Contents
- Model fitting with epochs
- Early stopping
1. Model fitting with epochs
이전에 규제를 배우며 과대적합과 과소적합에 대해 알아보았다. 규제 강도 (𝛼) 가 커질수록 train score 와 test score 모두 감소하는 과소적합을 보였고 강도가 작아지면 train set 에만 잘 맞는 과대적합을 보인다. 이와 같은 관계가 model fitting 과 epochs 사이에도 존재한다. 다음은 loss 와 accuracy 그래프이다.
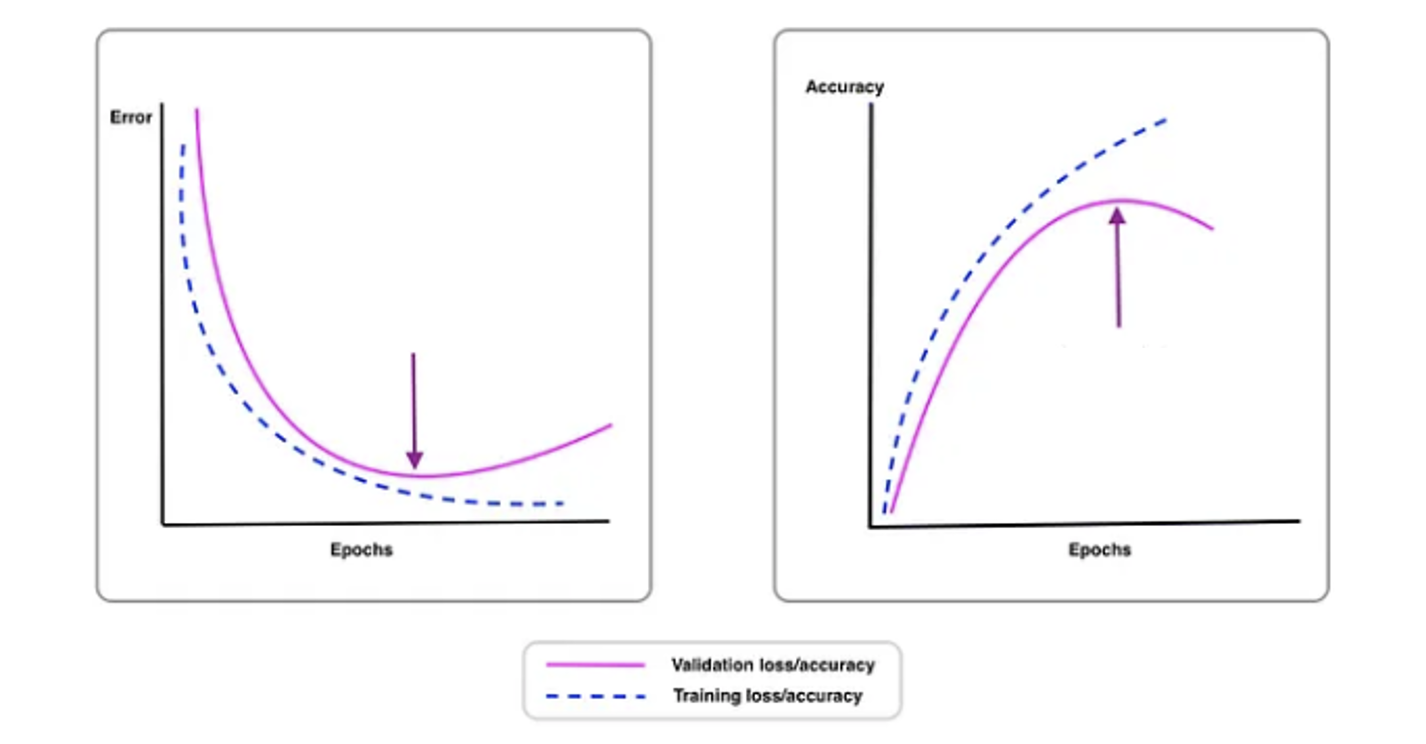
Epochs 가 너무 작을 시 과소적합이 발생하고 오히려 특정 threshold 를 넘긴다면 과대적합이 발생해 test score 가 떨어진다. 따라서 테스트 성능이 떨어지기 전 화살표로 표시된 훈련세트와 가까운 지점을 찾아 조기 종료 한다면 overfitting 을 방지함과 동시에 최적의 모델을 얻을 수 있다.
2. Early stopping
Early stopping provides guidance as to how many iterations can be run before the model starts to overfit.
Early stopping 은 regularization 의 한 종류로서, 먼저 epochs 를 크게 늘려 학습하여 최적인 지점을 찾은 후 해당 epochs 까지만 다시 훈련하는 것이다. 이는 gradient descent 와 같은 iterative methods 로 훈련 시 overfitting 을 방지할 수 있다는 장점이 있다.
sc = SGDClassifier(loss='log_loss')
train_score = []
test_score = []
classes = np.unique(train_target)
for _ in range(0,300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
test_score.append(sc.score(test_scaled, test_target))Accuracy vs Epochs 그래프를 그려보기 위해 위와 같이 score 를 저장해주자. 특히 partial_fit() method 를 사용할 때에는 분류해야 하는 전체 classes 를 알 수 없으므로 직접 classes 라는 parameter 를 통해 알려주어야 한다. 이에 반해 fit() method 는 이미 전체 데이터에 대한 것이므로 classes 매개변수가 불필요하다. 결과적으로 우리는 다음과 같은 그래프를 얻을 수 있다.
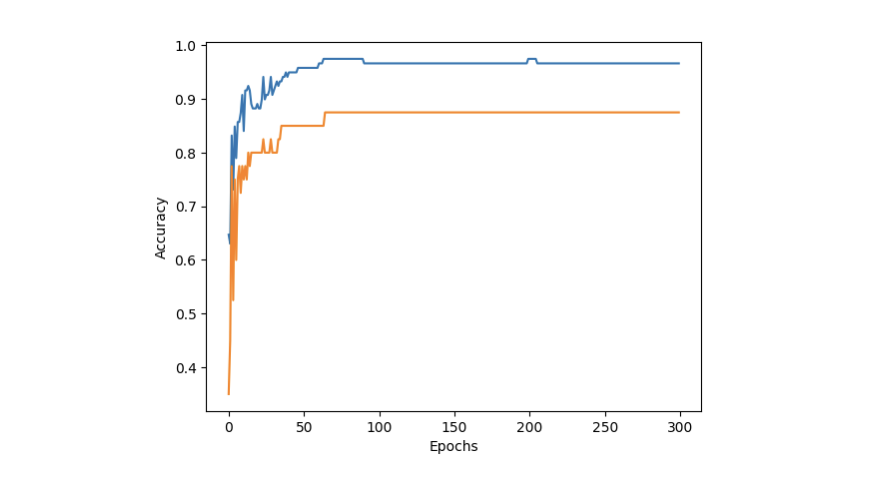
Epochs 를 더 늘리더라도 테스트 점수가 급격히 떨어지지 않으므로 훈련 횟수를 증가시킬 수도 있지만, 그만큼 자원도 많이 소모해야 하므로 굳이 권장하지 않는다. 따라서 100 정도의 epochs 가 적절할 것으로 보인다. 그렇다면 max_iter 을 100 으로 설정하여 다시 partial_fit() 을 실행한 후 정확도를 비교해보면 이전보다 개선됐음을 알 수 있다.
sc = SGDClassifier(loss='log_loss', max_iter=100, tol=None)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target)) # 0.865546218487395
print(sc.score(test_scaled, test_target)) # 0.8참고로 tol 은 언제 멈출 지를 결정하는 criterion 이다 (float or None, default=1e-3).
If it is not None, training will stop when (loss > best_loss - tol) for n_iter_no_change consecutive epochs.
Partial_fit() method 의 관점에서 best_loss 는 훈련 중 가장 작은 loss 를 일컫는다. 그렇다면 tol=None 일 때의 criterion 은 현재 loss 가 best (smallest) loss 에 비해 tolerance 만큼의 flexibility 를 제공했음에도 significant improvement 를 이루지 못했을 때 멈추는 것이다.
