Language Models are Unsupervised Multitask Learners(a.k.a GPT-2) Review
Reference
Abstract
- NLP에는 전통적인 Question Answering, Machine Translation, Reading Comprehension, Summarization과 같은 여러 가지 Task가 존재한다.
- 그리고 최근에는 supervised learning 방식이 아니더라도 학습이 가능할 뿐만 아니라, GPT-2와 같은 초거대 모델들은 거의 모든 부분에서의 성능 향상을 보여주고 있다.
- 이러한 점에서 보여주는 것은 이러한 초거대 모델들을 활용하여 자연적인 글에서 스스로 학습을 하도록 한다는 것이다.
Introduction
- 이 논문이 발표될 당시의 일반적인 Machine learning system의 접근 방식은 주어진 문제에 따라 데이터셋을 학습시키고, 또 그러한 데이터셋을 구하기 위해 수동적으로 라벨링하는 방식이였다.
- 그러나 위와 같은 방식은 domain generalization에서의 취약점을 보인다.
- 따라서 Multitask Learning은 여러 가지 도메인에서 좋은 성능을 보이는 일반적인 성능을 위해 해결해야 하는 문제였다.
- 하지만 그 당시 실험 결과나 이러한 것들을 고려할 때, 여러 가지 데이터셋을 직접 학습해야 했고, 따라서 많은 computing resource를 필요로 하고, 지속적으로 데이터셋을 수집하는데 어려움을 겪었다.
- 이러한 문제점을 해결하고자 나온 아이디어가 바로 pre-training 과 supervised fine-tuning 이다.
- 그러나 pre-training과 supervised fine-tuning 방식 또한 특정 task를 행하기 위해 supervised learning 방식의 training이 필요하다.
- 따라서 본 논문에서는 language model의 강력함과 zero-shot setting 방식으로 down-stream task를 행할 수 있음을 보여준다.
- 즉, 파라미터나 모델 아키텍처의 수정 없이도 학습을 가능케 한다.
Approach
- 당시 나오는 논문의 기본 형태는 unsupervised distribution estimation 방식이다.
- 자연어처리 분야에서는 다양한 길이의 sequence가 입력으로 language model로 들어간다. 입력으로 넣은 뒤 확률의 계산을 통해 문장 내 다음 토큰을 추정하고, 또 추정한다.
- 즉, 다양한 길이의 문장(이 다음과 같은 조건부확률의 곱으로 계산이 된다.
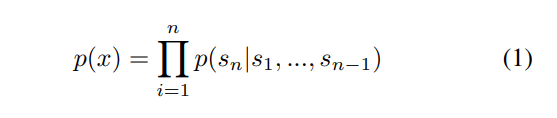
- MQAN 논문의 방법을 참조하게 되면 다음과 같은 방식으로 general한 task를 풀어나갈 수 있다.
- 특정한 하나의 task에 대해 학습을 수행하기 위해는 간단하게 다음과 같이 나타낼 수 있다.
- - 위의 (1)의 식을 간단하게 나타낸 것이다. 에 따라 이 나올 확률을 계산한다.
- 그러나 여러 다른 task에도 general하게 동작하게 하기 위해서는 식은 다음과 같이 되어야 한다.
- 따라서, 번역에 대한 task에서는 (translate to french, english text, french text)인 sequence가 (어떤 task, 입력, 출력)과 같은 방식으로 학습이 진행된다.
- 또 다른 예시로 reading comprehension에 대한 예시로는 (answer the question, document, question, answer)인 sequence가 (어떤 task, 입력, 출력)과 같은 방식으로 학습이 진행된다.
- 이처럼 여러 가지 다른 task가 있다 하더라도 위와 같은 format을 유지하여 language model의 유연성을 활용할 수 있다. 따라서 language 모델의 아키텍처를 변경하는 등의 행위를 할 필요없이 여러 가지 다른 task에 대해 학습이 가능하다.
- 위와 같은 시사점을 참고하여, language 모델을 explicit한 supervised learning 방식을 이용하지 않고도 학습을 할 수 있다.
- 지도적 목적함수가 비지도적 목적함수와 같기 때문에, 최적의 파라미터를찾는 과정에서 지도적 목적함수에서의 global minimum이 비지도적 목적함수에서의 global minimum과 같을 것이다.
- 이러한 방식으로 unsupervised learning 방식과 language model을 활용하여 여러가지 domain에 대해 학습하는 multi-task learning을 할 수 있다.
Language Model Architecture
- 기본적인 언어 모델의 구조는 Transformer based의 아키텍처이다.
- BERT와는 달리 Decoder 모델로 구성되어 있다.
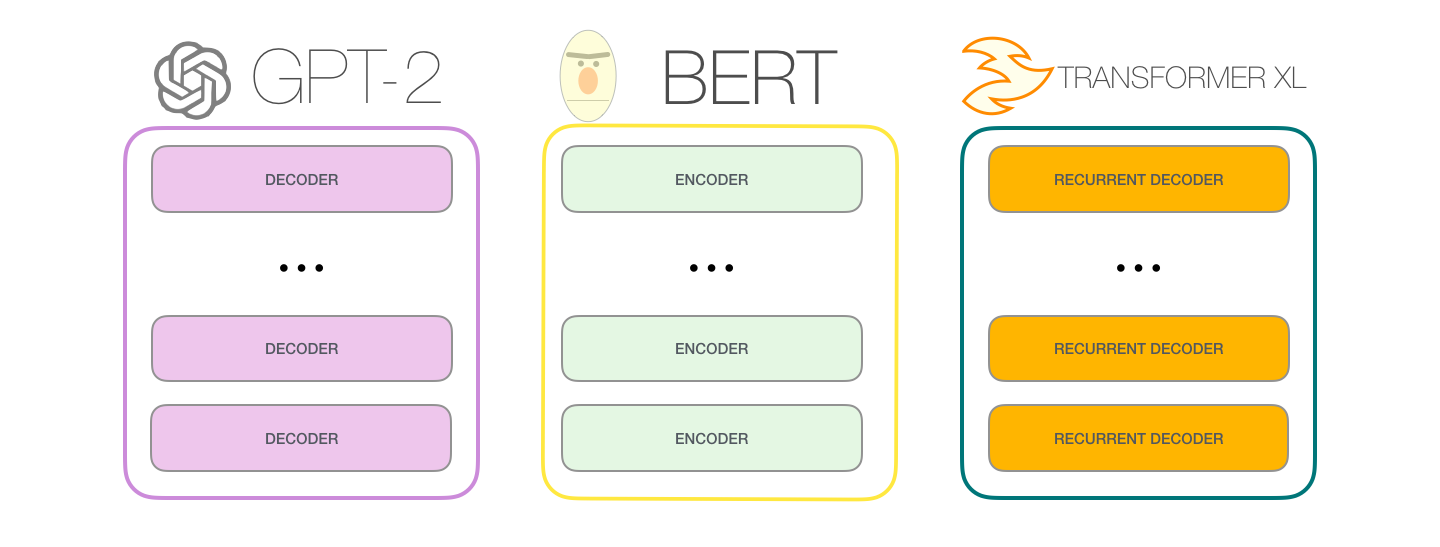
- 출처 : https://jalammar.github.io/illustrated-gpt2/
Discussion & Conclusion
- language model의 크기만 충분히 크고 데이터만 충분히 많다면, 간단한 zero shot setting을 통해 여러 가지 task에 대해 학습이 가능하다.
- 하지만 아직 특정 몇몇 분야(summarization 등등)에서는 일반적인 성능만을 보인 것으로 보아 연구할 부분이 더 많이 남아 있다.

매일 매일 한 걸음씩 나아가고자 합니다.