- 논문 제목: MOSCARD - Multimodal Opportunistic Screening for Cardiovascular Adverse events with Causal Reasoning and De-confounding
- 링크: https://papers.miccai.org/miccai-2025/0582-Paper3125.html
- 저널: MICCAI 2025
0. Background
데이터 편향 (Data Bias)
- 선택 편향 (Selection Bias): 연구 대상자를 선정하거나 제외하는 기준이 결과에 영향을 미쳐, 비교하려는 집단 간의 특성이 이미 차이가 나버리는 상태
- 예시: 병원에 입원한 환자들만을 대상으로 '고혈압'과 '당뇨'의 상관관계를 조사한다면, 일반인보다 고혈압과 당뇨를 동시에 가지고 있을 확률이 훨씬 높아, 두 질환의 상관관계가 실제보다 높게 측정되는 문제가 발생함.
- 샘플링 편향 (Sampling Bias): 모집단(전체 대상) 중에서 표본을 추출할 때, 특정 성향을 가진 표본이 다른 표본보다 더 많이 혹은 더 적게 뽑히는 것
- 예시: 특정 검사 기록이 있는 환자만 추출한다면, 해당 검사가 필요할 정도로 증상이 있었던 환자들로만 표본이 한정되는 문제가 발생함.
- 발생하는 문제점: Shortcut Learning
- 딥러닝 모델이 데이터에 내재된 본질적인 특징을 배우는 대신, 정답을 맞히기 위해 쉽고 단순한 가짜 상관관계(Spurious Correlation)'를 학습하는 현상임.
- 모델 입장에서는 복잡한 패턴을 분석하는 것보다, 데이터에 섞여 들어온 단순한 부가 정보를 활용하는 것이 손실 함수를 줄이는 효율적인 지름길이기 때문에 발생함.
- 예시: 기흉 환자의 CXR 데이터에는 치료를 위해 흉관을 삽입한 사진이 많을 수 있으므로, 모델은 폐의 상태를 보는 게 아니라 "흉관이 보이면 기흉이다"라고 학습하게 됨.
- 모델링 관점에서의 해결 방법: 적대적 탈편향(Adversarial debiasing)
- 모델이 예측을 수행할 때, 원치 않는 편향된 정보(보호 변수, 예: 인종, 성별 등)를 사용하지 못하도록 강제하는 학습 기법으로 GAN 구조를 차용하여 두 개의 네트워크가 서로 경쟁하며 학습
- 예측기 (Predictor): 데이터를 입력 받아, 원래 목표 label을 예측
- 예측기의 목표:
Task 1: 원래 정답을 잘 맞힌다.
Task 2: 적대자가 보호 변수를 맞히지 못하도록 방해한다.
- 예측기의 목표:
- 적대자 (Adversary): 예측기의 출력 값으로 성별, 인종 등과 같은 보호 변수를 역으로 추론
- 적대자의 목표: 예측기의 출력에서 보호 변수를 최대한 잘 맞히는 것입니다. 즉, 편향의 흔적을 찾아내는 '탐정' 역할을 합니다.
- 적대자가 잘 맞히는 방향의 반대 방향으로 예측기를 업데이트하여, 예측기는 "보호 변수와 상관관계가 없는 독립적인 특징(Bias-invariant features)"만을 학습함
- 한계: 단일 교란 요인(confounder)만을 대상으로 하기 때문에 그 복잡성으로 인해 효과가 제한적이며, 연령 및 동반 질환과 같은 상호 의존적인 요인들을 모델링하는 데 실패함!
교란 요인 (Confounder)
입력 데이터()와 예측 목표() 모두에 영향을 주어, 둘 사이의 진정한 인과관계를 왜곡하거나 가짜 상관관계를 만들어내는 제3의 변수()
- 예시: 나이()가 많을수록 심장 상태()가 나쁠 확률이 높으면서, 실제로 심혈관 사건()이 발생할 확률도 높음.
- 왜 문제인가? 상관관계(Correlation)이지 인과관계(Causality)가 아님
- 모델은 CXR 데이터()에서 심장 비대나 폐 부종 같은 생물학적 징후를 찾아야 함. 하지만 나이()라는 교란 요인이 끼어들면, 모델은 CXR에 있는 노화의 흔적만 보고 결과를 예측함.
1. Introduction
목적
기회적 선별검사(Opportunistic screening)를 통해 주요 심혈관 사건(MACE) 위험이 있는 환자 예측
- 기회적 선별검사(Opportunistic screening): 환자가 다른 건강상의 이유로 병원을 방문했을 때, 의료진이 기회를 포착하여 환자가 인지하지 못했거나 요청하지 않은 추가적인 질병 선별 검사를 시행하는 것 (본 연구: 건강 검진 목적의 CXR과 ECG 검사)
- 주요 심혈관 사건(Major Adverse Cardiovascular Events, MACE): 심혈관계 질환 관련 임상 연구에서 약물의 효과나 수술의 안전성을 평가할 때 사용하는 평가지표(Composite Endpoint)
- 3-point MACE
- 심혈관 사망: 심부전, 부정맥, 심근경색 등 심혈관 질환이 직접적인 원인이 되어 사망한 경우
- 비치명적 심근경색: 심장 근육의 괴사가 일어났으나 사망에 이르지는 않은 경우
- 비치명적 뇌졸중: 뇌혈관 문제로 뇌 손상이 발생했으나 사망에 이르지는 않은 경우
기존 연구의 한계
- 멀티 모달리티의 한계
- 이질적인 고차원 데이터를 결합하는 것은 데이터의 복잡성, 노이즈, 의미론적 상호운용성, 편향 및 윤리적 딜레마로 인해 헬스케어 AI 분야에서 해결 해야 할 과제임.
- MedClip과 같은 시각-언어 모델은 모달리티의 제약(주로 텍스트와 이미지)과 내재된 편향으로 인해 의료 영역에서 여전히 제한적임.
- 선택적 코호트의 일반화 성능 감소: 선택적 샘플링에 기반한 인구 집단 편향으로 인해 다양한 인구 집단에서 성능 저하를 보이는 경우가 많음. 이러한 편향은 훈련 데이터에 충분한 다양성이 부족할 때 발생하며, 이는 지름길 학습(shortcut learning)과 소수 집단(underrepresented groups) 간의 지속적인 부정확성을 초래함.
개선 방안
- 멀티 모달리티 통합: 동일한 방문 시 획득한 CXR과 12-Lead ECG를 통합하는 것은 환자의 심장 건강에 대한 보다 포괄적인 관점을 나타낼 수 있음. 기회적 선별검사의 경우, 이러한 조합이 심장 초음파, CT, MRI와 같은 더 정교한 영상 장비에 비해 자원 효율적임.
- Chest X-Ray(CXR): 심장 질환에 기여하는 만성 질환의 징후를 감지하는 데 유용함.
- 12-Lead ECG: 심장의 전기적 활동을 직접 평가하여 부정맥, 허혈성 변화 및 구조적 이상을 감지함.
- 데이터셋의 편향 및 교란 요인 제거
- 혼동 손실(confusion loss)을 통해 CXR 및 ECG 데이터 특징화에서 교란 요인 효과(선택 편향)를 제거.
- 동반 질환과 목표 MACE 위험 사이의 인과 관계(예: 비만 → 인슐린 저항성 → 이상지질혈증 → 동맥경화증 → 심혈관 질환 위험)를 모델링하기 위해 인과 추론을 적용.
2. Methods
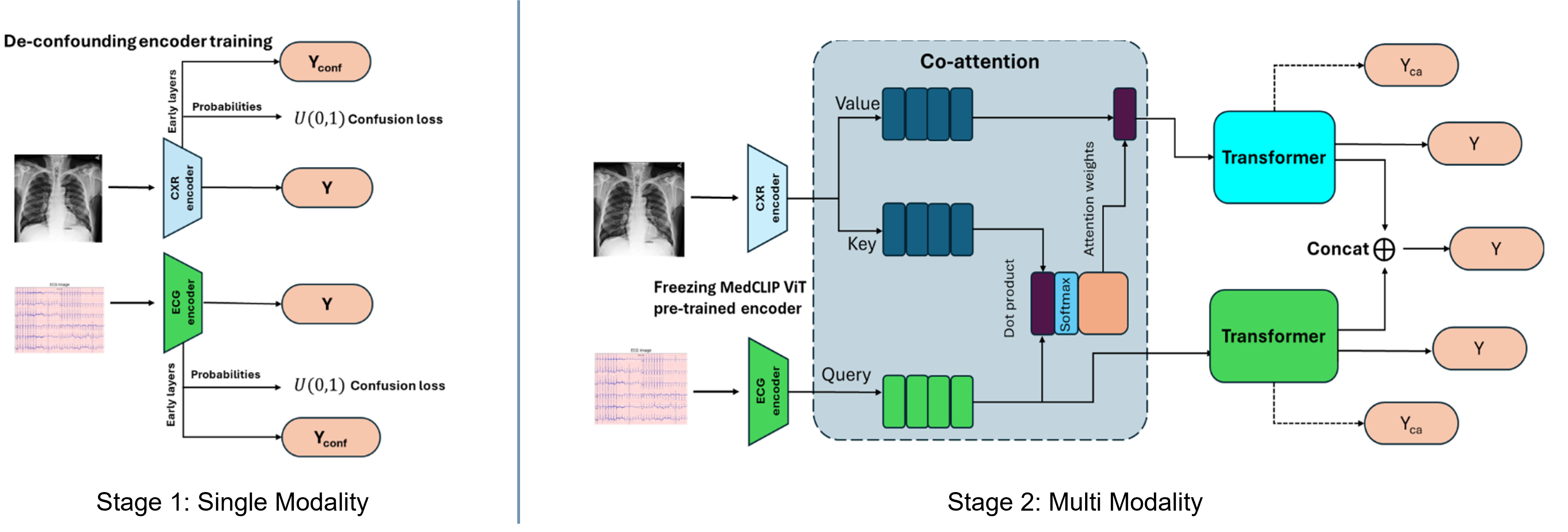
- 제안하는 방법론: 2-stage 멀티모달 프레임워크 MOSCARD를 제안함.
- 1단계(그림 a): 교란 요인(confounder) 효과를 제거하기 위해 혼동 손실(confusion loss)을 사용하여 단일 모달리티 인코더를 훈련함
- 2단계(그림 b): Co-attention을 활용한 멀티모달 학습을 적용함.
- 2단계에서 인과 관계를 모델링하기 위해, 이미지(), 대상 레이블(), 인과 인자(), 그리고 교란 요인()을 나타내는 구조적 인과 모델(SCM)과 그 매개변수화인 유향 비순환 그래프(DAG)를 적용했습니다.
- 멀티모달 모델은 세 가지 예측 브랜치로 구성됨.
- 메인 브랜치: MACE() 예측 용도
- 각 모달리티의 판별 브랜치: ViT 인코더의 초기 레이어 피처를 사용하여 인과 인자()와 교란 요인 레이블()을 예측합니다.
Stage 1: Single Modality Encoder
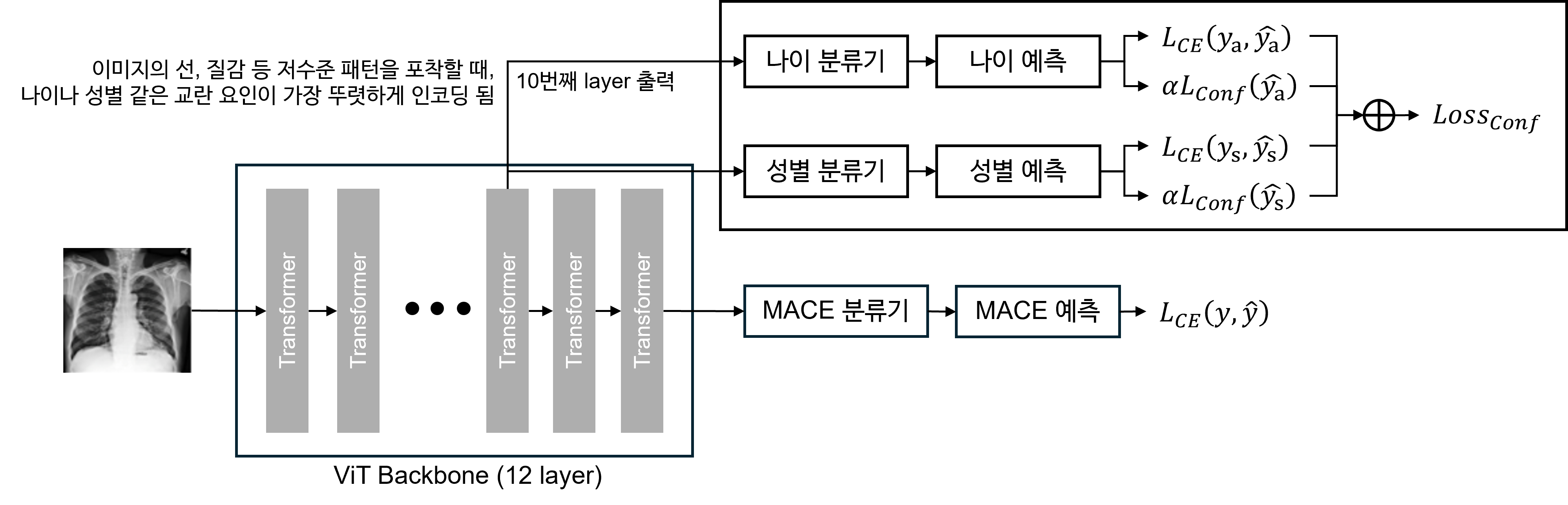
- CXR 및 ECG 영상( 및 )을 처리하기 위한 별개의 12개 레이어 ViT 인코더를 통해 탈교란(de-confounding)을 설계함.
- 인과 관계 는 우리가 원하는 효과를 나타내지만, 백도어 경로(backdoor path) 는 가짜 상관관계(spurious correlations)를 도입하고 예측에 영향을 미치는 교란 요인 의 영향을 강조합니다 (그림 a). 이러한 편향을 완화하기 위해, 우리는 두 개의 별도 역전파(backpropagation) 그래프를 사용하여 잘못된 연결인 및 를 제거함으로써 각 인코더에서 교란 영향을 개별적으로 제거합니다.
- 손실 함수 1: 메인 MACE 예측 작업에 집중
- 손실 함수 2: 성별 및 연령 예측을 처리하는 교란 요인 작업에 할당되며, 교차 엔트로피를 사용
-
교란 요인의 영향을 더욱 완화하기 위해, 교란 요인 예측이 균등 분포(uniform distribution)에 근사하도록 유도하는 혼동 손실(confusion loss) 를 통합합니다. 교란 요인을 효과적으로 완화하기 위해, 우리는 주로 저수준(low-level) 패턴을 포착하고 성별 및 연령과 같은 요인과 관련된 강한 교란 신호를 자연스럽게 인코딩하는 ViT의 초기 레이어 피처를 활용합니다.
-
Stage 2: Multimodal Co-attention alignment
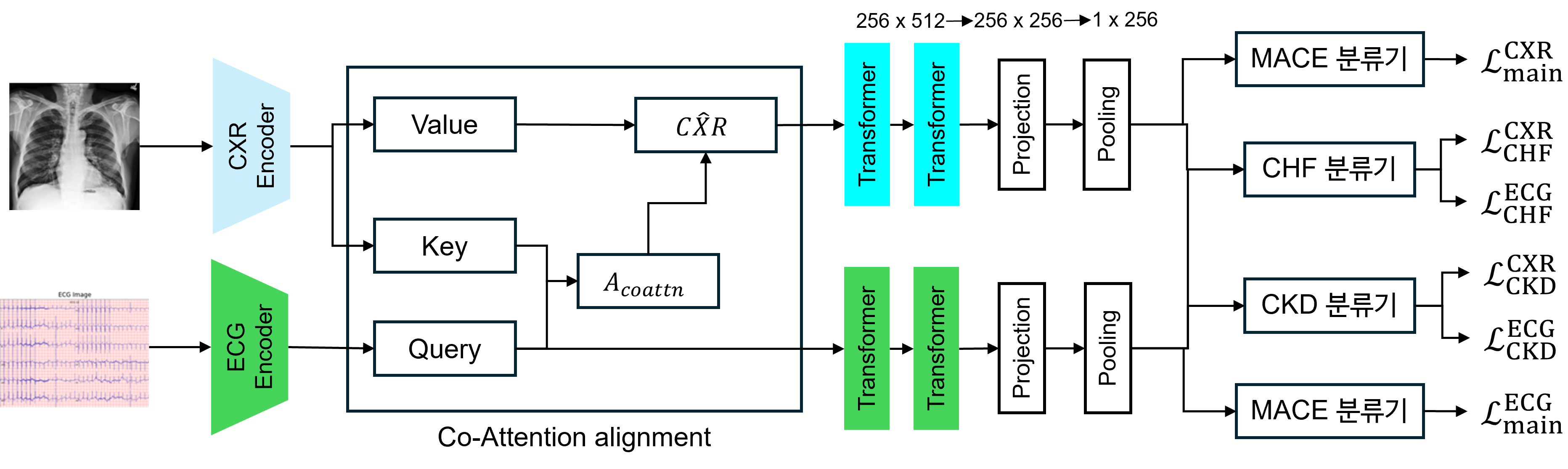
- stage 1에서 얻은 사전 훈련된 인코더 가중치를 고정(freeze)하여 활용함.
Co-Attention
- CXR의 주요 정보를 보존하고, ECG를 가이드 모달리티(guiding modality)로 사용하기 위함.
-
Key & Value: CXR 피처()
-
Query: ECG 피처()
-
- Attention score: 투영된 쿼리()와 키() 사이의 유사도를 계산하여 얻어지며, 수치적 안정성을 위해 로 스케일링됩니다. 소프트맥스 연산이 적용되어 Co-attnetion 행렬()이 생성되며, 이는 CXR의 서로 다른 영역에 중요도 가중치를 할당합니다. 이 어텐션 가중치들은 CXR 특징의 가중 합을 계산하는 데 사용되어, 이를 다음과 같이 정제된 로 변환합니다.
- 학습되는 가중치:
- Value: (CXR 특징으로부터 유도됨)
- 이를 통해 모델이 ECG 특징을 Condition으로 활용하여 가장 정보가 많은 영역에 선택적으로 집중할 수 있게 함.
Classification
- Co-Attention 메커니즘 이후, CXR과 ECG 특징은 두 개의 트랜스포머와 다층 퍼셉트론(MLP) 브랜치를 거쳐 분류 작업을 수행함.
- 모델은 다섯 개의 브랜치로 구성되어 두 가지 작업을 수행함.
- 인과 작업(causal task): 분류 레이블 를 예측
- 메인 작업(main task): 분류 레이블 를 예측
- 그림 b에 표시된 바와 같이, 의 관계는 인과 인자 가 와 모두에 영향을 미침
Loss function
- 목적: 모델이 의 정보를 활용하여 MACE 예측에 대한 일반화 성능을 향상시키는 것
- Causal learning: 모달리티별 고유의 정보와 향상된 분류 성능을 위한 결합된 표현의 이질성을 보존하기 위해, 인과 학습(Causal learning)은 CXR과 ECG 특징 각각에 별도로 적용됩니다.
- 다섯 개 브랜치 분류 작업의 전체 손실 함수
- CXR에 대한 인과 및 메인 손실: &
- ECG에 대한 인과 및 메인 손실: &
- 결합된(concat) ECG와 CXR에 대한 통합 손실:
3. Results
Dataset
Internal cohort
- 미국 내 서로 다른 4개 기관에서 21,872명의 환자에 대한 후향적 데이터 수집
- Inclusion
- CXR을 수행하고 6개월 이내에 일치하는 12-Lead ECG 검사를 받은 환자
- Exclusion
- 6개월 이내에 추적 관찰이 중단된 환자 제외
- 최종 환자 수: 12,612명
- Train/Valid 분할: 8:2 랜덤 샘플링 (Train: 79,648개, Valid: 21,108개의 ECG-CXR 쌍)
- MACE 결과는 수동 차트 리뷰를 통해 편집
- 고위험 심장 질환 환자들로 구성되어 있으며, 6개월 및 1년 이내 MACE 발생률은 각각 51.77%와 55.91%로 높게 나타남.
Shift cohort - Emergency Department (ED)
- 시프트 데이터에 대한 모델의 일반화 능력을 평가하기 위해, 응급실에서 CXR을 수행한 환자들로부터 테스트 데이터를 수집함.
- 환자 수 : 2,638명
- 데이터 건수: ECG-CXR 쌍 2,830개
- Internal cohort와 비교
- 더 젊은 환자: 80세 이상 8.34%
- 낮은 동반 질환의 유병률: 울혈성 심부전(CHF 0%), 만성 신장 질환(CKD 0%), 당뇨병(0.94%), 고혈압(2%)
- 낮은 1년 이내 MACE 발생률: 25.12%
Shift cohort - MIMIC
- 벤치마킹 목적으로 MIMIC-IV eICU 데이터에서 모델을 평가함.
- 입원 중 CXR 촬영을 받은 환자 200명을 무작위로 선택하고, 그중 시간적으로 일치하는 ECG 기록이 있는 175명의 환자를 식별함.
- 임상 기록과 입원 환자 사망률 데이터를 파싱하여 6개월 MACE 결과를 큐레이션했으며, MACE 발생률은 25.71% 였음.
Performance
- 우리는 단일 모달리티 및 베이스라인 멀티모달 모델을 우리가 제안한 교란 요인 탈편향(Conf), 인과+교란 요인(With Confounder), 그리고 인과 전용(Without Confounder) 모델과 비교했습니다. 베이스라인 단일 모달리티 인코더는 MedCLIP에서 파생되었으며, CXR 및 ECG 데이터에 대해 각각 별도로 미세 조정(fine-tuning)되었습니다. 제안된 멀티모달 정렬 프레임워크인 MOSCARD를 MedCLIP(대조 학습) 및 ALBEF(지식 증류) 베이스라인과 비교했습니다. 단일 및 멀티모달 모델에 대한 평가 결과는 표 1과 2에 요약되어 있습니다.
Single Modality
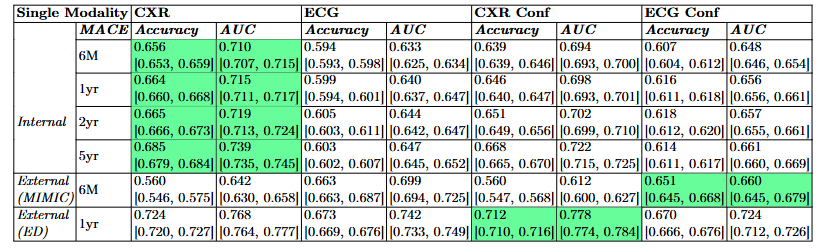
- Internal 테스트셋에서 베이스라인 CXR은 특히 5년 시점의 MACE 예측에서 0.739의 AUC로 가장 좋은 성능을 보임.
- 탈교란(de-confounding) 브랜치를 통합하는 것이 Internal 테스트셋에서 성능을 향상시키지는 않았으며, 이는 탈교란이 홀드아웃(hold-out) 테스트에서의 예측 성능을 강화하지 않음을 나타냄. (CXR Conf 5년 AUC 0.722).
- 탈교란 모델은 외부 데이터셋(ED: 0.778 CXR Conf, MIMIC: 0.66 AUC ECG Conf)에서 최적의 일반화 능력을 보여주었으며, 이는 탈교란이 없는 베이스라인 모델들이 일반화되지 않는 예측용 '지름길 특징(shortcut features)'에 의존할 수 있음을 입증함.
Multi Modality
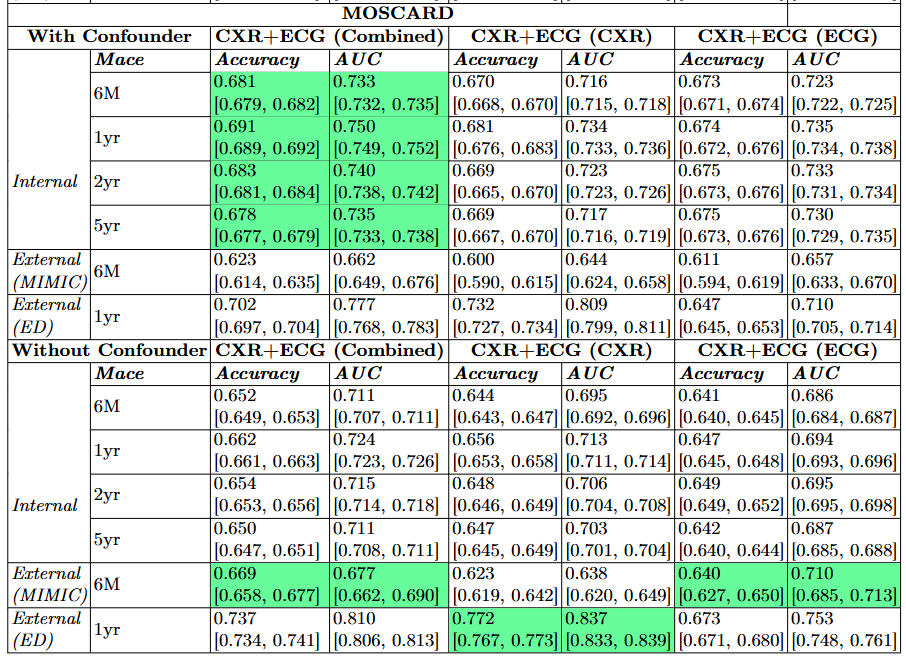
- 각 멀티모달 모델은 세 가지 유형의 예측을 수행함
- 정렬 후 CXR 및 ECG 특징을 결합(concat)하여 유도된 '결합(combined)' 예측
- 정렬된 공간의 특징을 사용한 'CXR' 단독 예측
- 정렬된 공간의 특징을 사용한 'ECG' 단독 예측.
- 멀티모달 모델의 경우, 인과성을 적용한 MOSCARD 모델이 내부 및 외부 데이터셋 모두에서 최고의 성능을 달성했으며 MedCLIP(MIMIC CXR AUC 0.550, ED CXR AUC 0.528) 및 ALBEF(MIMIC ECG AUC 0.604, ED ECG AUC 0.732) 베이스라인을 능가함.
- 내부 데이터셋에서의 최고 성능은 MOSCARD의 '결합' 예측에서 관찰되었으며, 특히 1년 시점의 MACE 예측에서 0.750의 AUC를 기록함.
- MOSCARD를 사용했을 때 ECG 특징만을 기반으로 한 예측이 단일 모달리티 ECG 모델의 성능을 일관되게 능가한다는 점을 발견했으며, 이는 단방향 어텐션을 사용하더라도 ECG 기반 예측을 개선하는 데 있어 멀티모달 통합이 갖는 이점을 보여줌.
- 인과성을 적용한 MOSCARD(CXR 브랜치)는 외부 응급실(ED) 데이터셋에서 최고의 성능(AUC = 0.837)을 달성한 반면, MOSCARD(ECG 브랜치)는 6개월 시점의 MACE 예측에서 MIMIC 데이터셋에 대해 최고의 성능(AUC = 0.71)을 보임. 이러한 발견은 데이터셋 고유의 특성이 모달리티의 효과성에 어떻게 영향을 미치는지 강조함. 하지만 내부 데이터셋과 마찬가지로, 멀티모달 학습은 외부 ED 및 MIMIC 데이터셋 모두에서 성능을 향상시킴. 이러한 결과는 내부 데이터셋의 경우, 교란 요인(confounder) 모델을 포함한 MOSCARD가 단일 모달리티 대비 최고의 성능을 달성함을 나타냄.
- 외부 데이터셋의 경우 MOSCARD가 다른 모델들보다 우수한 성능을 보였는데, 이는 질병 유병률 및 인구통계학적 분포의 차이로 인해 탈교란(de-confounding) 및 인과 학습이 외부 데이터셋에 특히 유익하다는 것을 시사함.
Subgroups
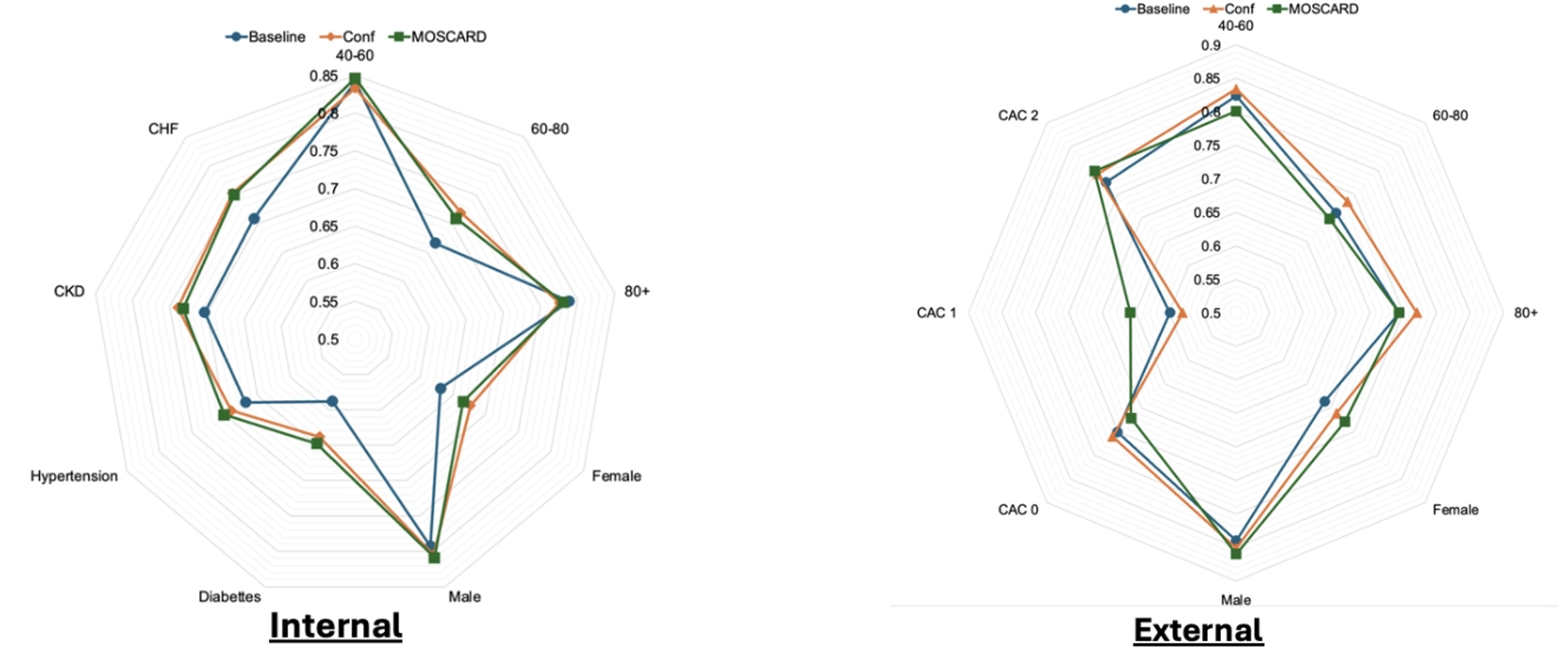
- MOSCARD가 내부 및 외부 ED 데이터 모두에 대해 동반 질환 및 인구통계학적 특성을 포함한 모든 하위 그룹에서 최적의 균등화된 성능을 달성했음을 보여줌. 탈교란된 인코더는 베이스라인 대비 하위 그룹 성능을 향상시켰으며, 홀드아웃(hold-out) 세트에서는 유사한 성능을 달성했으나 외부 ED 테스트에서의 성능 하락을 개선함.
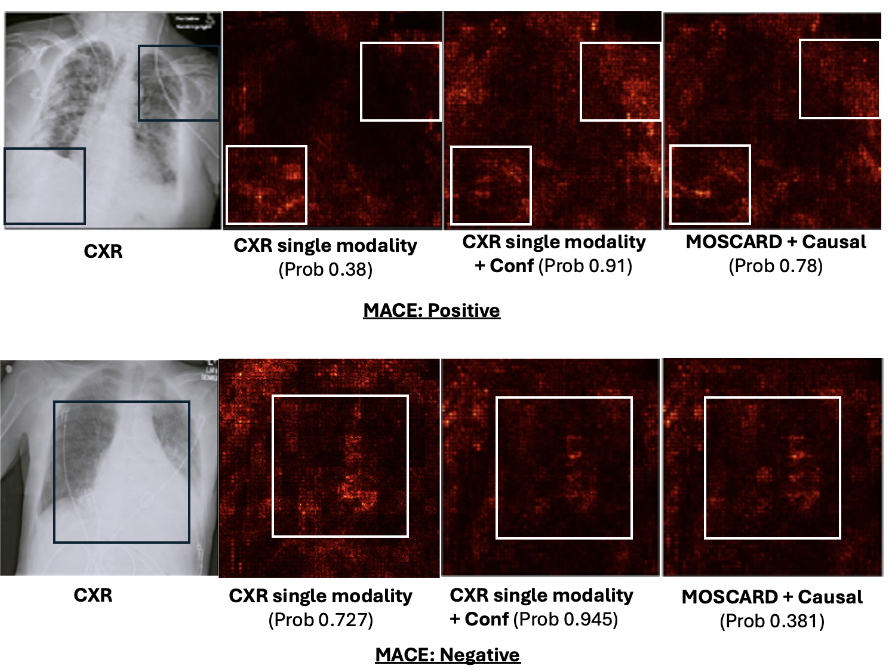
- 2단계 학습의 맥락에서, 우리는 MOSCARD의 추론이 단일 모달리티 인코딩과 어떻게 다른지 탐구하기 위해 몇 가지 흥미로운 사례에 대해 픽셀 마스킹을 활용한 살리언시 맵(saliency map) 해석을 적용함.
- 두 사례 모두에서 단일 모달리티 모델은 예측을 수행할 때 주로 외부 전선이나 보조 장치에 의존했습니다. 탈교란 후에도 초점은 이동했으나, 모델의 예측은 여전히 틀리거나 과도하게 확신하는 상태을 보임. 반면, ECG 가이드를 받은 MOSCARD는 외부 전선이나 보조 장치에 방해 받지 않고 심장과 폐 영역에 집중함으로써 두 사례 모두에서 성공적으로 올바른 예측을 내렸음.
4. Discussion
- MOSCARD가 전통적인 단일 모달리티 및 기존의 멀티모달 모델과 비교하여, 환자군 변화(고위험군에서 저위험군으로의 변화)에 대해 더 정확하고 공정한 예측을 제공하는 데 효과적임을 보여줌.
- 탈교란(De-confounding)은 외부 데이터셋에서의 일반화 성능을 향상시키는 데 강력한 힘을 발휘했음.
- CXR Conf 모델: 응급실(ED) 데이터셋에서 0.778의 AUC 달성
- ECG Conf 모델은 MIMIC 데이터셋에서 0.66의 AUC 달성
- 인과 추론을 적용한 MOSCARD: 외부 데이터셋에서 최고의 성능을 기록
- 인과 버전(causal version) 모델: ED 데이터셋에서 1yr MACE에 대해 0.837의 AUC 달성
- MIMIC 데이터셋: MOSCARD의 ECG 브랜치 성능이 더 우수(AUC = 0.71)
- MOSCARD는 내부 및 외부 ED 데이터셋 모두에서 동반 질환 및 인구통계학적 특성에 기반한 모든 하위 그룹에 걸쳐 최적의 성능을 달성
- 일반화 가능한 멀티모달 예후 프레임워크: 심혈관 평가를 위해 구체적으로 내원한 환자들에게만 의존하기보다, MACE 위험이 있는 개인을 조기에 식별 가능함. 또한 이전에 본 적 없는 다양한 인구 집단에 대해 견고하게 작동함.
- 인구통계학적 편향 완화: 멀티모달 데이터에서 교란 요인과 기저의 인과 구조의 역할을 간과하는 경우가 많은 기존의 대다수 문헌과 달리, 동반 질환을 통합하고 혼동 손실(confusion loss)을 사용하여 인구통계학적 편향을 완화함으로써 인과 추론을 명시적으로 통합함
- 탈편향(debiasing) 전략: 이질적인 코호트에서 모델의 일반화 가능성과 효과성을 강화함.
- ED 데이터셋: 동반 질환이 적고 MACE 발생률이 낮은 비교적 건강한 환자들을 포함
- MIMIC-IV: 추가적인 동반 질환을 가진 더 복잡한 중환자실(ICU) 환자군
- CXR 브랜치: 초기 동맥경화나 폐 울혈과 같은 초기 단계의 심혈관 이상 징후를 식별함으로써 ED 데이터셋에서 가장 좋은 성능
- ECG 브랜치: 전기적 활동 평가를 기반으로 질병이 진행된 단계일 가능성이 높은 MIMIC-IV 환자들에 대해 더 우수한 성능
- MOSCARD 내에서의 CXR과 ECG co-alignment는 두 모달리티 모두에서 학습하고 인구 집단 간의 차이를 조정할 수 있어, 모델이 단일 모달리티의 성능을 크게 앞지르는 데 기여함

MedicalAI Researcher