Overview
- 제목: MoMA: a mixture-of-multimodal-agents architecture for enhancing clinical prediction modelling
- 저널: npj Digital Medicine (25년 12월)
- 요약
- 멀티모달 EHR 데이터를 활용한 임상 예측 작업을 수행하는 LLM 에이전트
- 비정형(의료영상) 데이터를 각 모달리티별 Specialist Agent로 구조화된 텍스트 요약문 생성
- 각 모달리티의 요약문을 Aggregator Agent로 단일 요약문 생성
- Predictor Agent로 임상 예측 수행 (파인튜닝 적용)
Introduction
현대 의료는 임상 노트, 의료 영상, 활력 징후, 실험실 결과와 같은 다양한 환자 데이터 모달리티를 통합하는 전자 건강 기록(EHR) 을 점점 더 많이 활용하고 있습니다. 각 모달리티는 고유하고 상호 보완적인 정보를 제공합니다.
- 기록지: 의료 전문가가 기록한 환자의 증상, 진단 및 치료를 요약합니다.
- 의료 영상: 해부학적 구조와 병리학적 상태를 객관적으로 묘사하여 질병 탐지 및 모니터링을 용이하게 합니다.
- 랩데이터 및 바이탈 사인: 환자의 생리적 상태와 이상 징후를 수치화합니다.
이러한 멀티모달 EHR 데이터의 통합은 환자의 건강 상태에 대한 보다 총체적인 이해를 가능하게 합니다. 실제로 과업 관련 멀티모달 데이터를 통합하는 머신러닝 모델은 단일 모달리티에 의존하는 모델보다 우수한 성능을 보이는 것으로 나타났습니다.
멀티모달 통합 방법론
멀티모달 통합 방법론은 일반적으로 세 가지 범주로 나뉩니다:
- 조기 결합(Early Fusion): 훈련 전 입력을 결합.
- 공동 결합(Joint Fusion): 훈련 중 표현(Representation)을 함께 학습.
- 후기 결합(Late Fusion): 별도로 훈련된 모델의 출력을 결합.
특히 공동 결합은 모달리티 전반에 걸쳐 공유 임베딩 공간(Shared Embedding Space)을 학습하며, 이는 조기 또는 후기 결합보다 더 깊은 교차 모달 관계를 표현할 수 있습니다. 최근의 멀티모달 대규모 언어 모델(LLM)은 이러한 공동 결합 방법의 발전을 이끌고 있습니다.
기존 방식의 한계
하지만 기존의 모든 접근 방식(LLaVA-Med, VILA-M3 등)은 여전히 다음과 같은 문제에 직면해 있습니다.
- 방대한 데이터 요구: 공동 벡터 공간을 학습하기 위해 대규모의 쌍을 이룬(paired) 멀티모달 데이터셋이 필요합니다.
- 데이터 확보의 어려움: 의료 분야에서는 데이터 파편화와 복잡성으로 인해 동일한 환자나 사례에 대해 여러 모달리티가 완벽하게 연결된 데이터를 충분히 확보하기 어렵습니다.
- 확장성 부족: 새로운 모달리티가 추가될 때마다 상당한 수준의 지도 학습 기반 정렬(Supervised Alignment)이 필요합니다.
제안 방법: Mixture-of-Multimodal-Agents (MoMA)
이러한 한계를 극복하기 위해, 본 연구는 사전 학습된 LLM의 고유한 능력, 즉 멀티모달 임상 데이터를 자연어로 번역하는 능력을 활용하고자 합니다.
MoMA의 핵심 아이디어
- 언어를 공유 공간으로 활용: 최신 멀티모달 LLM은 비텍스트 데이터(영상, 수치 등)를 텍스트 요약으로 변환할 수 있습니다. 이 변환된 텍스트는 전통적인 공동 결합 방식의 '공유 벡터 공간'과 유사한 역할을 수행합니다.
- 제로샷(Zero-shot) 변환: 이 과정은 사전 학습된 LLM을 사용하여 추가 데이터 없이 수행될 수 있어, 방대한 데이터 요구 사항을 피할 수 있습니다.
- 협업 에이전트 구조: 여러 LLM 에이전트가 협력할 때 더 나은 결과를 낸다는 점에 착안하여, MoMA 아키텍처를 설계했습니다.
MoMA 아키텍처의 작동 원리
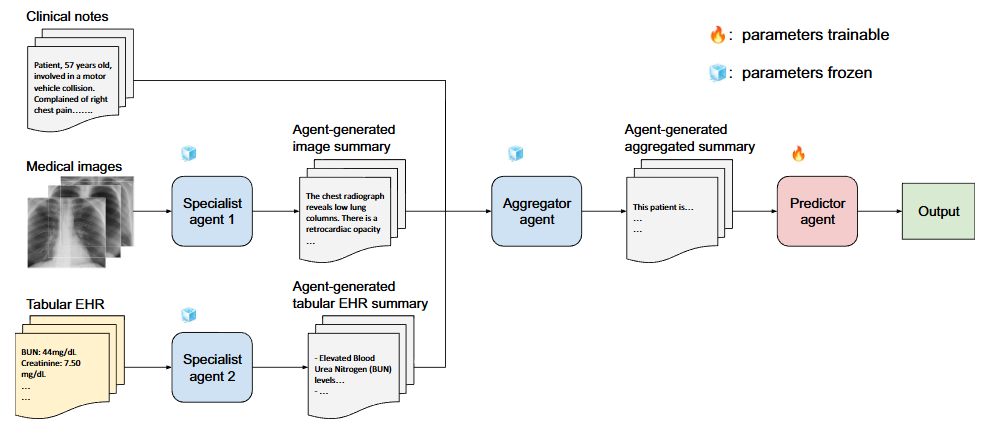
- 전문가 에이전트(Specialist Agents): 각 비텍스트 모달리티를 전담하는 LLM 에이전트가 데이터를 텍스트 요약으로 변환합니다.
- 통합 에이전트(Aggregator Agent): 생성된 요약들과 기존 임상 노트를 통합하여 하나의 통합된 서사(Unified Narrative)를 형성합니다.
- 예측 에이전트(Predictor Agent): 최종적으로 통합된 정보를 바탕으로 임상 예측을 수행합니다.
MoMA의 장점 및 검증 결과
MoMA는 기존 모델들과 차별화되는 몇 가지 강력한 이점을 가집니다.
- 플러그 앤 플레이(Plug-and-play): 재학습 없이 최신 멀티모달 LLM을 즉시 교체하거나 추가할 수 있습니다.
- 효율성: 전문가 및 통합 에이전트는 제로샷으로 작동하며, 오직 예측 에이전트만 미세 조정(Fine-tuning)이 필요합니다.
- 우수한 성능: 실제 의료 데이터셋(흉부 외상 중증도, 알코올 오남용 선별 등)에서 검증한 결과, 전체 테스트 세트뿐만 아니라 모든 성별 및 인종 하위 그룹에서도 베이스라인 모델을 능가했습니다.
- 자원 절감: 대규모 쌍을 이룬 데이터가 부족하거나 개인정보 보호 규정으로 인해 모델 공유가 어려운 기관에서도 정확한 임상 예측 모델을 개발할 수 있게 해줍니다.
Method
이 섹션에서는 본 연구에서 제안하는 MoMA 아키텍처를 제시합니다. 먼저 MoMA의 핵심적인 설계 통찰을 개략적으로 설명한 후, 각 에이전트의 역할과 최종 출력을 생성하기 위한 협력 프로세스를 상세히 기술합니다. 또한, 비교 베이스라인 역할을 하는 교차 주의(Cross-attention) 및 전문가 혼합(Mixture-of-Experts) 기반의 통합 방법을 소개합니다. 본 연구는 TRIPOD-LLM(개별 예후 또는 진단을 위한 다변량 예측 모델의 투명한 보고 - 대규모 언어 모델) 가이드라인을 준수하며, 부록 4에 상세히 기재된 모든 보고 요구사항을 충족하는 체크리스트를 완료했습니다.
멀티모달 에이전트 혼합(MoMA) 아키텍처
MoMA 아키텍처의 설계는 전문가 혼합(Mixture-of-Experts, MoE)과 에이전트 혼합(Mixture-of-Agents, MoA)이라는 두 가지 프레임워크를 기반으로 합니다.
- MoE 프레임워크: 게이팅 네트워크를 통해 각 입력을 가장 관련성 있는 전문가에게 전달함으로써, 전문가 지식을 적응적으로 활용하고 각 전문가에게 불필요한 정보가 과부하되지 않도록 하는 방식입니다.
- MoA 아키텍처: 전통적인 전문가와 게이팅 네트워크를 서로 다른 사전 학습된 LLM 에이전트로 대체하여 MoE 개념을 확장합니다. LLM 에이전트는 원래의 입력 텍스트에만 의존할 때보다 다른 LLM 에이전트의 출력을 추가 입력으로 포함할 때 더 나은 성능을 달성하는 경향이 있습니다.
본 연구에서는 MoA 프레임워크를 EHR 데이터의 여러 모달리티를 수용할 수 있도록 확장하여 MoMA 아키텍처를 제안합니다. 단일 텍스트 입력을 분석하는 기존 MoA와 달리, MoMA는 각 비텍스트 모달리티를 텍스트 요약으로 변환하는 전용 전문가 에이전트를 할당합니다. 이러한 요약들은 LLM의 협업 능력을 활용하기 위해 일련의 LLM 층을 통해 처리됩니다. 이 아키텍처는 멀티모달 LLM을 플러그 앤 플레이(plug-and-play) 방식으로 통합하여 점점 늘어나는 모달리티를 지원할 수 있습니다.
아키텍처 세부 정보 및 수식
MoMA의 핵심 설계 원칙은 다양한 모달리티를 텍스트 공간으로 정렬하는 것입니다. 원래의 임상 텍스트는 통합 에이전트에 도달할 때까지 처리되지 않은 상태로 유지됩니다.
- 전문가 및 통합 단계
- 전문가 에이전트는 이미지나 구조화된 실험실 결과와 같은 비텍스트 데이터를 간결한 텍스트 요약으로 변환합니다. 예를 들어, LLaVA-Med나 CXR-LLAVA는 의료 영상에서 요약을 생성하고, 구조화된 EHR 데이터는 Llama-3와 같은 범용 LLM으로 요약할 수 있습니다.
- 샘플 에 대해 통합 에이전트에게 제공되는 입력 는 다음과 같이 정의됩니다:
• : 샘플 의 원본 임상 텍스트
• : 텍스트 결합(Concatenation) 연산
• : 비텍스트 모달리티의 수
• : 번째 비텍스트 모달리티를 처리하는 전문가 에이전트
• : 번째 비텍스트 모달리티의 입력 데이터
- 통합 및 예측 단계
- 통합 에이전트()는 를 입력받아 모든 모달리티의 정보를 통합한 포괄적이고 간결한 요약을 생성합니다. 이 요약은 최종 예측을 수행하는 예측 에이전트()에게 전달됩니다.
- 여기서 는 샘플 의 출력 예측값입니다.
- 본 연구에서는 Llama-3를 표 형식 데이터의 전문가 에이전트, 통합 에이전트, 그리고 예측 에이전트로 모두 활용했습니다. 최종 예측을 생성하기 위해, 미세 조정된 Llama-3 통합 에이전트가 출력한 마지막 토큰의 은닉 상태(hidden state)를 추출하여 순전파 층(feedforward layer)에 통과시킴으로써 최종 로짓(logit)을 생성합니다. 사용자는 필요에 따라 이러한 에이전트들을 더 진보된 모델로 자유롭게 교체할 수 있습니다.
프롬프트 엔지니어링
본 연구는 MoMA 프레임워크에 최적화된 프롬프트를 생성하기 위한 일반적인 가이드라인을 제공합니다. 사용자는 아래 나열된 요소들을 LLM에 입력하여 프롬프트를 자동으로 생성할 수 있습니다. 구체적으로, 프롬프트는 텍스트 전문가 에이전트가 과업별 임상 정보를 추출하도록 안내하고, 비텍스트 전문가 에이전트가 임상 텍스트와 관련성이 높고 상호 보완적인 데이터를 식별하도록 지시하며, 통합 에이전트가 모든 전문가 에이전트의 출력을 합성 및 요약하도록 지시해야 합니다.
1. 텍스트 전문가 에이전트를 위한 프롬프트 가이드라인
텍스트 전문가 에이전트의 프롬프트 구성 요소는 다음과 같습니다.
- 관련 핵심 포인트 식별 (Identify Relevant Points)
- 전체 노트를 주의 깊게 읽고 주된 초점과 관련된 직접적인 언급을 강조합니다.
- 예시: "숙련된 외상 의사로서... 흉부 외상 부상을 요약하십시오."
- 지정된 기준 적용 (Apply Specified Criteria)
- 기록된 세부 사항을 명시된 임계값(예: 하루 음주 횟수, 특정 방사선 보고서 결과 등)과 비교합니다.
- 예시: "과도한 음주: 여성의 경우 하루 4잔 이상, 남성의 경우 5잔 이상..."
- 추가 환자 속성 통합 (Incorporate Additional Patient Attributes)
- 주요 소견과 겹치거나 이를 설명할 수 있는 공존 질환 또는 요인(예: 다른 진단명, 생활 방식 문제 등)을 찾습니다.
- 예시: "간염, 신기능 장애 등과 같은 상태에 대해 노트를 훑어보십시오..."
- 명확성과 흐름 유지 (Maintain Clarity and Flow)
- 소견을 하나의 일관된 요약으로 제시합니다. 확정적인 증거부터 시작하여 경계선에 있거나 불확실한 항목을 언급하고, 혼란 변수(Confounder)로 마무리합니다.
- 예시: "[X]의 증거와 다른 상태의 증거를 명확히 구분하여 소견을 요약하십시오..."
- 전문 용어 사용 및 비밀 유지 (Professional Language and Confidentiality)
- 객관적인 임상 용어를 사용합니다.
- 개인 건강 정보(PHI)를 누락하고 추측을 피합니다.
- 예시: "개인 건강 정보(PHI)를 포함하지 마십시오... 직접적으로 증명되지 않는 정보에 기반해 추측하거나 추론하지 마십시오."
- 최종 구조화된 검토 (Final Structured Review)
- 확인된 증거, 부분적/부재한 소견 및 관련 혼란 변수에 대한 간결한 개요로 마무리합니다.
- 예시: "이 기준을 충족하는 직접적인 증거가 발견되지 않으면, 직접적인 증거가 없음을 명시적으로 기재하십시오."
2. 비텍스트 전문가 에이전트를 위한 프롬프트 가이드라인
비텍스트 전문가 에이전트의 프롬프트 구성 요소는 다음과 같습니다.
- 관련 지표 식별 (Identify Relevant Indicators)
- 결과와 관련된 직접적인 측정치(예: 혈중 알코올 농도)를 스캔합니다.
- 검토의 초점이나 질환에 연결된 주요 수치를 찾습니다.
- 예시: "알코올 소비와 흔히 연관된 초기 측정치를 식별하십시오..."
- 간접적 증거 평가 (Evaluate Indirect Evidence)
- 결과와 관련된 이차적 또는 간접적 측정치(예: 비정상적인 효소 수치)를 확인합니다.
- 이것이 당면한 문제를 간접적으로 시사하는지 유의합니다.
- 예시: "간 수치 상승과 같은 간접적인 증거가 있는 실험실 검사를 고려하십시오..."
- 간결하게 요약 (Summarize Concisely)
- 가장 관련성이 높은 소견을 강조하는 짧고 명확한 개요를 작성합니다.
- 전문성을 유지하고 불필요한 추측을 배제합니다.
3. 통합 전문가 에이전트를 위한 프롬프트 가이드라인
통합 전문가 에이전트의 프롬프트 구성 요소는 다음과 같습니다.
- 에이전트 생성 요약에서 핵심 포인트 수집 (Gather Key Points from Agent-Generated Summaries)
- 임상 관찰, 실험실 소견 또는 영상 결과와 같이 각 요약에서 모든 관련 소견을 수집합니다.
- 예시: "에이전트가 생성한 요약을 검토하여 행동 패턴을 포함한 알코올 사용과 관련된 세부 정보를 식별하십시오..."
- 상충하는 정보 처리 (Handle Contradicted Information)
- 보고서 내용이 상충하는 경우, 자동 생성된 정보가 이미 확정된 증거를 덮어쓰지 않도록 합니다.
- 예시: "LLM이 생성한 방사선 보고서가 임상 노트와 서로 상충하는 경우, 임상 노트를 무시하지 않도록 하십시오..."
- 혼란 정보 제외 (Exclude Confounding Information)
- 목표와 관련 없는 대안적인 원인이 있는 세부 사항은 제외합니다.
- 예시: "언급된 실험실 이상 수치에 대해 임상 요약을 검토하여 알코올 사용과 관련 없는 원인이 있는지 확인하십시오."
- 통합된 요약 생성 (Create a Unified Summary)
- 특정 예측 과업을 위해 멀티모달 데이터에서 얻은 에이전트 생성 보고서들을 통합하여 포괄적인 요약을 생성합니다.
- 예시: "임상 요약과 실험실 결과 모두에서 관련 세부 정보를 통합하여 환자의 알코올 사용에 대한 종합적인 요약을 작성하십시오."
Published SOTA
본 연구에서는 성능 비교를 위해 기존의 최신 기술(SOTA) 방식들을 다음과 같이 구현하고 검증했습니다.
- ClinicalBERT 기반 모델: Gao 등의 설계를 따라 응급실(ED) 노트와 방사선 보고서를 입력값으로 사용하여 ClinicalBERT를 미세 조정했습니다.
- 토큰 할당: ClinicalBERT의 입력 길이 제한으로 인해, 정보 제공 가능성이 높은 노트를 우선순위에 두었습니다. ED 노트는 긴 순서대로, 방사선 보고서는 이른 시간 순서대로 정렬했습니다.
- 상세 설정: 첫 300개 토큰은 ED 노트에, 나머지 토큰은 방사선 보고서에 할당했으며, 한 쪽에서 토큰이 남으면 다른 쪽에 재할당했습니다. 전체 한도를 초과하는 노트는 절단(Truncation) 처리되었습니다.
- cTAKES 및 1D-CNN 모델: Afshar 등의 연구에 따라, 자연어 처리 엔진인 cTAKES를 사용하여 모든 환자 기록에서 질병, 증상, 해부학적 부위, 약물 및 처치와 같은 임상 개념을 추출했습니다.
- 예측 방식: 추출된 개념들은 임베딩 과정을 거쳐 알코올, 마약성 진통제(Opioid) 및 비마약성 약물 오남용에 대한 다중 과업 예측을 수행하는 1차원 합성곱 신경망(1D-CNN)으로 처리되었습니다.
- 검증: 기존 연구의 학습된 모델을 추가 미세 조정 없이 본 연구의 테스트 세트에서 평가했으며, MoMA와 동일한 코호트(환자군)를 사용하여 모델을 재학습시키기도 했습니다.
계산 자원 및 실행 시간
모델의 학습과 추론에 소요된 하드웨어 및 시간적 비용은 다음과 같습니다.
- 하드웨어 사양: 모든 실험은 80GB 메모리를 갖춘 두 대의 A100 GPU에서 수행되었습니다.
- 외상 중증도 분류 과업: 흉부 및 척추 외상 과업의 경우, 전문가 에이전트를 통한 요약 생성에 약 72시간이 소요되었으며, 나머지 프로세스는 4시간 이내에 완료되었습니다.
- 알코올 오남용 선별 과업: 전문가 에이전트의 요약 생성에 약 48시간이 소요되었고, 나머지 과정은 3시간 이내에 마무리되었습니다.
Results
Datasets and cohort characteristics
본 연구진은 위스콘신 대학교 병원 및 클리닉(UW Health)에서 수집된 비공개 데이터 세트를 활용하여 세 가지 임상 예측 작업인 흉부 외상 중증도 층화, 흉부 및 척추 외상 중증도 다중 작업(multitask) 층화, 그리고 비건강 음주 선별에 대해 MoMA 아키텍처를 검증했습니다. 이 작업들은 복잡성과 분류 구조 면에서 차이가 있습니다. 첫 번째는 흉부 외상에 대한 다중 클래스 분류를, 두 번째는 흉부와 척추 모두의 중증도를 공동으로 예측하는 다중 클래스 분류를, 세 번째는 비건강 음주에 대한 이진 분류를 다룹니다. 또한 작업별로 사용된 모달리티 조합도 다릅니다. 처음 두 작업은 자유 형식의 임상 노트와 흉부 X선 영상을 통합하며, 비건강 음주 선별 작업은 자유 형식 텍스트와 실험실 검사 수치를 결합합니다.
외상은 45세 미만 인구의 주요 사망 원인입니다. 흉부 외상은 가장 흔히 발생하는 외상 중 하나로, 외상 관련 사망의 거의 절반이 입원 후에 발생하며, 흉부 외상 중증도를 적시에 층화하는 것은 환자를 분류하고 합병증을 예측하는 데 도움이 될 수 있습니다. 흉부 외상 중증도 층화 작업에 사용된 코호트는 2015년 1월부터 2019년 12월 사이에 수집되었으며, 총 2,722명의 고유 환자 샘플로 구성되었습니다. 이 작업은 부상 중증도를 음성(negative), 경증/중등도(minor/moderate), 중증 이상(serious or greater)으로 분류하는 3개 클래스 분류를 포함했습니다.
UW Health의 공인 외상 등록 코더팀은 각 환자의 진료 사례에 대해 광범위한 수동 차트 추상화(manual chart abstraction)를 수행했습니다. 이 과정에서 미국 외상학회(ACS) 및 외상 질 향상 프로그램(TQIP) 표준을 준수하여 간이 외상 점수(AIS) 및 관련 외상 지표를 산출하고 검증했습니다. 각 환자 사례에는 전자 건강 기록(EHR)에서 추출된 텍스트 모달리티인 임상 노트와 비텍스트 모달리티인 흉부 X선 영상이 포함되어 있습니다.
흉부 외상 중증도 층화 작업과 동일한 코호트를 사용하여, 모델이 흉부와 척추의 부상 중증도를 동시에 예측하는 더 복잡한 다중 작업(multitask) 환경을 정의했습니다. 각 사례는 흉부 외상 중증도 층화 작업과 동일한 주석 프로토콜을 사용하여 라벨링되었으며, 흉부와 척추 각각에 대해 부상 중증도가 평가되었습니다. 각 샘플은 텍스트 모달리티인 임상 노트와 비텍스트 모달리티인 흉부 X선 영상을 포함합니다.
또한 본 연구진은 비건강 음주 선별 작업에서도 MoMA를 검증했습니다. 알코올 오남용은 세계보건기구(WHO)에 의해 질병 부담에 기여하는 5대 위험 요인 중 하나로 인식되고 있으며, 비건강 음주에 대한 적시 선별은 알코올 관련 피해 위험을 완화하는 데 도움이 될 수 있습니다. 전향적 연구에서 두 개의 연구팀이 배치되어 2021년 9월부터 2024년 2월 사이에 동의를 얻은 2,096명의 환자를 선별하고 등록했습니다. 이들은 미국 국립 약물 남용 연구소(NIDA)에서 권장하는 TAPS(담배, 알코올, 처방약 및 기타 물질) 선별 도구를 사용하여 지난 3개월 동안의 비건강 음주 여부를 평가받았습니다.
이 작업은 환자가 지난 3개월 동안 비건강 음주를 했는지 여부를 이진 분류의 라벨로 사용합니다. 훈련된 코디네이터로 구성된 응급실(ED) 모집 팀이 참여 의사가 있는 환자를 대상으로 적격성을 심사했습니다. 입원 시 중독 의학 연구팀이 적격 환자에게 접근하여 서면 동의를 구하고 TAPS 선별 도구를 시행했으며, 참여를 마친 환자에게는 기프트 카드가 제공되었습니다. 수동 선별 결과는 설문 데이터베이스에 수집되었으며, 해당 환자의 EHR 관련 진료 사례와 연결되었습니다. 여기에는 텍스트 모달리티인 임상 노트와 표 형식의 실험실 검사 수치가 비텍스트 모달리티로 포함됩니다.
본 연구진은 테스트 세트가 개발 세트와 독립적임을 보장하기 위해 세 가지 작업 모두에 대해 시간적 검증(temporal validation)을 수행했습니다. 흉부 외상 및 다중 작업 층화의 경우, 개발 세트는 2015년 1월부터 2018년 12월까지의 데이터를, 테스트 세트는 2019년 1월부터 2019년 12월까지의 데이터를 사용했습니다. 비건강 음주 선별의 경우, 개발 세트는 2021년 9월부터 2023년 8월까지의 데이터를, 테스트 세트는 2023년 9월부터 2024년 1월까지의 데이터를 사용했습니다. 두 코호트의 특성은 표 1(Table 1)에 정리되어 있습니다.
Overall performance
비교 베이스라인 및 평가 지표
본 연구진은 흉부 외상 중증도 층화 작업과 다중 작업(흉부 및 척추) 외상 층화 작업을 위해, 기존에 발표된 베이스라인인 Gao 등의 방법론에 따라 자유 형식 텍스트로 미세 조정된 ClinicalBERT를 사용했습니다. 비건강 음주 선별 작업의 경우, 의학 개념(CUI; Concept Unique Identifier)으로 매핑된 임상 텍스트를 처리하는 Afshar 등의 1차원 합성곱 신경망(1D-CNN) 모델과 비교했습니다. 이러한 베이스라인들은 해당 세 가지 작업에 대한 최신(SOTA) 접근 방식을 나타냅니다.
또한, 의료 분야에서 널리 사용되는 대표적인 다중 모달 LLM 베이스라인인 LLaVA-Med와도 성능을 비교했습니다. LLaVA-Med는 표 형식(tabular)의 데이터를 지원하지 않으므로, 음주 선별 작업에서는 표 형식의 EHR 데이터를 일반 텍스트로 변환하여 미세 조정했습니다. 이 외에도 두 가지 벡터 기반 다중 모달 융합 방법인 교차 주의(Cross-attention) 모듈 방식과 전문가 혼합(MoE) 메커니즘 방식을 추가로 평가했습니다.
주요 실험 결과
외상 중증도 층화 작업
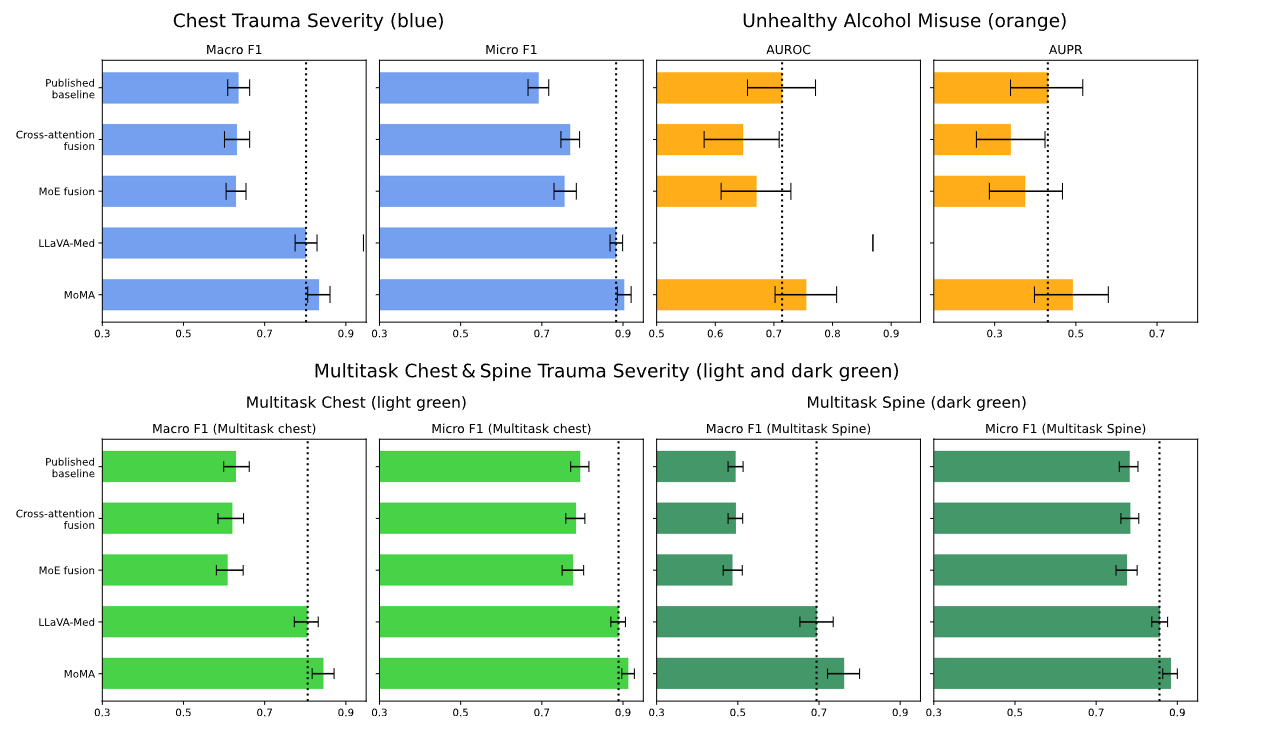
흉부 및 다중 작업 외상 층화 작업 모두에서 MoMA는 미세 조정된 LLaVA-Med를 포함한 모든 베이스라인보다 우수한 성능을 보였습니다. 특히 교차 주의 및 MoE 베이스라인보다 월등한 성능을 기록했습니다.
- 흉부 외상: 단일 작업 및 다중 작업 환경 모두에서 Macro-F1 0.85 근처, Micro-F1 0.90 이상의 점수를 달성했습니다.
- 척추 외상 (다중 작업): Macro-F1 0.75 이상, Micro-F1 0.90에 근접한 점수를 기록했습니다.
- 모달리티 포화: 연구진은 외상 작업에 세 번째 모달리티(검사 결과)를 추가해 보았으나, 이미 두 가지 모달리티만으로도 성능이 포화 상태에 이르러 추가적인 이득은 없음을 발견했습니다.
2. 비건강 음주 선별 작업
이 작업의 기존 베이스라인(1D-CNN)은 54,915건이라는 훨씬 큰 데이터 세트로 학습되었기 때문에 LLaVA-Med나 MoE 방식보다 우수한 성능을 보였습니다. 그러나 MoMA와 동일한 소규모 코호트로 1D-CNN을 재학습시킨 결과, 성능이 크게 저하되었습니다 (AUROC 0.641, AUPR 0.325).
- MoMA의 성과: 동일한 소규모 코호트 조건에서 MoMA는 AUROC 약 0.75, AUPR 약 0.50에 달하는 강력한 결과를 도출하며 베이스라인들을 능가했습니다.
결론적으로, MoMA는 대규모 데이터가 부족한 환경에서도 비텍스트 데이터를 자연어 공간으로 번역함으로써 기존의 벡터 기반 융합 방식보다 훨씬 유연하고 정확한 예측이 가능함을 입증했습니다.
상세 실험 결과
소집단 분석 (Subgroup analysis)
임상 예측 모델에서 소집단 분석은 다양한 환자 군 전반에 걸쳐 일관된 성능을 보장하는 데 필수적입니다. 인종 및 성별과 같은 하위 그룹별 모델 성능을 평가함으로써, 연구진은 특정 집단에 영향을 미칠 수 있는 성능 변동을 식별할 수 있습니다.
- 분석 결과: MoMA 아키텍처는 분석된 모든 하위 그룹에서 일관되게 가장 우수한 성능을 달성했습니다.
- 통계적 검증: 여성 대 남성, 비백인 대 백인 집단 간의 성능을 비교하기 위해 대응 표본 t-검정(paired t-tests)을 실시한 결과, MoMA는 하위 그룹 간에 일관된 성능을 보여주었습니다.
- 베이스라인과의 차이: 반면, 베이스라인 방법들은 흉부 외상 중증도 층화 및 다중 작업(흉부 및 척추) 외상 층화 작업에서 하위 그룹 간에 눈에 띄는 성능 차이를 나타냈습니다.
- 참고 사항: 비건강 음주 선별 코호트의 경우, 비백인 사례 수가 적어 변동성이 높았기 때문에 백인 대 비백인 그룹 간의 비교는 분석에서 제외되었습니다.
제거 연구 (Ablation study)
비텍스트 모달리티가 성능 향상에 기여하는 바를 검증하기 위해, MoMA의 다른 구성 요소는 유지한 채 비텍스트 입력만을 제거하는 연구를 수행했습니다. 구체적으로 흉부 외상 작업에서는 흉부 X선 영상을, 음주 선별 작업에서는 실험실 검사 수치를 제외했습니다.
- 결과: 다중 모달 입력을 사용하는 MoMA는 텍스트만 사용하는 모델보다 우수한 성능을 보였습니다.
- 결론: 이러한 결과는 MoMA의 향상된 성능이 단순히 LLM의 뛰어난 텍스트 이해 능력뿐만 아니라, 비텍스트 모달리티를 효과적으로 통합하고 활용하는 아키텍처의 능력 덕분임을 입증합니다.
사례 연구 (Case study)
사례 연구는 MoMA 아키텍처가 비텍스트 정보를 어떻게 효과적으로 통합하고 모든 가용 데이터를 하나의 요약본으로 합성하는지를 보여줍니다.
- 영상 정보 통합 사례: 흉부 X선 전용 에이전트가 영상 이미지를 분석하여 심각한 상태를 식별하거나 배제합니다. 한 사례에서 에이전트는 심각한 소견이 없음을 확인하여 부상을 '중등도(moderate)'로 정확하게 분류할 수 있게 했습니다. 반면, 텍스트 전용 접근 방식은 이 사례를 '심각(severe)'으로 잘못 분류했는데, 이는 중요한 방사선 정보를 활용하지 못하는 한계를 보여줍니다.
- 데이터 정제 및 해석력: 전용 에이전트와 통합 에이전트는 수천 단어에 달하는 방대한 임상 텍스트와 수십 개의 검사 수치를 핵심 정보는 유지하면서 무관한 세부 사항은 필터링한 간결한 요약본으로 증류해냅니다. 이를 통해 예측 에이전트가 정확한 분류를 할 수 있도록 돕는 동시에, MoMA의 의사 결정 과정에 대한 투명성과 해석 가능성을 높였습니다.
- 통합 메커니즘: 통합 에이전트는 임상 노트를 기본 정보원으로 사용하며, 영상 소견이 텍스트를 명확하게 하거나 보강할 때만(예: "통합 에이전트와 영상 전용 에이전트 모두 기흉 없음 보고") 선택적으로 반영합니다. 텍스트 정보가 이미 명확하고 결정적인 증거를 제공하는 경우 영상 증거의 비중은 낮게 조정됩니다.
고찰 (Discussion)
1. MoMA 아키텍처의 설계와 의의
본 연구에서는 다중 모달 의료 데이터를 활용한 임상 예측 작업을 위해 사전 학습된 대규모 언어 모델(LLM)의 위력을 활용하도록 설계된 유연한 아키텍처인 MoMA(Mixture-of-Multimodal-Agents)를 소개했습니다. MoMA는 최신 LLM이 특정 데이터 유형을 처리하는 전용 에이전트 역할을 수행할 수 있도록 하는 모듈식 '플러그 앤 플레이(plug-and-play)' 설계를 채택하고 있으며, 이는 작업 요구 사항에 따라 쉽게 교체하거나 확장할 수 있습니다.
본 아키텍처는 서로 다른 EHR 모달리티 조합(방사선 영상 + 임상 텍스트, 실험실 검사 수치 + 임상 텍스트)과 다양한 예측 유형(다중 클래스, 다중 작업, 이진 분류)을 포함하는 세 가지 임상 작업에서 검증되었습니다. 특히 모든 작업에 비공개 데이터 세트를 활용함으로써, 공개 데이터가 모델의 사전 학습 단계에 포함되었을 가능성으로 인한 데이터 누출(data leakage) 위험을 배제했습니다. MoMA는 이러한 작업 전반에서 베이스라인 모델보다 우수한 성능을 달성하며, 광범위한 임상 예측 작업을 처리하기 위한 매우 효과적이고 유연한 솔루션으로서의 잠재력을 입증했습니다.
2. 데이터 통합 및 정제 메커니즘
MoMA의 근본적인 원리는 임상 위험 예측이 다중 모달 EHR의 총체적인 합성으로부터 이득을 얻는다는 점에 있습니다.
- 정보의 보완과 노이즈 제거: 전용 에이전트는 원시 데이터(픽셀 등)에서 직접 작동하여 표현 능력을 극대화하는 대신, 원본 임상 노트와 협력적으로 융합될 수 있는 보완적이고 노이즈가 제거된(denoised) 텍스트 인상을 생성합니다.
- 정보 손실과 이득의 균형: 이러한 변환 과정에서 일부 정보 손실이 발생할 수 있으나, 실험 결과 노이즈 제거와 정보 보완을 통해 얻는 이득이 정보 손실로 인한 비용보다 크다는 것을 확인했습니다.
- 자문 역할의 통합: 통합 에이전트는 전용 에이전트의 출력을 자문(consultant) 역할로 활용하며, 전용 에이전트의 요약이 임상 노트를 명확히 할 때만 선택적으로 정보를 수집하고 요약본이 전체 내용을 지배하지 않도록 조절합니다.
3. 연구의 차별점 및 해석 가능성
현재 멀티 에이전트 아키텍처에 대한 연구는 주로 생성(generative) 작업에서의 텍스트 이해 능력 향상에 중점을 두어 왔습니다. 그러나 이러한 아키텍처가 다중 모달 EHR 데이터를 포함하는 분류 작업에서 예측 성능을 효과적으로 개선할 수 있는지에 대해서는 아직 입증된 바가 거의 없었습니다. 본 연구는 LLM의 텍스트 이해 능력을 활용하여 다양한 모달리티에 걸친 임상 분류 작업에서 뛰어난 성능을 달성함으로써 이러한 격차를 직접적으로 해결합니다.
또한, MoMA는 성능뿐만 아니라 투명성과 해석 가능성 측면에서도 효과적인 솔루션을 제공합니다. 전용 에이전트가 핵심 정보를 추출하고 통합 에이전트가 이를 간결하게 정제하는 순차적 접근 방식은 의사 결정 과정의 투명성을 높입니다. 예측의 근거를 이해하는 것이 정확도만큼이나 중요한 임상 환경에서 MoMA는 성능과 해석 가능성을 동시에 잡은 모델입니다.
4. 유연성 및 확장성
MoMA는 대규모의 쌍을 이루는 사전 학습 데이터(paired pretraining data)를 요구하는 일반적인 통합 방법론과 달리, 기존의 사전 학습된 모델을 활용하여 비텍스트 모달리티를 텍스트 공간으로 '투영(projecting)'할 수 있는 유연성을 제공합니다. 이러한 독립성 덕분에 사전 학습 시 특정 데이터 세트의 가용성에 구애받지 않고 다양한 임상 작업에 더 잘 일반화될 수 있습니다.
나아가 MoMA의 모듈식 설계는 향후 더 발전된 모델의 원활한 통합을 가능하게 합니다.
- 새로운 모달리티 확장: 방사선 영상이나 검사 수치 외에도, 적절한 전용 에이전트를 선택함으로써 다양한 비텍스트 모달리티를 쉽게 통합할 수 있습니다.
- 에이전트 예시: 예를 들어 3D CT 스캔을 위한 BrainGPT, 병리 영상을 위한 HistoGPT, 단일 세포 시퀀싱 데이터를 위한 scChat 등을 MoMA 워크플로우에 쉽게 포함할 수 있습니다.
5. 실험 결과의 함의
실험 과정에서 연구진은 외상 중증도 층화 작업에 세 번째 모달리티인 실험실 검사 수치를 추가하는 것이 성능을 더 이상 향상시키지 않는다는 점을 발견했습니다. 이는 부상 정도(AIS 점수)가 주로 임상 노트와 영상에 기록된 해부학적 부상에 의해 결정되는 반면, 일상적인 실험실 수치(전해질 등)는 이와 약하게 연결되어 있기 때문입니다. 반대로 비건강 음주 선별 작업에서는 혈중 알코올 농도와 같은 실험실 수치가 직접적으로 관련이 있어 성능 개선에 기여했습니다.
이러한 결과는 MoMA가 작업별 정렬을 반영하고 있음을 보여줍니다. 즉, 프레임워크가 임상 결과에 유익한 모달리티를 활용하고 관련성이 낮은 신호의 비중은 낮추는 능력을 갖추고 있음을 의미합니다.
6. 학습 효율성 및 환각(Hallucination) 관리
MoMA의 또 다른 핵심 장점은 비텍스트 모달리티 번역을 위해 별도의 학습 과정이 필요하지 않다는 것입니다. 오직 예측 에이전트만 미세 조정(fine-tuning)하면 되므로, 대규모 다중 모달 모델 학습에 수반되는 컴퓨팅 부담과 데이터 요구 사항을 크게 줄여줍니다.
또한, LLM의 고질적인 문제인 '환각' 이슈를 해결하기 위해 MoMA는 생성된 요약본을 인간의 해석에만 의존하게 두지 않습니다. 대신 이 요약본을 하위 예측을 위한 중간 표현으로 사용하며, 실제 임상 라벨(Ground truth)을 사용하여 예측 에이전트를 미세 조정함으로써 모델 예측과 실제 결과 사이의 정렬을 유도하고 환각의 부정적 영향을 완화합니다.
7. 한계점 및 결론
몇 가지 한계점은 향후 탐구가 필요합니다:
- 에이전트 간 상호작용: 현재 에이전트 간 소통 방식은 단순하며, 이를 더 고도화하면 모델의 능력을 향상시킬 수 있습니다.
- 추론 비용: 다중 모달 재학습 비용은 줄였으나, 추론 시 여러 에이전트를 실행해야 하므로 컴퓨팅 비용이 발생합니다.
- 범위 확장: 본 연구는 임상 분류에 집중했으나, 향후 의료 시각 질의응답(Medical VQA) 등으로 확장하기 위한 검증이 필요합니다.
요약하자면, MoMA는 다중 모달 의료 데이터를 임상 예측 작업에 활용하는 데 있어 비약적인 발전을 나타냅니다. 실제 응용 환경에서 기존 모델을 압도하는 성능을 보여주는 동시에, 해석 가능성과 입력 형식에 대한 유연성을 제공하여 임상 의사 결정을 개선할 수 있는 매우 유망한 도구임을 입증했습니다.
