[ML] What is Machine Learning and Supervised Learning/Unsupervised Learning? 머신러닝, 지도학습, 비지도 학습이란?
Machine Learning

📌 머신러닝이란?
이번 포스트에서는 머신 러닝이 무엇인지, 그리고 어떤 종류가 있는지 간단하게 적어보려고한다.
머신러닝이라고 하면 사람들은 흔히 인공지능을 떠올리고는 하는데 어떻게 보면 맞는 말이고 어떻게 보면 틀린 말이다.
요즘 사람들이 칭하는 인공지능이라는 말은 크게 분류된 인공지능이라고 할 수 있다. 사실 요즘 인터넷에서 "AI가 이제 ~~도 하고, ~~도 해" 라고 말하는 AI는 거의 딥러닝에 가깝다.
그러나 요즘은 딥러닝, 머신러닝 이런걸 다 합쳐서 그냥 통상 AI라고 부르기도 한다. 아래 사진에 연두색 큰 원이 이에 해당한다.
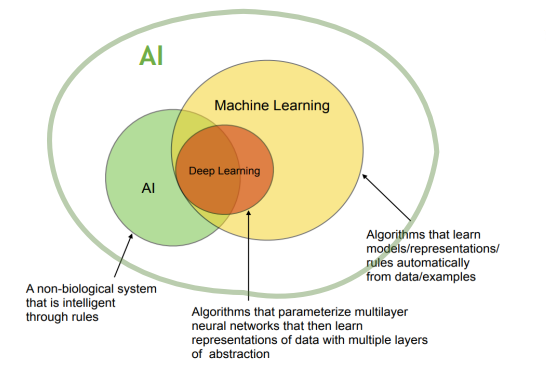
그렇다면 머신러닝은 무엇일까?
머신러닝은 러프하게 블랙 박스 를 입력과 출력의 데이터만을 가지고 매핑하는 것을 알아내는 것이라고 말할 수 있다.
어렸을 때 학습지에서 수학 문제를 풀 때 이런 블랙 박스를 본 경험이 있을 것이다. 비슷하게 머신러닝에서는 입력값과 출력값이 어떻게 매칭이 될 수 있는지 이 블랙 박스 자체를 찾는 것이라고 이해하면 편하다.

기계학습의 현대적 정의 by Mitchell
- 기계학습을 정의하려면 풀고자 하는
Task : T가 있어야 한다. - 잘 했는지 못 했는지 평가 하기 위한
Performance measure : P - 학습할 수 있는 문제집
Training experience : E
- 문제집을 많이 풀면 풀수롣 p가 높아져야 하는데 그렇지 않다면 학습이 제대로 안되는 것
- 학습이 된다는것은 e를 제공했을 때 P가 높아지는 것
✅ 머신러닝의 종류
머신러닝은 크게
지도학습 Supervised Learning과비지도학습 Unsupervised Learning으로 나눌 수 있다.
두 학습의 가장 큰 차이점은 정답 데이터셋의 유무이다.
- 지도학습 : 정답 데이터셋이 존재함.
- 비지도학습 : 정답 데이터셋이 존재하지 않음.
1. 지도학습 Supervised Learning
특정 벡터(input) X와 목푯값(output) Y가 모두 주어진 상황
우리는 이미 옳은 정답 output이 무엇인지 알고 있다. 따라서 이미 알고 있는 올바른 예측 결과를 바탕으로 피드백을 줄 수 있다.
지도학습의 대표적인 종류로는 Regression과 Classification이 있다.
✔ Regression 회귀
Continuous output 연속적인 결과로 예측하는 것, y = f(x)
예를 들어 집의 평당 넓이에 따른 가격 정보를 알고 있다고 가정하자. 아래 그래프에서 x축이 집의 넓이 y축이 가격에 해당한다.
이 데이터들을 통해 넓이와 가격 사이의 함수관계 = Black box를 알아내는 것이 Classification에 해당한다. 주어진 데이터들을 통해 black box를 추론하고 정답을 모르는 새로운 입력값이 들어왔을 때 이 값을 앞서 알아낸 black box를 통해 추론하는 것이다.
만약 주어진 입력값과 출력값으로 추론한 black box가 'y=x'라고 가정해보자. 평수에 정비례해서 가격이 늘어나는 것이다.
x(input) - y(output)
1평 - 2000만원
2평 - 4000만원
3평 - 6000만원
이런식이라면 만약에 우리가 기존에 존재하지 않은 데이터로 3.5평은 평당 얼마일까? 추론하고 싶을 때 앞서 데이터로 얻어낸 black box, y=x 로 '약 7000만원 정도로 예측' 할 수 있는 것이다. 물론 100% 정확한 값은 아니다.
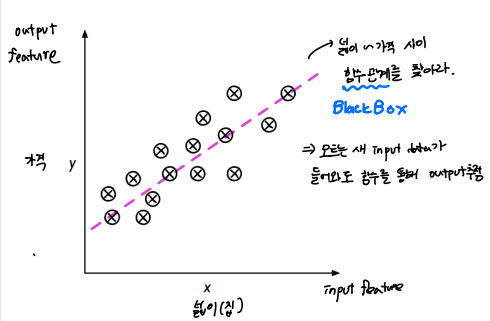
✔️Classification 분류
Discrete output 불연속적 결과로 예측하는 것, Categories
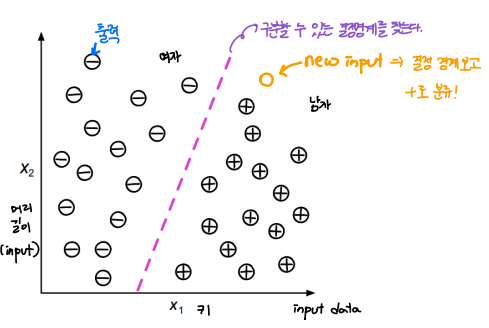
예를 들어 키에 따른 머리길이 데이터가 있다고 해보자. 모두 그런 것이라 보기는 어렵지만 대체적으로 남자가 여자보다 키가 크고, 여자는 남자보다 머리가 긴 경우가 많을 것이다.
이러한 데이터 쌍 (키, 머리길이) 를 그래프 상에 표시해보자. 그러면 이 데이터들을 구분할 수 있는 결정경계를 유추해 낼 수 있다. 아래 사진에서 보라색 점선에 해당한다.
그렇다면 이 보라색 결정경계를 기준으로 왼쪽에 있는 데이터는 여자, 오른쪽에 있는 데이터는 남자라고 추정할 수 있다.
그런 상태에서 새로운 input(키, 머리길이)이 들어왔을 때, 이 사람이 여자일지, 남자일지 판단하는 것이 Classification 문제라고 생각할 수 있다.
즉 앞서 이야기한 Regression에서는 평수에 따라 달라지는 집값을 연속적인 값으로 결과를 예측했다면, Classificaion에서는 여자 or 남자, 양성 or 음성, 합격 or 불합격 등 이산적으로 결과를 예측하는 것을 의미한다.
또 다른 예시로는개-야옹이 문제를 예시로 이야기 할 수 있다.
이는 컴퓨터 비전을 처음 설명할 때 자주 등장하는 소재이기도 한다.(컴퓨터 비전에 대해 더 자세히 보고 싶으면 여기서 참고 할 수 있다.) 예를 들어 고양이 사진 50장, 강아지 사진 50장의 training data set이 있다.
여기서 우리는 이미 사진(input)과 개인지 고양이인지(output) 정답에 대해 알고 있으니 지도학습, supervised leanrning인 것을 알 수 있다.
총 100 장의 사진으로 학습을 시킨 후, 이제 새로운 사진을 하나 가지고 와서 (이 사진은 강아지나 고양이라고 가정하자.) 이 사진을 강아지인지 고양이인지 앞서 알아낸 black box를 통해 분류해내는 것이다.
즉 개이거나 고양이이거나 불연속적 결과로 예측을 하는 것, 카테고리를 나누는 것임으로 지도학습 중에서도 Classification 분류 문제에 속하는 것이다.

2. 비지도학습 Unsupervised Learning
특정 벡터(input) X는 주어지는데 목푯값(output) Y가 모두 주어지지 않는 상황
비지도 학습은 지도 학습과는 달리 우리의 결과가 어떤 모습일지 알 수가 없다. 따라서 지도학습에서 처럼 예측 결과에 따른 피드백 또한 없다.
따라서 우리는 데이터들의 상관관계를 바탕으로 클러스터링하여 구조를 유추해낸다.
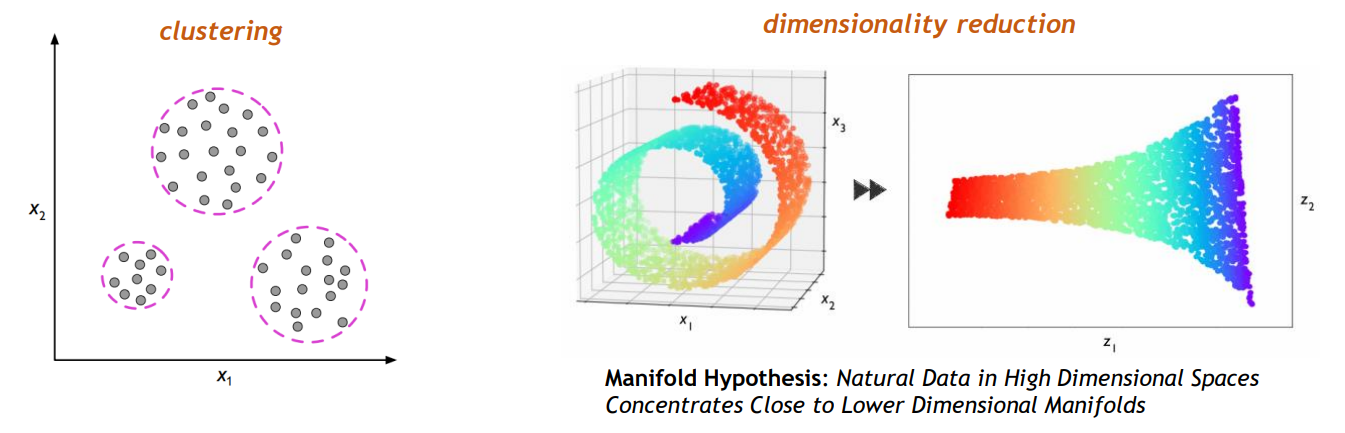
✔ Clustering
예를 들어 인터넷에서 무작위로 뉴스 기사를 100개 추출해 input으로 사용한다고 가정해보자. 우리는 이 100개의 data를 서로 비슷한 내용을 담고 있는 그룹으로 클러스터링하고 싶다.
우리가 학습시킬 머신은 이 100개의 데이터가 어떤 뉴스인지 전~혀 알 방법이 없지만 그저 내용들을 보고 비슷하다고 생각하는 것 끼리 묶는 것이다.
예를 들어 우리가 넣은 100개의 뉴스가 연예, 정치, 스포츠라고 해보자. 그런데 머신은 이 사실을 모른다. 즉 결과를 모르니 Unsupervised Learning이라고 할 수 있다.
쉽게 이야기하면 자기가 무엇을 하는지도 모르고 일을 하는 것이다. 앞서 개나 강아지로 분류를 하는 것은 새로운 사진을 받았을 때 개나 강아지로 분류해야지~ 하고 무엇을 하는지 알고 있지만 여기서는 머신은 자신이 하는 일을 모른다.
머신에게 우리가 준 것은 그저 100개의 기사뿐이다. 각기사가 어떤 카테고리에 속하는지, 몇개의 카테고리에서 기사들을 가지고 왔는지는 알지 못한다.
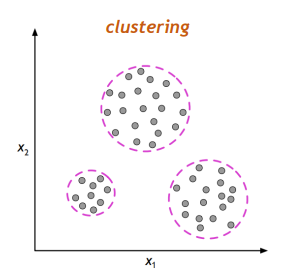
그럼에도 머신은 이 기사들을 3개의 카테고리로 아래 사진처럼 클러스터링해낸다. 물론 이것이 뜻하는 바는 전혀 모른다.
+) Quiz
지도 학습과 비지도 학습에 대해 배워봤으니 예시들을 통해 제대로 이해했는지 확인해보자.
- Given email labeled as spam/not spam, learn a spam filter.
스팸과 스팸이 아닌 메일로 label이 달린 메일 데이터가 있다. 이런 spam filter를 학습시키는 것.
- Given a database of customer data, automatically discover market segments and group customers into different market segments.
소비자에 대한 데이터베이스가 주어질 때, 시장 세그먼트를 자동으로 검색하고 고객을 다양한 시장 세그먼트로 그룹하는 것.
- Given a dataset of patients diagnosed as either having diabetes or not, learn to classify new patients as having diabetes or not.
당뇨병이 있는지 없는지 진단된 환자의 데이터 세트가 주어지면 새로운 환자를 당뇨병이 있는지 없는지 분류하는 방법을 배우는 것.
Answers to the Quiz
- 지도학습 Supervised Learning - 분류 Classification
- 비지도 학습 Unsupervised Learning
- 지도학습 Supervised Learning - 분류 Classification
