Unsupervised Learning
지금까지 배운 것은 Supervised Learning에 대해 주로 배웠다.
- Classification
- Regression
- Object detection
- semantic segmentation
- image captioning
등이 있다.
그렇다면 Unsupervised Learning은 data가 라벨 없이 주어져 있을 때, 데이터의 숨어있는 기본적인 구조를 학습하는 것을 목표로 학습하는 방법이다.
- clustering
- dimensionality reduction
- feature learning
- density estimation
등이 있다.

사진은 Unsupervised Learning의 한 예시인 Clustering이다.
Generative Models
Generative model은 한국어로 생성 모델이라고 하며, data를 입력했을 때 동일한 분포에서 새로운 샘플들을 생성하는 것을 말한다. 생성 모델도 unsupervised learning에 속하는데, density estimation(분포 추정)을 하는 것이 핵심 과제이다. 분포 추정 방법은 크게 두 가지가 있다.
- Explicit density estimation : 생성 모델을 명시적으로 나타내 주는 방법
- Implicit density estimation : 생성 모델을 정의하지 않고 sample을 얻는 방법
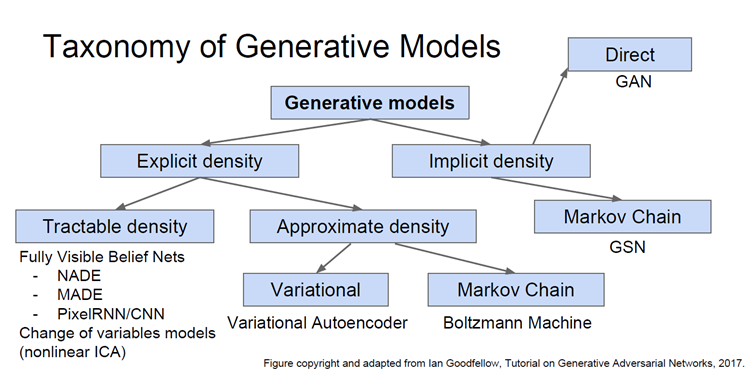
위 사진은 generative model의 종류를 나타낸다.
오늘 강의에서는 generative model 중 PixelRNN/CNN, Variational Autoencoder, GAN에 대해 설명한다.
PixelRNN/CNN
pixelRNN/CNN은 explicit density estimation 중 계산 가능한 density Tractable density를 다루는 방법이다.
Explicit density model을 만들기 위해, chain rule을 이용해 이미지를 1차원 분포들 간 곱의 형태로 분해한다.

그렇다면 이전 pixel들을 어떻게 정의할까? 이전 pixel을 정의할 때 RNN을 사용하는 방법이 바로 PixelRNN이다.
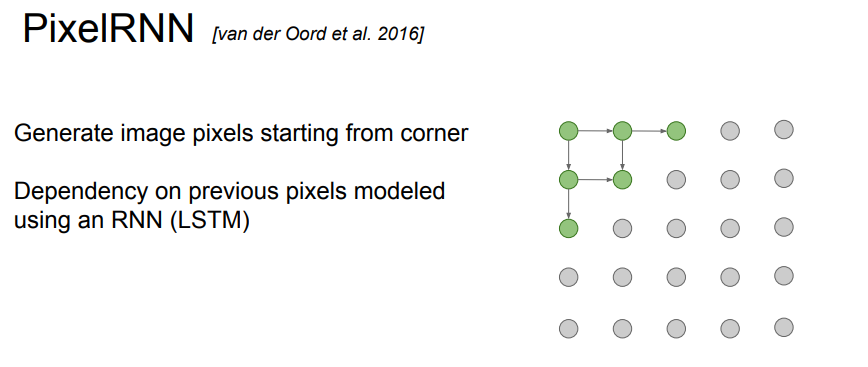
RNN 중 LSTM을 사용하여 모델링을 한다.
하지만 순차적으로 픽셀을 생성하기 때문에 속도가 느리다는 단점이 있다. 이러한 단점을 해결하기 위해 나온 것이 PixelCNN이다.
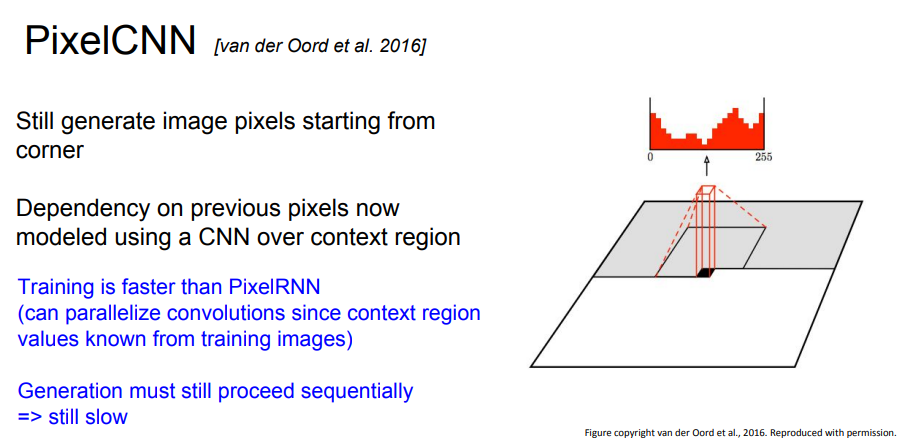
기본적인 세팅 자체는 PixelRNN과 동일하지만 pixelCNN은 모델링을 할 때 특정 픽셀만 고려하는 CNN을 사용한다.
그림의 회색 영역이 이미 생성된 픽셀인데, 이 중에서도 특정 영역을 사용하여 다른 픽셀 값을 생성한다.
Variational Autoencoders (VAE)
VAE는 계산이 불가능한(intractable) 확률 모델을 정의한다. 따라서 lower bound를 구해서 계산 가능한 형태로 만들어 준다.

z는 잠재 변수latent variable 라고 하는데 앞으로 더 자세히 다룰 것이라고 한다.
이제 Autoencoders에 대해 알아볼 것이다. AE라고도 하는데, 이는 데이터 생성이 목적이 아닌 레이블되지 않은 학습 데이터로부터 저차원의 feature reperesentation을 학습하기 위한 방법이다.
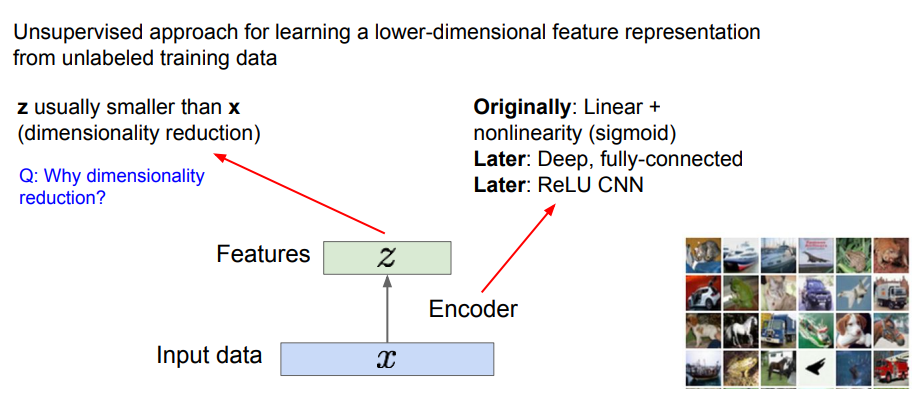
사진을 보면 입력 데이터 x가 있고, 어떤 특징 z를 학습하기를 원한다. 여기서 encoder는 입력 데이터 x를 특징 z로 변환하는 매핑 함수의 역할을 한다. 다양한 방법으로 설계할 수 있지만 보통은 Neural Network를 사용한다.
encoder의 예시로는
- ReLU, CNN
- Sigmoid
- FC Layer
등이 있다.
특징 벡터 z는 보통 x보다 작다. 이로 인해 차원 축소의 효과를 기대할 수 있다. 그렇다면 어떻게 feature representation을 학습할 수 있을까?
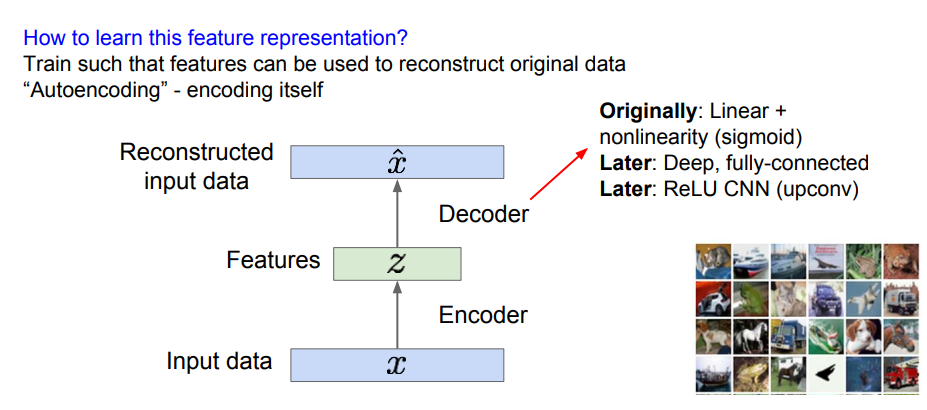
decoder란 특징 벡터 z를 통해 input data처럼 재구성하는 과정을 말한다. encoder의 역과정이라고 생각할 수도 있다.
또한 decoder는 training 과정에서만 쓰이고, 실제로 test를 할 때에는 encoder만 가지고 진행한다.
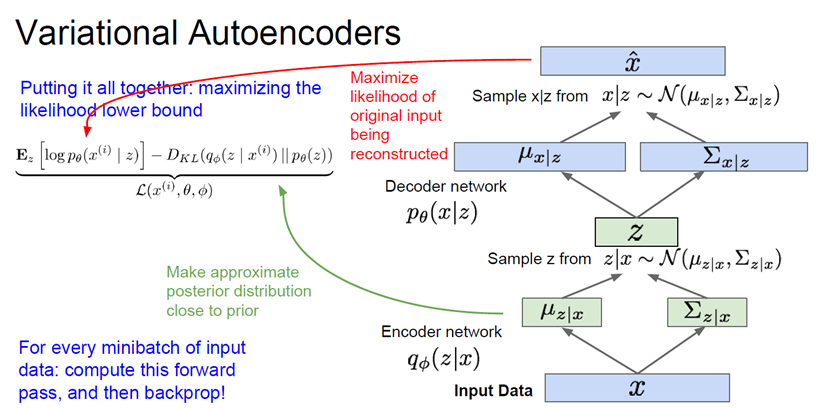
위 사진은 train 과정을 보여준다.

이 방법은 서로 독립되어 있는 변수 z를 통해 여러 가지 이미지를 생성할 수 있지만 blur된다는 단점이 있다.
Generative Adversarial Networks (GAN)
GAN은 확률 분포를 계산하지 않고 단지 sample을 얻어내는 방법을 말한다. 분포가 매우 복잡하기 때문에 직접 sampling을 하는 것은 불가능하다. 따라서 결과만 뽑아내는 것이다. GAN을 구현하기 위해서는 두 가지의 Network가 필요하다.
- Generator Network : discriminator를 속여 가짜 이미지를 만드는 것이 목적
- Discriminator Network : 진짜와 가짜 이미지를 구별하는 것이 목적
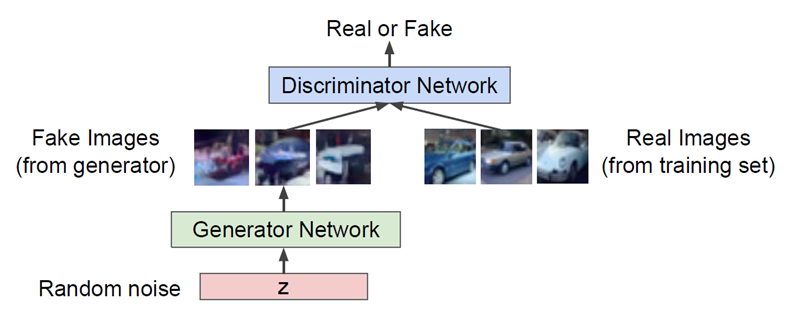
이렇게 generator와 discriminator를 번갈아 가며 학습한다.

GAN을 통해 만든 결과 sample이다.

