Contents
- Logistic loss
- Data preprocessing
- SGDClassifier
1. Logistic loss
Deep learning 에서 binary cross entropy 로 사용되는 로지스틱 손실 함수는 분류 시 최적화를 수행한다. 특히 prediction (y_pred) 과 target (y_true) 값을 비교해 둘의 차이가 적다면 작은 양수값을 loss 로 가지도록 하는 반면, 둘의 차이가 크다면 큰 양수값을 부여한다.
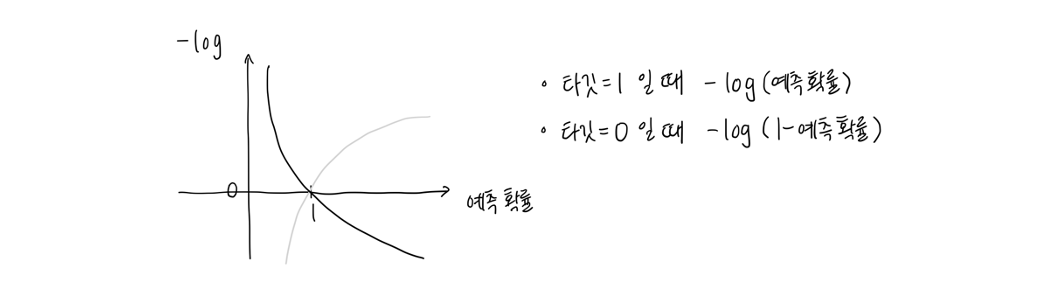
예를 들어 타깃이 1 일 때 예측값 0.2 와 0.8 을 가정해보자. Logistic loss 로 각각 -log(0.2) 와 -log(0.8) 을 갖으며, 후자가 더 작은 값이다. 즉, 0.8 로 예측을 할 시 손실이 더 적다는 의미이다.
2. Data preprocessing
SGD 는 데이터 전처리가 요구되는데, 이는 최적화 시 SGD 가 이용하는 gradient descent 가 각 features 의 스케일에 민감하기 때문이다. 왜 그럴까?
Learning rate, which controls the step size in each iteration, can become harder to tune when features are on different scales.
- A learning rate that works well for one feature might be too large for another, causing instability in learning.
여러 가지 이유가 존재하는데, 그 중 하나로 learning rate 을 들 수 있겠다. Learning rate 은 경사를 조금씩 하강하도록 하는 step size 인데 서로 다른 특성들 간에 스케일이 맞지 않는다면 하나의 특성에 대해서는 점진적이지만 다른 하나의 특성에는 step size 가 너무 클 수 있고, 이는 곧 불안정한 학습으로 이어진다.
예로 들어 하나의 dataset 에 range 가 다른 두 가지의 특성 과 이 있다면, 에 learning rate 을 맞출 경우 에는 너무 큰 rate 이 될 것이다.
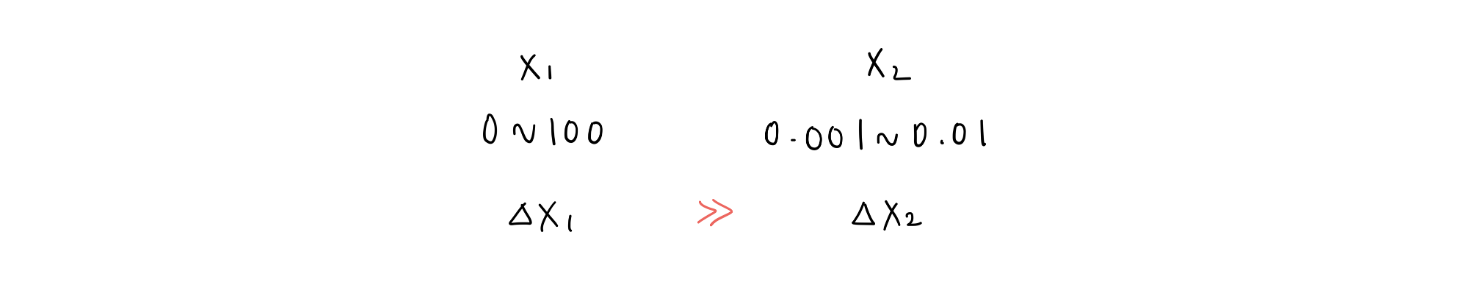
3. SGDClassifier
Sci-kit learn 에서 제공하는 SGD classes 로는 분류 알고리즘을 위한 SGDClassifier 와 회귀 알고리즘을 위한 SGDRegressor 가 있다. 참고로 DL 에서 배울 Tensorflow 의 Keras API 는 세 가지의 gradient descent 를 모두 제공한다.

또한, SGD 는 직접적인 ML/DL 모델이 아닌 최적화 알고리즘이라는 점에서 'loss' 라는 parameter 로 실제 어떤 모델을 최적화 할 지를 정해주어야 한다.
우리는 로지스틱 회귀를 통해 채소 데이터를 분류할 것이므로 SGDClassifier 에 log_loss 를 적용하도록 하자.
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log_loss')
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target)) # 0.6470588235294118
print(sc.score(test_scaled, test_target)) # 0.725그렇다면 방금 훈련을 마친 기존의 모델을 유지하되, 데이터를 다시 학습하기 위해 partial_fit() method 를 이용할 수 있고, 전보다 정확도가 조금 더 증가한 것을 알 수 있다.
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target)) # 0.773109243697479
print(sc.score(test_scaled, test_target)) # 0.85