
BeautifulSoup
파이썬에서 사용할 수 있는 웹데이터 크롤링 라이브러리
install
- conda install -c anaconda beautifulsoup4
- pip install beautifulsoup4
from bs4 import BeautifulSoup
page = open("../data/03.beautifulsoup.html","r").read()
soup = BeautifulSoup(page,"html.parser")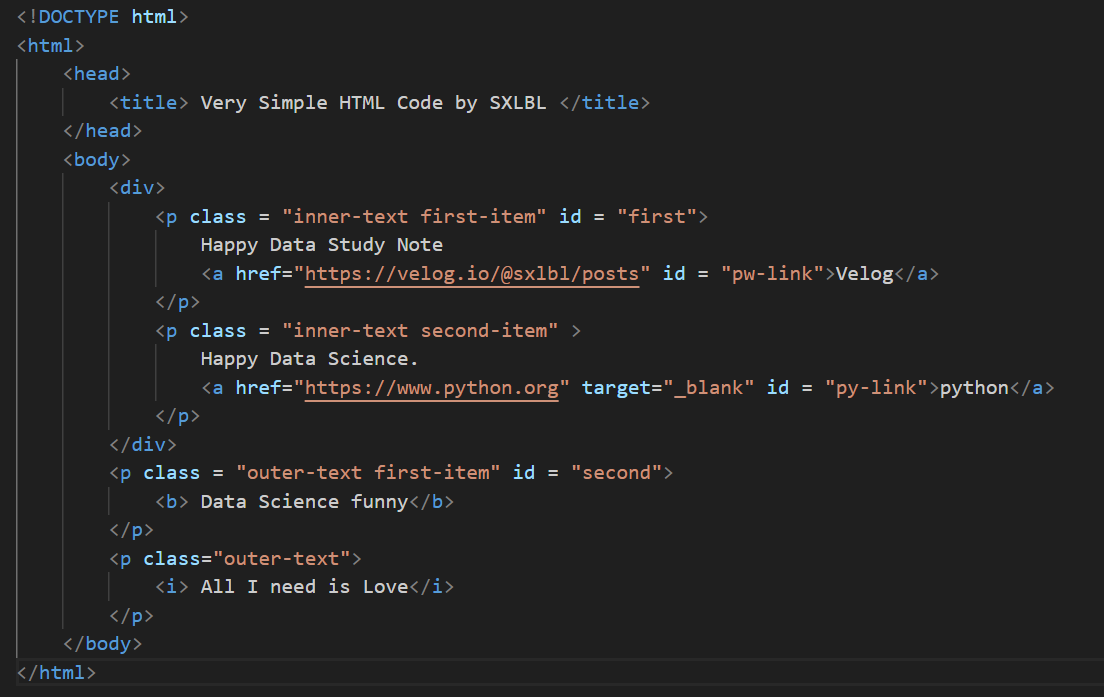
➡️ open으로 가져온 html구문
print(soup.prettify())
들여쓰기로 html 구문 확인 가능
1. head 태그확인
soup.head
<head>
<title> Very Simple HTML Code by SXLBL </title>
</head>2. body 태그확인
soup.body
<body>
<div>
<p class="inner-text first-item" id="first">
Happy Data Study Note
<a href="https://velog.io/@sxlbl/posts" id="pw-link">Velog</a>
</p>
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blank">python</a>
</p>
</div>
<p class="outer-text first-item" id="second">
<b> Data Science funny</b>
</p>
<p class="outer-text">
<i> All I need is Love</i>
</p>
</body>3. p 태그 확인
- 맨 앞 p 출력
soup.p
soup.find("p")
<p class="inner-text first-item" id="first">
Happy Data Study Note
<a href="https://velog.io/@sxlbl/posts" id="pw-link">Velog</a>
</p>
🚩 조건추가
soup.find('p',class_= "inner-text first-item")
<p class="inner-text first-item" id="first">
Happy Data Study Note
<a href="https://velog.io/@sxlbl/posts" id="pw-link">Velog</a>
</p>soup.find("p",{"class":"outer-text"})
<p class="outer-text first-item" id="second">
<b> Data Science funny</b>
</p>🚩다중조건
soup.find("p", {"class" : "inner-text first-item","id":"first"})
<p class="inner-text first-item" id="first">
Happy Data Study Note
<a href="https://velog.io/@sxlbl/posts" id="pw-link">Velog</a>
</p>
🚩 text만 추출
soup.find("p",{"class":"outer-text"}).text
'\n Data Science funny\n'soup.find("p",{"class":"outer-text"}).text.strip()
'Data Science funny'- 모든 P출력
soup.find_all("p")
🌟 리스트로 반환됨
[<p class="inner-text first-item" id="first">
Happy Data Study Note
<a href="https://velog.io/@sxlbl/posts" id="pw-link">Velog</a>
</p>,
<p class="inner-text second-item">
Happy Data Science.
<a href="https://www.python.org" id="py-link" target="_blank">python</a>
</p>,
<p class="outer-text first-item" id="second">
<b> Data Science funny</b>
</p>,
<p class="outer-text">
<i> All I need is Love</i>
</p>]
🚩 조건추가
soup.find_all("p", {"class" : "outer-text" })
soup.find_all(class_ = "outer-text" )
[<p class="outer-text first-item" id="second">
<b> Data Science funny</b>
</p>,
<p class="outer-text">
<i> All I need is Love</i>
</p>]soup.find_all(id = "pw-link")
[<a href="https://velog.io/@sxlbl/posts" id="pw-link">Velog</a>]
🚩 text만 추출
print(soup.find_all(id = "pw-link")[0].text)
print(soup.find_all(id = "pw-link")[0].string)
print(soup.find_all(id = "pw-link")[0].get_text())
Velog
Velog
Velogprint(soup.find_all("p")[0].text)
print(soup.find_all("p")[0].get_text())
Happy Data Study Note
Velogprint(soup.find_all("p")[1].text)
print(soup.find_all("p")[1].get_text())
Happy Data Science.
python
🚩 for문활용
for each_tag in soup.find_all("p"):
print('='*50)
print(each_tag.get_text())
#or
for each_tag in soup.find_all("p"):
print('='*50)
print(each_tag.get_text())#결과값
==================================================
Happy Data Study Note
Velog
==================================================
Happy Data Science.
python
==================================================
Data Science funny
==================================================
All I need is Love
🚩a태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
for each in links :
href = each.get("href")
text = each.get_text()
print(text + " -> " +href)#결과값
Velog -> https://velog.io/@sxlbl/posts
python -> https://www.python.org예제 | 네이버금융
네이버페이증권 링크 : https://finance.naver.com/marketindex/
import requests
# = from urllib.request import Request
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
soup = BeautifulSoup(response.text,"html.parser")
print(soup.prettify())➡️ 네이버페이 HTML 불러오기
🌟 용어
#: id (HTML에서 id는 고유값).: class>: 하위에 라는 뜻
1. 환전 고시 환율 부분 불러오기

exchangeList = soup.select('#exchangeList > li')
exchangeList
➡️ id exchangelist에 해당하는 li(list) 불러오기 - 총 4개
2. 필요항목 가져오기
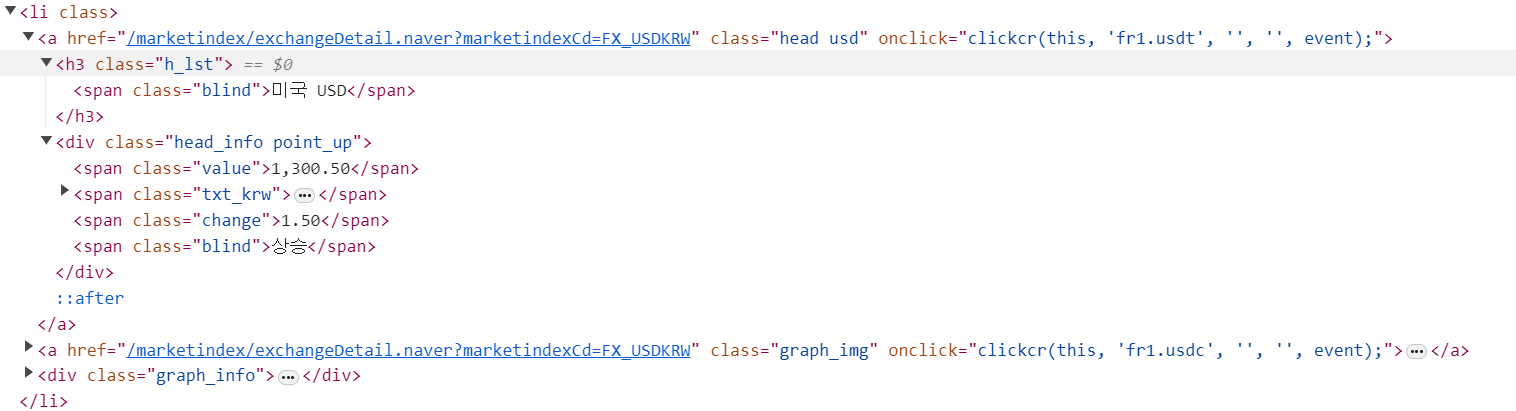
exchange_datas = []
baseurl = "https://finance.naver.com/"
for item in exchangeList :
data = {
"title" : item.select_one(".h_lst").text,
"exchange" : item.select_one(".value").text,
"change" : item.select_one(".change").text,
# "updown" : item.select_one(".head_info.point_up > .blind").text,
"link" : baseurl + item.select_one("a").get("href")
}
exchange_datas.append(data)
exchange_datastitle| class_ = h_lst에 해당하는 textexchange| class_ = value에 해당하는 textchange| class_ = change 해당하는 textlink| a 에서 href 가져오기updown| class_ = head_info.point_up의 > 하위에 있는 blind 클래스
➕ HTML 문법 구문에는 head_info point_up 이지만, 파이썬에서는 공백을 .으로 적어줘야함
➕ 환율이 상승일 경우 head_info.point_up 하락일경우 head_info.point_dn 으로 달라서 for문 사용 불가
exchange_datas[0]["updown"] = exchangeList[0].select_one("div.head_info.point_up > .blind").text
exchange_datas[1]["updown"] = exchangeList[1].select_one("div.head_info.point_dn > .blind").text
exchange_datas[2]["updown"] = exchangeList[2].select_one("div.head_info.point_up > .blind").text
exchange_datas[3]["updown"] = exchangeList[3].select_one("div.head_info.point_up > .blind").text
➡️ 수기로 넣어주었음
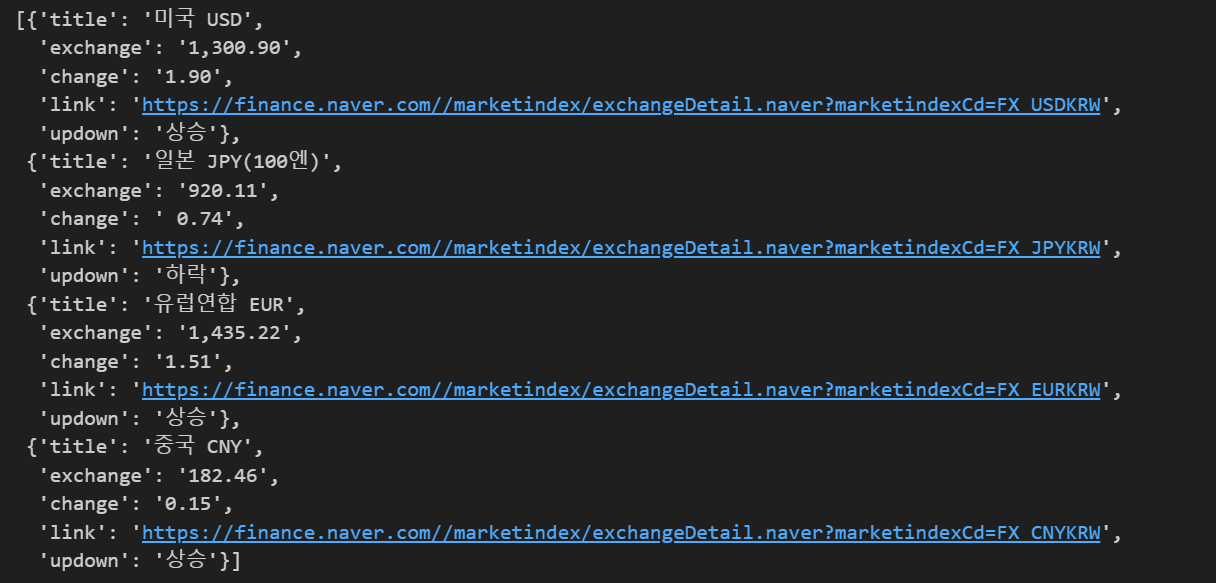
3. 엑셀보내기
import pandas as pd
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx")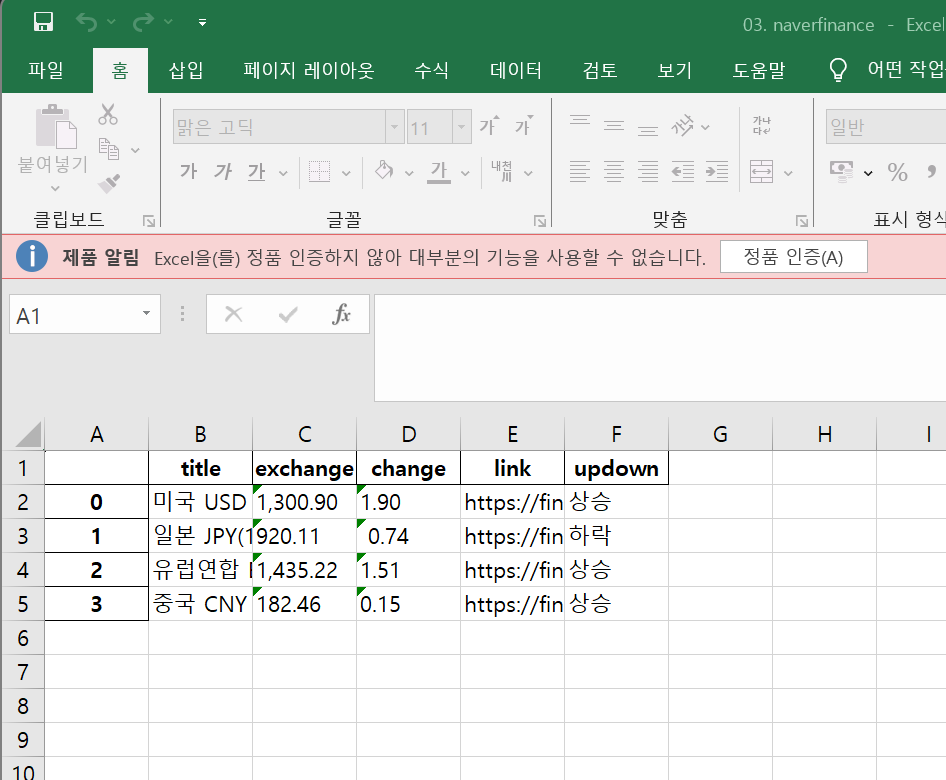
예제 | 위키백과 크롤링
url에 한글이 껴있는경우
html = "https://ko.wikipedia.org/wiki/{search_words}"
한글부분 {}포맷처리 후
from urllib.request import urlopen, Request
import urllib
req = Request(html.format(search_words = urllib.parse.quote("여명의눈동자")))
response = urlopen(req)
soup = BeautifulSoup(response,"html.parser")
print(soup.prettify())request에서 변수.format(변수 = urllib.parse.quote("내용"))으로 처리
====== 총정리 ======
import
from bs4 import BeautifulSoup
➡️BeautifulSoup(경로orURL, "html.parser")
import requests
➡️requests.get(url)
import urllib.request import urlopen
➡️urlopen(url)
1. open("파일경로","r").read()
: HTML문서가 파일로 존재할 때
from bs4 import BeautifulSoup
page = open("../data/03.beautifulsoup.html","r").read()
soup = BeautifulSoup(page,"html.parser")
print(soup.prettify())2. requests.get(url)
: url로 가져올 때
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
soup = BeautifulSoup(response.text,"html.parser")
print(soup.prettify())3. urllib
: url에 한글이 있어 깨지는경우
from urllib.request import urlopen, Request
import urllib
# html = https://ko.wikipedia.org/wiki/여명의_눈동자
html = "https://ko.wikipedia.org/wiki/{search_words}"
req = Request(html.format(search_words = urllib.parse.quote("여명의눈동자")))
response = urlopen(req)
soup = BeautifulSoup(response,"html.parser")
print(soup.prettify()){}로 변수 설정 후
Request()에서 format
or decoding 시키기
파이썬 urllib, requests 차이
HTML로 내용확인
soup 변수에 HTML 크롤링 or 경로저장 후
1. prettify()
print(soup.prettify())
: HTML구문 들여쓰기 확인가능
2. head
soup.head
: HTML구문 내 head 확인가능
3. body
soup.body
: HTML구문 내 body 확인가능
4. find()
soup.find("p")
soup.find('p',class_= "inner-text first-item")
soup.find("p",{"class":"outer-text"})
: 첫 p구문 찾기 , 로 조건걸기 가능
5. find_all()
soup.find_all("p")
soup.find_all(class_ = "outer-text" )
soup.find_all("p", {"class" : "outer-text" })
: 전체 P구문 찾기 ,로 조건걸기 가능
➕ text만 보기
print(soup.find_all(id = "pw-link")[0].text)
print(soup.find_all(id = "pw-link")[0].string)
print(soup.find_all(id = "pw-link")[0].get_text())
: HTML 구문 날리고 text만 뽑기
6. select()
🌟 용어
#: id (HTML에서 id는 고유값).: class>: 하위에 라는 뜻
경로를 통해 찾을 때 유용
exchangeList = soup.select('#exchangeList > li')
참고
- https://desarraigado.tistory.com/14 : select, find_all 차이점
Daily Study Note
