What's going on inside ConvNets?
ConvNet 안에서 일어나는 일들을 Visualizing하는 것이 중요한 이유는 딥러닝이 잘 작동하는 이유를 시각화해서 설명하고 납득시키기 위해서이다.

딥러닝 내부의 첫 번째 layer는 입력 이미지와 필터의 Weight 값을 내적하여 만든 layer이다. 따라서 우리의 눈으로 보았을 때 edge 성분이 많이 검출되는 것을 확인할 수 있다.
이제 이 필터들이 layer가 깊어지면서 합성곱 연산이 이루어지고 더 복잡해진다. 따라서 깊은 layer의 필터는 우리가 직관적으로 이해하기는 어려운 필터들이 된다.

Last layer에서는 한 이미지에 4096차원의 특징 벡터들이 존재한다. 따라서 각 이미지마다 특징 벡터들을 Nerest Neighbor 알고리즘을 돌리게 되면 유사한 이미지가 검출되는 것을 확인할 수 있다.

이 4096차원의 특징 벡터를 PCA 알고리즘 등으로 2차원으로 차원 축소를 하게 되면 군집화 된 모습을 볼 수 있다. 아까 중간의 깊은 layer들은 우리가 직관적으로 이해하기 어렵다고 했지만 모든 layer가 그런 것은 아니다. Activation map을 통과시킨 layer의 모습을 시각화하면 이처럼 사람의 얼굴 부분이 활성화된 layer가 있다는 것을 확인할 수 있다.
지금까지 살펴본 이미지는 모두 고정적인 1개의 이미지였다. 그렇다면 general한 이미지가 들어왔을 때에는 어떤 이미지가 들어와야 각 뉴런의 활성화가 최대치가 될까? 이러한 방법으로 Visualization한 방법을 Maximally Activation Patches라고 한다.

또 다른 방법으로는 Occlusion Experiments라는 방법이 있는데, 이는 입력의 어떤 부분이 Classification을 결정했는지 알아보기 위해 사용한 방법이다. 입력 이미지의 일부분을 가린 후 분류를 잘 하는지 확인하는 것인데, 만약 이미지를 가렸는데 네트워크 score에 변화가 있다면 네트워크는 그 부분을 분류하는 데 크게 영향을 미치는 요소로 판단했다고 볼 수 있다.

마지막으로 Saliency map이라는 방법도 있는데, 이는 어떤 픽셀을 보고 이미지를 분류했는지 알아내는 방법이다. 이 방법을 가지고 segmentation을 진행할 수도 있지만 성능이 좋지 않다.

Gradient Ascent
우리는 Gradient를 구할 때 Backpropagation 방법으로 구하는 경우가 많았다. 이것의 이는 입력 이미지가 들어왔을 때 Weight 값을 업데이트시키기 위해 사용했던 방법인데 이것의 반대 개념이 Gradient Ascent이다. 네트워크의 weight값은 고정시키고 해당 뉴런을 활성화시키는 General한 입력 이미지를 찾아내는 방법이다.
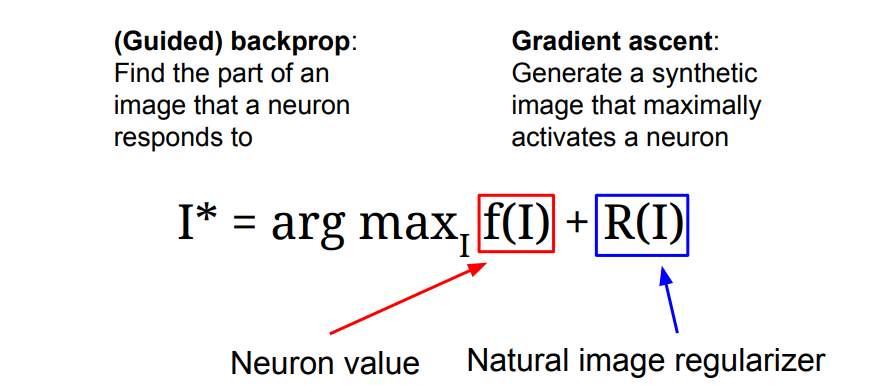
이 식에서 만들어진 I*가 이미지의 픽셀 값을 나타낸다.
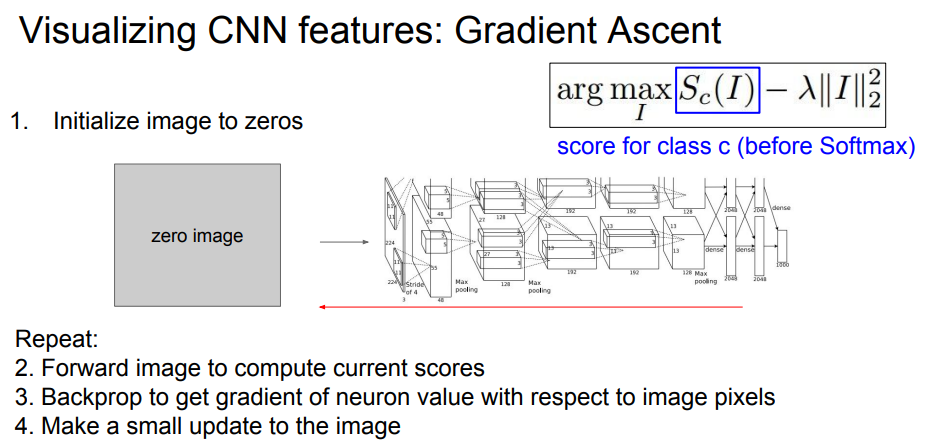
과정을 살펴보면
- 이미지를 0으로 초기화한다.
- 이미지의 현재 score를 계산한다.
- backpropagation을 통해 현재 gradient를 구한다.
- 이미지를 pixel 단위로 업데이트한다.

이것이 gradient ascent를 진행한 이후의 이미지이다.
Feature Inversion
이 개념 또한 네트워크의 다양한 layer에서 어떤 요소들을 포착하고 있는지 알아볼 수 있는 방법이다. 이미지의 특정 layer에서 activation map을 추출한 다음 이 activation map을 가지고 이미지를 재구성하는 방법이다.
여기서 gradient ascent를 이용하는데, 스코어를 최대화하지 않고 특징 벡터의 거리가 최소화되는 방향으로 update를 진행한다.

이것은 feature inversion을 진행한 이후의 이미지이다. 깊은 layer로 갈수록 색이나 텍스처 등 의미론적 정보만 가지고 이미지를 재구성하는 것을 확인할 수 있다.

Texture Synthesis
texture 합성 문제는 컴퓨터 그래픽스 분야에서는 아주 오래된 문제이다. 예를 들어 아래 사진과 같은 조그만 패치가 있을 때 비슷한 패턴을 가진 더 큰 패치를 생성하는 문제가 있다.

가장 클래식한 방법은 Nearest Neighbor를 이용한 방법으로, 신경망을 사용하지 않는다. scan line을 따라서 한 픽셀씩 이미지를 생성해 나가는데, 입력 패치에서 가장 가까운 픽셀을 복사해서 넣는 방법이다.
하지만 복잡한 texture에서는 이러한 방법이 잘 동작하지 않는다. 따라서 등장한 것이 신경망을 이용한 시도이다.
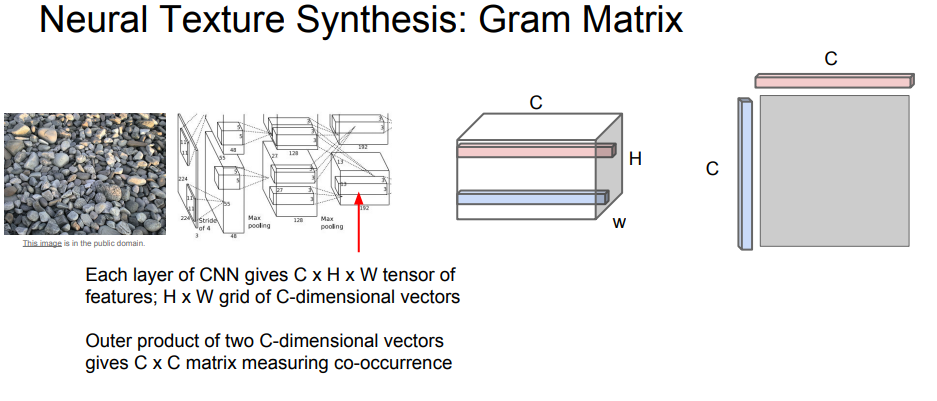
이 방법은 Gram Matrix라는 개념을 사용하는데, 특정 layer에서 activation map을 가져온 뒤 서로 다른 공간 정보에 있는 channel을 외적하여 새로운 matrix를 만드는 방법이다.
Gram matrix는 이미지의 각 지점에 해당하는 값을 모두 평균화시켰기 때문에, 공간 정보를 날려버린 대신 co-occurence만을 포착해 낸다.
공분산 행렬을 사용할 수도 있지만, 계산 비용이 너무 크기 때문에 gram matrix를 이용한다.
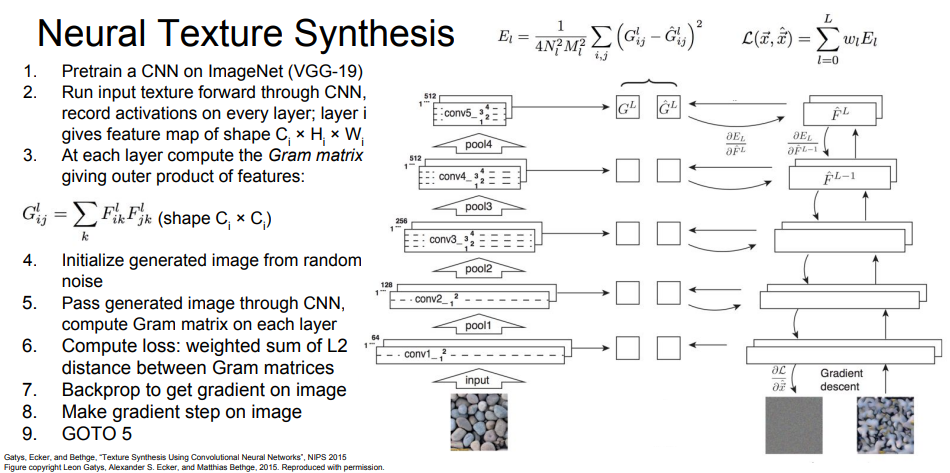
이미지를 생성하는 과정은 다음과 같다.

결과는 얕은 layer에서는 공간적인 구조를 잘 살리지 못하지만 layer가 깊어질수록 공간 정보를 잘 나타냈다는 것을 확인할 수 있다.
Neural Style Transfer
마지막으로 이러한 texture synthesis와 feature inversion을 조합한 아이디어가 Neural Style Transfer이다. Style Transfer에서는 입력이 두 가지이다.
- Content Image : 이미지가 어떻게 생겼으면 좋겠는지를 나타냄
- Style Image : texture가 어땠으면 좋겠는지를 나타냄

최종 이미지는 Content Image의 feature reconstruction loss도 최소화하고 Style Image의 gram matrix loss도 최소화하는 방식으로 생성해 낸다.
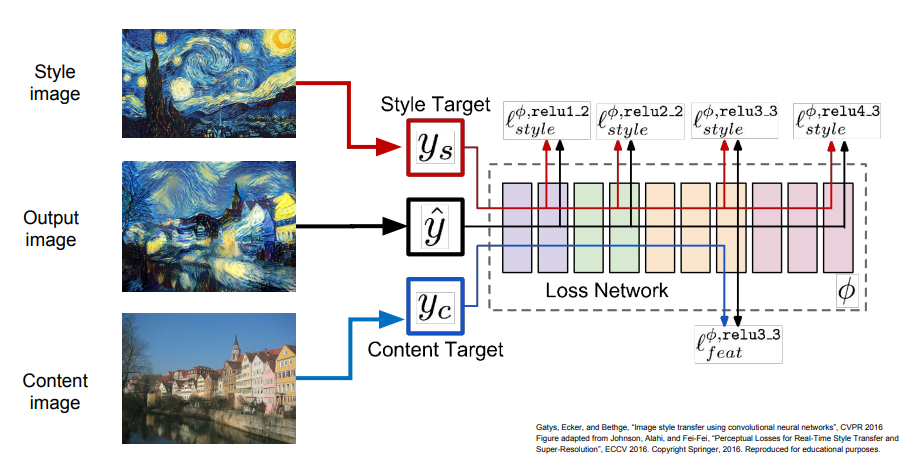
하지만 많은 forward/backword 연산을 반복해야 하기 때문에 화질이 높을수록 메모리와 계산량이 엄청나게 크다.
따라서 이러한 문제를 해결하기 위한 네트워크 학습 방식이 등장했다.
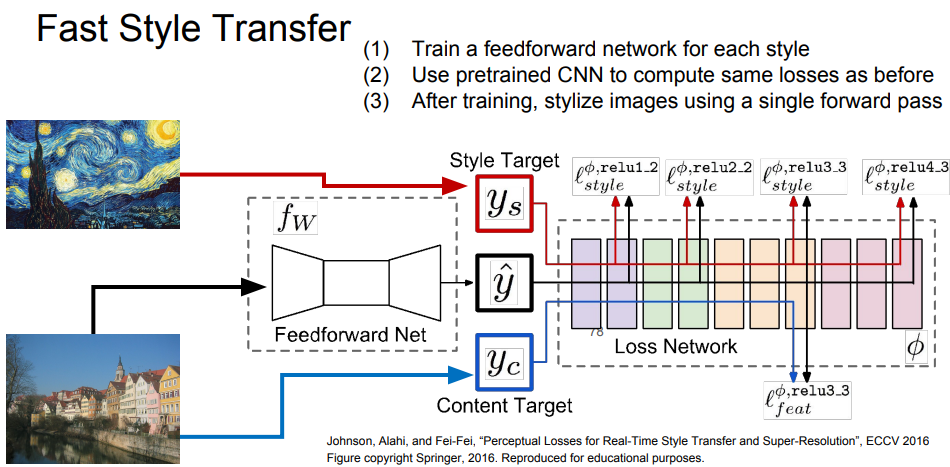
이 방법은 합성하고자 하는 이미지의 최적화를 전부 수행하지 않고 Content Image만을 입력으로 받아서 결과를 출력할 수 있는 단일 네트워크를 학습시킨다.
학습 시에는 Content loss와 style loss를 동시에 학습시키고 네트워크의 가중치를 업데이트한다.
학습 시간은 오래 걸리지만 한 번 학습시키고 나면 이미지를 통과시킨 결과가 바로 나온다.
