
👋에필로그
미니프로젝트에 했던 나만 보고 버리기 아까운 내용을 기록하기 위해 정리한 내용입니다. 자세한 내용을 적을 수 없어 간단하게 정리하며 소감 위주로 적은 글임을 알립니다.
🧐미니프로젝트란?
미니프로젝트(일명 미프!)는 지난 섹션에서 배운 내용들을 복습하는 차원에서 조별로 함께 실습하는 시간입니다.
(KT 교육장에서 사람들과 함께 대면할 수 있는 시간이기도 합니다.)
📚5차 미니프로젝트
5차에서는 데이터기반 DX솔루션 기획을 주제로 진행하였습니다.
사실상 STEP1 데이터 분석 DX 기획에서 배웠던 내용들을 종합적으로 진행해봤던 빅프로젝트 예행 연습이라고 할 수 있을 것 같습니다.
- DX 솔루션 개요서를 통해 고객의 문제에 대한 정의를 하고,
- 데이터 분석을 통해 정보를 제공하고
- DX 솔루션 프로토타입을 통해 고객 관점의 UI를 구성해 볼 수 있습니다.
주제
119 구급대원이 응급 상황에서 환자의 상태에 맞는 병원을 실시간으로 선정할 수 있도록 돕는 DX 솔루션 기획.
최근 응급실 환자 수용 거부로 인한 이송 문제를 해소하기 위해, 병원의 실시간 응급실 및 수술실 현황 분석을 기반으로 병원 선정 및 이송 문제를 자동화함으로써 해결할 수 있다.
5차 미니프로젝트의 일정을 정리하자면 이렇습니다.
Day2 _ 데이터 분석 및 모델링
2일차에서는 1일차에서 수집하고 전처리한 데이터를 기반으로 분석 및 모델링을 진행하였습니다.
📋데이터 분석
분석을 및 모델링을 위한 전처리를 진행하고 파생변수를 생성하는 과정을 수행하였습니다. 이를 시각화하여 데이터를 탐색적으로 분석하였습니다.
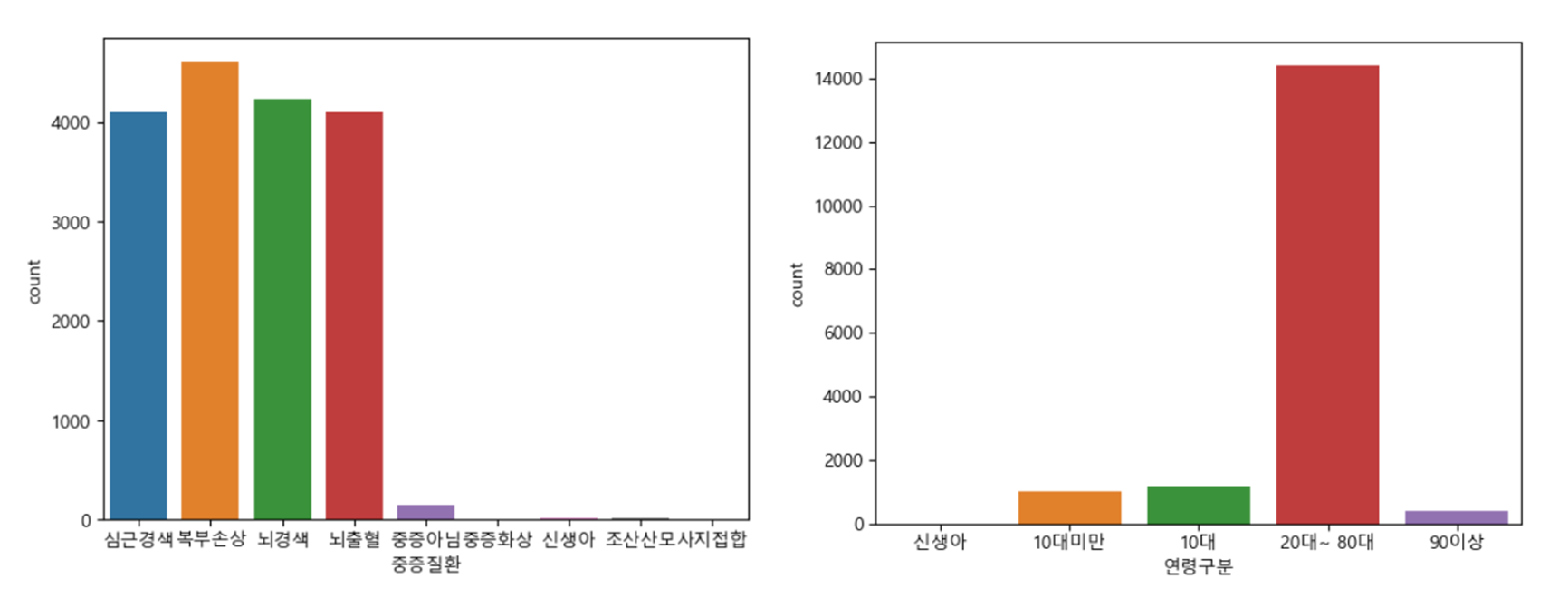
환자의 상태에 따른 중증질환을 예측하는 모델을 개발하기 위해 환자 상태 변수가 중증질환임을 판단할 수 있는지 검정하는 과정을 수행하였습니다.
카이제곱 검정 Chi-Square Test
증상과 중증질환 변수가 모두 1과 0으로 구성되기 때문에 범주형 변수 간의 차이를 검정하기 위해 카이제곱 검정을 수행하였습니다.
from scipy.stats import chi2_contingency
# sym: 증상
cross_sym = pd.crosstab(data[sym], data['중증질환'])
chi2_contingency(cross_sym)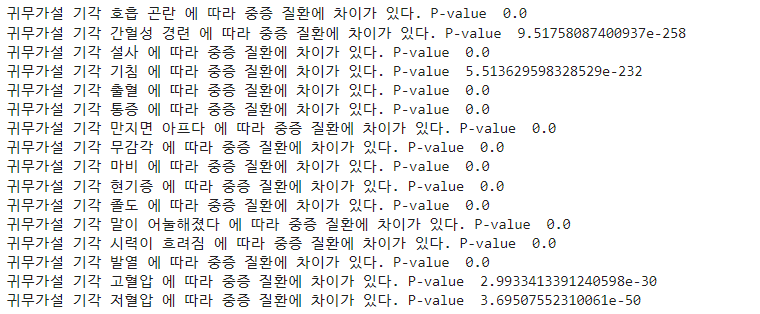
검정 결과, 모든 증상 변수가 중증질환에 영향을 미친다고 할 수 있기 때문에 증상 리스트를 기반으로 중증질환을 예측하는 모델의 설명변수를 구성하였습니다.
분산분석 ANOVA
환자의 상태를 나타내는 나이, 체온, 혈압과 같은 변수는 연속형 변수이기 때문에 수치형과 범주형 변수 간의 차이를 검정하기 위해 분산분석을 수행하였습니다.
from scipy.stats import f_oneway
# status: 상태
for c in status:
data_list = []
for s in diseases:
# 중증질환별로 데이터 분리하기
data_list.append(data.loc[data['중증질환'] == s, c])
# 통계 검증 : anova검증 (f_oneway)
spst.f_oneway(*data_list)
검정 결과, 나이를 제외한 상태 변수가 중증질환에 영향을 미친다고 할 수 있기 때문에 환자의 상태를 기반으로 중증질환을 예측하는 모델의 설명변수를 구성하였습니다.
📋모델링
환자의 상태가 주어졌을 때 중증질환임을 예측하는 모델을 개발하였습니다.
- 목적변수: 중증질환 여부
- 설명변수: 환자의 상태(체온, 혈압, 증상)
1) 데이터 분리
X = data.drop('중증질환, axis=1)
y = data['중증질환']2) 데이터 분할
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(X, Y, test_size=0.3, random_state=2023, stratify=Y)3) 모델링
모델은 의사결정나무(Decision Tree), 랜덤포레스트(Random Forest), XGBoost, DNN의 성능을 비교하여 가장 좋은 성능을 보이는 모델로 선정하였습니다.
# import
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.backend import clear_session
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score## Decision Tree
model_DTC = DecisionTreeClassifier()
model_DTC.fit(train_x, train_y)
pred_DTC = model_DTC.predict(test_x)
## Accuracy = 0.8839
print(accuracy_score(test_y, pred_DTC))## Random Forest
model_RFC = RandomForestClassifier()
model_RFC.fit(train_x, train_y)
pred_RFC = model_RFC.predict(test_x)
## Accuracy = 0.9086
print(accuracy_score(test_y, pred_RFC))## XGBoost
model_XGC = XGBClassifier()
model_XGC.fit(train_x, train_y)
pred_XGC = model_XGC.predict(test_x)
## Accuracy = 0.9174
print(accuracy_score(test_y_l, pred_XGC))## DNN
model_DNN = Sequential()
model_DNN.add(Dense(4,activation='softmax'))
#compile
model_DNN.compile(optimizer='adam', loss = 'sparse_categorical_crossentropy', metrics=['accuracy'])
#fit
history = model_DNN.fit(train_x, train_y_l, epochs=30, verbose=1)
#predict
pred_DNN = model_DNN.predict(test_x)
## Accuracy = 0.8771
print(accuracy_score(test_y, np.argmax(pred_DNN, axis=1)))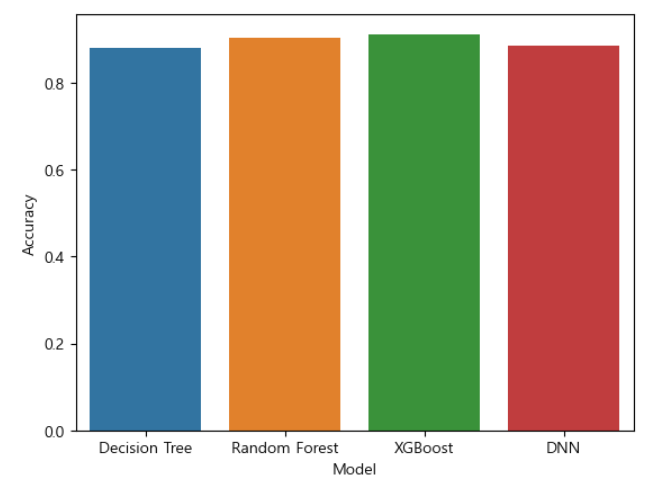
가장 성능이 좋았던 모델은 정확도가 0.9174로 평가된 XGBoost로 해당 모델로 예측모델을 선정하였습니다.
📝소감
2일차는 사실 휴가 이슈로 인해 수업이 끝나고 조원분의 파일을 받아서 정리를 위해 다시 공부를 하였습니다. 그래서 수업이 어땠는지는 모르지만 전반적인 흐름을 이해할 수 있었습니다.
데이터 분석 과정을 간단하게 정리만 하였지만 사실 데이터 분석과정이 가장 어렵다는 것을 알고 있기 때문에 본 프로젝트를 할 때에는 좀 더 구체적이고 신뢰할 수 있는 과정으로 데이터 전처리 및 분석 과정을 꾸려야 겠다는 생각을 하게 되었습니다.
모델링은 사실 튜닝 과정을 거치면 더 좋은 성능을 낼 수 있기 때문에 실습은 시간 관계상 간단하게만 모델을 생성하였던 것 같습니다.
2일차를 통해 전반적인 데이터 분석 및 모델링 과정을 다시 한번 경험할 수 있어서 좋았습니다.
