(x)
typeof(x)
is.matrix(x) # TRUE
is.array(x) # TRUE
dim(x) # 2,2array
x <- array(1:24,dim=c(2,3,4)) # dim=c(행,열,면)
x
class(x)
str(x)
mode(x)
typeof(x)
is.matrix(x) # FALSE
is.array(x) # TRUE
dim(x) # 2,3,4x[1,1,1] # [행,열,면]
x[1,1,4]
dimnames(x) <- list(c('r1','r2'),c('c1','c2','c3'))
x
dimnames(x)
rownames(x)
colnames(x)
dimnames(x) <- NULL
dimnames(x)
dim(x) # 배열 모양 확인
dim(x) <- c(3,4,2) # 배열 모양 수정
dim(x)
dim(x) <- c(4,6) # 배열 모양 수정(면 삭제)
x
is.matrix(x)
is.array(x)6. factor
: 범주형 데이터를 표현하는 자료형. 순위형(ordinal), 명목형(nominal) 등의 종류가 있다. ex) (좋음, 보통, 나쁨), (남자, 여자), 거주지역, 혈액형 ...
명목형(nominal)
x <- factor("나쁨",levels=c("좋음","보통","나쁨"))
str(x) # 3개의 레벨 중 2번 레벨 값을 가진다는 뜻
class(x)
mode(x) # 문자가 들어갔지만 내부적으로는 숫자가 들어있는 것처럼 보임
typeof(x)순위형(ordinal)
y <- factor("보통",levels=c("좋음","보통","나쁨"),ordered=T) # ordered=T : 순위형 factor
str(y) # 3개의 레벨 중 2번 레벨 값을 가진다는 뜻
class(y)
mode(y) # 문자가 들어갔지만 내부적으로는 숫자가 들어있는 것처럼 보임
typeof(y)is.factor()
: factor 자료형 체크 함수.
is.factor(x)
is.factor(y)is.ordered()
: 순위형 factor 체크 함수.
is.ordered(x) # 명목형이므로 FALSE
is.ordered(y) # 순위형이므로 TRUElevels(), nlevels()
: factor level 값이나 수를 확인하는 함수.
levels(x) # factor level 값 확인
nlevels(x) # factor level 수 확인
levels(x) %in% '좋음'
'좋음' %in% levels(x)
which(levels(x) %in% '좋음') # '좋음'이 있는 인덱스 위치factor level 수정
levels(x)[which(levels(x) %in% '나쁨')] <- '매우나쁨'
levels(x)[which(levels(x) %in% '좋음')] <- '매우좋음'
x <- factor(c("나쁨","매우좋음"),levels=c("좋음","보통","나쁨"))
7. data frame
: 데이터베이스 table과 유사하다. 행과 열로 구성되어있다. 서로 다른 데이터 타입을 갖는 2차원 배열 구조이다.
df <- data.frame(name=c('scott','harden','curry'),
sql=c(90,80,70),
r=c(70,90,80))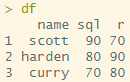
str(df) # R에서 숫자 값은 실수형이 기본값
class(df)
mode(df)
typeof(df)특정한 열 확인
df$name
df$sql
df$r
df[,'name']
df[,'sql']
df[,'r',drop=F] # drop=F 세로 방향으로 출력된다.행과 열
dim(df)
df[1,1] # [행,열]
df[1,] # 인덱스를 이용해서 행 추출
df[,2] # 인덱스를 이용해서 열 추출
df[c(1,3),] # 여러 인덱스를 이용해서 행 추출
df[,c(2,3)] # 여러 인덱스를 이용해서 열 추출열 이름 출력
names(df)
colnames(df)열 이름 수정
colnames(df) <- c('NAME','SQL','R')
colnames(df)[3] <- 'PYTHON' # 특정한 위치의 열 이름 수정행 이름 출력
rownames(df)행 이름 수정
rownames(df) <- c('사원1','사원2','사원3')
rownames(df) <- NULL # 초기값으로 수정행과 열의 수
dim(df) # 행, 열의 수
dim(df)[2] # 열의 수
length(df) # 열의 수. R의 데이터프레임에서 length는 행의 수가 아닌 열의 수이다.
dim(df)[1] # 행의 수
NROW(df) # 행의 수
nrow(df) # 행의 수특정한 열 이름 찾기
'SQL' %in% names(df)
'SQL' %in% colnames(df)
names(df) %in% 'SQL'
colnames(df) %in% 'SQL'
which(colnames(df) %in% 'SQL')
which(colnames(df) == 'SQL')
df[,c('SQL','PYTHON','R')] # 오류 발생. 왜냐하면 'R'이라는 컬럼이 없기 때문에위의 'R'처럼 없으면 없는대로 있는 열들만 뽑아낼수 있는 방법이 뭐가 있을까?
df[,names(df) %in% c('SQL','PYTHON','R')] # 특정한 열이 있는지를 확인한 후에 추출
# 'R'이라는 열은 없으니까 'SQL','PYTHON'이라는 열만 추출된다!
df[,!names(df) %in% c('SQL')] # 특정한 열을 제외한 후 추출
which(names(df) %in% c('SQL','PYTHON','R'))
which(!names(df) %in% c('SQL','PYTHON','R'))값을 수정
df[1,1] <- 'james'새로운 열 추가
df$R <- c(90,80,60)열 삭제
df$R <- NULL새로운 행 추가
df[4,] <- c('scott',100,90)
df[nrow(df)+1,] <- c('박찬호',90,80)아래의 SQL문을 R로 나타내면 어떻게 해야할까?
SQL
SELECT *
FROM df
WHERE NAME = '박찬호'R
df[df$NAME == '박찬호',]
df[df$NAME == '박찬호','NAME']
행 삭제
df <- df[!df$NAME == '박찬호',]
df <- df[-which(df$NAME == 'scott'),]행 추출
df <- data.frame(x=1:1000000)
head(df) # 상위 6개 행 추출
tail(df) # 하위 6개 행 추출
head(df,n=10) # n=10 추출해야할 행의 수
tail(df,n=10) read.csv()
: csv 파일을 데이터프레임으로 읽어 들이는 함수
employees <- read.csv("c:/data/employees.csv",header=T) # 컬럼이름이 있으면 header=T
employees
str(employees)
departments <- read.csv("c:/data/departments.csv",header=T)
departments
str(departments)SQL
SELECT *
FROM employees
WHERE employee_id = 100;R
데이터프레임[행 추출 조건,열 추출 조건]employees[employees$EMPLOYEE_ID == 100,]
employees[employees$SALARY >= 2000,c('LAST_NAME','SALARY')]
employees[!employees$JOB_ID == 'ST_CLERK',c('LAST_NAME','SALARY','JOB_ID')]
employees[employees$JOB_ID %in% c('AD_ASST', 'AC_ACCOUNT'),c('LAST_NAME','SALARY','JOB_ID')]
employees[!employees$JOB_ID %in% c('AD_ASST', 'AC_ACCOUNT'),c('LAST_NAME','SALARY','JOB_ID')]
employees[employees$DEPARTMENT_ID %in% c(20,30,40) & employees$SALARY >= 10000,
c('LAST_NAME','SALARY','DEPARTMENT_ID')]
employees[employees$DEPARTMENT_ID %in% c(20,30,40) | employees$SALARY >= 10000,
c('LAST_NAME','SALARY','DEPARTMENT_ID')] write.csv()
: 데이터프레임을 csv 파일 형태로 저장하는 방법
write.csv(result,"c:/data/result.csv",row.names=F) # row.names=F 행 번호는 저장되지 않음