Intro
지금까지 배운 것은 앞에서 image가 들어오면 어떤 deep neural network를 통과해 결과값이 나오는 것이었다.
즉 이미지가 들어오면 카테고리가 출력이 되는 것이다. 하지만 이제 다른 Computer Vision tasks에 대해 배우게 된다.
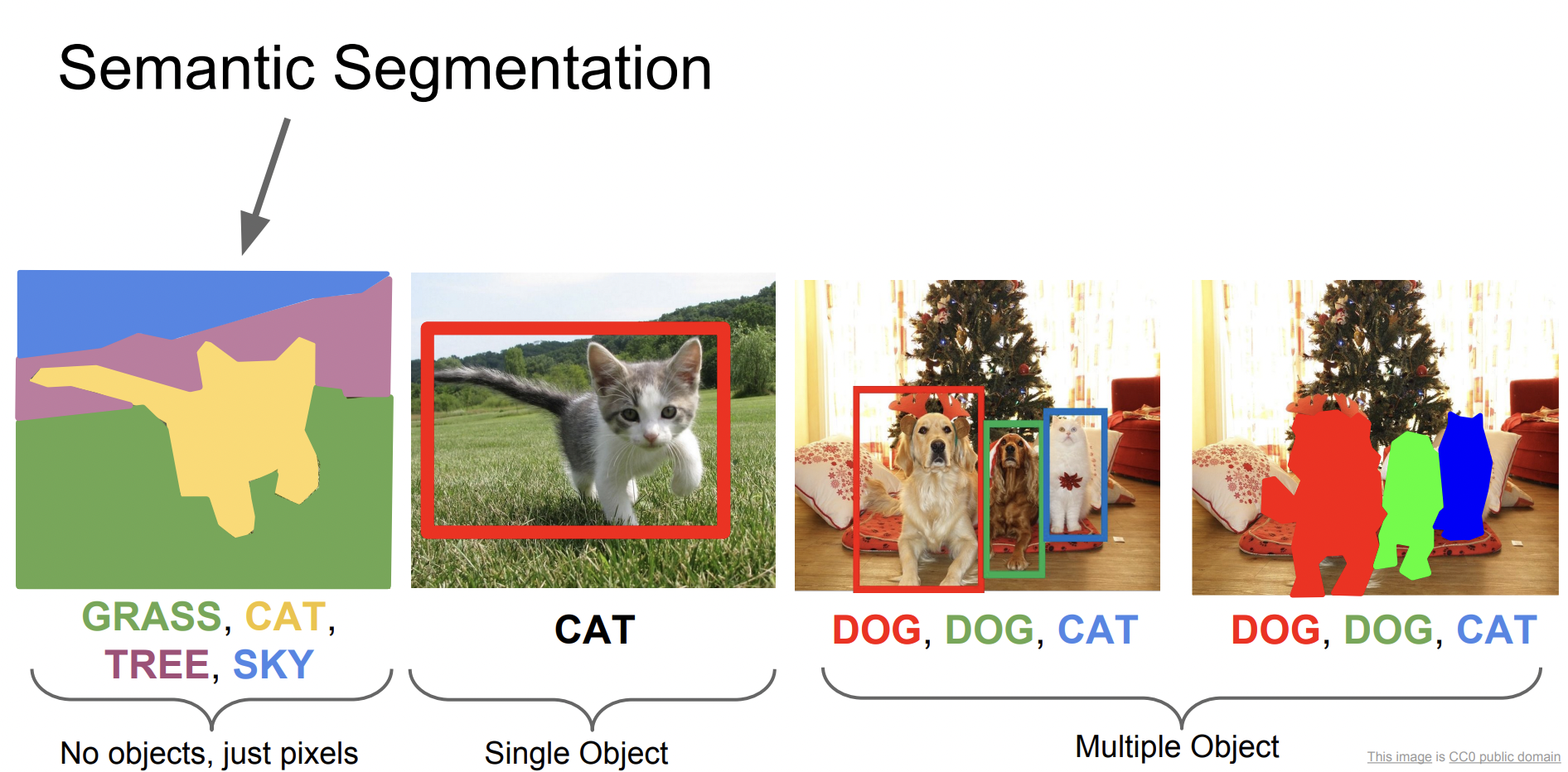
Semantic Segmentation
먼저 Semantic Segmentation은 입력으로 이미지가 들어오면 출력으로 이미지의 픽셀에 카테고리를 정하게 된다. 일종의 classification 분류 문제라고 할 수 있다.
다른 점은 이미지 전체에 카테고리가 매겨지는 것이 아니라 모든 픽셀에 카테고리가 매겨진다. 그래서 이미지에 개체가 여러 개여도 하나로 인식되는 단점이 있다.
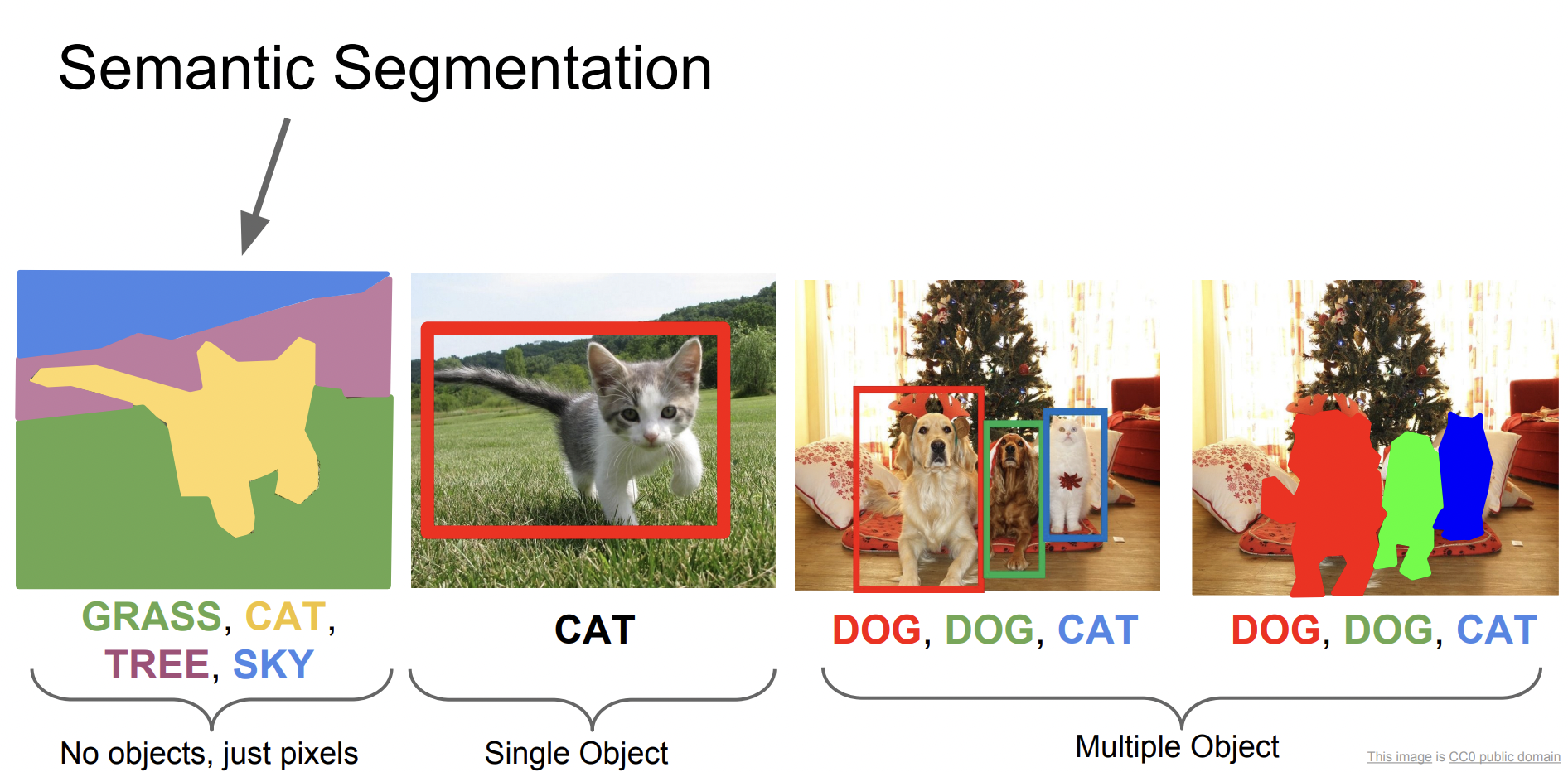
Semantic Segmentation을 구현하기 위해 가장 먼저 생각한 방법은 Sliding Window 기법이다.
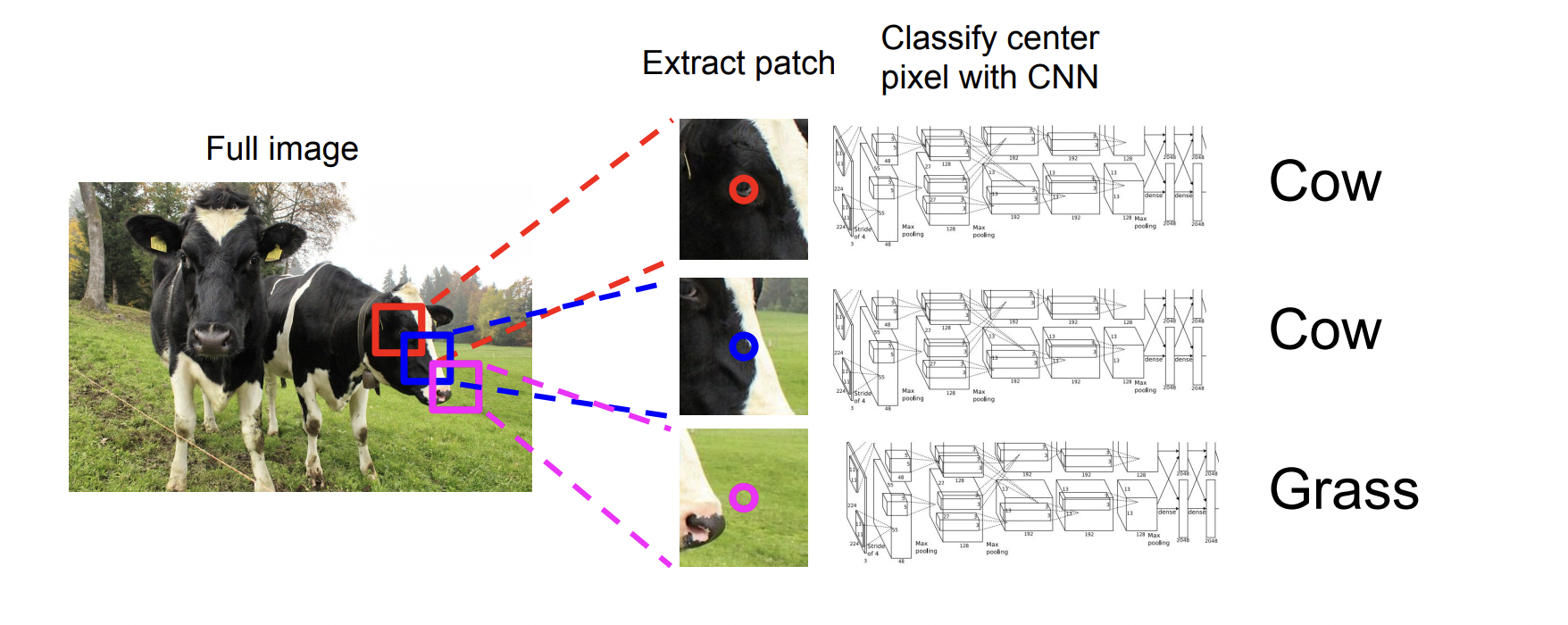
Patch를 만들고, 즉 이미지를 작은 단위로 쪼개고 각각의 patch마다 Classification을 진행하는 방법이다. 하지만 이 방법은 비용이 크기 때문에 좋지 않은 방법이다.
그 다음으로 제안된 방법은 Fully Convolutional 방법이다.
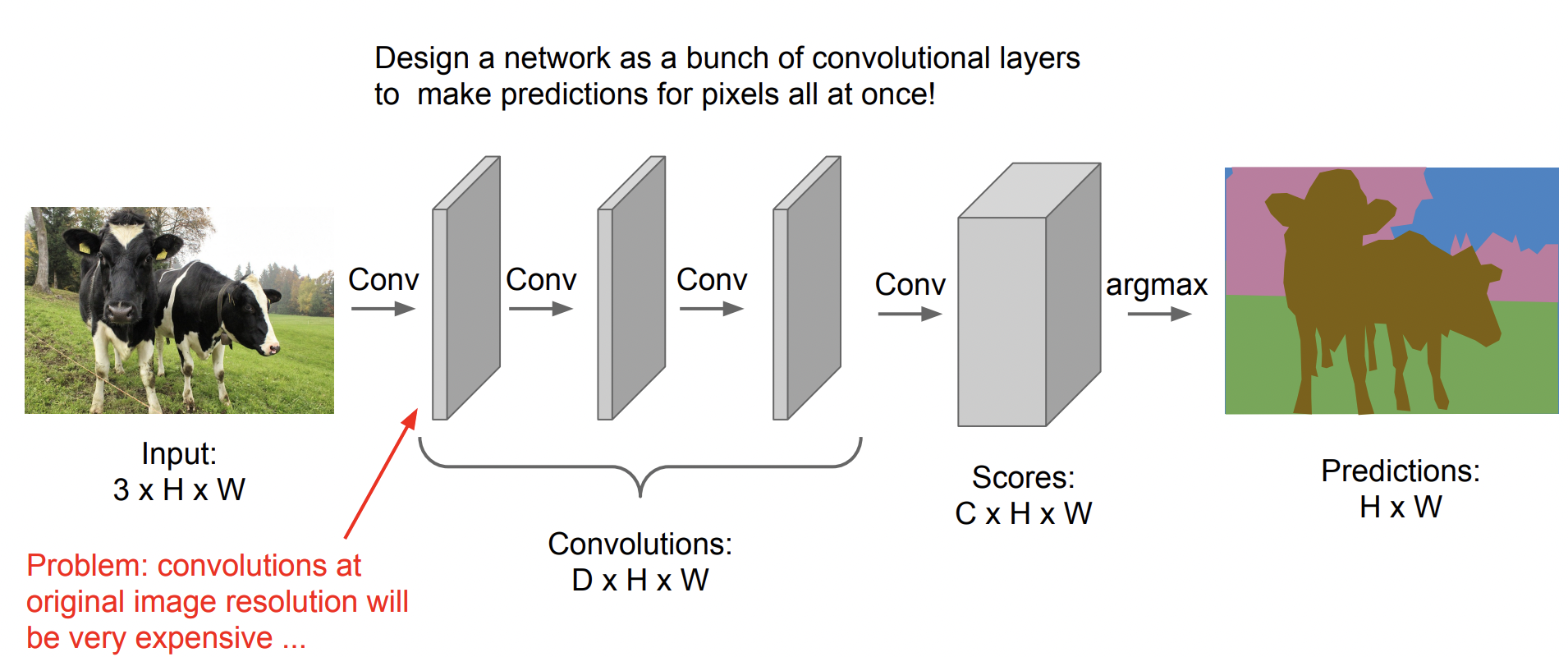
이때의 Network는 FC layer 없이 Conv layer로만 구성되어 있다. 하지만 입력의 Spatial size(공간 정보)를 유지해야 하고, 모든 pixel에 대해 score를 계산해야 하기 때문에 마찬가지로 계산 비용이 크다.
따라서 Downsampling과 Upsampling을 이용한 방법이 등장하게 된다.
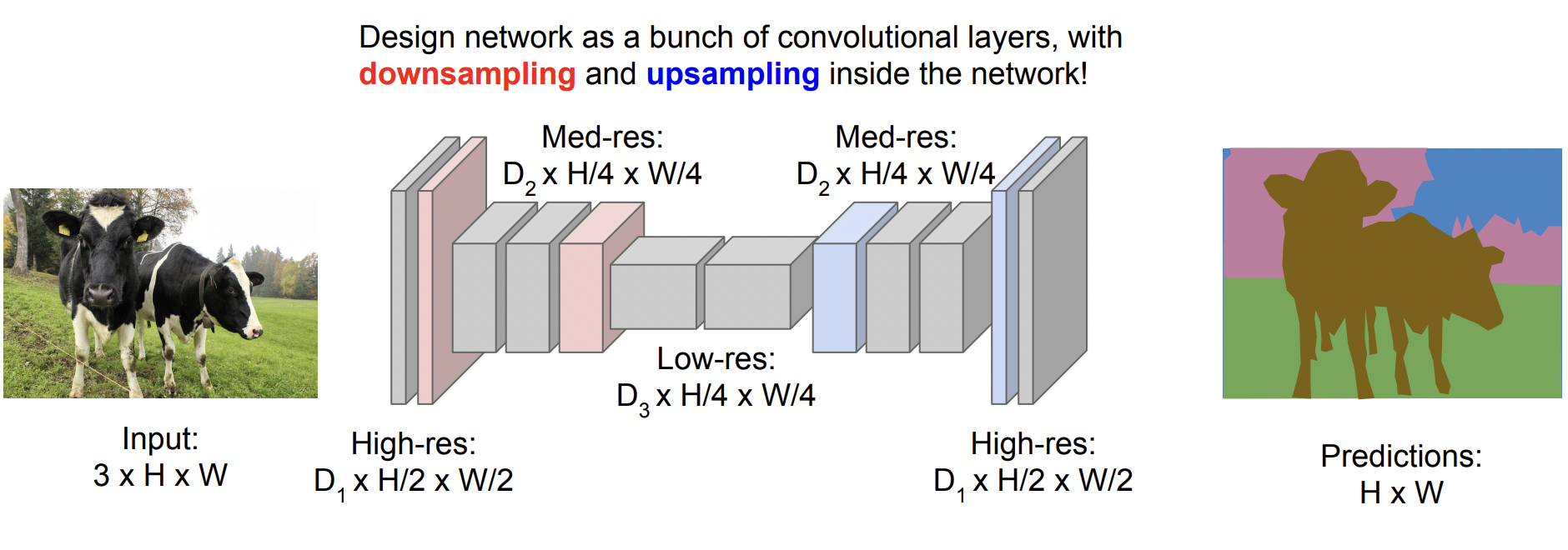
Upsampling
Downsampling은 지금까지 배운 것처럼 pooling을 진행하거나, stride를 이용해 가능하다. 따라서 이 강의에서 처음 등장한 Upsampling을 집중적으로 알아볼 것이다.
Upsampling은 간단하게 말하면 Downsampling의 반대 과정이라고 할 수 있다. 하지만 이미지의 크기를 키우게 되면 빈 공간이 생기는데, 이 빈 공간을 채우기 위해 총 3가지 방법을 제안한다.
- Unpooling
- Max Unpooling
- Transpose Convolution
Unpooling
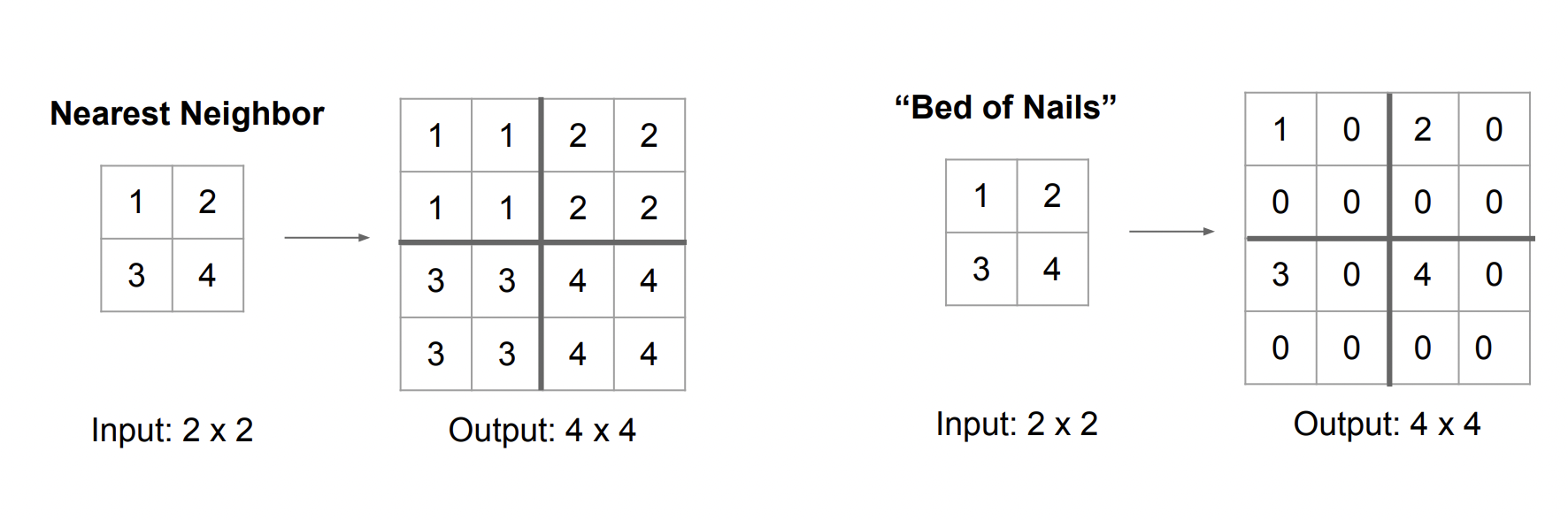
Nearest Neighbor 방법과 Bed of Nails 방법이 있다.
Nearest Neighbor 방법은 숫자를 동일하게 해서 크기만 키우는 것이고, Bed of Nails는 1번째 위치에 기존의 input 값을 넣고 나머지는 0으로 채우는 방법이다.
Max Unpooling
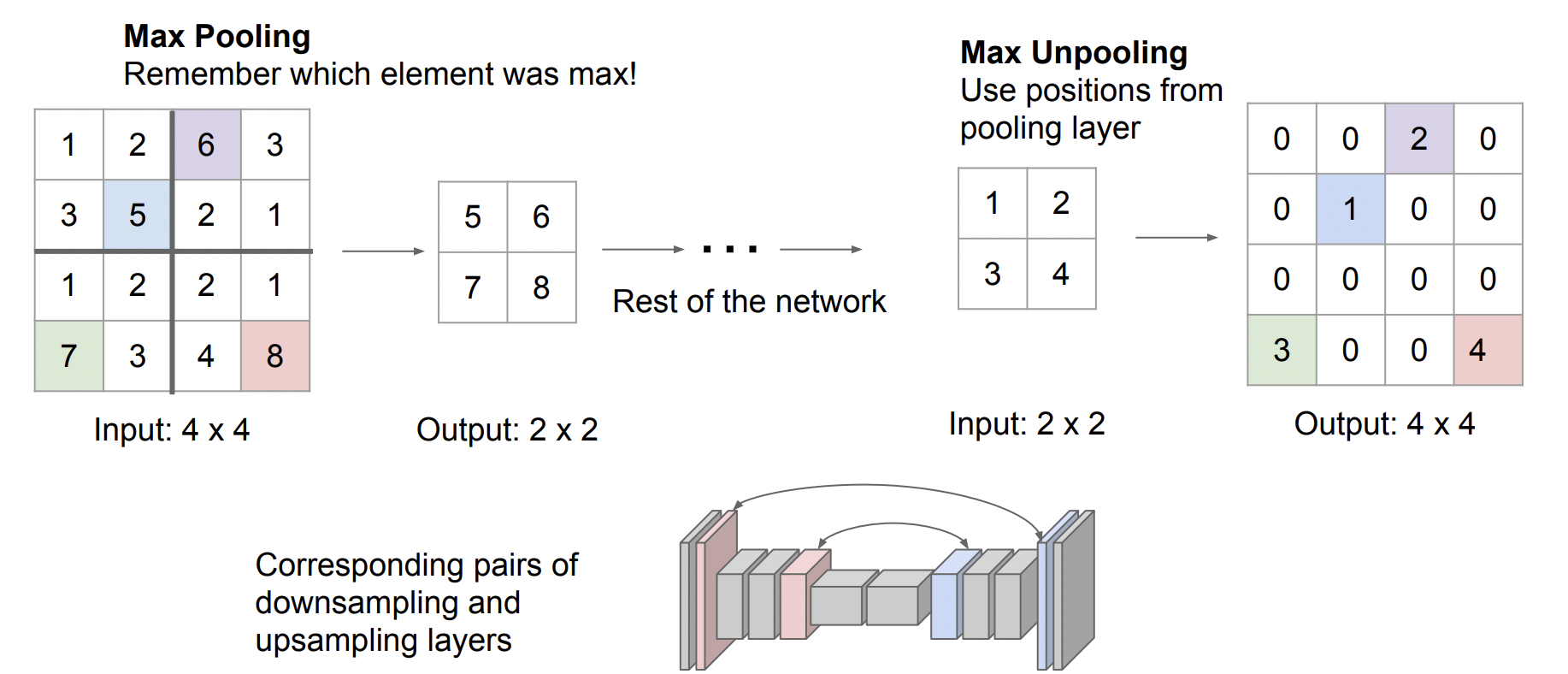
Max pooling을 진행할 때 그 위치를 기억해 값을 넣고 나머지를 0으로 채우는 방법이다. max pooling을 하게 되면 특징맵의 공간 정보를 잃게 되는데, 공간 정보를 균형있게 유지할 수 있기 때문에 좋은 방법이다.
transpose convolution
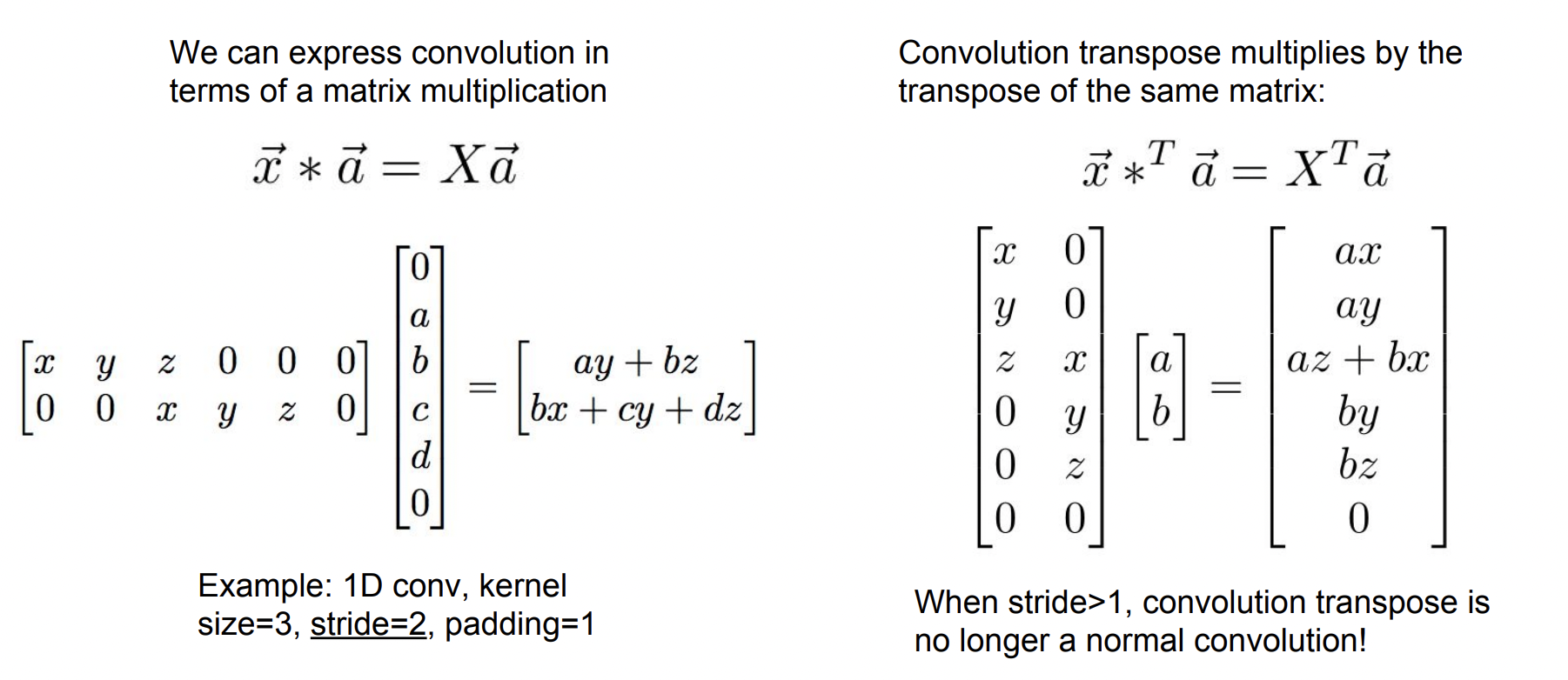
Transpose한 matrix를 내적하는 과정으로 이해하면 쉽다. stride가 1일 때는 큰 차이가 없지만 stride가 2가 되면 결과값이 크게 확장되는 것을 볼 수 있다.
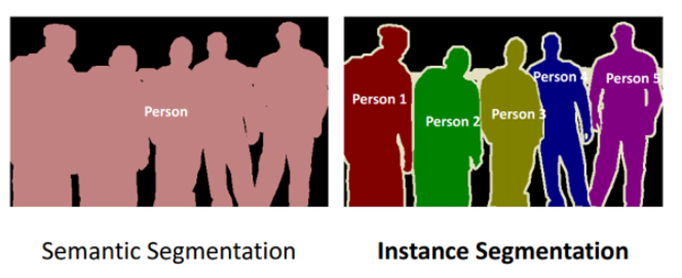
Instance Segmentation
앞서 설명한 Semantic Segmentation의 단점을 개선한 것이 Instance Segmentation이다. 각각의 pixel별로 Object가 존재하는지 아닌지를 판단한다.
Classification + Localization
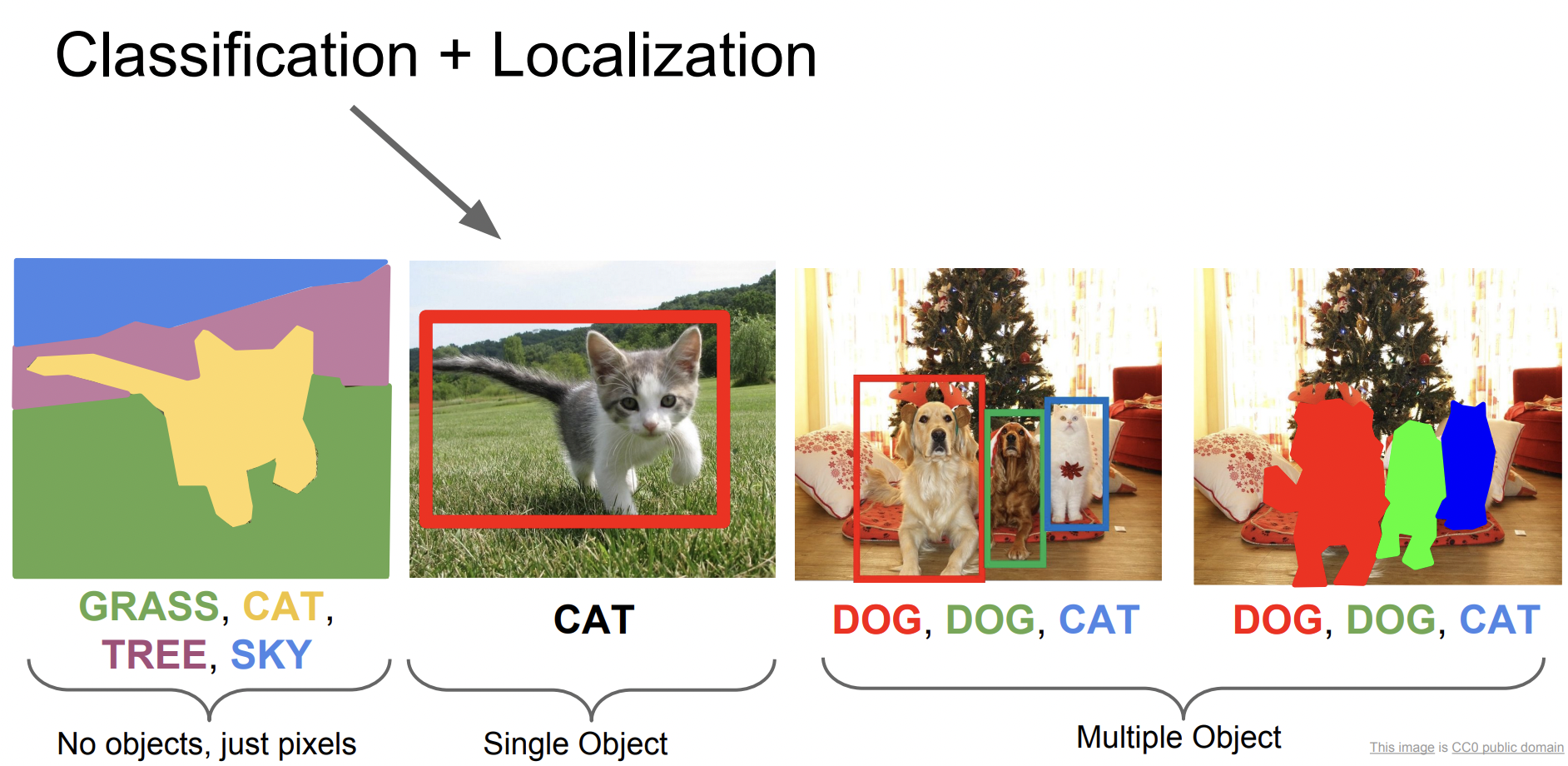
이미지가 어떤 카테고리에 속하는지 분류하는 것 뿐만 아니라 실제 객체가 어디에 위치하는지 box를 쳐 표시하는 것이다.
Localization에서는 object detection과는 다르게 객체가 오직 하나뿐이라고 가정한다. 구조는 Image classification과 비슷하지만 1개의 FC layer가 추가로 존재한다. 여기서 box corrdinate를 진행한다.
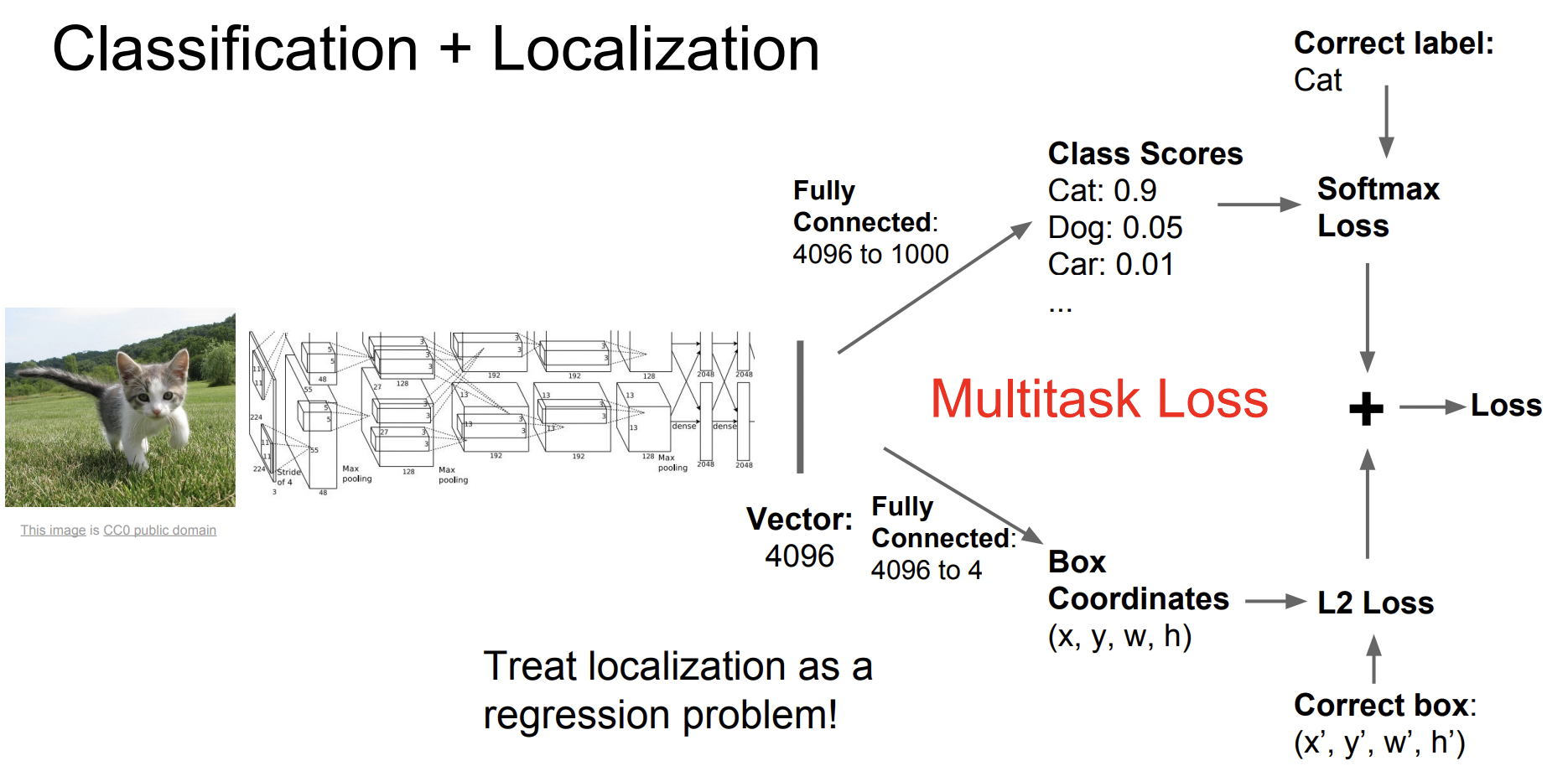
하나는 score를 반환하고 다른 하나는 bbox의 좌표를 반환한다.
따라서 2개의 loss function이 존재하며 각각의 loss를 합친 것이 최종 loss이다.
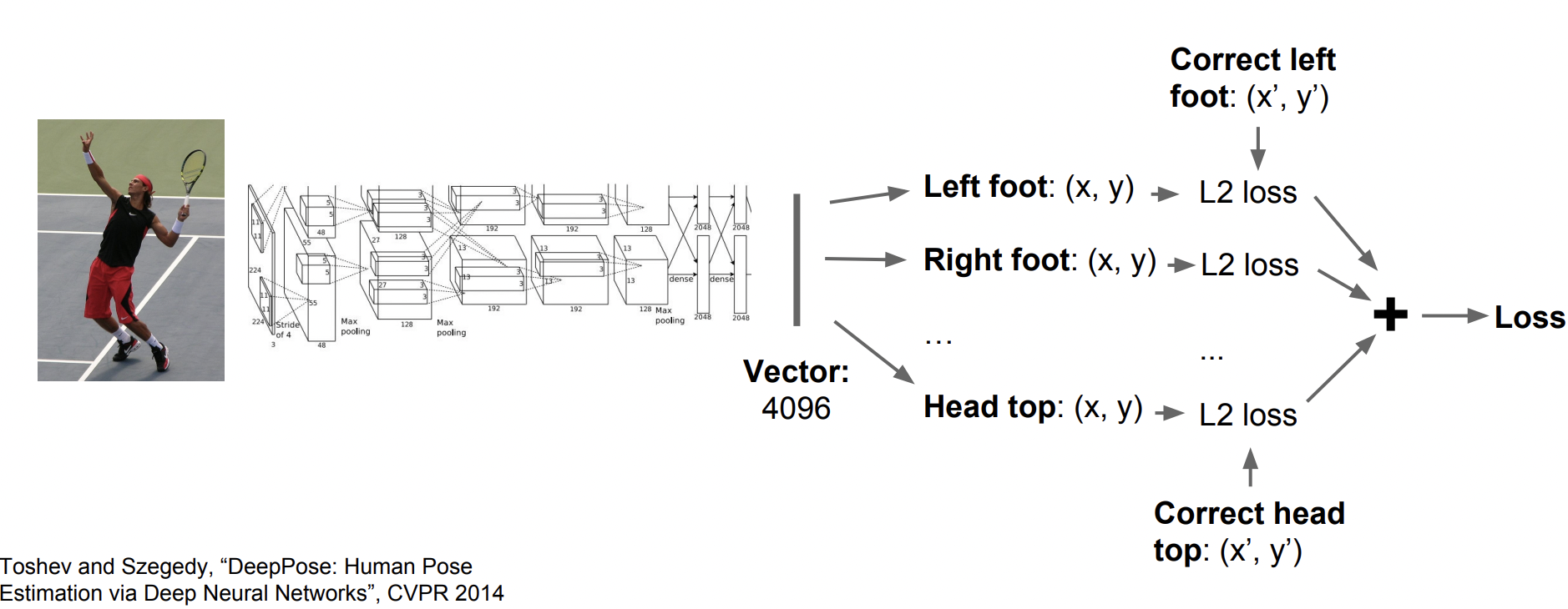
예시로 human pose estimation을 할 때, 입력으로 image를 넣고 output으로는 총 14개의 관절의 위치 좌표값이 나오게 된다.
Object Detection
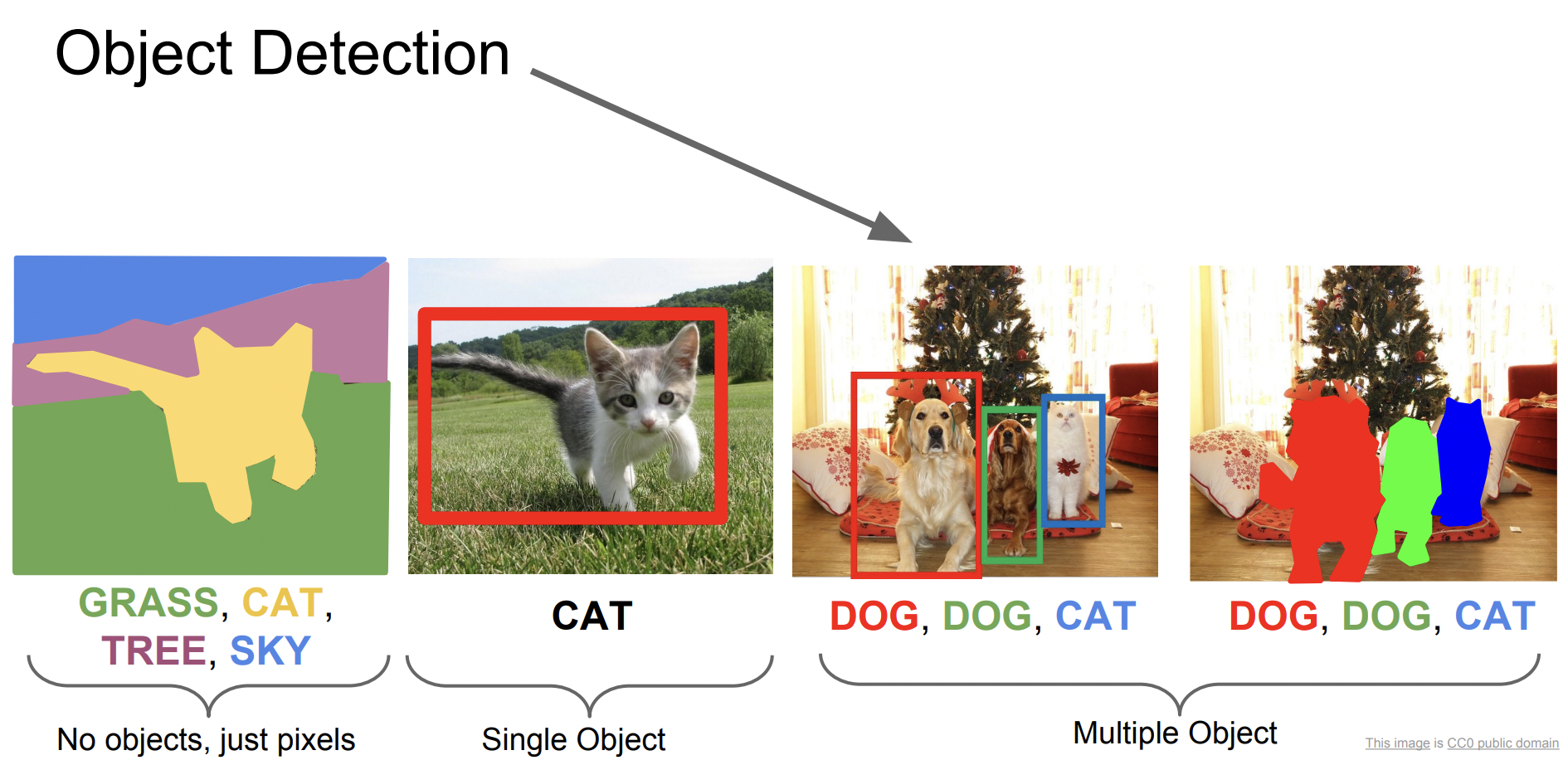
Object detection에서도 고정된 카테고리가 있다. 컴퓨터가 여러 개의 객체를 인식해야 하고, 객체의 개수가 매번 달라지기 때문에 쉽지 않은 문제이다.
Object detection은 크게 1-stage Detector과 2-stage Detector로 나뉜다. 전자는 Classification과 localization을 한 번에 진행하고, 후자는 단계별로 진행한다.
2-stage detector에는 크게 세 가지 종류의 알고리즘이 있다.
- R-CNN
- Fast R-CNN
- Faster R-CNN
R-CNN
R-CNN을 설명하기 위해 알아야 할 개념이 있는데, 바로 Selective Search Algorithm 이다.
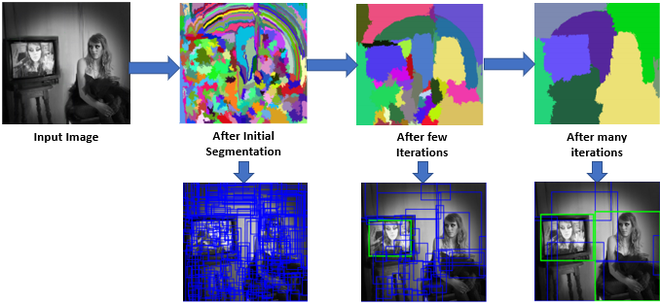
입력 영상에 대해 segmentation을 실시해서 이를 기반으로 후보 영역을 찾기 위한 seed를 설정한다. 그렇게 되면 초기에는 엄청나게 많은 수의 후보가 만들어지게 된다. 이를 적절하게 통합해 나가면 결국 후보의 개수가 줄어든다.
R-CNN에서는 이 알고리즘을 이용해 초기에 영역을 추출한다.
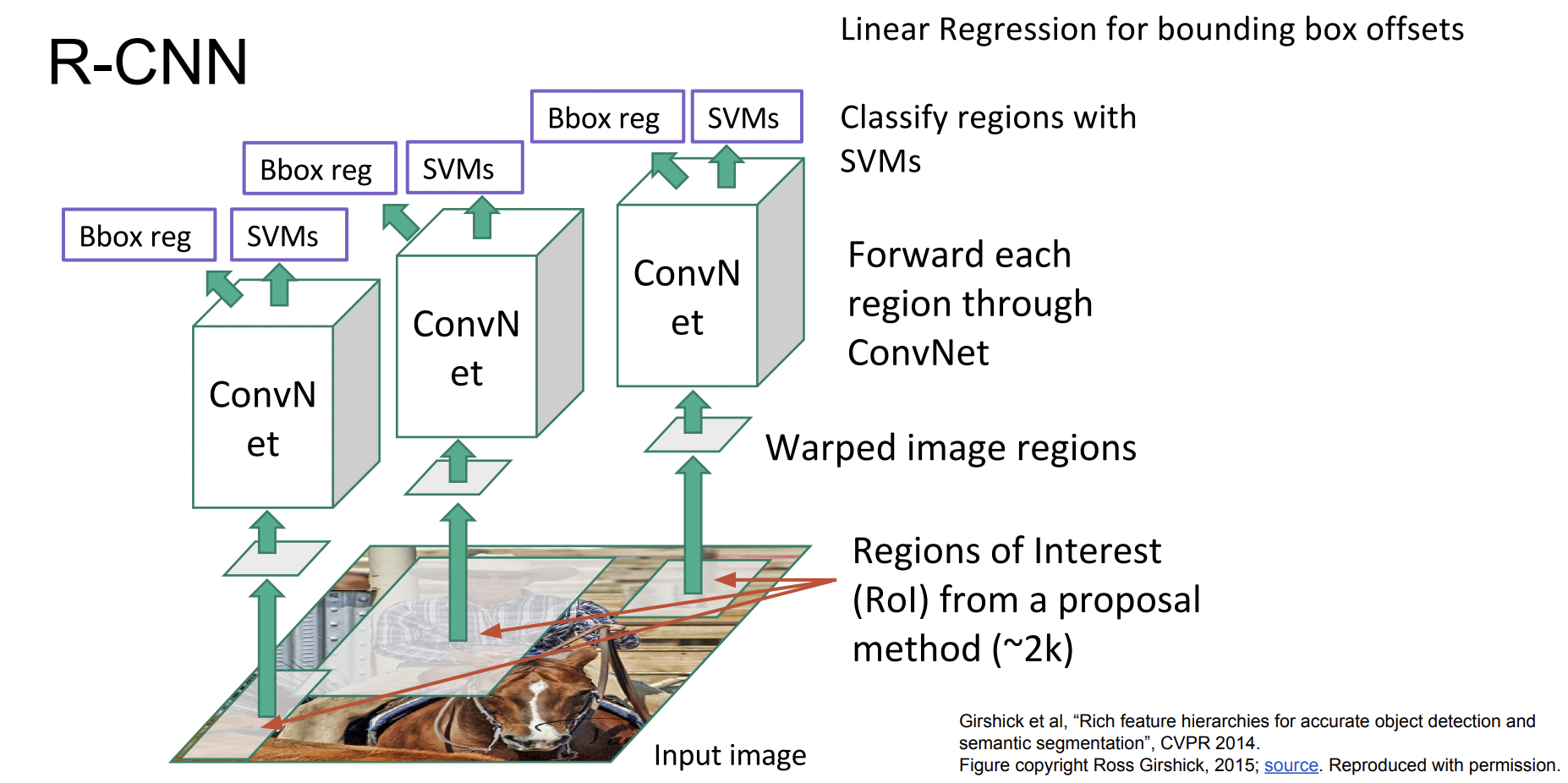
먼저 영역을 추출하고, CNN에 통과시키기 위해 input size를 조절한 후 CNN을 통과시키고 SVM을 통해 classification 과정을 거친다. 마지막으로 linear regression을 이용해 Bounding box의 loss도 계산하여 두 loss가 최소가 되는 방향으로 train시킨다.
그러나 R-CNN은 초창기 모델이기 때문에 단점이 존재한다.
- 계산 비용이 많이 든다
- Supervised 학습이기 때문에 모든 객체의 bbox가 있어야 train이 가능하다
- 속도가 느리다
이러한 단점을 보완하여 등장한 것이 바로 Fast R-CNN이다.
Fast R-CNN
속도가 느린 이유를 각각의 region마다 모두 CNN을 진행했기 때문이라고 생각하고 단 한 번의 CNN 과정만 거친다.
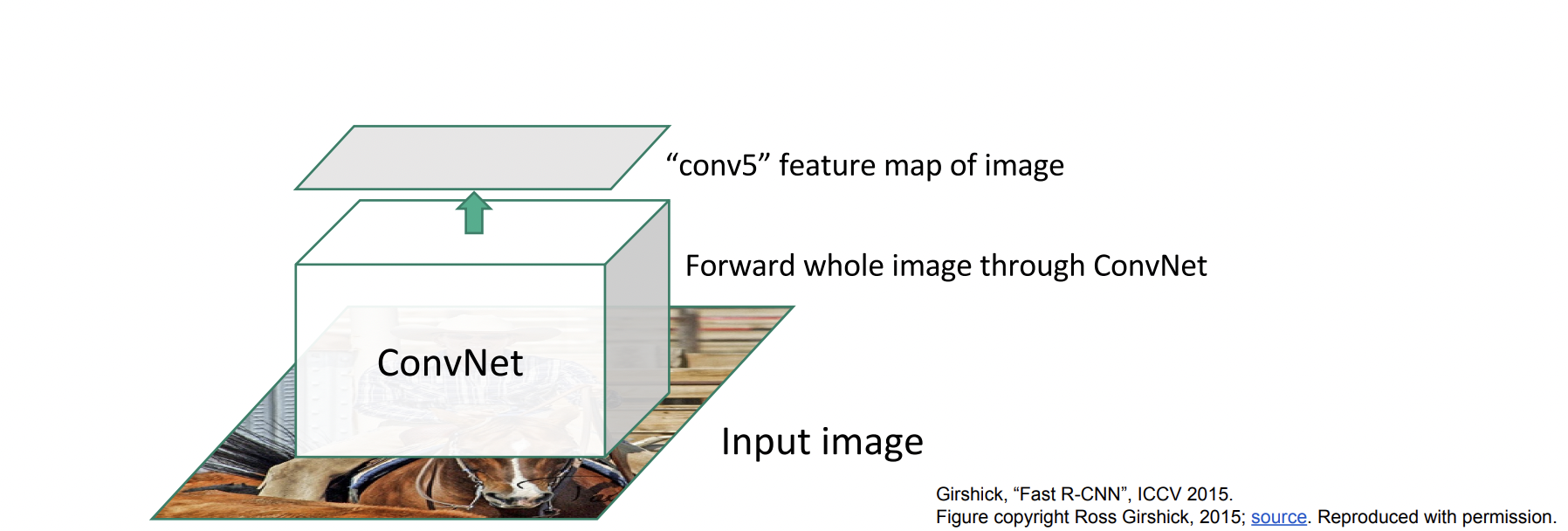
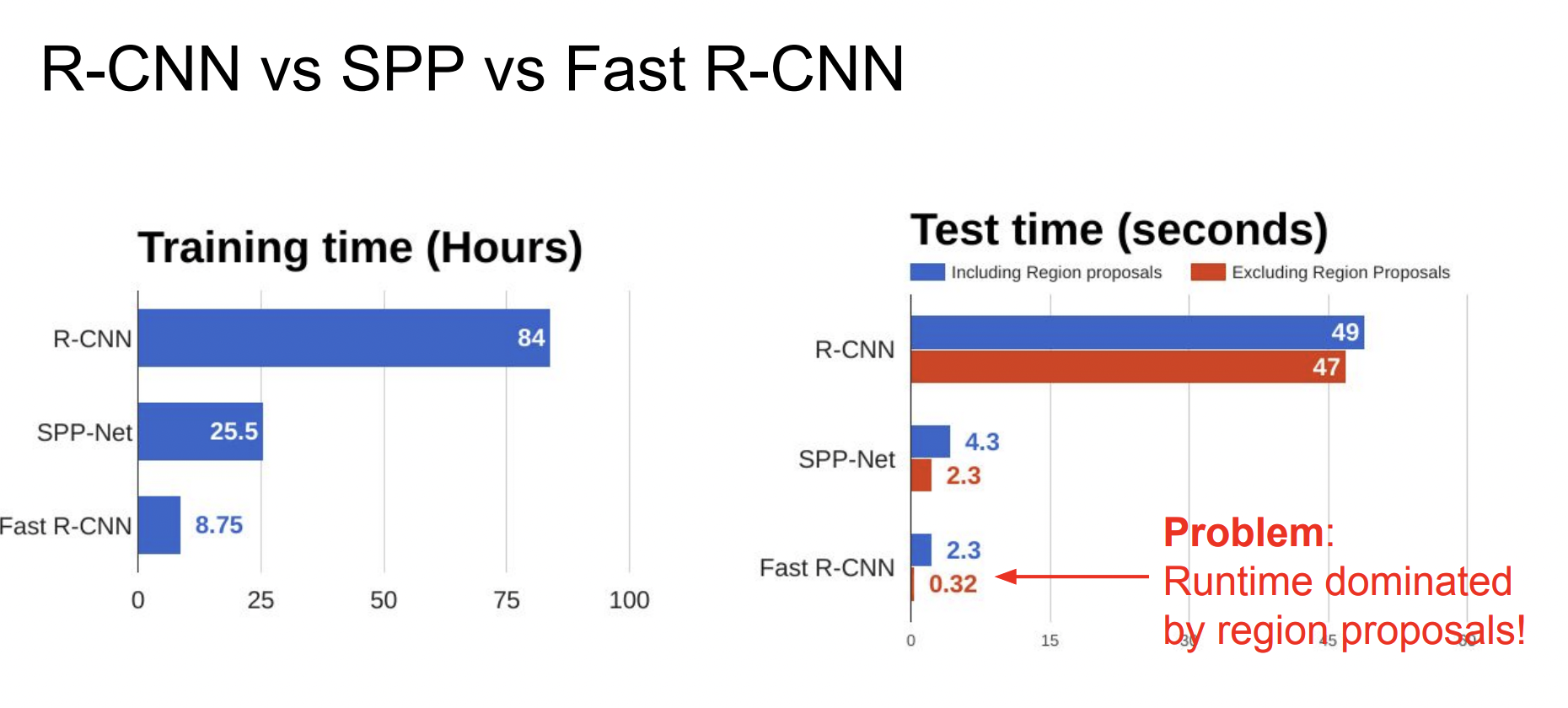
train/test time이 확실히 줄어든 것을 볼 수 있다. 하지만 region proposal을 계산하는 데 시간이 오래 걸리기 때문에 병목현상이 발생한다. 그래서 이 region proposal 또한 딥러닝으로 수행하는 방법이 바로 Faster R-CNN이다.
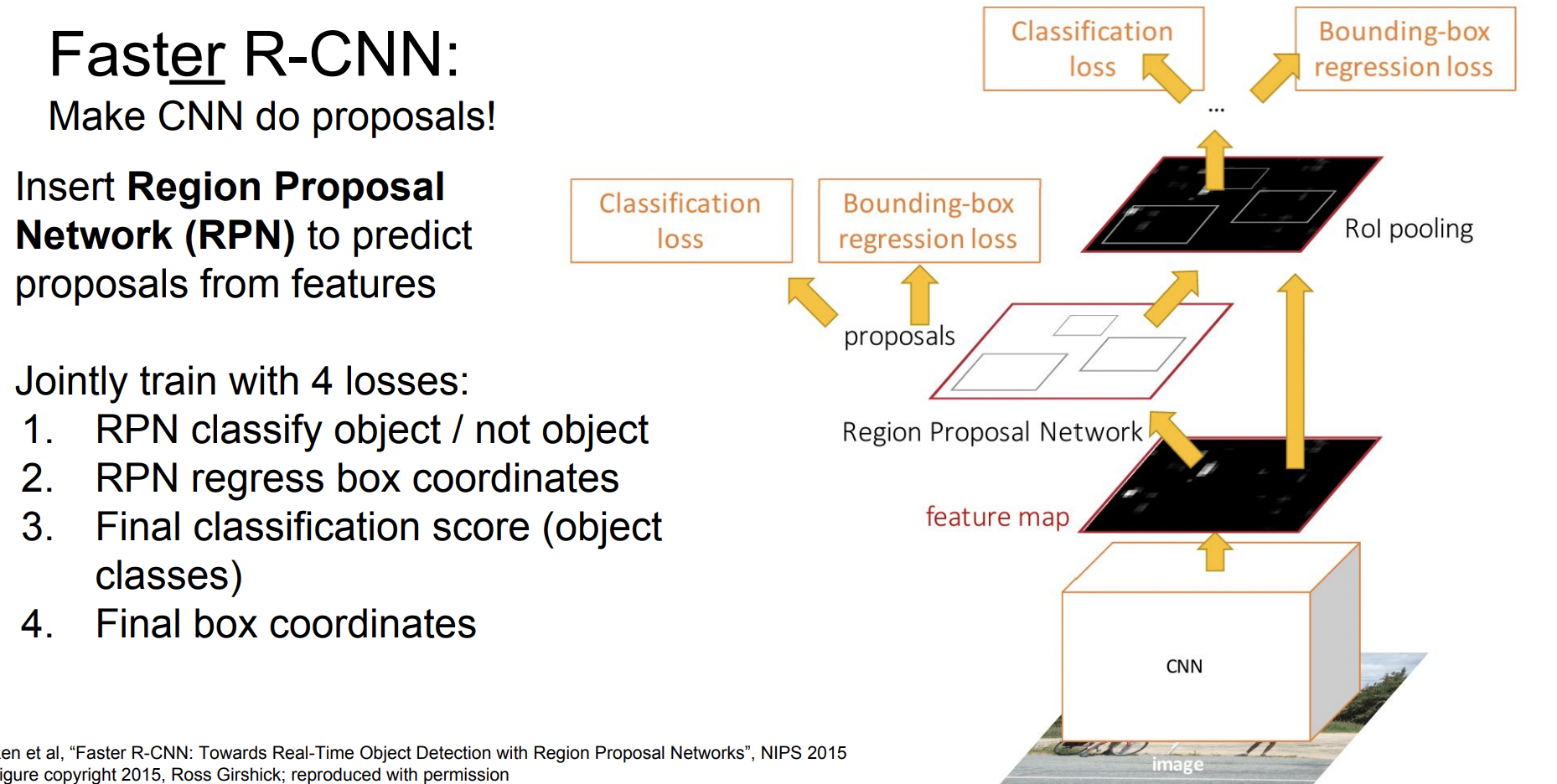
Faster R-CNN
Faster R-CNN에서는 이미지가 입력으로 들어오면 전체 CNN을 통해 feature map을 뽑아낸 뒤 계산한다. 따라서 4개의 loss가 한번에 계산된다.
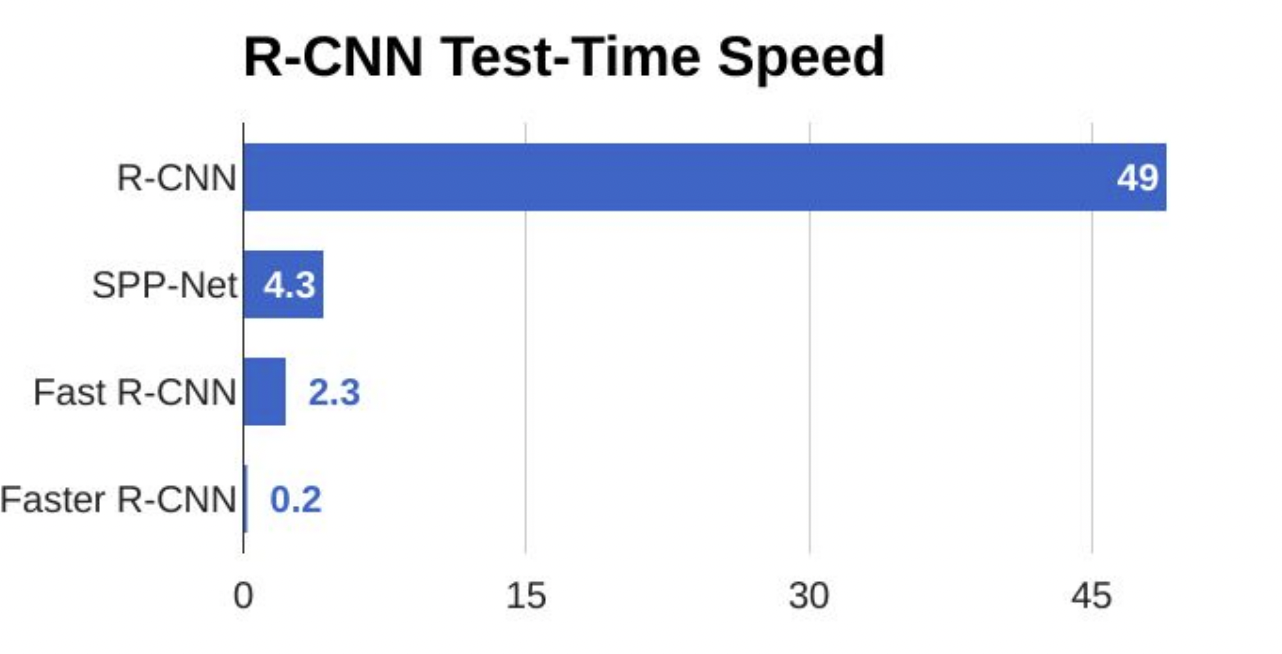
speed를 비교하면 확실히 빨라진 것을 알 수 있다.
Mask R-CNN
Mark R-CNN은 image segmentation을 수행하기 위해 고안된 모델이다. 하지만 구조 자체는 Faster R-CNN에서 upgrade된 구조이다. 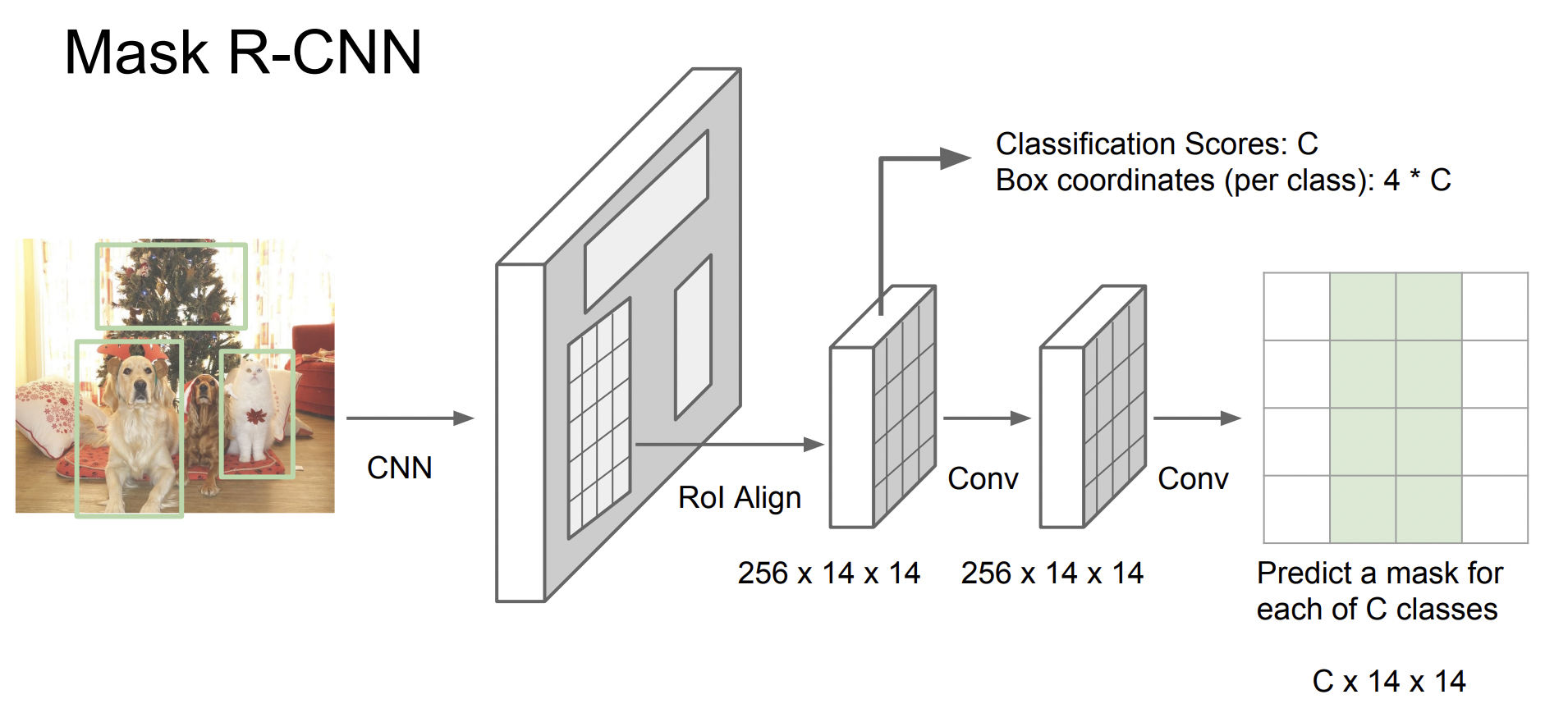
YOLO / SSD
1-stage detector는 크게 두 종류로 나뉘는데, YOLO와 SSD이다. 하지만 이 강의에서는 굉장히 간단하게 설명하고 넘어갔다.
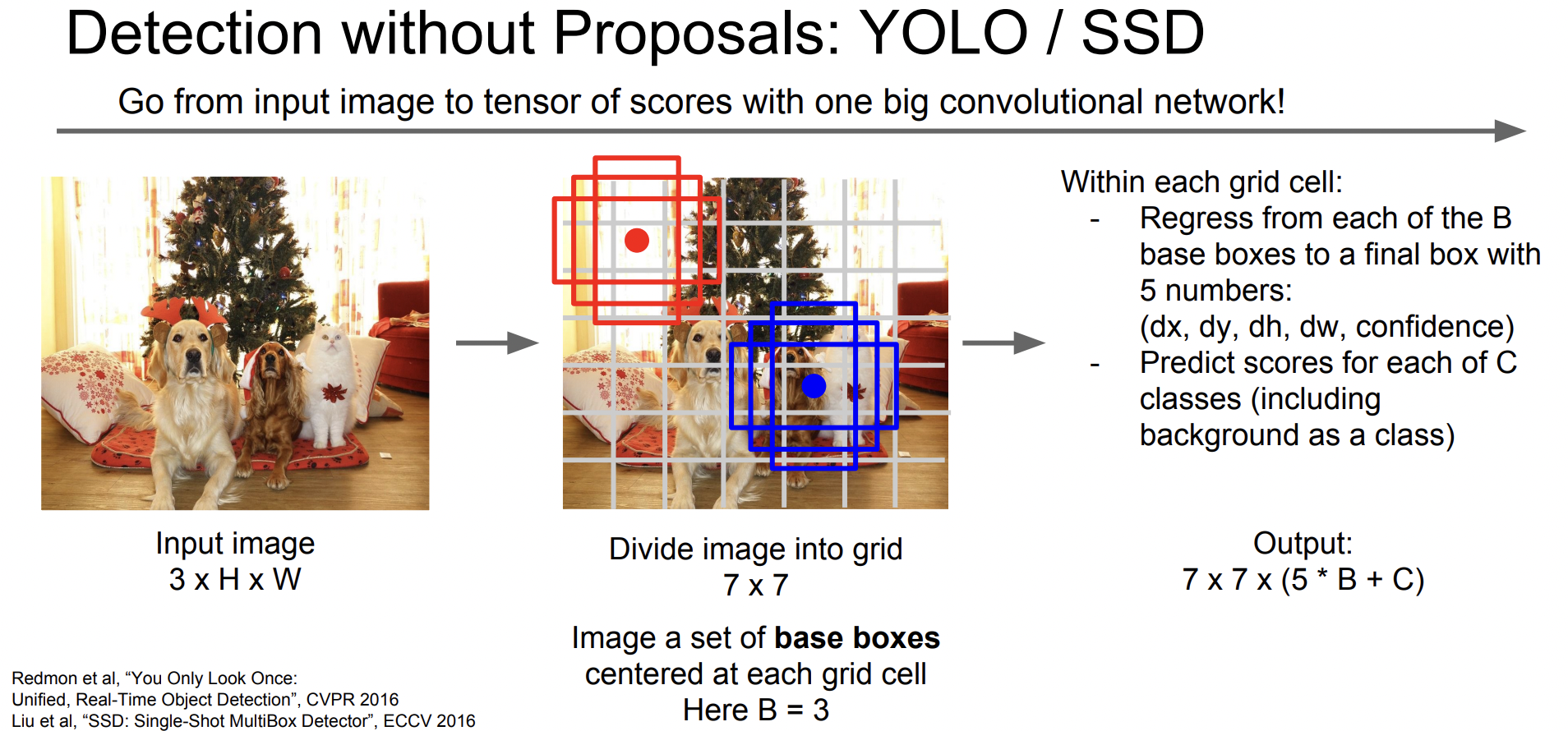
이 네트워크들은 Feed forward를 한 방향으로 수행하는 네트워크이다. 각 task를 따로 계산하지 않고 하나의 Regression 문제로 풀어보자는 것이다. 출력은 3d를 가지는 Tensor가 된다.
YOLO는 이미지의 grid를 나눌 때 7 x 7로 고정을 한 뒤 bbox를 찾지만 SSD의 경우 여러 feature map을 참고하여 세분화하여 grid를 나눈다는 차이점이 있다.
