1
- 대부분의 Mysql 인덱스 (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT)는 B-tree안에 저장된다.
- 예외적으로 spatial 데이터 타입은 R-tree를 사용
- 메모리 테이블은 또한 hash index를 지원
- InnoDB는 FULLTEXT 인덱스를 위해 inverted list를 사용한다.
2 B-tree
-
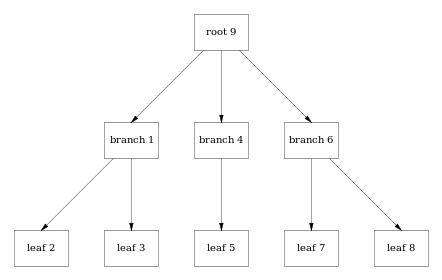
맨 위가 루트노드, 그 다음 중간이 브랜치 노드, 맨 밑이 리프노드 입니다.
-
리프노드는 실제 DB의 레코드에 대한 주소를 가지고 있습니다.
-
B-Tree의 B는 Balanced(균형잡힌)이라는 뜻으로 B-Tree는 균형트리라는 뜻을 갖고 있습니다. 균형트리라는 것은 루트로 부터 리프까지의 거리가 균형을 맞추고 있다는 것을 뜻합니다.
-
B-Tree는 루트노드에서 리프노드로 한 단계씩 내려갈 때마다 브런치 노드가 늘어나는 수는 제곱으로 늘어나게 됩니다.
- 그래서 아무리 데이터 수가 많아지더라도 실제로 데이터를 찾기위해 타고가는 횟수는 생각보다 늘어나지 않습니다. -
결과적으로 B-Tree를 사용하게 되면 디스크 입출력에 걸리는 시간이 데이터의 수와 큰 상관 없이 균일한 성능을 보장합니다.
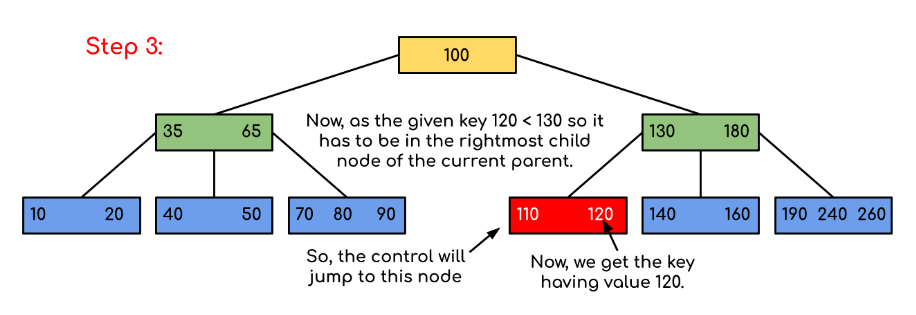
- 그림으로 보면 120에 해당하는 키값을 조회하고 싶을때 최상위 루트노드인 100부터 조회 할 부분의 크기를 해당 노드의 순서와 비교하며 범위를 줄여나가서 실제 DB의 레코드에 대한 주소를 찾습니다.
- 나누어진 인덱스는 130과 180사이 그리고 35와 65 사이 두개입니다 .
- 100을 35와 65, 130과 180 사이를 비교하며 , 130과 180 사이를 선택했다면 그 밑에 3개를 비교합니다.
- 그렇게 노드를 타고 내려가면 120이라는 키를 찾을수 있습니다.
- 시간복잡도는 O(logN)입니다.
- 범위 검색을 위해서 주로 사용됩니다.
3. 인덱스 사용 예시
성능비교에 사용되는 쿼리는 아래와 같습니다 .
- 참고 : 쿼리 실행 정보는 노드가 반복하는 것을 나타내는 TREE 출력 형식을 사용하여 표시됩니다. EXPLAIN ANALYZE는 항상 TREE 출력 형식을 사용합니다.
- MySQL 8.0.21 이상에서는 FORMAT=TREE를 사용하여 선택적으로 명시적으로 지정할 수 있습니다. TREE 이외의 형식은 계속 지원되지 않습니다.
1. EXPLAIN : EXPLAIN은 MySQL 서버가 어떠한 쿼리를 실행할 것인가, 즉 실행 계획이 무엇인지 알고 싶을 때 사용합니다.
explain은 MySQL 8.0.19 이상부터 지원하며,
optimizer로 부터 query 수행 계획을 가져와 보여줍니다.
- 사용 예시
EXPLAIN
SELECT *
FROM table t
WHERE 1=1
AND virtual_card_yn = 'N'
AND card_seq > 0 - explain format = json 으로 주면 더 많은 정보를 알려줍니다.
- MySQL Workbench를 사용하면 Visual Explain를 활용할 수 있습니다.
- 가장 직관적으로 Explain을 확인할 수 있습니다.2. EXPLAIN ANALYZE : 아래를 알려줍니다.
1. 예상 실행 비용 (일부 반복자는 비용 모델에서 설명되지 않으므로 추정치에 포함되지 않습니다.)
2. 반환된 행의 예상 수
3. 첫 번째 행을 반환하는 시간 모든 행을 반환하는 데 걸리는 시간(실제 비용)
4. (여러 개의 루프가 있는 경우 이 그림은 루프당 평균 시간을 나타냅니다.) iterator가 반환한 행 수 루프 수query 수행 예상 비용
결과 row의 예상 개수
결과의 첫번째 row가 반환되는 시간(milliseconds)
모든 결과가 반환되는 시간(milliseconds)
iterator가 반환하는 row의 개수
loop가 수행되는 횟수
3. 사용예시
- 특정 테이블의 인덱스 확인
SHOW index FROM table_name- 인덱스 추가 쿼리
ALTER TABLE tablename ADD INDEX indexname (column1, column2); ADD INDEX idx_age (col1);
인덱스의 설정방법
인덱스 설정시에는 따로 따로 인덱스를 선언해줘야 제대로 설정이 가능하다.
// X -> INDEX(id, age)
// O -> INDEX(id), INDEX(age)
- 인덱스 사용
SELECT * FROM table1 USE INDEX (col1_index,col2_index)
WHERE col1=1 AND col2=2 AND col3=3;
SELECT * FROM table1 IGNORE INDEX (col3_index)
WHERE col1=1 AND col2=2 AND col3=3;실습
- code =
SHOW INDEX FROM cust_card_apply_hist
- 하나만 가져와서 보면
`Table` : cust_card_apply_hist
`Key_name` : idx_cust_card_apply_hist_01
`Seq_in_index` : 3
`Column_name` : APPLY_TYPE_CD
`Index_type` : BTREE
`Cardinality` : 53588 -
EXPLAIN ANALYZE 사용해서 비교하기
- 2-1. use index **사용안하고** :-> Filter: (ccah.PLATFORM_CD = 'A') (cost=6229.55 rows=6109) (actual time=0.100..50.178 rows=34828 loops=1)
-> Table scan on ccah (cost=6229.55 rows=61093) (actual time=0.097..42.047 rows=104972 loops=1)-
2-2. use index 사용하고 :
-> -> Filter: (ccah.PLATFORM_CD = 'A') (cost=6229.55 rows=6109) (actual time=0.092..56.711 rows=34828 loops=1)
-> Table scan on ccah (cost=6229.55 rows=61093) (actual time=0.089..48.410 rows=104972 loops=1)actual time이 감소한 것을 알수있다.
-
