Contents
- Gradient descent
- Stochastic gradient descent
- Loss function
1. Gradient descent
Gradient Descent (GD) is an optimization algorithm for finding a local minimum of a differentiable function.
경사 하강법이라 불리는 gradient descent 는 말 그대로 경사를 내려가며 local minimum 을 찾는 방법이다. 특히 machine learning 이나 deep learning 에서 GD 는 함수의 손실을 최소화하는 parameters 를 찾기 위해 사용된다. 이때 연속적인 곡선으로 이루어진 경사가 요구되는데, 이는 곧 미분가능을 의미한다.
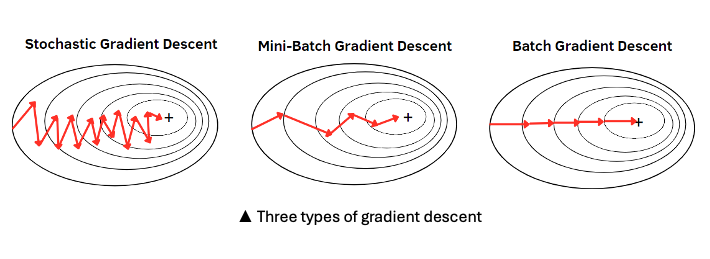
세 종류의 GD 중 stochastic 은 훈련세트에서 한 개씩 샘플을 꺼내 조금씩 경사를 따라 이동하는 것을 반복하는 반면, mini-batch 와 batch 는 각각 여러 개의 샘플을 꺼내거나 한꺼번에 전체 샘플을 꺼내 동일한 훈련을 반복한다. 이때 모든 샘플에 대한 훈련을 마치는 것이 epoch 에 해당한다. 가능한 많은 샘플을 꺼내는 것이 분명 가장 안전하며 이상적이지만, 일반적으로 크기가 매우 큰 데이터들을 다루기 때문에 메모리 부족 등의 문제가 발생한다.
기존의 데이터에 새로운 샘플들이 계속 추가되는 상황을 떠올려보자.
그렇다면 우리는 이미 학습시킨 모델을 매번 새로 remodeling 해야할까? 훈련데이터가 점점 더 많아질 것이므로 이는 좋은 방법이 아니다. 기존의 데이터 크기를 유지하기 위해 일부를 버리고 다시 훈련을 시킨다면? 이 또한 샘플 수가 적은 특정 데이터가 큰 타격을 입을 수 있다. 따라서 학습을 이미 마친 모델을 유지하되, 경우에 따라 업데이트만 해줄 수는 없을지 알아보도록 하자.
2. Stochastic Gradient Descent
이에 대한 답으로 우리는 점진적 학습을 통한 최적화 알고리즘의 Stochastic gradient descent 를 들 수 있다. 아래와 같이 무작위하지만 점진적으로 경사를 따라 내려가는 상황을 그려볼 수 있다.
Stochastic gradient descent (SGD) is an optimization algorithm to find the model parameters that correspond to the best fit between predicted and actual output.
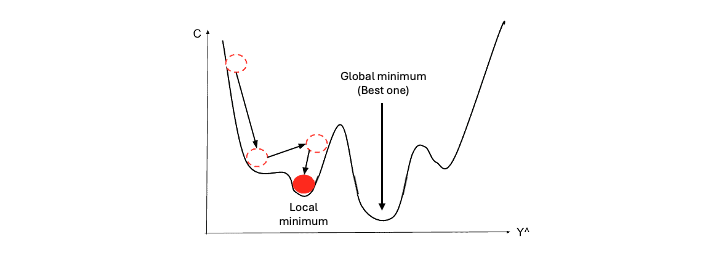
특히 조금씩 하강하는 것이 중요한데, 만약 learning rate 이 너무 크면 local 또는 global minimum 을 찾지 못하고 건너뛸 수 있기 때문이다.
3. Loss function
그렇다면 '경사' 라는 것은 정확히 어떤 의미일까? 이는 바로 loss function을 일컫는다. 손실하는 값이기 때문에 loss 가 적을수록 최적이 될 것이다. SGD 를 통해 우리는 손실 함수의 값이 낮아지는 쪽으로 모델의 가중치와 절편에 점진적 변화를 줄 수 있다.
로지스틱 회귀와 같은 알고리즘을 이용해 분류를 수행하고자 할 때, 해당 모델의 성능을 파악하기 위한 metric 으로 정확도가 사용되지만 최적화를 하기에는 유효하지 않다. 앞서 언급했듯이 gradient descent 에 이용되는 loss function 은 미분가능한 함수여야 하는 반면, 분류의 정확도는 discrete 하기 때문이다.
