It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners 리뷰
Reference
https://arxiv.org/pdf/2009.07118.pdf
Abstract
- 사전 학습된 language model과 이러한 모델들을 스케일 업한 GPT-3와 같은 뛰어난 모델이 있음. 또한 GPT-3는 few-shot에서 주목할 만한 성능을 보여줌.
- 하지만 GPT-3의 파라미터 개수는 1750억개로 너무 크다는 단점이 명확히 존재함.
- 따라서 본 논문에서는 작은 language 모델로 NLU를 해결하는 방식을 보여줌.
Introduction
-
기존의 pretrained된 language model을 활용하는 접근 방식은 사전 학습된 LM(language model)의 output layer를 교체하여 classifier를 학습하거나 주어진 task에 적절하게 가공하는 fine-tuning 방식이였음.
-
하지만, LM은 그 자체만으로도 아주 강력한 사전 학습 방식을 갖고 있고, cloze question 형태를 통해, unlabeled 데이터셋이나 라벨이 거의 붙어 있지 않은 데이터셋으로도 학습 가능함.
-> Cloze Question이란?
-> "the correct answer is _ " 와 같이 빈칸이 뚫어져 있는 문장 -
물론, GPT-3의 1750억개의 파라미터를 통해 SuperGLUE task에서 SOTA(State-of-the-art)를 달성하기는 했음. 그러나 주요한 단점들이 2가지 존재함.
-> 너무나 많은 파라미터가 필요하기 때문에, 현실 세계에서 활용 불가능.
-> GPT-3가 받아들일 수 있는 토큰의 개수는 2048토큰이라 그 이상은 받아들일 수가 없음.
-
따라서, PET(Pattern Exploiting Training) 방식을 고안하게 됨.
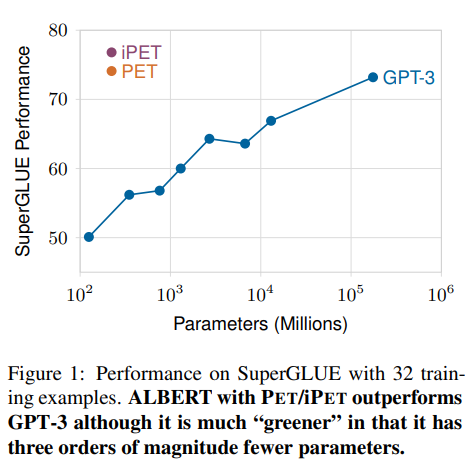
-
위의 표는 ALBERT + PET/iPET와 GPT-3의 비교 표
-
훨씬 적은 파라미터의 개수로 더 좋은 성능을 낼 수 있었음을 시사함.
Pattern-Exploiting Training
-
생소하거나 어려운 용어들이 많아서 정리를 한 번 하는게 좋음.
-
Pattern-Verbalizer Pair 용어 정리
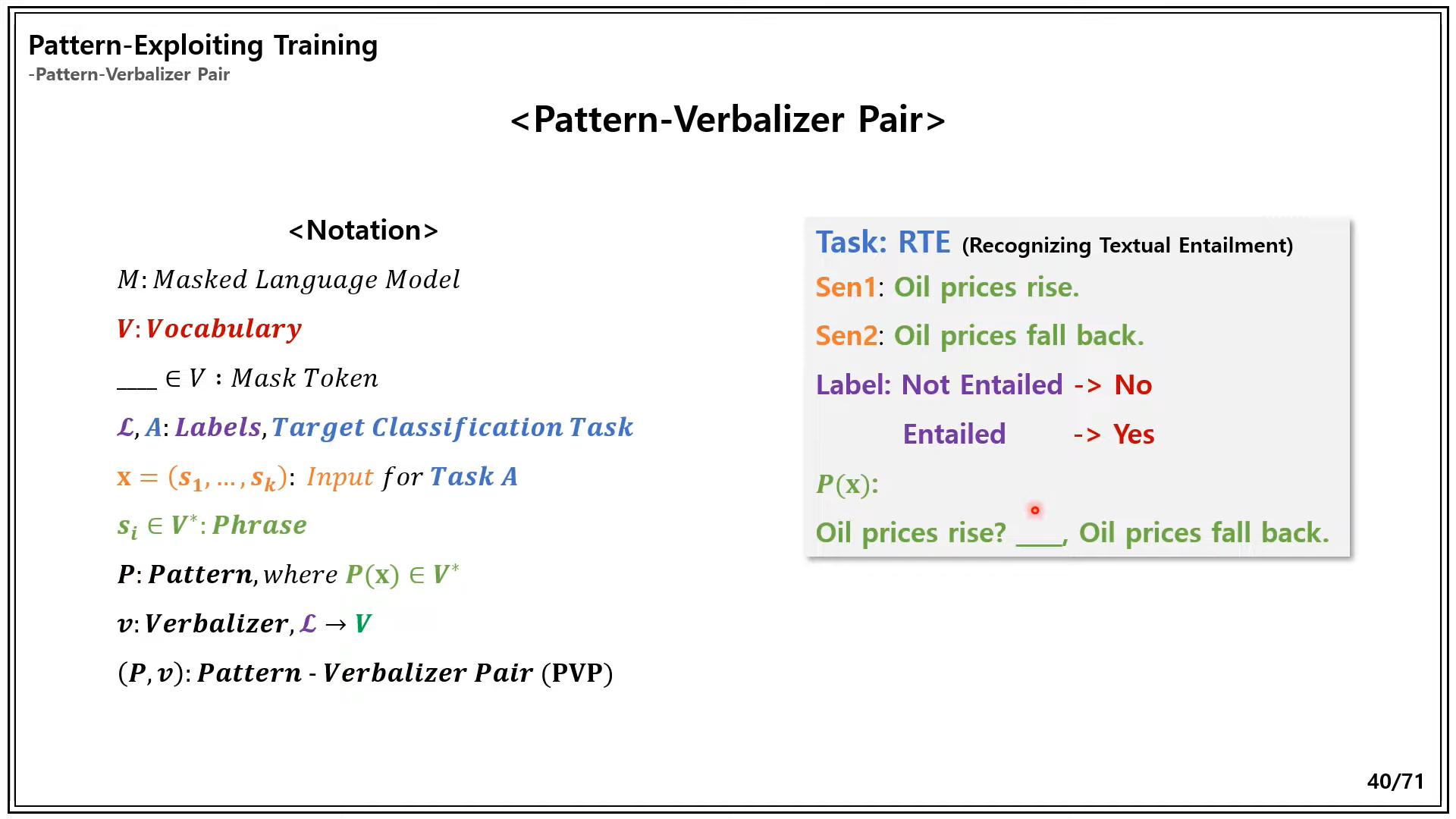
-
References : https://www.youtube.com/watch?v=q5FGZBqK-vc
-> 위의 그림과 밑의 용어 표기명은 다를 수 있음. PVP에 대한 전반적인 이해가 있어야 본 논문을 이해할 수 있음.
- M : masked language model
- T : masked language model에서 활용된 Vocabulary
-> mask token도 포함되어 있는 사전
- T* : 문장에 있는 모든 토큰 시퀀스를 포함. 최소 k개의 마스크 토큰과 일반 토큰을 포함함.
- : 아래 그림의 logits
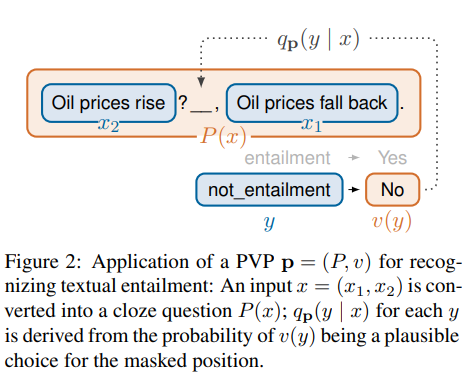
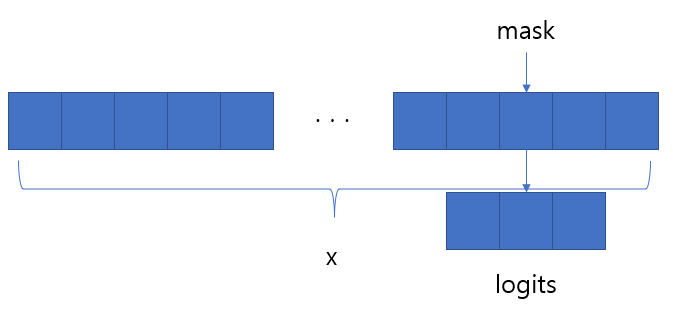
- 그렇다면 은 어떻게 구성이 될까?
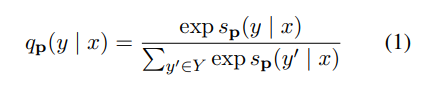
- x : x1과 x2를 포함한 input 시퀀스
- y : 정답 라벨
- v(y) : vocabulary에 존재하고 cloze question 패턴에 맞게 변형된 y
- 위의 값들을 통해 가 구성이 되고 에서 알 수 있듯이, task에 맞는 정답에 대해서만 softmax를 취함.
- 그렇다면 은 어떻게 구성이 될까?
-
how to make dataset
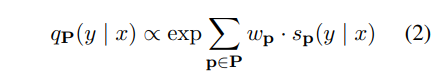
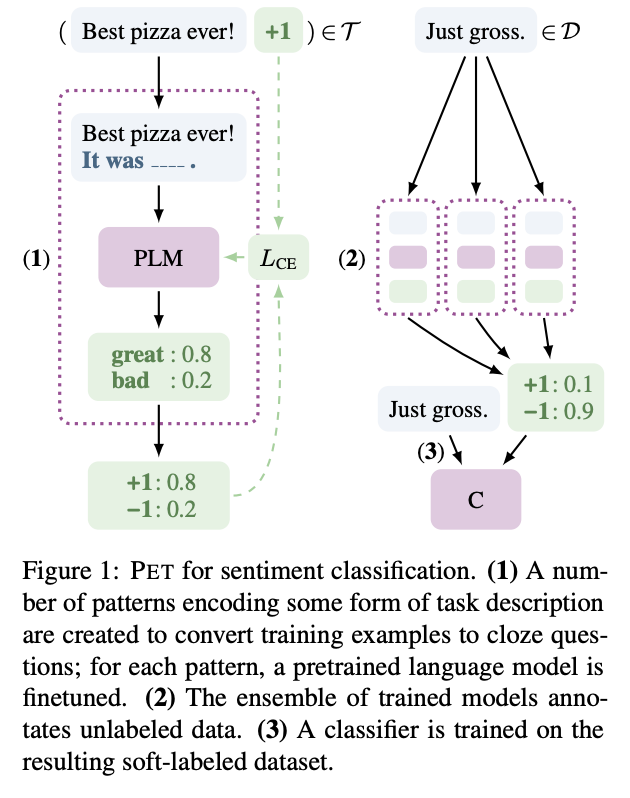
- 위의 식과 그림을 통해 soft label dataset을 구축함.
- PVP p에서 여러 가지 pattern들이 존재함. pattern들과 주어진 라벨링된 데이터셋을 활용함. fine-tuned된 MLM이 soft-label을 오토라벨링하여 데이터셋을 구성함. 위의 그림 (2) 참조
- 따라서, soft-labeled dataset과 logits 값에 대해 cross entropy loss를 최소화하는 방향으로 학습 진행.
- 위의 식과 그림을 통해 soft label dataset을 구축함.
PET with Multiple Masks
- 마스크의 개수가 여러 개일 때는 하나의 토큰으로 치환이 안 됨.
- 예를 들어, . It was __. 라는 패턴이 있을 때, 주어진 label이 존재함. 이 label이 terrible로, 즉 로 치환될 때, tokenizer에 따라 terri, ##ble 로 치환되면 2개의 mask가 생성되어야 함. 그렇게 되면 기존의 를 활용할 수 없게 됨.
- 따라서, 위와 같은 상황에서는 다른 방식을 활용함.
- auto-regressive한 방식으로 연속적으로 token을 예측함.
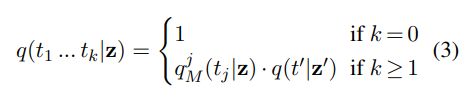
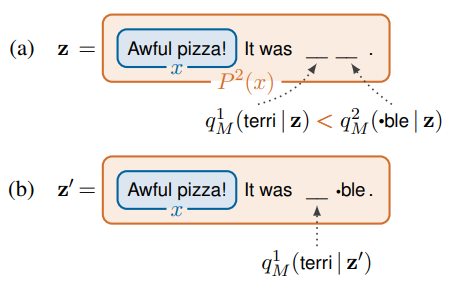
- terri와 ##ble 중 logits 값이 더 높은 것을 먼저 예측하고 연속적으로 token을 예측하는 방식으로 진행됨. 위 그림의 (a)에서 logits 값이 더 높은 것에 대한 전체 logits 값을 추출하고 그 다음 single mask 방식으로 또 logits 값을 곱하는 방식으로 진행.
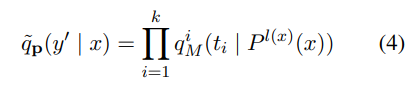
- 따라서 위와 같은 방식으로 product를 해서 진행이 됨.
- 원래 기존의 loss를 통해 학습을 진행하는 방식은 가 probability distribution이 아니므로, 즉, 합이 1이 안되므로 cross entropy loss 방식으로 학습을 진행하는 것이 아닌, multi-class hinge loss 방식으로 학습을 진행함.
