Reference
https://arxiv.org/pdf/2302.13971.pdf
Abstract
- 7B부터 65B의 다양한 크기로 학습을 진행(GPT-3의 175B에 비해 훨씬 작음.)
- 독점적이고 접근 불가능한 데이터셋이 아닌 공공의 데이터를 활용하여 학습
- 심지어 LLaMA-13B은 GPT-3(175B)에 비해 모든 벤치마크에서 성능을 능가한다.
- 또한 LLaMA-65B은 Chinchilla-70B 과 PaLM-540B과 비교했을 때도 성능을 능가한다.
Introduction
- LLM은 거대한 corpora 텍스트 데이터셋을 활용하여 텍스트 지시 또는 몇몇 예시를 통한 새로운 task에서 능력을 보여 준다. -> few-shot learning이 가능한 LLM 모델.
- 또한 이러한 few-shot properties를 LLM이 보여주기 위해서는 충분한 크기의 모델이 필요하다.
- 이러한 생각은 '더 많은 파라미터가 있을 수록 더 좋은 학습 능력을 보여줄 것이다'라는 가설에 따라 근거한다.
- 그러나, 최근 연구를 보면 가장 높은 성능을 보이는 모델이 가장 큰 모델이 아니라, 더 작은 모델을 통해 더 많은 데이터를 학습한 모델이라는 점이다.
- 우리가 궁극적으로 목표하는 것은 추론 비용이 낮은 것이고, 아주 큰 모델에서는 이러한 목표에 도달할 수 없다.
- 그리고 더 큰 모델로 학습하는 것이 비용적으로 적을 수는 있으나, 앞서 말했듯이 추론 비용이 낮은 것이 목표이니 더 작은 모델로 더 많은 데이터를 학습하여 추론 과정에서는 비용이 낮은 것이 더 효율적이다.
- 또한, 10B 모델로 200B 토큰을 학습한 것과 7B 모델에서 1T 토큰을 학습한 것을 비교했을 때 후자가 더 나아지고 있다는 점도 보여진다.
- 학습 데이터는 오픈 소스로 구할 수 있는 데이터만 활용하였다.
Approach
Pre-training Data
- 다양한 도메인을 커버할 수 있는 혼합된 데이터셋을 활용하였다. 데이터셋은 다음과 같다.
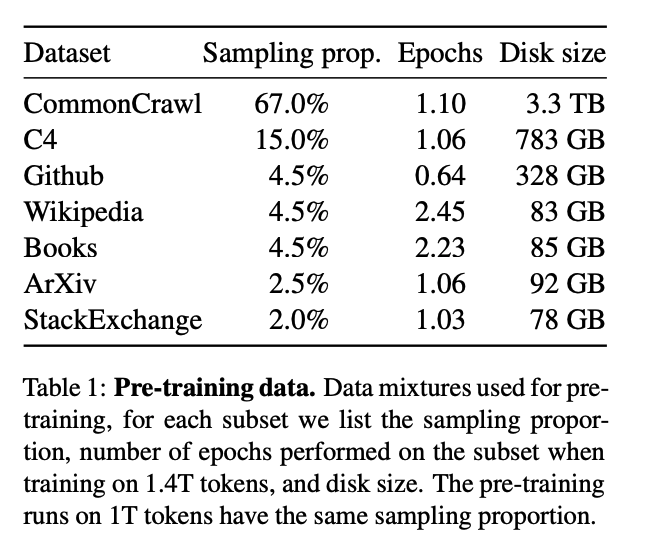
- Tokenizer로는 byte-pair encoding방식을 활용하였다.
Architecture
- 기존 모델과 주요한 차이점은 다음과 같다.
- Pre-normalization
- 학습의 안정성을 높이기 위해, RMSNorm normalizing function을 활용하였다.
- SwiGLU activation function
- ReLU 활성화 함수를 대체하여 사용한다.
- Rotary Embeddings
- 절대적인 positional embedding을 활용하는 것이 아닌, RoPE(rotary positional embedding)을 활용한다.
Main Results
- Zero-shot 과 Few-shot 모두 지원한다.
- 또한 PaLM, GPT-3, Chinchilla 와의 비교 결과는 다음과 같다.
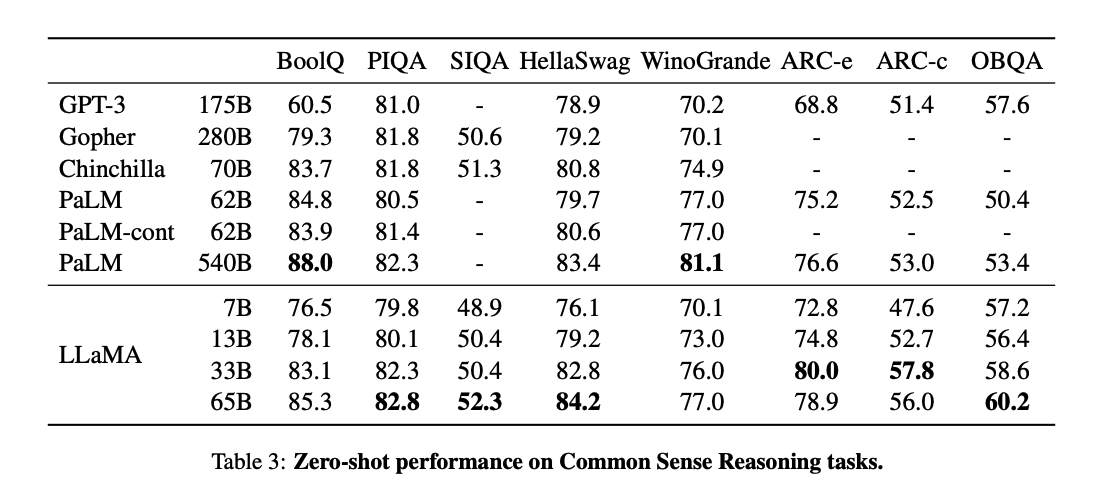
Common Sense Reasoning
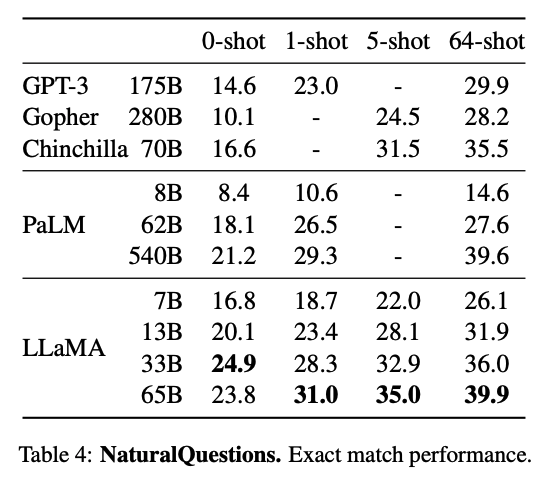
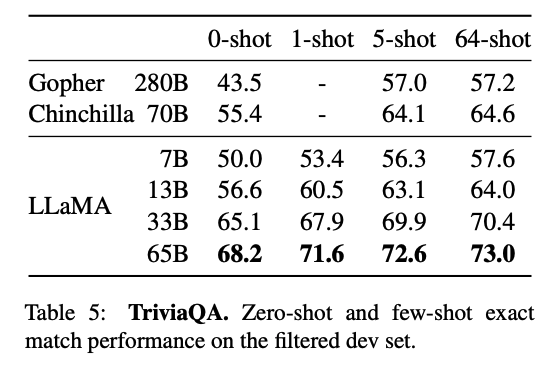
Closed-book Question Answering
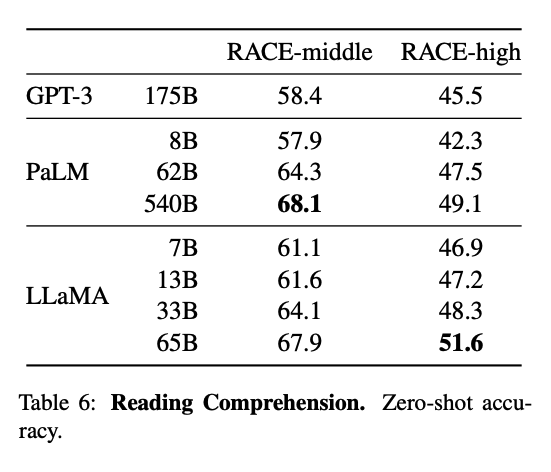
Reading Comprehension
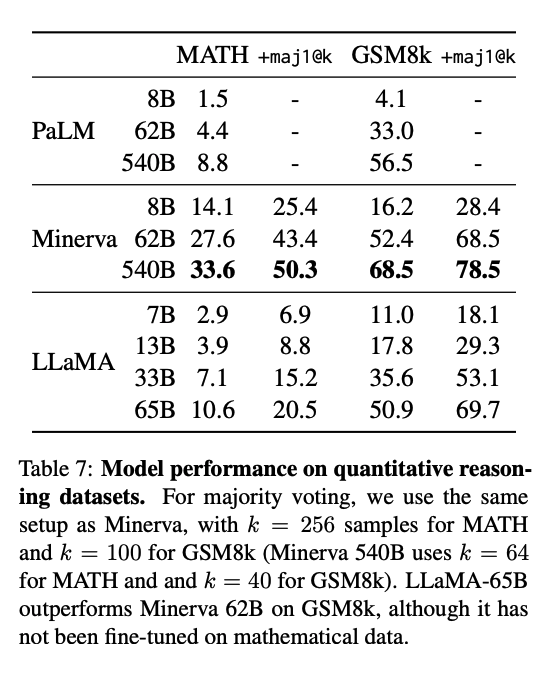
Mathematical reasoning
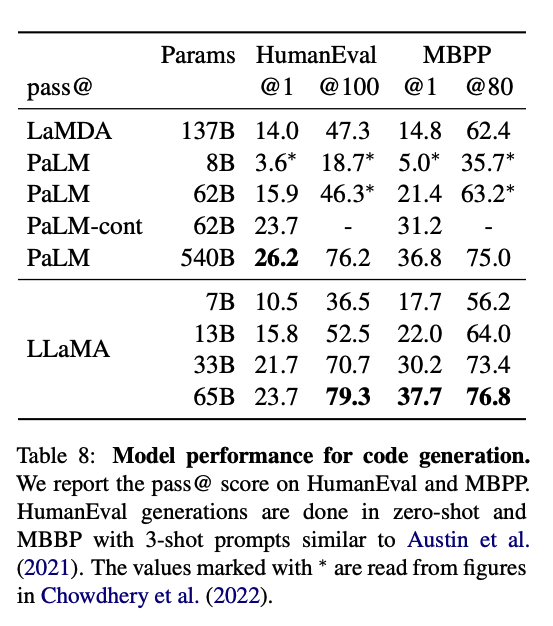
Code generation
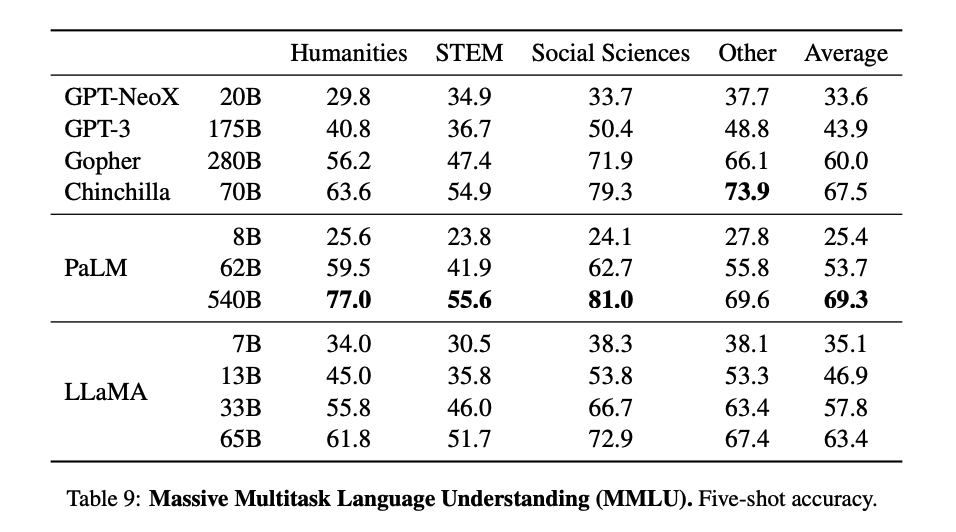
Massive Multitask Language Understanding

매일 매일 한 걸음씩 나아가고자 합니다.