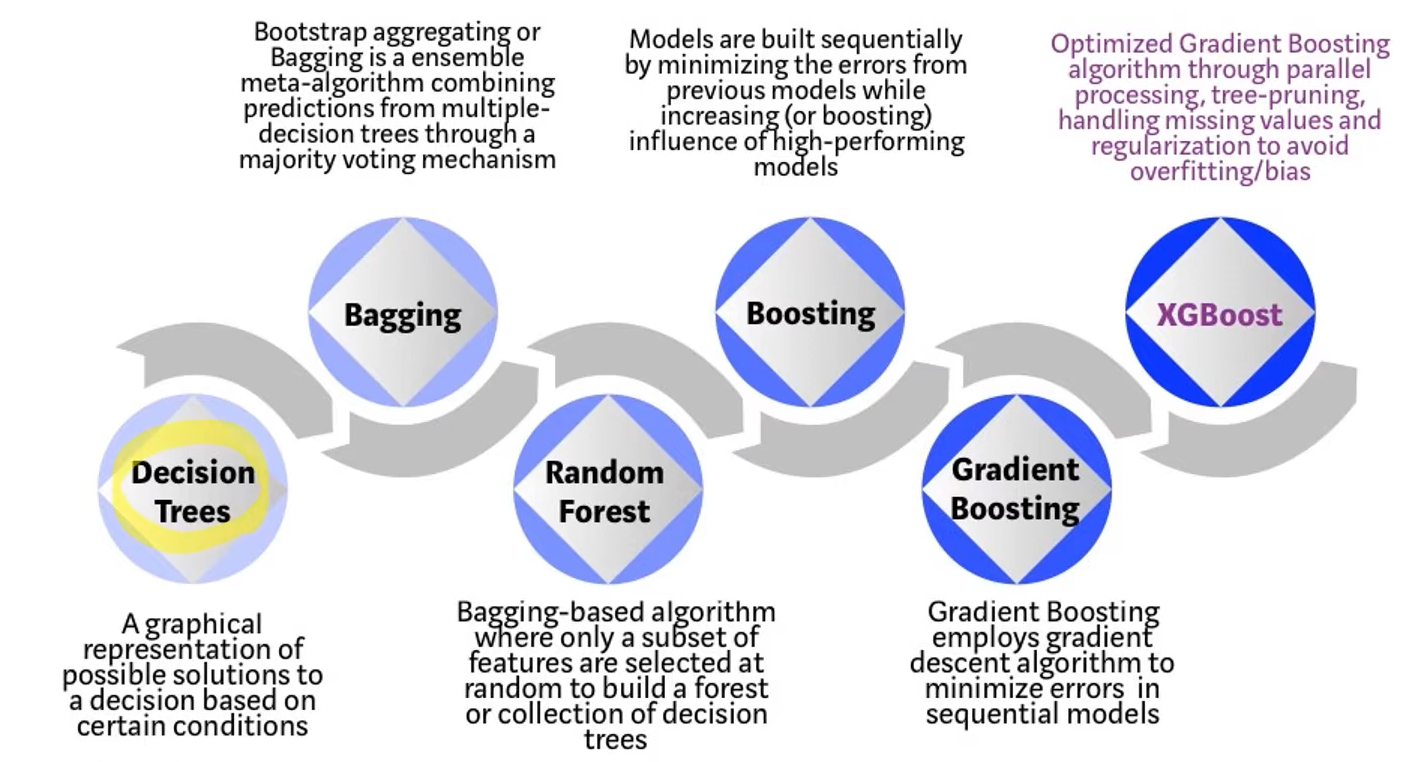
XGBoost
어떻게 하면 GBM을 더 빠르게 처리하고, 더 큰 데이터 셋에 효율적으로 적용시킬 수 있을까? 라는 생각에서 시작함.
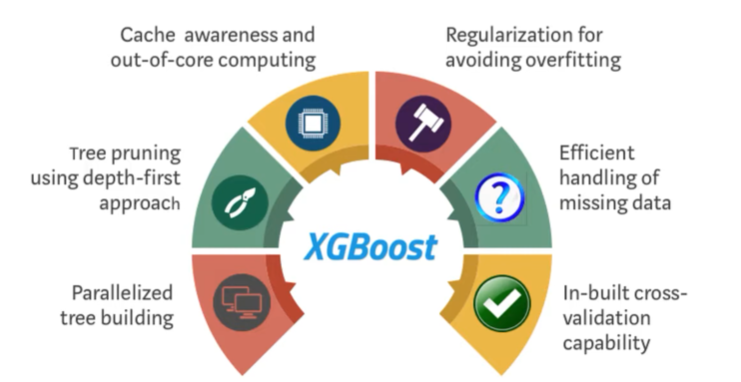
GBM과 비교해 다음과 같은 특징을 보임.
- 과적합과 편향을 피하기 위한 정규화가 이뤄짐.
- 병렬 처리 기법
- 가지 치기
- 결측치 핸들링 등
다음은 XGBoost의 큰 기능을 시각화한 것이다.
알고리즘적 관점
Split Finding Algorithm(데이터 포인트를 나누는 알고리즘)
-
Exact greedy algorithm
XGBoost는 학습기로 의사결정나무를 사용한다. 의사결정나무는 모든 split point(가장 최적으로 나눠주는)를 전수조사하게 된다.-
장점
- 이론 상으로 전수 조사를 하기 때문에 반드시 최적해를 찾는 것이 가능하다.
-
단점
- 전수조사를 하므로 메모리 등 굉장히 많은 리소스를 필요로 한다.(= 부족하면 못함. =최적해 못 찾음)
- 분산 환경에서 실행 불가능하다.
-
-
approximate algorithm
- 위의 알고리즘을 최적화시켜주는 알고리즘.
split finding algorithm을 통해 best split을 찾는데 다음과 같은 이득을 볼 수 있다.

40개의 데이터 포인트에 대해 순차적으로 하나하나 gradient를 계산하며 최적인 split point를 찾았다면 39번의 비교를 했어야한다. 그러나 빨간 줄로 나뉜(for bucket) 데이터 그룹을 기준으로 계산을 했다면 총 10개의 bucket에서 3번의 비교만 한다면 최적 split point를 발견할 수 있다.
40 vs 3 x 10(병렬 계산 가능)의 차이다.
Sparsity-Aware Split Finding(결측치 처리 알고리즘)
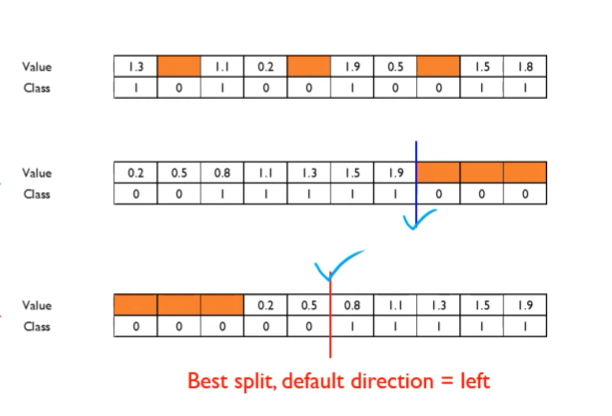
결측치를 양방향으로 보내보면서 split을 해보고 가장 최적의 split point로 분류 후 결측치에 대한 의사결정을 한다.
cache-aware access
CPU계산을 할 때 캐시를 이용해서 데이터 처리 속도를 높임.
머신러닝을 하는데 하드웨어 요소까지 처리한 첫 알고리즘
내용이 너무 깊어서 다 다루지는 못하겠지만 확실한 것은
GBM을 더 빠르게 처리하고, 더 큰 데이터 셋에 효율적으로 적용한다.
나중에 더 앞부분에 대한 지식을 갖춘다면 포스팅을 이어나가야겠다.
