[Paper 리뷰] KOSMOS-2: Grounding Multimodal Large Language Models to the World
목적: 기존에 있던 multimodal 분야의 instruction following, 여러 모달리티 인식, in-context learning을 넘어 더 다양한 multimodal task(referring: 이미지에 있는 어떤 object의 위치도 언급하는 등)를 수행하는 모델을 만들어보자. → KOSMOS-1의 기본적인 multimodal 능력에 더해서 task를 확장하는 모델.
paper link: https://arxiv.org/pdf/2306.14824
Generated examples of KOSMOS-2

- 기존의 multimodal에서 수행되던 것 외에 추가적으로 multimodal referring이 가능함. 위 그림 참조
Construction of Web-Scale Grounded Image-Text Pairs(GRIT)
- image-text pair인 COYO-700M과 LAION 2B로부터 시작하여 구축됨.
-
COYO-700M
- https://huggingface.co/datasets/kakaobrain/coyo-labeled-300m
- https://huggingface.co/datasets/kakaobrain/coyo-700m{ 'id': 841814333321, 'url': 'https://blog.dogsof.com/wp-content/uploads/2021/03/Image-from-iOS-5-e1614711641382.jpg', 'text': 'A Pomsky dog sitting and smiling in field of orange flowers', 'width': 1000, 'height': 988, 'image_phash': 'c9b6a7d8469c1959', 'text_length': 59, 'word_count': 11, 'num_tokens_bert': 13, 'num_tokens_gpt': 12, 'num_faces': 0, 'clip_similarity_vitb32': 0.4296875, 'clip_similarity_vitl14': 0.35205078125, 'nsfw_score_opennsfw2': 0.00031447410583496094, 'nsfw_score_gantman': 0.03298913687467575, 'watermark_score': 0.1014641746878624, 'aesthetic_score_laion_v2': 5.435476303100586 } -
LAION 2B
-
https://laion.ai/blog/laion-5b/
Dataset columns We provide these columns : URL: the image url, millions of domains are covered TEXT: captions, in english for en, other languages for multi and nolang WIDTH: picture width HEIGHT: picture height LANGUAGE: the language of the sample, only for laion2B-multi, computed using cld3 similarity: cosine between text and image ViT-B/32 embeddings, clip for en, mclip for multi and nolang pwatermark: probability of being a watermarked image, computed using our watermark detector punsafe: probability of being an unsafe image, computed using our clip based detector
-
-
Step 1: Generating noun-chunk-bounding-box pairs
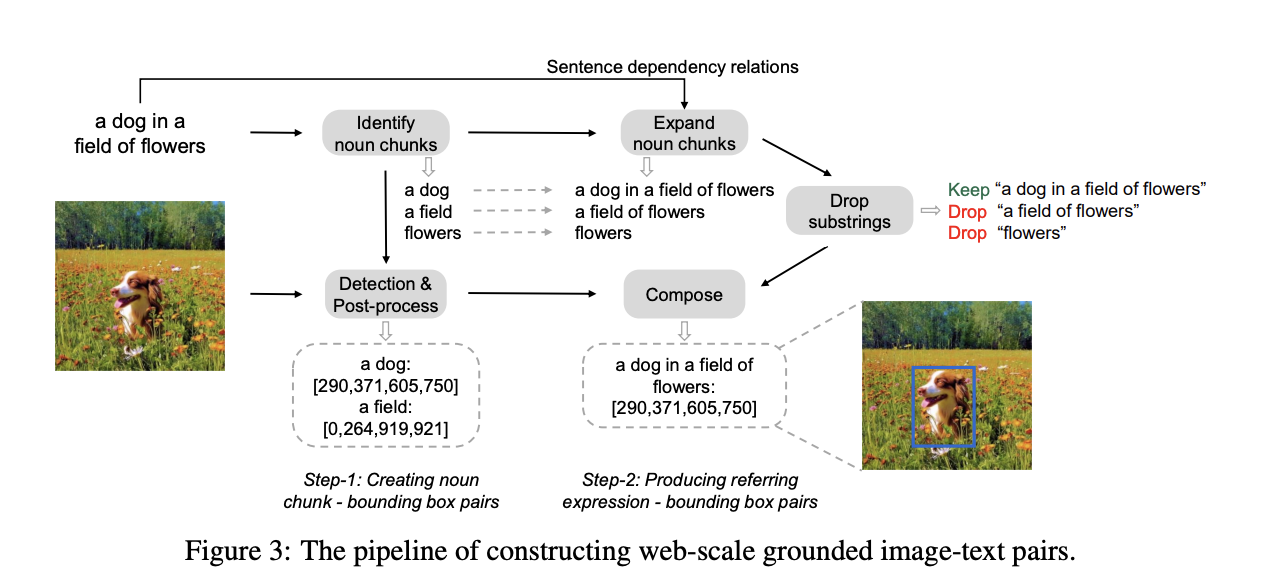
- spaCy를 통해 LAION 또는 coyo의 caption에서 명사를 추출.
- image에서 찾아내기 어려운 time, love 등과 같은 추상적인 명사들은 제거.
- 명사들과 연관된 object들의 bounding box를 찾기 위해 GLIP 사용.
- Non-maximum suppression 알고리즘 적용.
- noun-chunk-bounding-box pairs의 confidence score가 0.65보다 높은 것들만 남김. 만약 남겨진 pair가 없으면 그 image-caption pair 데이터는 날림.
Step 2: Producing referring-expression-bounding-box pairs
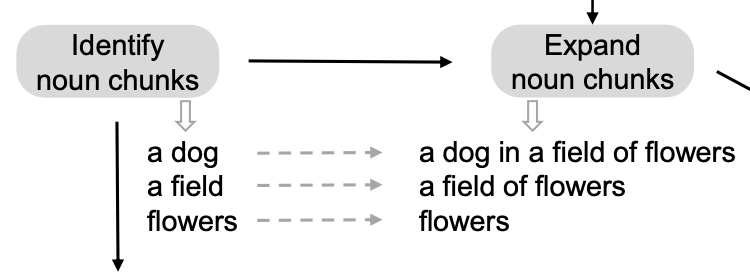
- 명사를 추출한 뒤, spaCy를 통해 문장의 dependency relation들을 얻어냄.
- 그리고 각각의 명사들을 referring expression으로 바꾸기 위해, 뒤의 부분을 이어붙여 가면서 referring expression을 완성시킴.
- 겹치는 referring expression들 중에 다른 referring expression에 포함되는 것들은 제외시킴. → a field of flowers는 a dog in a field of flowers에 속하기 때문에 제외함.
- 최종적으로 남은 referring expression 중 noun chunk 부분에 적합한 bounding box를 referring expression과 연결지음.
- Example of GRIT


KOSMOS-2: A Grounded Multimodal Large Language Model
- 구조와 training objective는 KOSMOS-1과 같음.
- KOSMOS-1의 구조
와 토큰 사이에 vision encoder를 통해 임베딩된 값들이 들어가게 됨.
- 학습 때 CLIP의 마지막 레이어를 제외하고는 freeze함.
- 구조가 특별하다기 보다는 interleaved image and text data를 가지고 학습한 것이 유의미한 성과를 낸 것으로 보임.
- 그리고 최종적으로 이미지 임베딩을 LLM에 입력으로 넣을 수 있는 차원으로 맞춰주기 위해 latent queries를 학습하는 방식인 Flamingo의 Resampler를 이용.

- KOSMOS-1의 training objective → next token prediction
Grounded Input Representations
- KOSMOS-1의 방식과 비슷하게 여러 정보들(bounding box나 location 등)을 나타내는 데 special token들을 사용함.
- top-left 점이 있는 segement의 정보와 bottom-right 점이 있는 segment의 정보를 통해 bounding box를 나타냄. 그리고 그것을
<box>와 같은 special token으로 감싸줌.<box><loc1><loc2></box>
- 그리고는 hyperlink처럼 꾸며주기 위해, 바운딩 박스의 object를 설명하기 위한 text span을
<p>태그로 감싸줌. →<p>text span</p><box><loc1><loc2></box> - 전체 예시

<grounding>토큰은 image에 존재하는 text에 대한 output을 생성 시작하기 위한 신호를 주는 토큰- 위의 예시는 아래의 예시를 표현하기 위한 input representation

Grounded Multimodal Large Language Models
- KOSMOS-2는 이전 모델과 다르게 bounding box에 대한 정보도 생성 가능. 이전 모델은 단순 text 생성만 됐음.
- 조금 더 세부적인 task들이 가능하다는 점.
Model Training
- KOSMOS-1과 거의 비슷하지만 location에 관한 토큰 추가
- Image encoder 부분은 224224 픽셀의 이미지를 1414 픽셀크기로 총 16*16=256 패치로 자름.
- location token은 77 픽셀 크기만큼을 커버함. 그리하여 3232=1024개의 추가적인 토큰이 vocab에 추가됨.
- Instruction tuning template 예시

Evaluation
Evaluation of multimodal grounding and referring
Phrase Grounding
- 이미지 내에서 phrase에 대한 bounding box 탐지
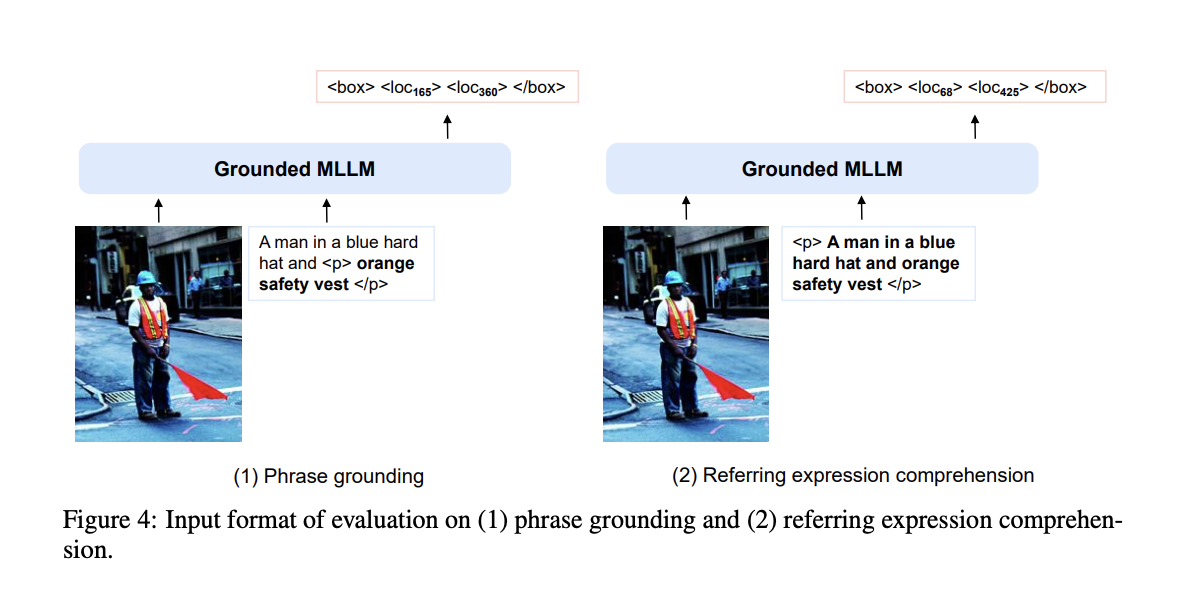
- evaluation을 할 때 multimodal grounding의 능력에 대해 평가해야 함.
- 따라서 input format은 다음과 같이 함.
- input prompt:
<s><image> Image Embedding </image><grounding> <grounding>토큰부터 이후에 생성되는 토큰은 location에 관한 정보가 있는 location token- 통상적으로는
<box>…</box>와 같은 방식으로 생성되는데, 만약 location token이 하나만 생성되었으면 이는 오답으로 처리.
- input prompt:
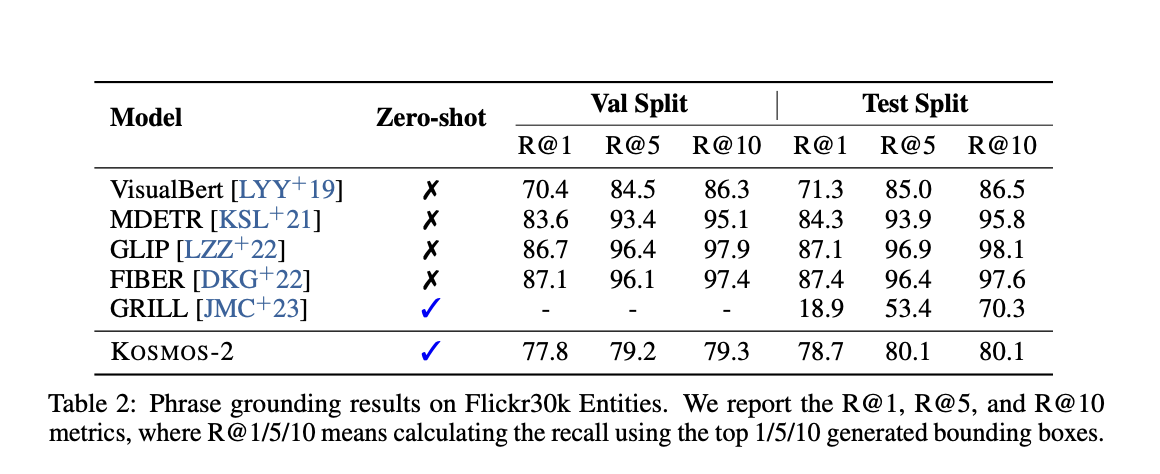
https://github.com/BryanPlummer/flickr30k_entities

Referring Expression Comprehension
- 이미지 내에서 bounding box에 대한 캡션 생성.
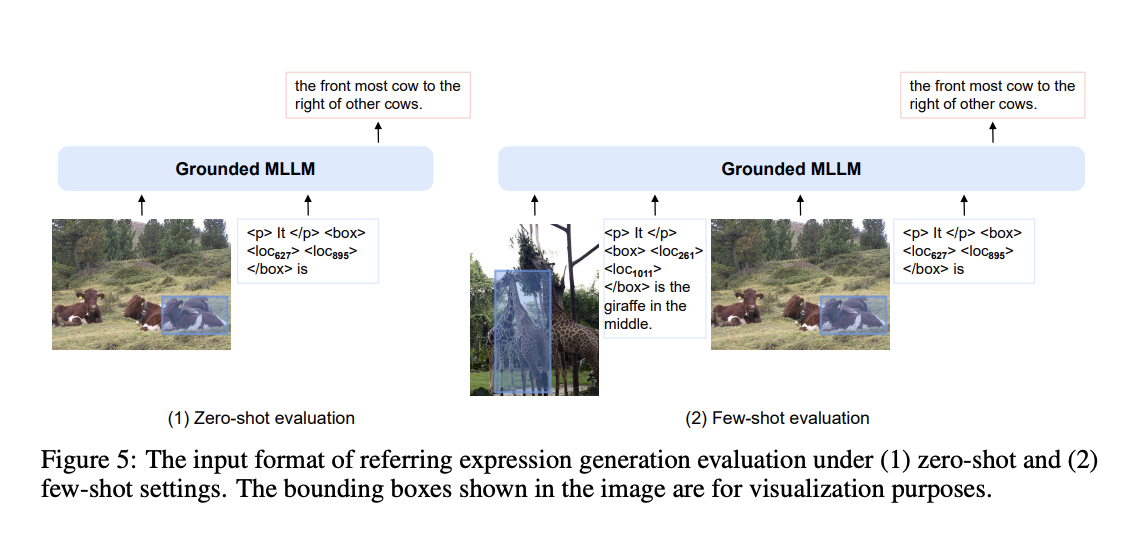
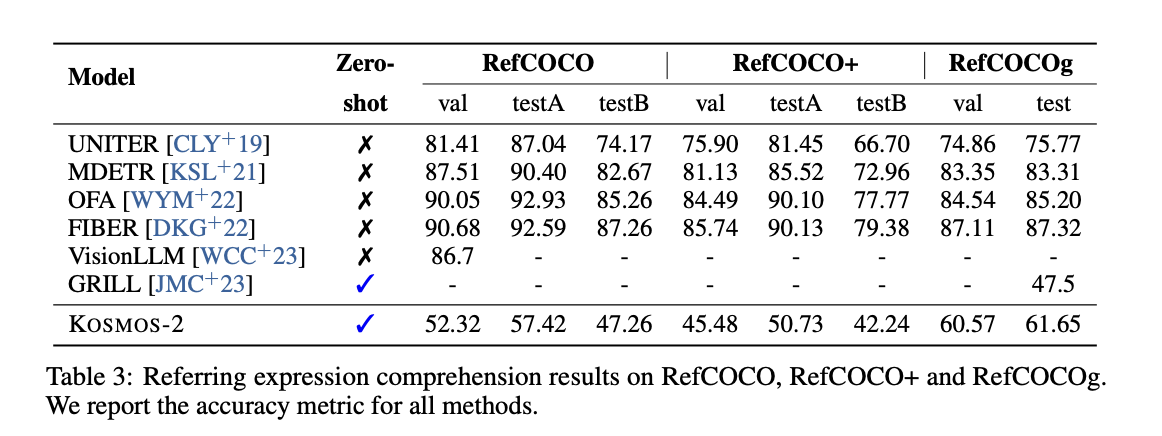
- 바운딩박스가 잘못 처리된 에러가 있다고도 함.

Perception-Language Tasks
- 기본적인 vision language model 능력치 평가
- image captioning
- visual question answering
- instruction tuning을 하면, 위 평가에 대해서 좋을 수 밖에 없기 때문에, KOSMOS-2도 KOSMOS-1과 같이 instruction tuning이 없는 버전의 체크포인트를 가지고 평가 진행.
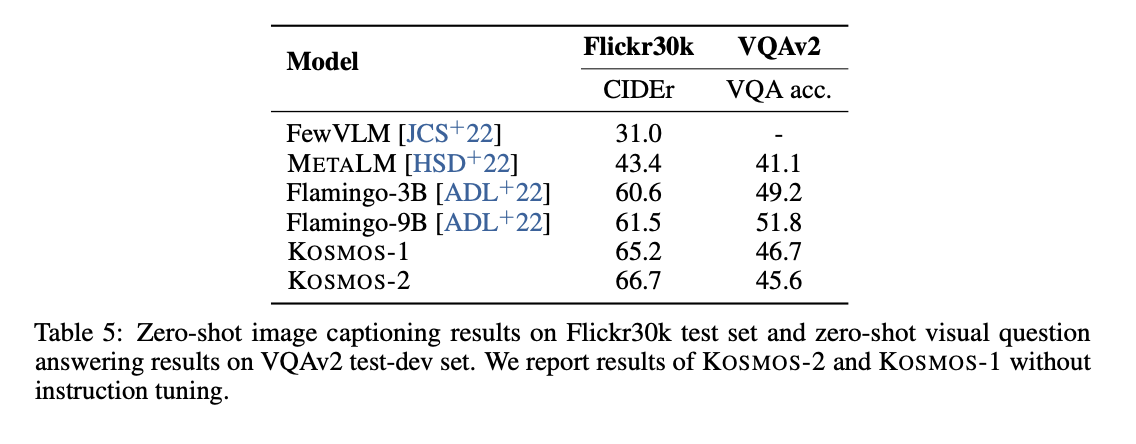
Language Tasks
- LLM 부분이 있으니 LLM의 능력치가 떨어지진 않았는지에 대한 평가.
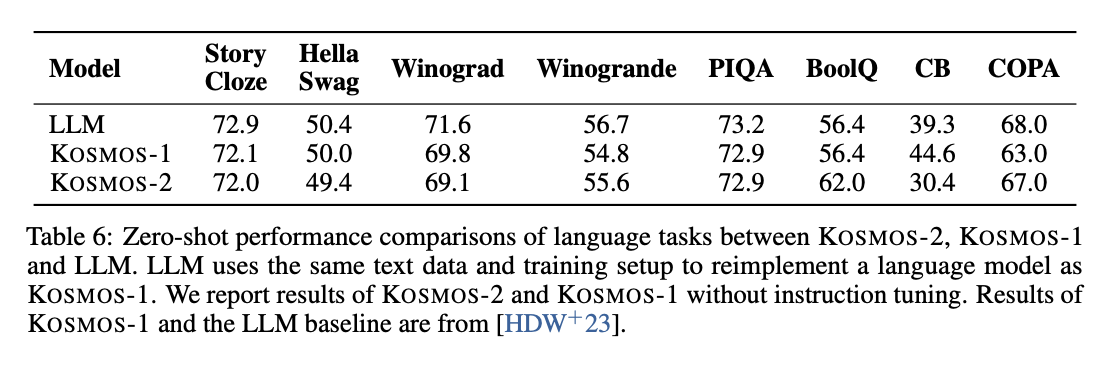
- LLM은 KOSMOS-1의 LLM component를 떼 와서 평가 진행.
- 여러 가지 modality를 합쳐서 더 다양한 task를 수행할 수 있게 되었음에도 불구하고 성능이 크게 하락하지 않음.
Comment
- 기본적으로 이전 multimodal과 유사한 방식으로 진행되었고, 안 되던 task를 확장시켰다는 contribution이 있어 보임. vision language 모델이라면 vision에서 수행했던 task들을 수행할 수 있어야 하는데, 이전 논문들은 단순히 VQA나 image에 대한 description만 가능했다면 본 논문은 bounding box도 추론할 수 있다는 점이 있음.
- 데이터셋을 잘 가공하여 이러한 결론에 도달했다는 것으로 보임.
- 이 당시는 아직은 MLLM의 태동이라 가능한 task를 확장하는 느낌이 강함.

매일 매일 한 걸음씩 나아가고자 합니다.