의사결정트리
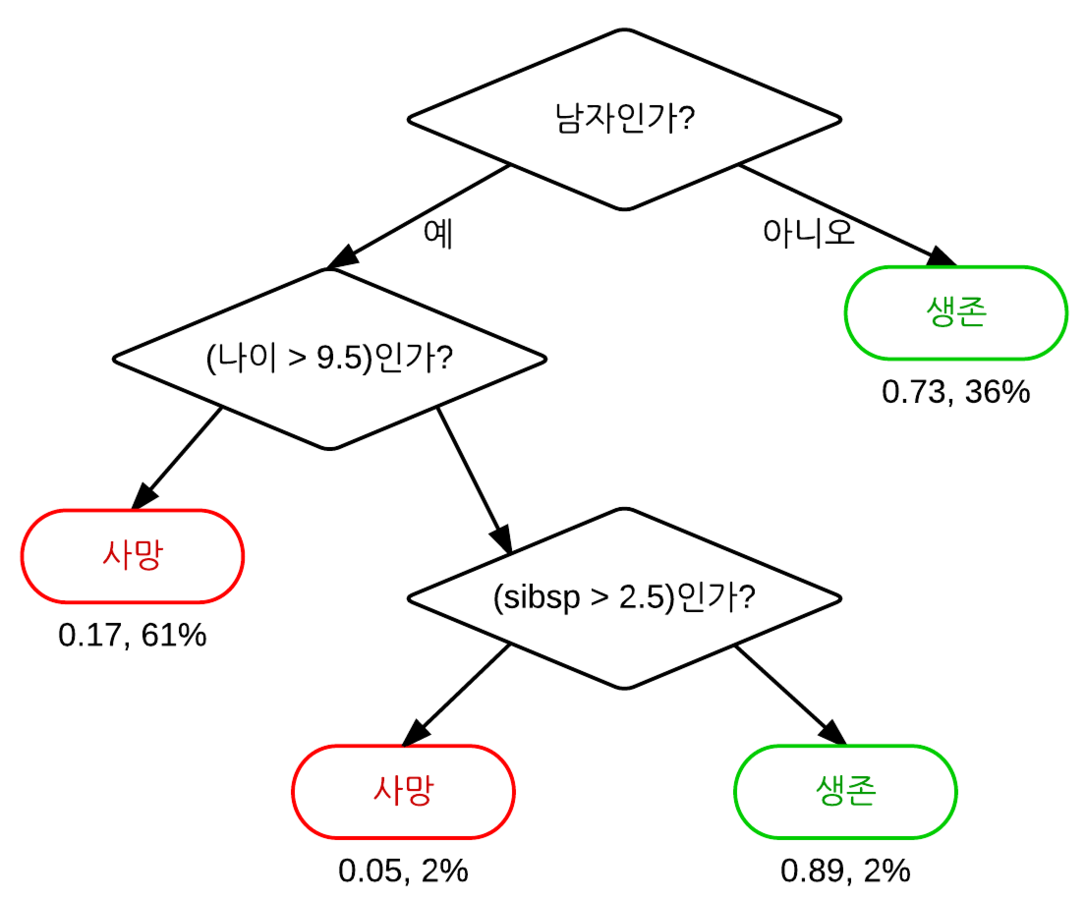
- 루트 노드, 분기, 내부 노드 및 리프 노드로 구성된 트리 구조
- 들어오는 분기없이 루트 노드로 부터 시작.
- 데이터를 잘 나누는 질문일수록 상위 노드에 존재한다.
- 일반적으로 CART(Classification and Regression Tree) 알고리즘을 통해 훈련된다.
장점
- 시각적으로 잘 표현되기 때문에 해석하기가 쉽다.
- 분류/회귀에 모두 사용될 수 있다.
단점
-
트리의 규모가 커질수록 과적합될 확률이 높아 새로운 데이터 셋에는 일반화가 잘 되지 않는다.
사전 가지치기(데이터 부족할 때 트리 성장 멈춤)와 사후 가지치기(데이터가 부족한 하위 트리 제거)를 통해 보완
-
훈련 비용이 다른 알고리즘에 비해 많이 든다.
-
사이킷런에서 범주형 변수 관련해서는 지원하지 않는다.
랜덤 포레스트
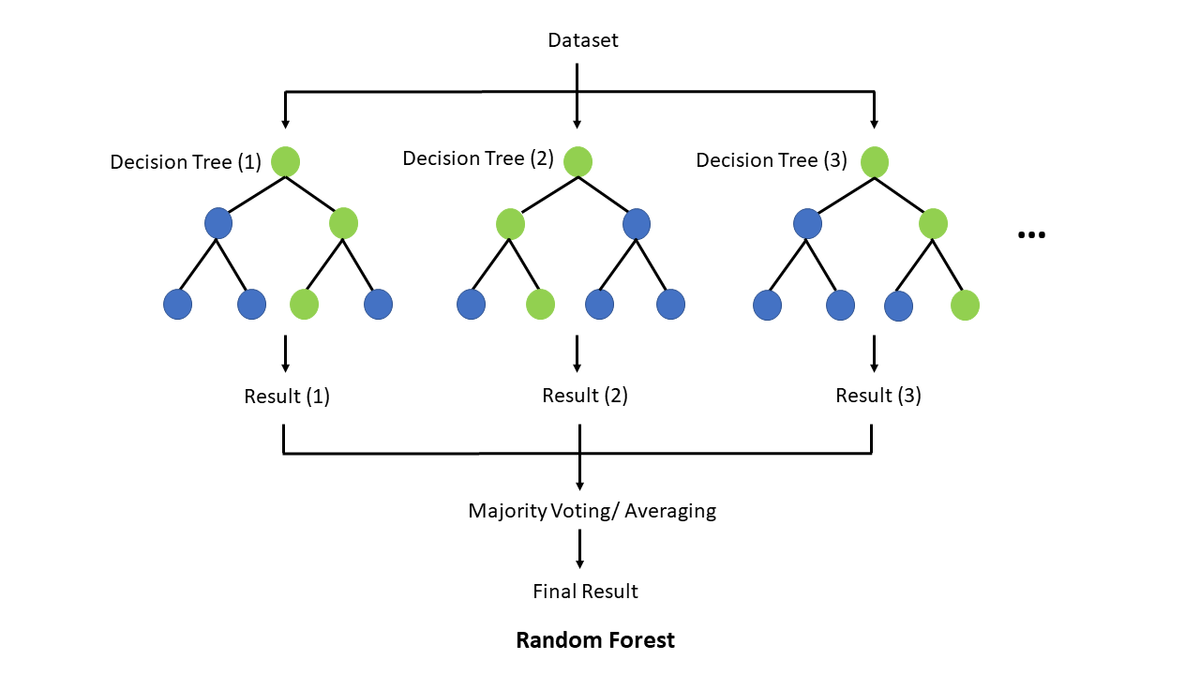
- 의사결정나무를 만들 때 사용되는 여러 변수들을 무작위로 선정하여 여러 개를 만든다. 이 때 각 나무끼리는 낮은 상관관계를 가진다.
작동 방식
- 훈련 전 노드 크기, 트리 개수, 샘플링된 변수(특징)의 개수를 설정해줘야한다.
- 각 트리는 부트스트랩 샘플로 훈련된다.
- 각 트리는 랜덤으로 추출된 특징으로 훈련된다. 이로 인해 각 트리는 낮은 상관관계를 가지게 된다.(feature bagging)
- 문제 유형에 따라 예측 결정 방법이 달라짐.
- 회귀: 개별 결정트리의 결과값의 평균으로 예측됨.
- 분류: 최빈 범주 변수로 예측됨.
- 훈련 데이터 셋의 은 테스트 데이터로 분류하는데 이를 oob(out-of-bag)샘플이라고 한다. 이 oob샘플로 교차 검증을 실시하고 예측을 완료한다.
장점
- 과적합의 위험이 감소됨.
- 회귀/분류 문제를 높은 정확도로 처리 가능함.
- 특성 중요도를 평가하기 쉽다.
단점
- 대규모 데이터에 대해 정확한 예측을 제공하지만 그만큼 데이터 처리 속도가 느리다.
- 대규모 데이터 처리를 위해 그만큼 많은 리소스를 필요로 한다.

배움을 기록하는 습관 들이기
좋은 정보 얻어갑니다, 감사합니다.