7. Motion Capture and Character Animation

🖤Motion Capture
What is Motion Capture[MC]?
- Motion capture (MoCap) is the process of recording the movements of objects or people.
사람이나 오브젝트의 움직임을 녹화한 것이다.
- Movements 를 digital data로 바꾼다.
Movements of one or more actors are sampled many times per second and translated into digital data.
- 2D or 3D character animation에 사용이 가능하다
- performance capture : 얼굴, 손가락, 표정 등을 캡쳐 하는 것
→ motion을 캡쳐할 때는 중요한 관절 정보만 잘 판단하면 된다. 그러나 표정같은 것을 알기 위해서는 미세하게 다 알아야 한다. 눈썹 각도 등등. 그래서 이것들은 다른 형식의 좀 더 정교한 모션 캡쳐가 필요해 따로 분류해 부른다.
- more realistic and natural animations 을 만들기 위해
Methods for generating character animation
전통적으로 많이 사용되던 것
✔ Key frame animation
-
애니메이터, 디자인을 직접 만드시는 분들이 key 단위로 애니메이션 생성
-
특정 시간에 어떤 포즈를 가질 것인지 정의하는 것
-
linear interpolation만으로 정의할 수 없는 특징적인 움직임을 따로 정의하고 나머지는 interpolation 하는 것
-
well-suited for animating non-humanoid characters, fantastical creatures, or highly stylized movements.
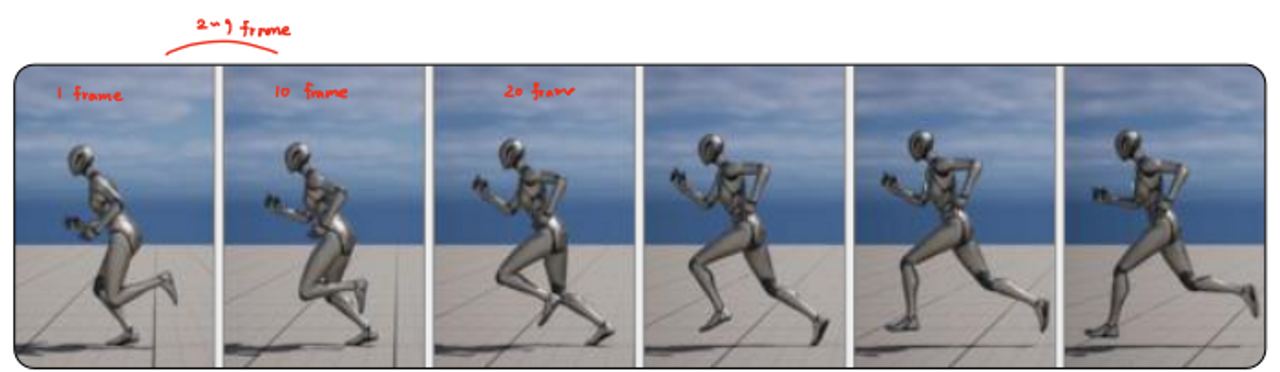
✔ Procedural animation
-
도저히 애니메이터가 붙어서 할 수 없는 기괴한 것들 그런 것을 수학적으로 잘 모델링 하면 되는 것들.
-
알고리즘이나 룰, 시뮬레이션에 의존, 직접 만드는 것이 아니라 수학적인 계산을 통해 이런 움직임을 가질거야라고 정의하는 것
-
대표적으로 코사인, 사인과 같은 움직임이 있다. 이걸 다 키마다 움직이려면 힘드니까 주기 함수를 이용한 알고리즘을 통해 계산해 만든다
-
자동적으로 수행되거나 반복작업을 통해 시간과 노력을 줄일 수 있지만 목표를 달성하기 위해너는 추가적인 fine-tuning이 필요하다
-
ex) 촉수 괴물

요즘 들어 핫해진 것
Mocap (Key frame animation 을 대체)
✔ Advantages
- Realism : 사실적이다.
- Efficiency : 애니메이터가 직접 한 땀 한 땀 다 만드는 것이 아니기 때문에 효율적이다.
- Consistency : 어떤 스타일을 유지하기 쉽다. 애니메이터는 계속 돌려보면서 조금 이상한데? 계속 확인해봐야 한다. 근데 같은 액터가 같은 상황에서 연기를 하면 스타일을 유지하기 쉽다.
- Performance-driven : 행동이 바로 적용이 된다.
→ 과장된 액션을 하면 바로 적용이 된다.
✔ Disadvantages
- Cost : 특수한 수트, 마커, 카메라, 처리할 소프트웨어, 액터 등등 비용이 많이 든다.
⇒ Cost 해결이 잘 안되어서 지금까지 잘 안됐다.
- Limited flexibility : realistic human or animal movements는 괜찮은데 fantastical creatures, highly stylized characters, or non-humanoid characters 에는 제대로 작동하지 않는다.
- Cleanup and refinement: 한 번에 쓸만하게 나오지 않아서 후처리 과정이 필요하다
- Dependence on performer : 연기하는 사람이 얼마나 잘 연기하느냐에 따라 달라진다.
There are mainly five types of motion capture methods
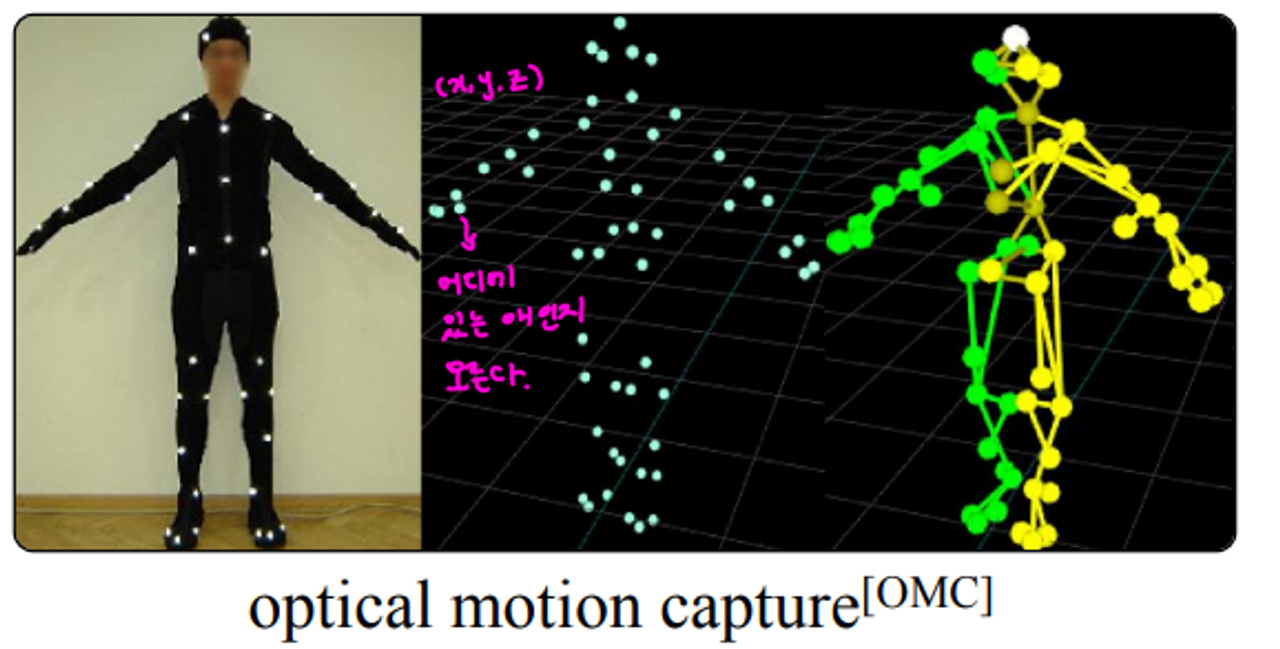
🤍Optical motion capture (OMC)
- 액터의 몸에 붙어 있는 마커들을 tracking 하고, capture space 주변에 있는 많은 카메라들로 움직임을 capturing 한다.
- The system triangulates the markers’ positions in 3D space and generates a digital skeleton that can be applied to a character model.
Triangulation
→ 내가 어떤 마커의 삼차원 공간 상의 위치를 추정하고 싶다. 여러 카메라를 기준으로 얻은 distance 들을 가지고 마커가 붙어 있는 삼차원 공간 상에서 x y z 를 얻어내는 것.
→ 움직임을 하다보면 마커를 가리게 되기 때문에 카메라가 여러개 있어야 한다.
1. Passive optical motion capture (POMC)
Passive : 빛을 쏘지 않거나 파워를 필요로 하지 않는 것
-
external light sources에 의존한다. 스스로 발광하지 않으니 카메라가 나를 향해 쏘는 빛을 이용
-
retroreflective material 반사를 잘하는 물질로 되어 있다. 카메라가 나한테 빛을 쏘면 이를 반사해서 돌려 주어 카메라가 마커를 감지하도록 한다.
-
마커들은 빞을 단순히 반사하는 역할을 한다.
-
카메라들이 빛을 쏘고 받기 위해 그 자리에 존재
-
빛이 reflective markers를 때리면 카메라를 향해 튕겨져 나간다. (detect and track 하기 위해)
- detect : given frame에 어디에 있는지 감지
- track : sequence of frame 에 어떻게 움직였는지, 모션을 따라가는 느낌
-
캡쳐된 이미지는 각 프레임마다 프로세스 되어서 각각 어떤 마커인지 판단 해주어야 한다.
-
그 이후엔 Triangulation을 이용해 위치를 찾아나간다.
→ x y z 값만 가지고 만들기는 힘들다. 원래 머리인지 어깨인지 어디 붙어있던 것인지를 찾는 과정을 푸는 것이 쉽지 않다.
2. Active optical motion capture
Active : 마커가 능동적으로 빛을 방출
-
마커에서 light를 액티브하게 뿜는다
-
마커는 power source가 필요하다 → 전자 회로가 필요하다.
-
마커는 unique IDs를 가진다.
→ Passive 방식은 마커가 id를 가지지 않았다. 그래서 x y z 포지션으로부터 내가 어디에 달려 있는 것인지 추정을 해야했는데 Active 방식에서는 빛을 쏘는 패턴 같은 것을 조종해서 나 몇번째 마커야 하는 것이 가능하다. → post processing이 필요가 없다
-
각가의 마커가 어디에 붙어 있는것인지 실시간을 바로 추적할 수 있다.
-
카메라는 마커가 쏘는 빛을 받아들이는 역할

Passive VS. Active
-
Cost: Passive > Active→ Active는 마커가 더 비싸다
-
Marker Complexity: Passive > Active→ Passive 방식은 마커를 액터의 몸에 달기도 쉽고 가볍다. Active 마커는 빛이 잘 분산되게 잘 달아야 하고 하니 좀 더 복잡하다
-
Lighting dependency: Passive < Active→ Passive 마커는 어두운 공간에서는 잘 되지만 빛이 많으면 잘 감지하고 트랙킹하기가 어렵다. 반면에 active는 이러한 것으로부터 영향을 덜 받는다.
-
Marker occlusion: Passive < Active→ Active 마커가 occlusion issue(카메라에 마커가 안 보이는 것)에 좀 더 잘 핸들링 한다. passive는 추정을 해야하는데 occlusion이 일어난다는 것은 놓쳤다는 이야기인데 놓친 것이 다른 것을 추정하는데 영향을 준다. 이것이 내가 놓친 것인지 팔꿈치인지 헷갈린다는 것이다.
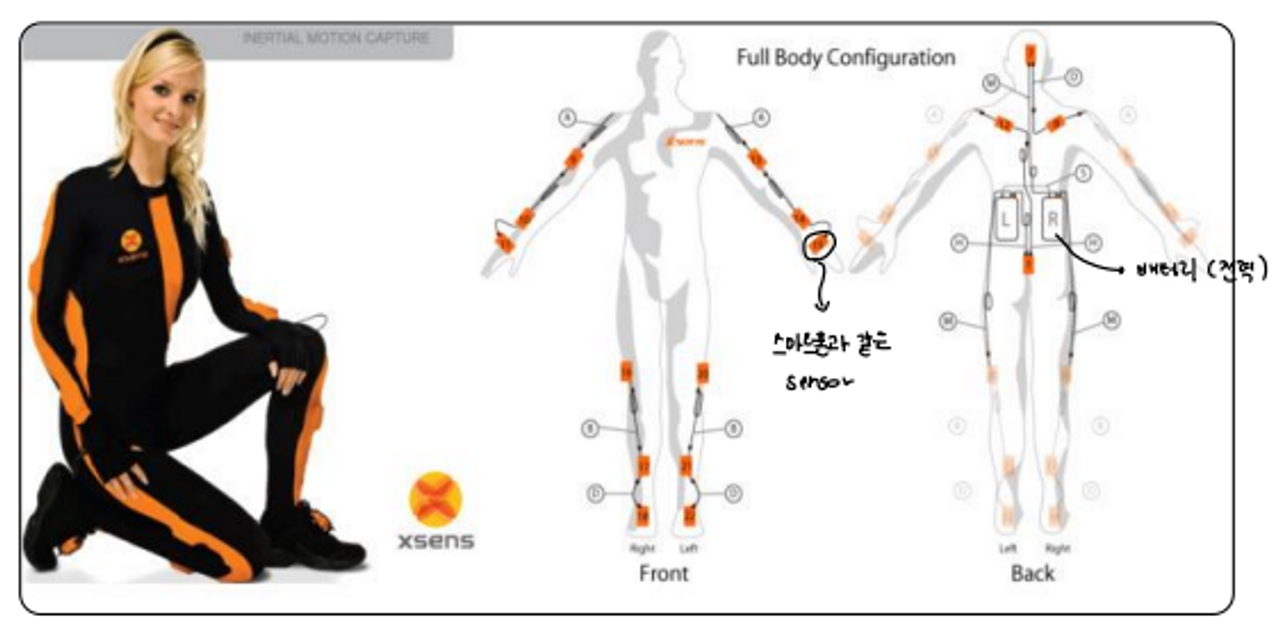
🤍Inertial motion capture (IMC)
- wearable sensors (IMUs) 가 액터의 몸에 붙어서 어떻게 움직이는지 찾는 것
→ 스마트폰을 여러개 몸에 붙이고 있는 것이라 생각하면 편하다
- acceleration, angular velocity, magnetic field orientation 을 측정 한다.
Advantages
- Portability and flexibility : 카메라나 캡쳐 스페이스가 필요하지 않다
- No occlusion issues
- Faster setup
- Real-time feedback
Disadvantages
- Positional accuracy → 이게 제일 문제
- 센서를 정교하게 다루는 것이 힘들다
- Magnetic interference
- 자성물체가 주변에 있으면 영향을 많이 받는다. 굉장히 민감하다.
- Battery life
- 오랜시간 퍼포먼스하면 배터리 갈아줘야 한다.
⇒ 모션캡쳐실을 구현하기 힘들 때
🤍Magnetic motion capture
- magnetic fields 를 사용함
- 연구의 영역임
🤍Machanical motion capture
- 강화 외골격을 이용함. 로봇을 타고 모션 트래킹을 함
- 부자연스러움 + 외골격 제작이 힘듬.
🤍Markerless motion capture
- 비전 카메라로 측정하자.
- 굉장히 활발히 연구가 되고 있다.
- accuracy가 문제가 되서 아직 쓰이진 않는다.
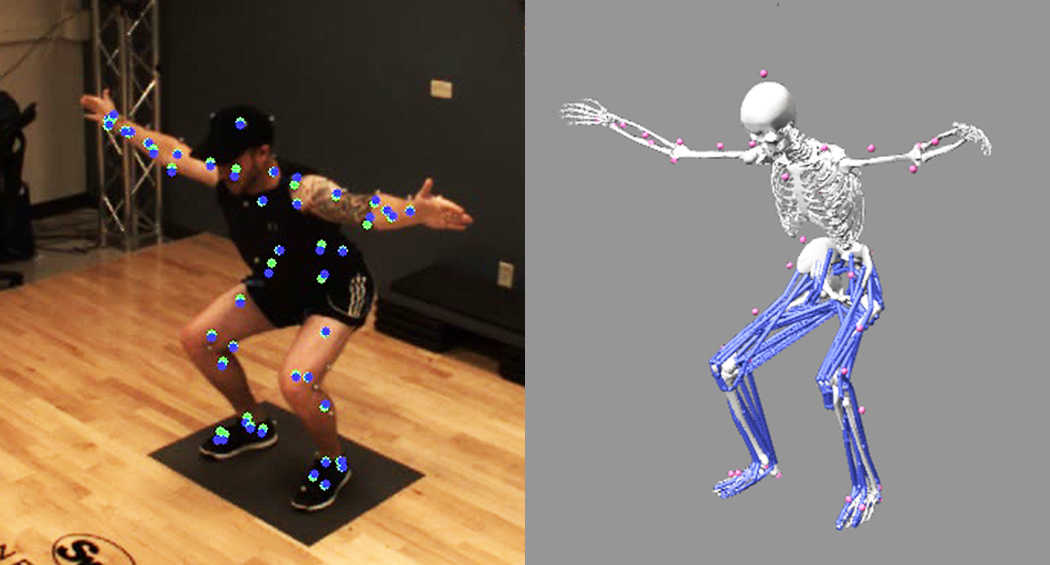
🖤 Post-processing of POMC
Why does passive optical motion capture (POMC) require postprocessing?
- 내가 얻은 point cloud (x y z ) 가 어떤 layout 마커에서 오는거지? 를 연결시켜주는 작업
- POMC가 AOMC보다 좀 더 많이 쓰인다
→ 저렴하고 사용하기 간단하고, 많은 전문가들이 이미 해봤기 때문에 그들을 그냥 고용해서 쓰면 되서 친숙하다- POMC는 post-processing 을 필요로 한다
→ accuracy, data quality를 올리기 위해
Resolving marker ambiguity (marker labeling)
- ambiguity 애매성
- POMC는 마커들이 똑같이 보인다. id X
- 빠르거나 복잡한 움직임을하면 뭐가 어디서 온 것인지 헷갈린다.
- 이로 인해 마커들을 정리하는 과정에서 잘못 대입이 되거나 바뀌기도 한다.
- 그래서 post-processing은 제대로 붙었는지 확인하고 제대로된 마커 layout으로 만듬
Reducing noise
- 센서를 이용하면 대부분 노이즈가 크다 ( 라이팅 컨디션, 카메라 해상도, 등등)
- 노이즈를 줄여주는 여러 기술을 적용한다.
Gap filling
- 아무리 카메라를 여러개 설치해도 가려지는 동작이 있을 것이다.
→ 2개 이상의 카메라에서 보이지 않으면 가려졌다고 판단
- 가려지는 곳 있으면 3차원 정보다 제대로 계산이 안된다.
→ 데이터의 갭이 생긴다.
→ 27개 마커하고 캡쳐 했는데 22개만 나옴
- 대충 여기 이쯤 있겠다, 수동으로 여기겠구만 해결함 & interpolation
Rigging and retargeting
- 마커레이어를 다 뽑으면 그것을 기반으로 캐릭터 움직임으로 만들어 주어야 한다.
Constraint enforcement
- 모션 캡쳐를 해서 3차원 데이터 만드는 것 자체는 우리 몸이 할 수 있는 자세인가? 이런거 고려한 것이 아니고 그냥 데이터를 가져다가 여기에 있어 한거다.
- 우리 사람의 신체 구조상 마커가 저기 있으면 안되는데? 하는 것들도 있을 것이다.
- 그런 것들에 대해 constraints를 enforce해서 다 없애거나 조종해줘야 한다.
Cleanup and optimization
- 마커가 occlusion 되어 없어지는 것들이 존재한다고 했다. 반대로 분신술을 하는 마커들이 있다.
- 모션을 빠르게 하면 동일 프레임 내에 reflection이 일어난다거나 해서 여러개 카메라에 들어가서 잔상처럼 남게 된다. 이런것들을 ghost marker라 한다.
- 이것들에 대한 처리도 해준다.
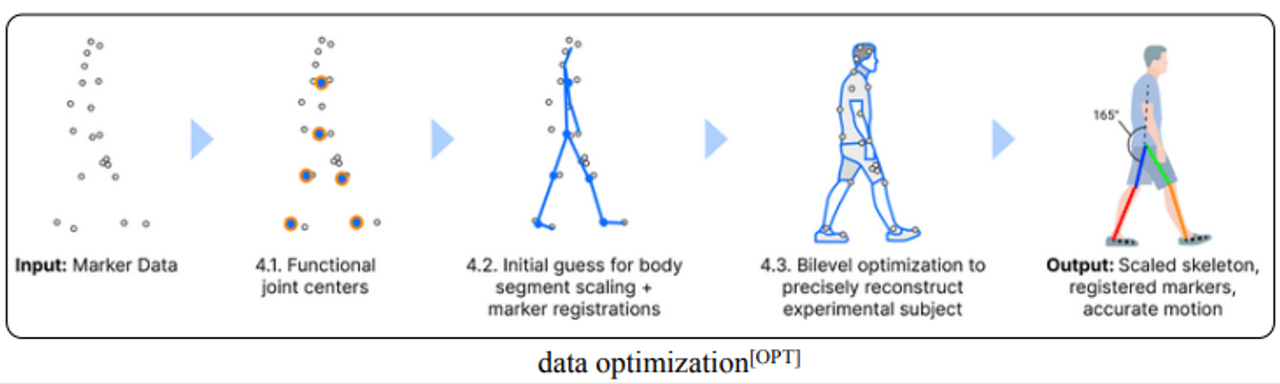
Correctly assigning labels to the markers in motion capture data
occlusion & Ghost Marker
-
POMC 가 각각의 마커들이 어떤건지 구별하는것이 어려웠다. → 이게 문제
-
distinguishing 하는 것도 어려워 죽겠느데 id도 없다.
-
이 문제가 실제 모션 데이터와 다른 결과물이 나오게 된다.
-
이 문제를 해결하기 위해 manual or automatic labeling methods 를 사용
→ SOMA: Solving Optical Marker-Based MoCap Automatically, 2021 CVPR 이 논문에서 자동으로 해결하는 것 제시
-
A mocap point cloud (MPC) is a time sequence with T frames of 3D points
MPC: mocap point cloud / Point Cloud Set
→ : T framde에서의 Point Cloud Set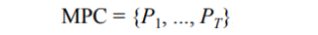
P: MPC에 있는 한 점
→ : 2frame에서 3번째 Point cloud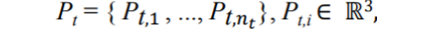
T: P가 나와야 하는 총 개수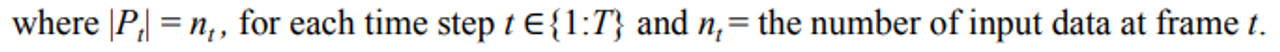
🖤 SOMA: Mocap Labeling Problem
Goal : MPC가 있을 때 이 친구가 내가 실제로 촬영할 때 쓴 marker layer와 연결을 해주는 것
가 L에 어디에 연결되어야 하는지
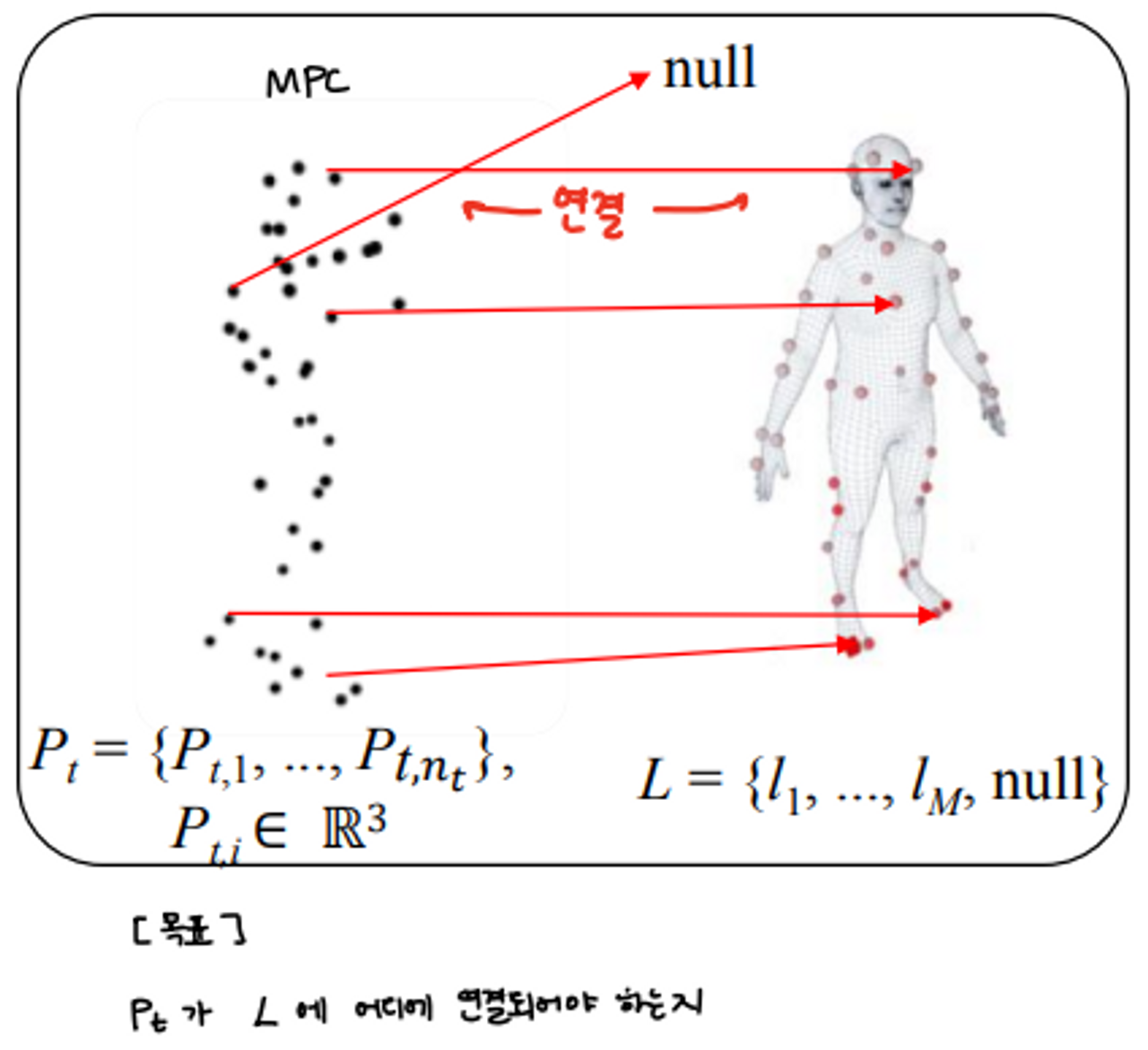
lㅁ : Marker Lable / L : 몸에 달린 총 Marker Label의 수
→ null : ghost marker ( 어떤 는 null에 assign)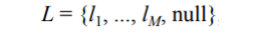
- L의 수는 ghost marker까지 포함해서
- Valid point labels and tracklets of them are subject to three constraints :
- t frame에서 i 번째 point cloud는 반드시 단 하나의 marker에만 연결될 수 있다.
- t frame에서 i 번째 point cloud는 반드시 단 하나의 tracklet 에만 연결될 수 있다. ( tracklet : 이움직임은 얘 꺼야, 연속된 프레임에서의 움직임 )
- ghost marker는 여러개가 될 수 있기 때문에 여기에는 여러개가 연결되도 상관 없다.

- 아래 사진에서 점점점 있는 것 point cloud를 input으로 받아 왔을 때 오른쪽에서 색이 바뀐 점(나는 누구야 라고 id 가 끝난 것) 의 결과를 얻고 싶다.
→ SOMA에서는 이를 해결하기 위해 Self-Attention이라는 것을 사용한다.
To process such data, SOMA exploit multiple layers of self-attention
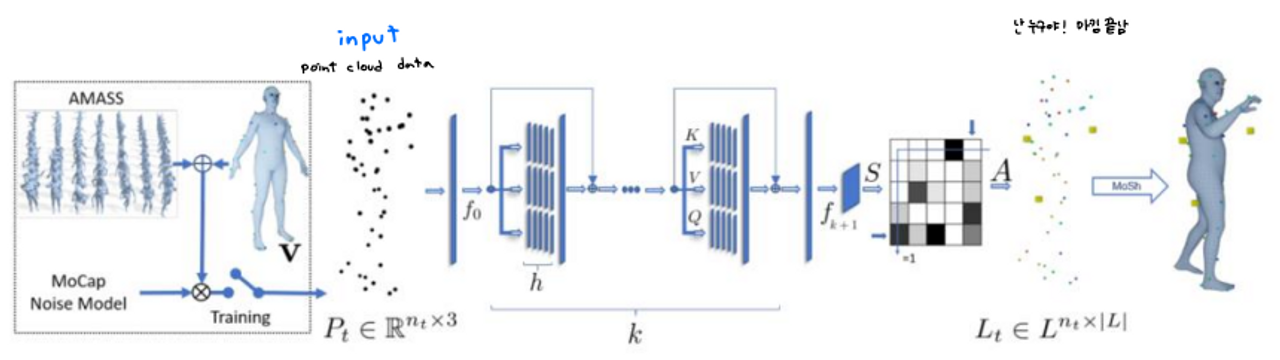
What is Attention?
- artificial neural networks에서는 attention은 이해할 때 사용하는 집중(cognitive attention)을 모방하는 것이다.
- attention은 자연어에서 처음 나왔다. 어떤 데이터가 연속적으로 들어왔을 때 이 데이터를 판단하는데 전체를 다 regulaer하게 참조해서 하는 것이 아니라 가장 연관성 있는 것을 가져다가 판단하는 것을 attention이라 한다
- 데이터가 막 들어왔는 데 내가 무슨 판단을 한거야. a-z의 데이터가 들어왔는데 알파라는 데이터를 판단하기 위해 a-z를 다 쓰는 것이 아니라 제일 관련 있어 보이는 c,d,e를 가져다가 판단한다.
⇒ 중요한 것 같은 데이터에 조금 더 focusing을 하겠다.
focus to the small but important parts of the data
⇒ 무엇이 중요한지는 학습하는 것은 gradient descent를 통해 훈련된다.
- token : cat, kitten, dog, houses
- : token들을 각각 인덱스로 라벨링 ex) cat →
- : 가중치
→ 가중치들의 합 = 1, 가중치가 높다는 것은 그것에 더 집중하겠다는 뜻
- : value vector
→ cat을 넣었을 때 word embedding을 통해 벡터로 만들어준다
→ 몇개의 카테고리를 제시하고 이 카테고리 별로 평가를 해 cat의 고유한 벡터를 생성해낸다. 문장을 벡터화 하여 문장을 해석가능한 숫자의 집합, 디멘젼으로 가지고 왔다는 것을 의미한다.
→ living being이라는 축, feline이라는 축, … 이렇게 7개의 축을 정의를 한 것이다.
→ 비슷한 느낌이면 비슷한 곳에 위치하게 된다. cat과 kitten은 비슷한 영역에 위치
⇒ word embedding : 비슷한 특징을 가지는 것들이 비슷한 영역에 있도록 만들어 주는 것.
⇒ attention : 벡터화 한 다음에 나와 연관이 있는 것을 찾는 것
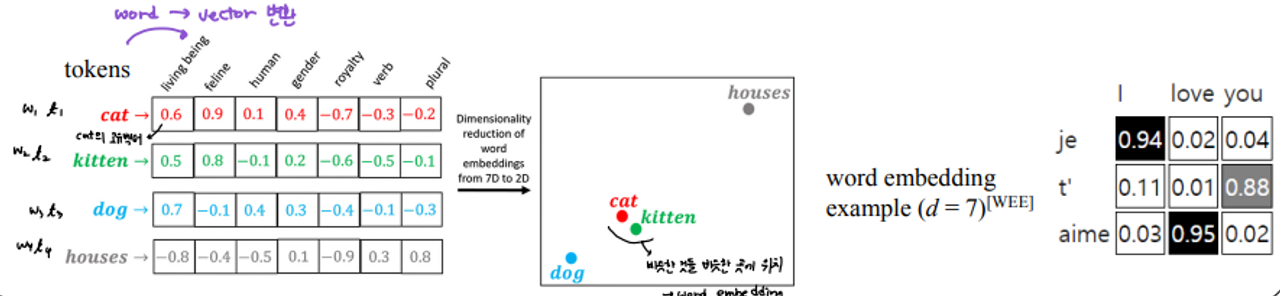
✅ 용어 정리
weight가 높다는 것이 나와 연관이 높다는 뜻
- Q : 들어오는 data, 판단할 녀석
- K : Q랑 관계가 어떻게 돼?
- V : Q랑 관계가 어떻게 돼?
- : 벡터의 dimesion을 몇 차원으로 했는가
→ 앞의 예시에서는 7

“The animal didn’t cross the street, because it was too tired”
- it은 animal과 연관이 깊다. didnt 이런 애들은 weight가 낮다.
-
Query : 구하고자 하는것 → it과 연관된것이 궁금
it을 word embedding을 통해 3차원 벡터로 보낸다.
-
Key, Value : animal도 3차원 벡터로 보낸다.
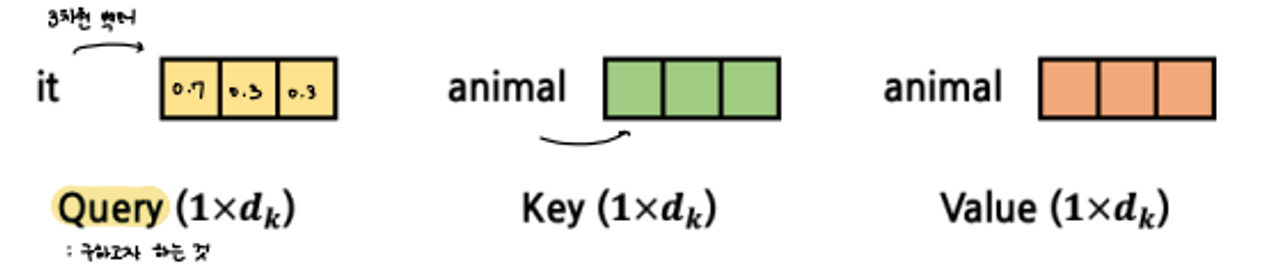
-
를 계산 → Attention Score 를 만듬
→ animal을 traspose 해야하니 세로로 눞힌다. 그리고 곱한다. 1x1 결과
→ it 과 animal를 통해 attetion score (둘 사이의 관계) 를 구함

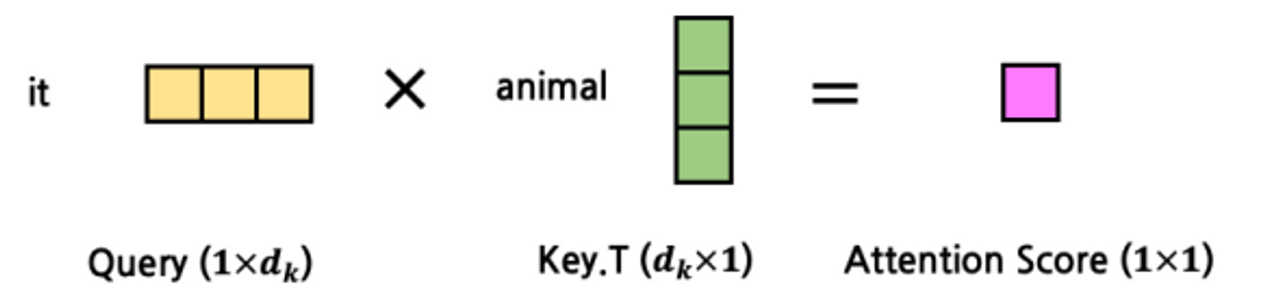
- 우리가 구하고자 하는 것은 it과전체 문장의 attetion이기 때문에 전체에 대해 수행한다.

-
이걸 구하고 SoftMax 를 해준다.
→ SoftMax : 데이터를 넣으면 0과 1사이로 적당히 분류해주는 필터 함수
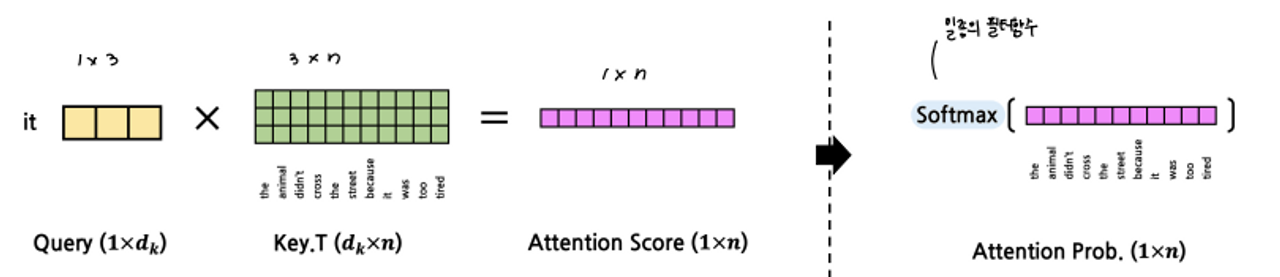
- SoftMax한 결과에 Value를 한 번 더 곱해준다.
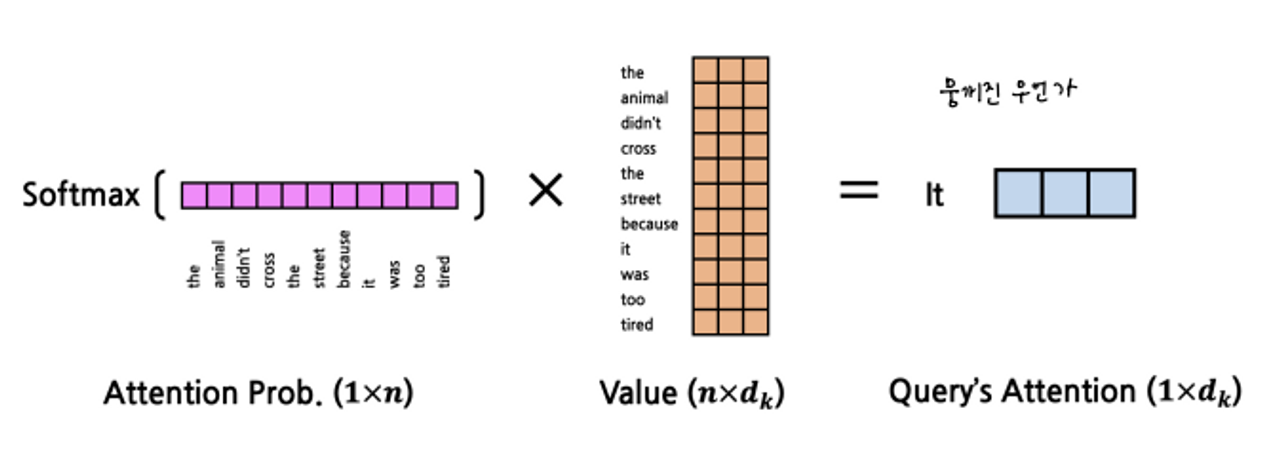
⇒ 최종 결과 : **it**과 문장 전체에 해당하는 attention에 대해 뭉개진 value
- 이 과정을 it에 대해서만 하는 것이 아니라 각각의 문장을 이루는 단어에 대해서 전부 수행해 Query’s Attetion을 만든다
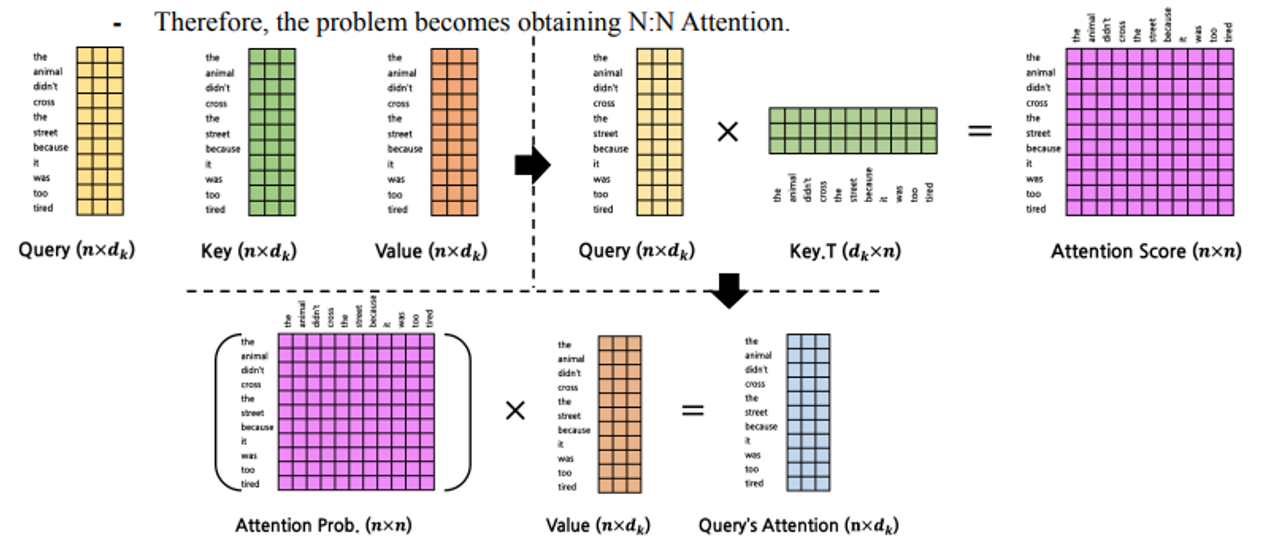
Self attention
- Q K V를 모두 같은 값을 쓰는 것
ex) animal은 문장 내에 누구와 가장 연관이 있지?
-
앞에서는 Query와 얼마나 연관이 있는지 찾는 것이었다. self는 이 문장 내에서 내가 어디와 가장 연관이 있는지 찾는 것이다.
-
SOMA에서 이것을 왜 사용할까?
→ 데이터를 판단하는데 있어 이거 들어왔는데 이 친구 머리일까? 찾아야하한다. self-attention에서는 주변 데이터를 보아 하거니 얘랑 연관이 많은 데이터는 이 친구 인 것 같은에 얘네를 미루어 보아 판단했을 때 이 녀석은 얘가 맞는 것 같아요 라고 판단을 하면 안된다. 이게 셀프를 사용하는 이유이다. 얘네는 다른 데이터가 필요가 없고 주어진 point cloud 데이터에서 머리와 연관이 많은 데이터는 어깨하고 목 주변에 있는 데이터 였다. 근데 걔네 구해 놓은 것 보니까 너 이거 머리 데이터 맞는 것 같아 라고 판단을 내려주길 원함.
-
self- attention을 multi layer로 사용한다.
→ self attention을 사용한다는 것은
데이터를 1234를 판단 했는데 1은 2하고 연관이 있는 것 같아를 찾는 것.
이것을 한 번 더 self-attiontion한다는 것은 3이 2 하고 연관이 있는데 2하고 연관이 있다는거야. 그래서 나는 3을 판단하는데 있어서 2를 0.5만큼 쓰고…
- 하나를 쓰는것 나하고 관련이 있는 주변녀석들을 판단을 하는 것인데 여러개 사용을 하면 나하고 관련이 있는 녀석에 관련이 있는 것을 판단할 수 있게 되어 더 정확도가 올라간다.
🖇 Reference
해당 포스트는 강형엽 교수님의 게임공학[GE-23-1] 수업을 수강하고 정리한 내용입니다.
