Finetuned Language Models are Zero-Shot Learners Review(a.k.a FLAN)
0
References
paper : https://arxiv.org/pdf/2109.01652.pdf
Abstract
- 본 논문은 언어 모델의 zero-shot 학습 능력의 향상을 위한 방법론에 대한 논문이다.
- 그것을 본 논문에서는 'instruction tuning'이라고 한다.
- instruction tuning이란? 언어 모델을 instruction을 통해 설명된 여러가지 데이터셋을 통해 fine tuning하는 방식이다.
- 단순한 여러 가지 데이터셋에 대해서 GPT-3보다 더 좋은 성능을 보였고, 심지어 큰 차이로 GPT-3보다 좋은 성능을 보인 것도 있다.
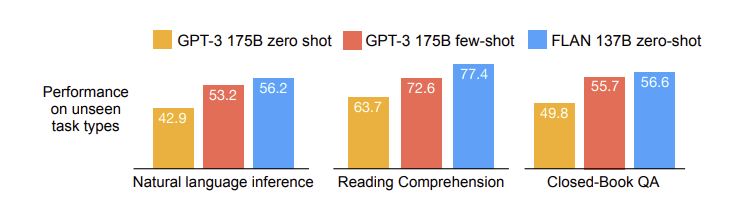
- 위의 표는 여러 가지 학습 시에 하지 않았던 task들에 대해 기본적인 GPT-3와 비교한 것이다.
- 이러한 표와 모델의 방법론을 생각하면, finetuning하는 데이터셋의 종류, 모델의 크기, 자연어 instruction들이 중요한 요소로 생각된다. (중요한 요소로 생각되는 것에 대한 자세한 내용은 Ablation study를 참고하면 좋을 것이다.)
Introduction
- GPT-3 는 few-shot 학습에서 주목할 만한 성능을 보인다.
- 하지만 zero-shot 학습 방식에서는 reading comprehension, question answering, 그리고 natural language inference등등의 부분에서 낮은 성능을 보인다.
- 그 이유는 무엇일까? 잠재적인 이유는 few-shot 예시가 없다면, 사전학습된 데이터의 형태와 유사하지 않은 prompt에 대해 좋은 성능을 보여주기 어려울 것이기 때문이다.
- 따라서, 이전에 NLP task에서 좋은 성능을 냈던 방식들(Pretrain-finetune + Prompting)을 합쳐서 새로운 방식을 제시한다.
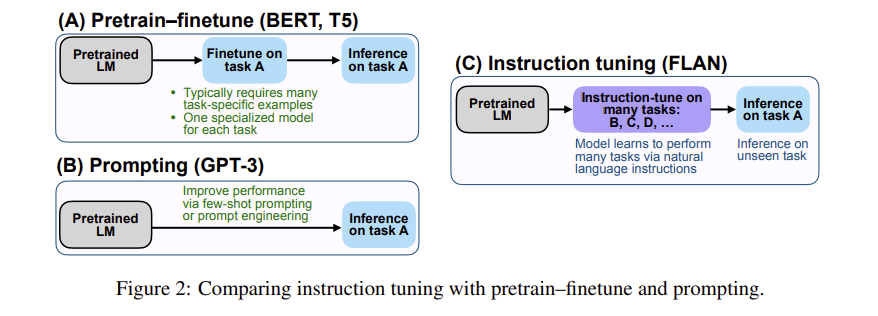
FLAN : Instruction Tuning Improves Zero-Shot Learning
- FLAN이 지향하는 아이디어는 다음과 같다.
- 지도 학습 방식과 task에 대해 묘사되어 있는 instruction을 활용하여, 언어 모델이 instruction을 잘 학습하고 학습시 본 적이 없는 task에 대해서도 잘 판단하는 방법이다.
- 평가를 하기 위해서 데이터셋을 task 타입에 맞춰 그룹을 구분 짓고, 평가를 위한 그룹에 대해서는 학습을 진행하지 않았다.
Task & Templates
- 다음은 구성한 데이터셋의 그룹에 관한 그림이다.
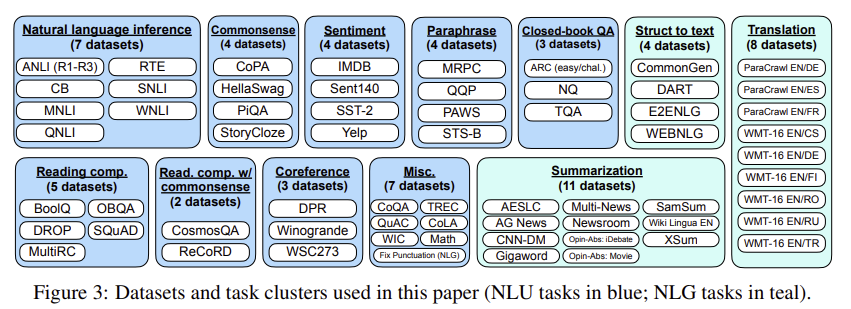
- 데이터셋의 그룹을 구성할 때, 비슷한 task에 대해서 같은 그룹으로 묶고 모든 데이터셋에 대해 instruction이 주어지는 형태로 형태를 변환했다.
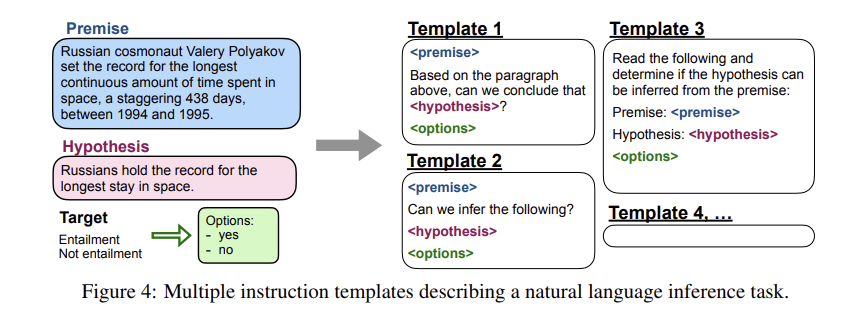
- 각각의 데이터셋에 대해서는 10개의 유일한 템플릿을 적용했다. 7개는 원래 task에 대한 설명을 기재했고, 나머지 3개의 데이터셋에 대해서는 다른 task에 대한 설명을 기재했다.
- 아래의 그림은 데이터셋의 템플릿을 통한 변환 예시다.
Evaluation Splits
- 평가 데이터셋을 구성하는 방법은 다음과 같다.
- 평가를 할 시에 본 적이 없는 데이터셋이라고 정의하는 경우는 어떤 특정 데이터셋이 포함된 클러스터의 다른 데이터셋들도 모두 instruction tuning 시에 학습하지 않는 경우다.
- 예를 들어서 read. comp. with commonsense cluster를 평가하기 위해서는 read. comp. 클러스터와 commonsense reasoning 클러스터 모두를 instruction tuning 시에 제외한다.
Classification with options
- FLAN을 통해 해결하는 task는 분류 문제 또는 생성 문제이다.
- FLAN은 decoder-only인 언어 모델을 instruction-tuning한 것이기 때문에, 생성 문제에서는 특별한 수정 없이 사용할 수 있다.
- 하지만 classification 문제에서는 따로 고려해야 할 부분이 있다.
- classification 문제에서 초기에는 그냥 target sentence를 input sentence에 맞춰서 답하는, 예를 들어, 'yes' 또는 'no'로 답장하는 형태였는데, 이 방식으로 하게 되면, 'yes' 와 'no'에 맞는 확률 질량 함수를 정확히 표현할 수 없게 된다.
- 따라서, sentence +
OPTIONS+ output class sentence 이러한 방식으로 입력 문장을 구성한 뒤, target 문장을 output class로 나타낸다.
Results
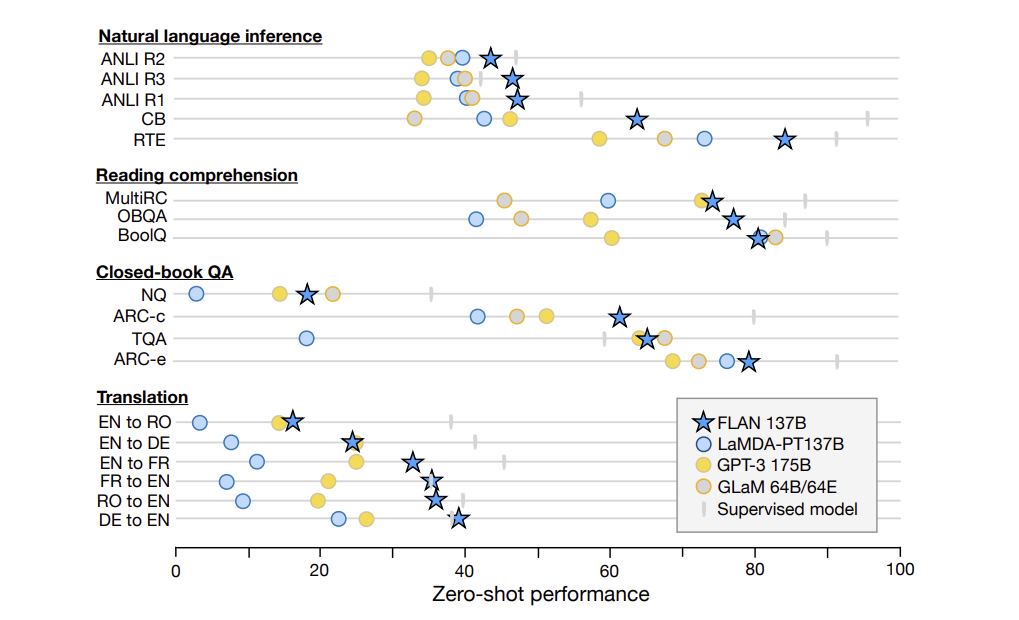
- 거의 대부분의 task에서 뛰어난 성능을 보인다.
Ablation Studies & Further Analysis
- 이 부분에서는 Ablation Study의 제목에 맞게 부분을 나눠서 실험을 진행하고 그것에 대한 결과를 본다.
- 위에 언급했던 바와 같이, finetuning하는 데이터셋의 종류, 모델의 크기, 자연어 instruction들이 모델 성능에 어떠한 유의미한 결과를 보여주는지 실험을 통해 알아 본다.
Number of Instruction Tuning Clusters
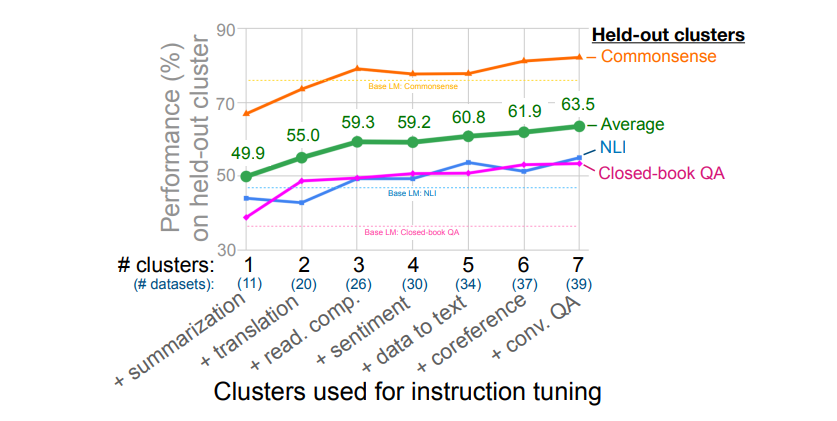
- 위의 표를 참고하게 되면 instuction tuning을 하기 위해 cluster를 추가할수록 성능이 올라간다는 것은 알 수 있다.
- 하지만 어떤 클러스터를 추가했을 때 성능에 가장 많은 기여를 하는지는 알 수 없다.
Scaling Laws
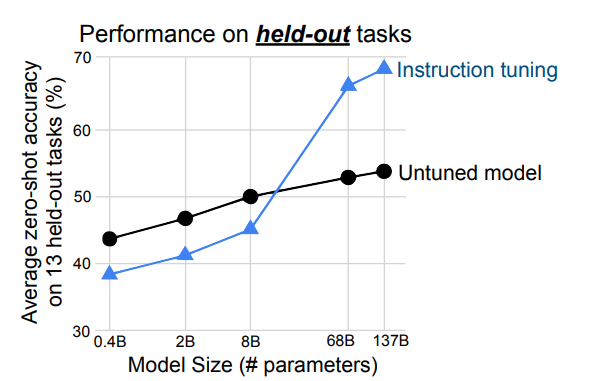
- 위의 표를 참고하게 되면 알 수 있듯이, 모델의 파라미터 개수가 굉장히 많다면 instruction tuning이 도움이 되지만, 8B 이하의 모델은 오히려 성능이 떨어진다.
- 이에 대해 추론할 수 있는 바는 모델의 파라미터 개수를 생각했을 때, 우리는 모델의 capacity에 대해 생각할 수 있다. 여러가지 task에 대한 instruction tuning이 모델의 capacity를 넘어 학습이 진행될 수 있다는 잠재적인 이유가 있다.
Role of Instructions

- 용어 설명
- FT : FineTuning
- Eval : 평가
- no instruction : (e.g., for translation the input would be “The dog runs.” and the output would be “Le chien court.”)
- instruction : FLAN 형태의 prompt
- dataset name : (e.g., for translation to French, the input would be “[Translation: WMT’14 to French] The dog runs.”)
- 위의 표에서도 마찬가지로 FLAN이 좋은 성능을 보여주는 것을 알 수 있다.

매일 매일 한 걸음씩 나아가고자 합니다.