
Housing Price Prediction
이전 포스트에서 설명한 머신러닝의 예시와 과정을 구체적으로 살펴보고자 한다. 이번 포스트에서 살펴보는 예시는 Supervised Learning에서도 regression probelm에 해당된다.
1. Problem Definition
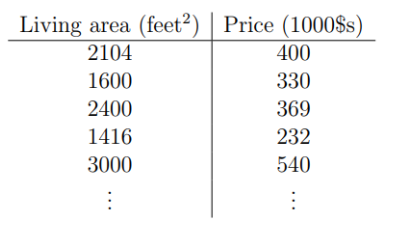
47개의 집에 대한 (평수, 가격)이 주어진다고 생각해보자.
이러한 데이터를 기반으로 우리가 어떻게 다른 집들의 가격을 예측할 수 있을까?
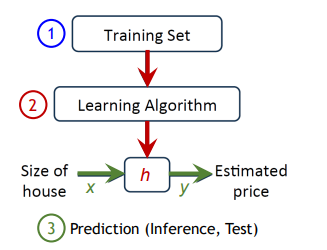
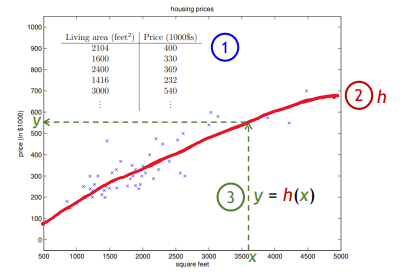
tranining set: dataset
→modelorhypothesis: prediction function h : y = h(x)
이전 포스트에서 언급한 것처럼 Regression 문제는 y=h(x)에서 h에 해당하는 black box를 찾아내는 것이라고 이야기 했다.
즉, 현재 예시에서는 47개 집의 (평수, 가격)에 데이터가 tranining set에 해당한다.
그리고 이 tranining set를 기반으로 알고리즘을 학습시킨다. 학습을 통해 우리는 집의 평수를 입력으로 넣었을 때 가격 결과를 낼 수 있는 prediction function h를 찾아내게된다.
그 후 집 값이 얼마인지 모르는 어떤 집의 평수 데이터를 넣었을 때 학습한 결과를 바탕으로 해당 집의 가격을 Prediction 해낸다.
2. Data Representation
머신러닝을 배우면서 사람마다 표기법이 참 많이 다르다는 생각을 했다. 실제로 책마다 블로그마다 논문마다 표기가 조금 다른데 전반적인 개념 자체는 동일하다.

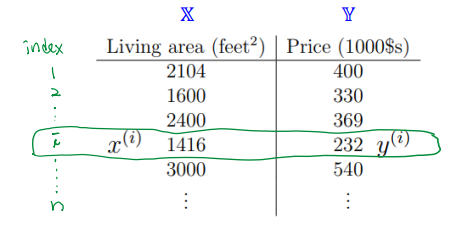
앞서 47개의 데이터로 적용하면 다음과 같다.
예를 들어 index가 3인 traning example은 인 1416과 인 232가 합쳐져 (1416, 232)이다.
우리가 가진 training set은 47개이니 이다.
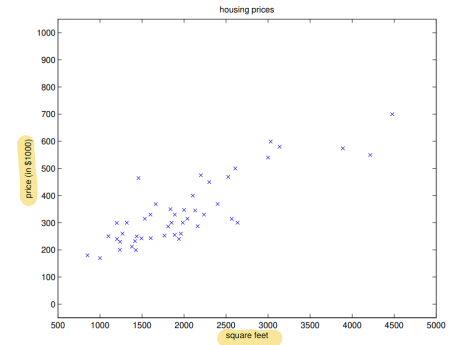
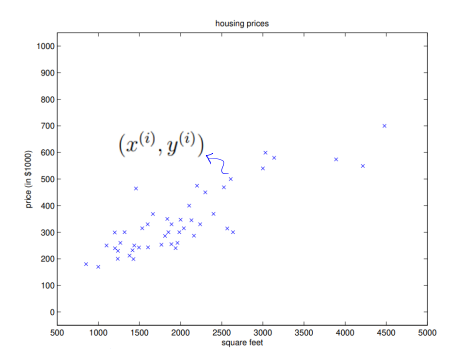
47개의 traing set 중 하나의 traing example을 그래프에서 표시하면 다음과 같다.
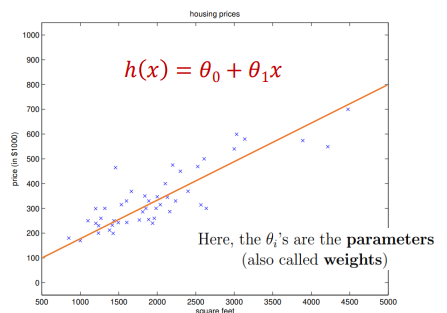
3. Model Representation
◆ Linear Model (Linear Hypothesis)
우리가 이 문제에서 다루는 것과 같은 모델을 선형 모델 Linear Model이라고 한다.
쉽게 말해 선형 모델은 1차 방정식으로 표현된다고 생각하면 된다.
이차방정식에 대해 배울 때 우리는 에서 a와 b 두개의 파라미터 값을 알면 하나의 곡선을 정의해낼 수 있었다.
여기서도 마찬가지이다. 결국은 우리는 저 직선을 찾고 싶은 것이다. 즉, 직선을 찾기 위해서는 a와 b에 해당하는 두 개의 파라미터를 찾아야 하는 것이다.
이를 vector 로 표기하면 다음과 같다. 위와 똑같은 식이나 벡터로 표현한 것이다. 벡터로 표현을 하면 추후 계산을 할 때 편리한 경우가 많아 함께 알아두면 좋다.
이후에는 수많은 matrix로 계산을 해야하는 경우가 많기 때문이다. 또한, 대부분 코드를 작성할 때 데이터 하나하나 반복문을 돌리기보단 벡터 연산으로 처리하는 것이 더 간편하다.
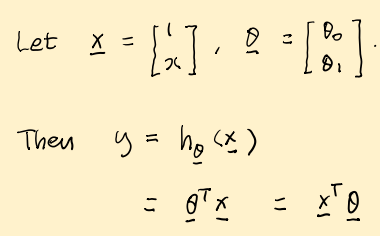
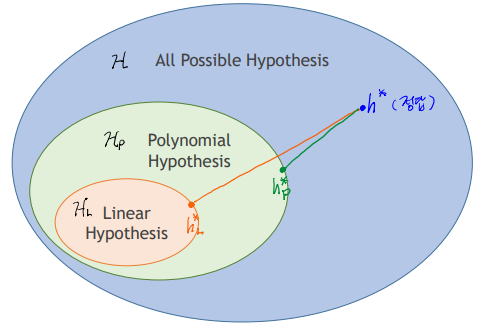
◆ Hypothesis Space & Model Capacity
ML은 hypothesis space 에서 가장 최선의 를 찾아내는 것이다.
우리는 예시에서 Linear Hypothesis를 사용했지만 실제로는 굉장히 다양하다.
이런 hypothesis space가 커질수록 (= 모델의 크기가 커질수록) fitting하기는 쉬워지지만 train하기는 어려워진다.
4. Cost Function
우리는 앞서 Lineat Model을 보면 black box에 해당하는 함수 h를 구하려면 2개의 파라미터가 필요하다는 것을 알았다.
그렇다면 이 2개의 파라미터는 어떻게 지정할까?
먼저 가 우리의 traning examples(47개의 x,y)에 가까워질 수 있도록 를 고른다.
아래 그래프에서 우리가 선택한 θ에 따른 가 다음과 같다면 x로 표시된 training example들과의 차이가 error가 된다.
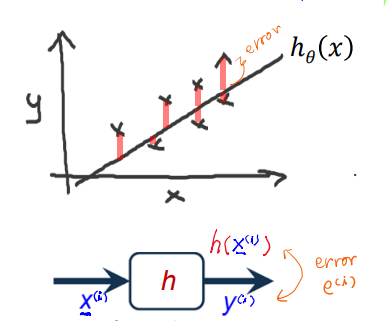
이제 이 error를 출이기 위해 Cost Function을 구한다.
Cost Function은 비용함수, 손실함수, 목적함수 등 다양한 이름으로 불린다. 통상 로 표기한다.
이런 Cost Function을 설정하는 것에는 여러가지 방법이 있다.
그 중 가장 대표적인 MSE cost를 사용해 cost function을 구해보고자 한다.
◆ MSE Cost
MSE는 Mean Squared Error로 간단히 말해 에러 제곱들의 합의 평균이다. 에러를 줄이려면 모든 에러들의 제곱의 합인 이 MSE가 작아지도록 하면 될 것이다.
SSE는 비슷한데 Sum of Squared Error이다. 이는 주황색 박스로 표시한 부분으로 그저 평균을 내지 않은 값이다.
여기서 의문이 들 수 있다. 왜 평균이라고 했는데 n으로 나누지 안고 2로 나누는지 말이다. 이는 계산의 편의성을 위해서이다. 원래 의미대로라면 n으로 나눠야 맞지만 뒤에 이어질 계산에서 미분을 하게 되는데 미분을 할 때 이차 방정식이라 차수에서 2가 나오게되는데 2로 나누면 약분을 하기가 편해져 2로 나누는 꼼수를 쓰는 것이라 생각하면 된다.
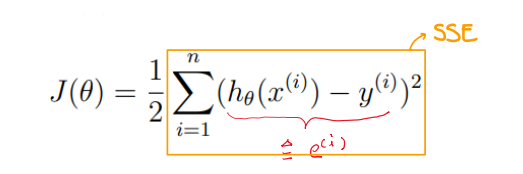
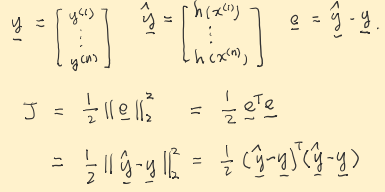
5. Optimization 최적화
아제 앞서 구한 cost function을 가지고 최적의 파라미터를 가지기 위한 최적화를 한다.
◆ Iterative Methods (반복법)
- Gradient Descent (GD)
- Stochastic Gradient Descent (SGD)
- Newton's Method
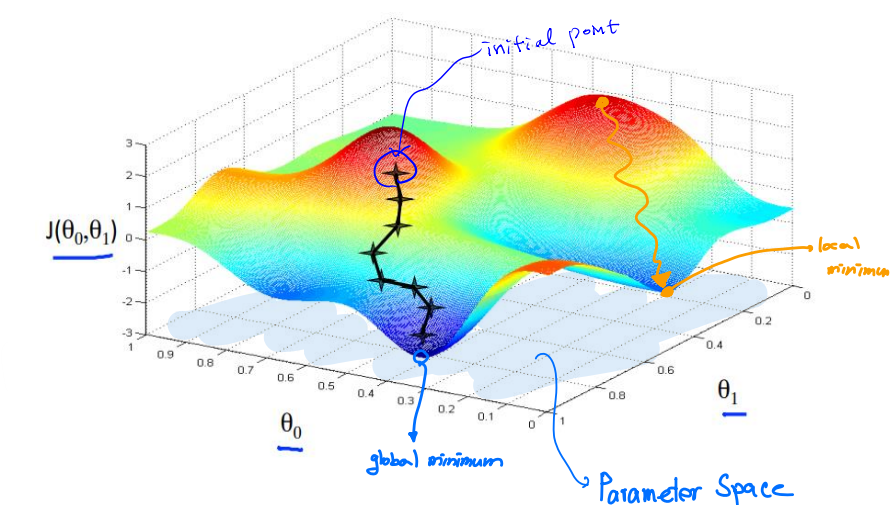
◆ Analytic Methods (해석적 방법)
- Normal Equation (Linear Model의 경우)
6. Extensions to Multiple Features
우리는 앞서 feature가 (평수, 가격) 두 가지로 모델을 학습하는 예시를 살펴보았다. 그런데 만약 이 feature가 (평수, 침실수, 가격)으로 3개로 늘어난다면?
✔ Traing set
이런 Feature의 수가 여러개로 늘어난다고 해도 앞의 방법을 그대로 따라가면 된다.
만약 feature 의 종류가 3개라면 traing set이 아래 표와 같이 될 것이다.
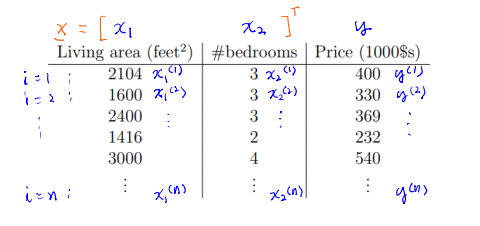
그러면 데이터는 아래처럼 표현이 가능해질 것이다.
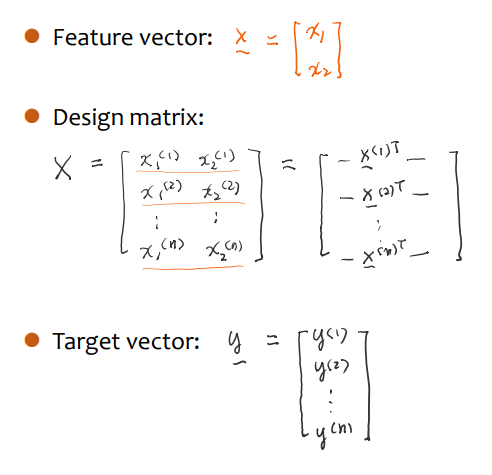
✔ Model Representation (Linear Model)
마찬가지로 선형 모델로 표현이 가능하다. 대신 feature가 3개가 되었으니 파라미터도 3개로 늘어난다.
각 feature에 파라미터를 마치 weight 가중치처럼 곱해서 표현한다고 생각하면 편하다.
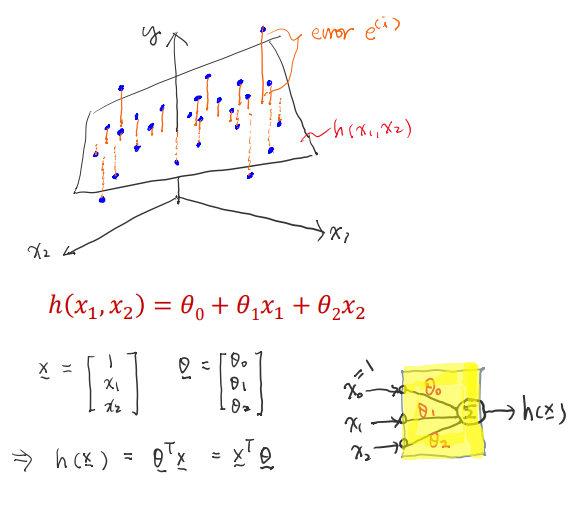
✔ Cost Function (MSE Cost)
Cost Function 또한 에러들의 제곱의 합의 평균인 MSE로 표현할 수 있다.

우와 멋있어요