Secret of RLHF in Large Language Models Part I: PPO(Reward Modeling Part)
목표: preference tuning을 하기 위해 reward 모델들을 사용하고, PPO(Proximal Policy Optimization)을 사용하는데, 이러한 것들이 왜 필요한지에 대해 알아보는 논문이다. 또한 PPO 알고리즘이 어떻게 동작하는지에 대해서도 한 번 알아볼 수 있도록 한다.
PPO 알고리즘이 어떻게 구성되어 있길래 reward model을 만들기가 어려울까?
- PPO 알고리즘은 기본적으로 4개의 모델을 필요로 한다. Policy model, Value model, reward model, reference model
- 또한 PPO는 sparse reward와 inefficient exploration을 통해 학습하기가 쉽지 않다.
- Sparse reward라고 하는 이유는 일반적으로 강화학습을 활용한 LLM 학습 방법론에서는 step마다 보상을 주는 것이 아닌, 문장 생성을 끝내고, 그러니까 exploration을 끝내고 한 번에 보상을 주기 때문이다.
- inefficient exploration이라고 하는 이유는, word space가 워낙 넓고, 차원이 굉장히 크기 때문에 탐험해야할 공간이 너무 넓기 때문이다.
Reinforcement Learning from Human Feedback
기본적으로 3단계로 구성됨.
- Supervised fine-tuning (SFT)
- Reward model (RM) training
- proximal policy optimization (PPO)
Supervised fine-tuning
- 이 단계에서는 LLM은 사람처럼 말하는 방식을 배운다. human-annotated dialogue 예시들을 통해 사람이 말하는 방식을 따라하며 배운다. next-token prediction 방식을 loss 함수로 설계했고, 이를 통해, 확률적으로 더 높은 token을 생성해낸다.
Reward model training
- 이 단계에서는 리워드 모델은 서로 다른 human feedback에 대해 preference를 비교하는 방법을 배운다.
Proximal policy optimization
- 이 단계에서는 리워드 모델로부터의 피드백을 통해 SFT된 모델을 업데이트한다.
- SFT된 모델을 업데이트하는 과정에서 optimized policy를 찾기 위해 exploration과 exploitation을 한다.
그렇다면 일반적으로 본 논문까지 왔다면 supervised fine-tuning에 대해서는 잘 알고 있을 것이고, reward model을 어떻게 학습하고, 또 학습된 reward model과 PPO 알고리즘을 통해 SFT된 모델을 업데이트하여 optimized policy를 찾아내는지에 대해 집중해야 할 것이다.
Reward Modeling
기본 transformer 구조의 unembedding layer
입력 텍스트
│
▼
[입력 임베딩] (예: 768차원) - [위치 임베딩] (768차원)
│
▼
[Transformer 블록] (768차원)
│
▼
[최종 Transformer 레이어 출력] (768차원)
│
▼
[Unembedding Layer] (768차원 → 50,000차원)
│
▼
[Softmax] (50,000차원)
│
▼
[예측된 단어] (어휘 사전 크기 50,000)
transformer based reward model
입력 텍스트
│
▼
[입력 임베딩] (768차원) - [위치 임베딩] (768차원)
│
▼
[Transformer 블록] (768차원)
│
▼
[최종 Transformer 레이어 출력] (768차원)
│
▼
[추가 선형 레이어 (Linear Layer)] (768차원 → 1차원)
│
▼
[보상 점수] (1차원)
-
두 가지의 차이점은 마지막 softmax layer + unembedding layer를 제거하고, 추가적인 linear layer를 통해 하나의 스칼라 값으로 변환하는 것이다.
-
기본적으로 sampling된 텍스트가 주어지면, 리워드 모델은 마지막 토큰에 대해 scalar로 된 reward value를 주게 되고, 더 좋은 샘플이면, 더 좋은 리워드가 부여된다.
-
리워드 모델의 학습 방법은 paired comparison dataset을 통해 학습을 한다. 그리고 loss 함수는 다음과 같이 설계한다.
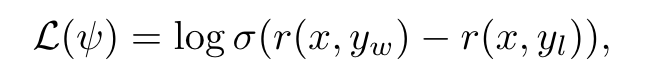
-
그리고 위 식에 imitation learning 기법의 term을 추가하고 이에 계수를 곱해 reward modeling loss를 다음과 같이 설계한다.
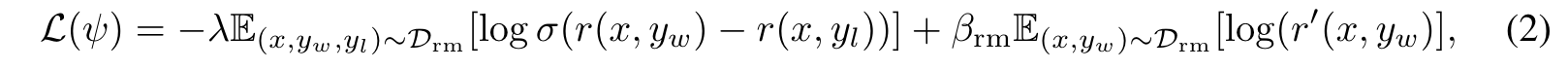
- 은 과 같은 파라미터를 가진 모델에서 최종 linear layer만 원래의 transformer 구조의 vocab linear layer로 바꾼 것이다.
- 따라서, 위의 loss 함수는 다음과 같은 2가지 목표를 가지고 있다.
- preferred response와 dispreferred response의 보상 차이를 크게 하는 것.
- preferred response처럼 LLM이 응답하게 만드는 것.
또한, 리워드를 줄 시에 sampled된 응답에 한 번에 너무 많은 보상을 주지 않기 위해, Kullback-Leibler (KL) divergence term을 추가하여 리워드를 조정한다.
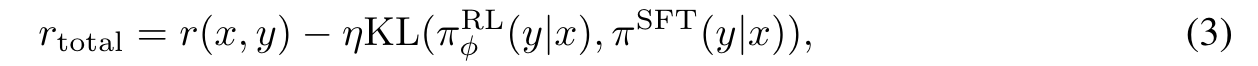
위의 식에서 알 수 있듯이, RL policy를 통해 학습되는 모델이 기존의 SFT된 모델 대비 많이 차이가 나면, penalty를 많이 부가하여 리워드를 낮추는 것이다.
이는 엔트로피 보너스라고 할 수도 있는데, 엔트로피는 정보의 불확실성의 측도이다. 이를 통해 엔트로피가 높다는 것은 에이전트가 여러 행동을 고르게 시도하게 된다는 것이다. 따라서 엔트로피 보너스라는 말은 KL term을 활용하여 특정 보상에 집중하여 모델이 조기에 수렴하는 것을 방지하고, 더 탐험을 할 수 있도록, 안정적으로 수렴할 수 있도록 하는 것이다.
회사에서 공부한 것에 대한 세미나를 하다가 이러한 질문을 받았다. '그렇다면 리워드는 어떻게 학습하는지는 알겠는데 어떻게 주는 거야?'위에 번지르르하게 설명을 해놨지만 사실 잘 와닿지는 않을 것이다. 우리가 강화학습의 미로게임 같은 것들을 생각을 해본다면 강화학습은 한 스텝, 한 스텝 갈 때마다 보상을 얻고, 결국 최종 목적지에 도착했을 때 보상이 가장 클 만한 방향으로 policy를 최적화 해가는 것이다.
여기 LLM에서는 한 스텝, 한 스텝 가는 것을 한 토큰, 한 토큰이라고 생각하면 된다. 한 토큰(한 스텝), 한 토큰(한 스텝)을 진행해서 최종적으로 eos token(목적지)에 도달했을 때 보상이 가장 클 만한 방향으로 학습을 진행하는 것이다.
즉, 정리하자면 다음과 같은 단계로 리워드 모델을 학습하는 것이다.
-
human preference 데이터셋 구축
- chosen과 rejected의 pair로 구성된 데이터셋을 구축한다. 그리고, 초기 reward model은 SFT된 모델의 weight으로 초기화를 하든, 더 작은 모델을 SFT를 해서 그 모델의 weight를 사용하든 적절한 방식을 활용하면 된다.
-
human preference 데이터셋을 통한 리워드 모델 학습
- 모델을 학습하기 위한 loss함수는 위와 같다. transformer 구조의 특정 weight으로 초기화된 모델을 통해 각각의 scalar 값을 도출한 뒤, chosen response에 대해서 리워드 값은 커지고, rejected response에 대해서 리워드 값은 작아지도록 하여 학습된다.
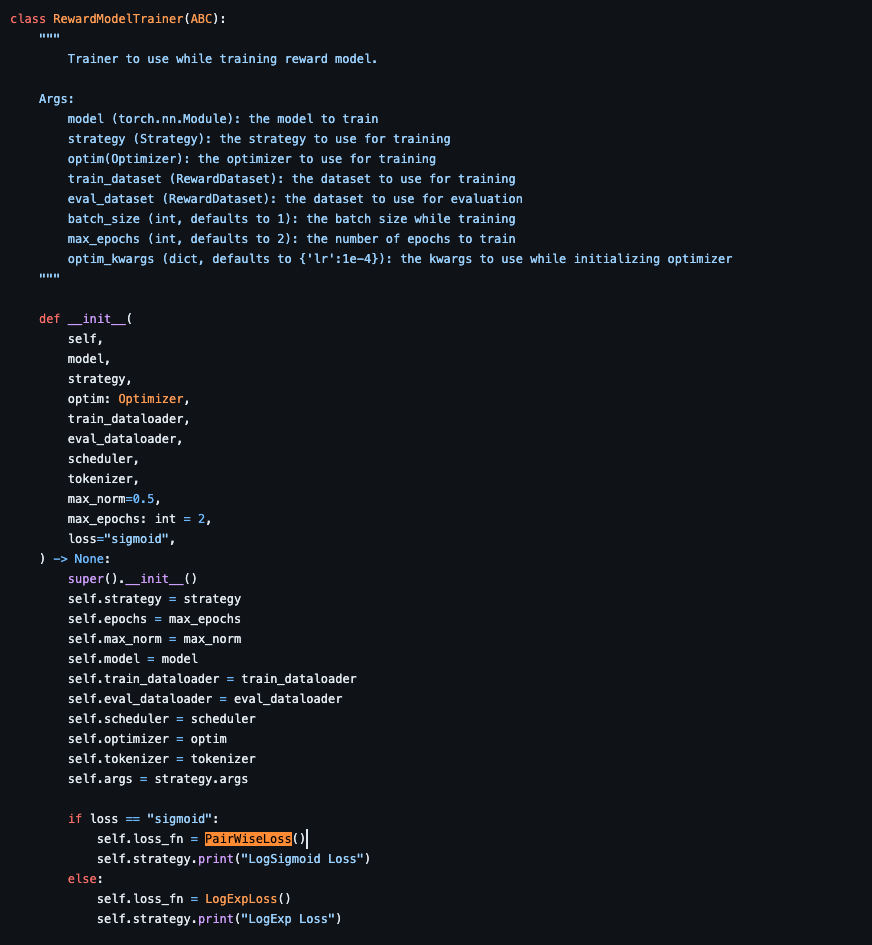
- referenced by OpenRLHF
- 위 과정에서 리워드 모델이 human preference에 대해서 배우는 것이다.
이제 이렇게 학습된 리워드 모델을 통해 최적화하고자 하는 policy에 대해 reward를 부여하는 것이다.
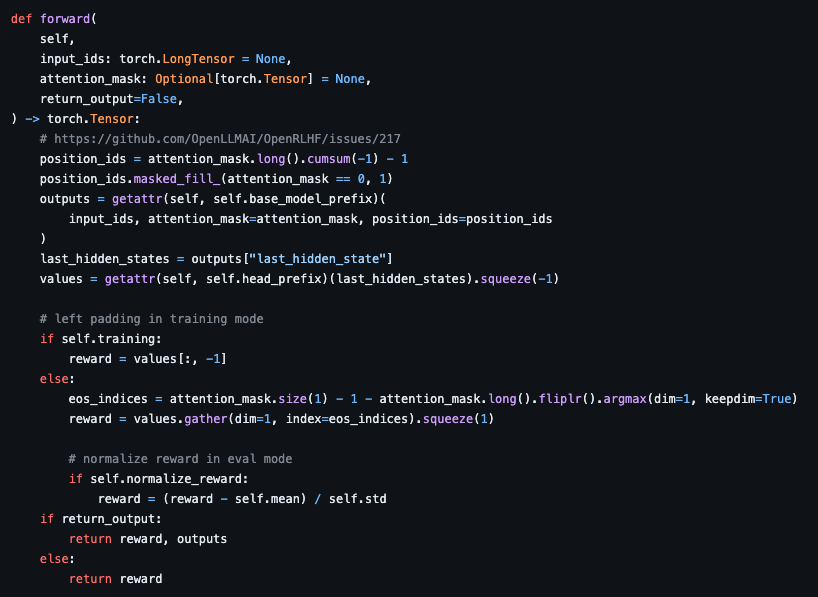
리워드 모델의 코드를 보게 되면, eos token의 리워드를 output으로 사용한다.(eos_indices 부분 확인)이는 next token prediction을 생각했을 때, 이전 token의 영향으로 eos token이 나오게 되고, 이 값을 최종 reward로 판단하는 것이다. 강화학습의 미로게임에서 최종 목적지에 도착했을 때의 reward를 계산하는 것과 같은 것이다.
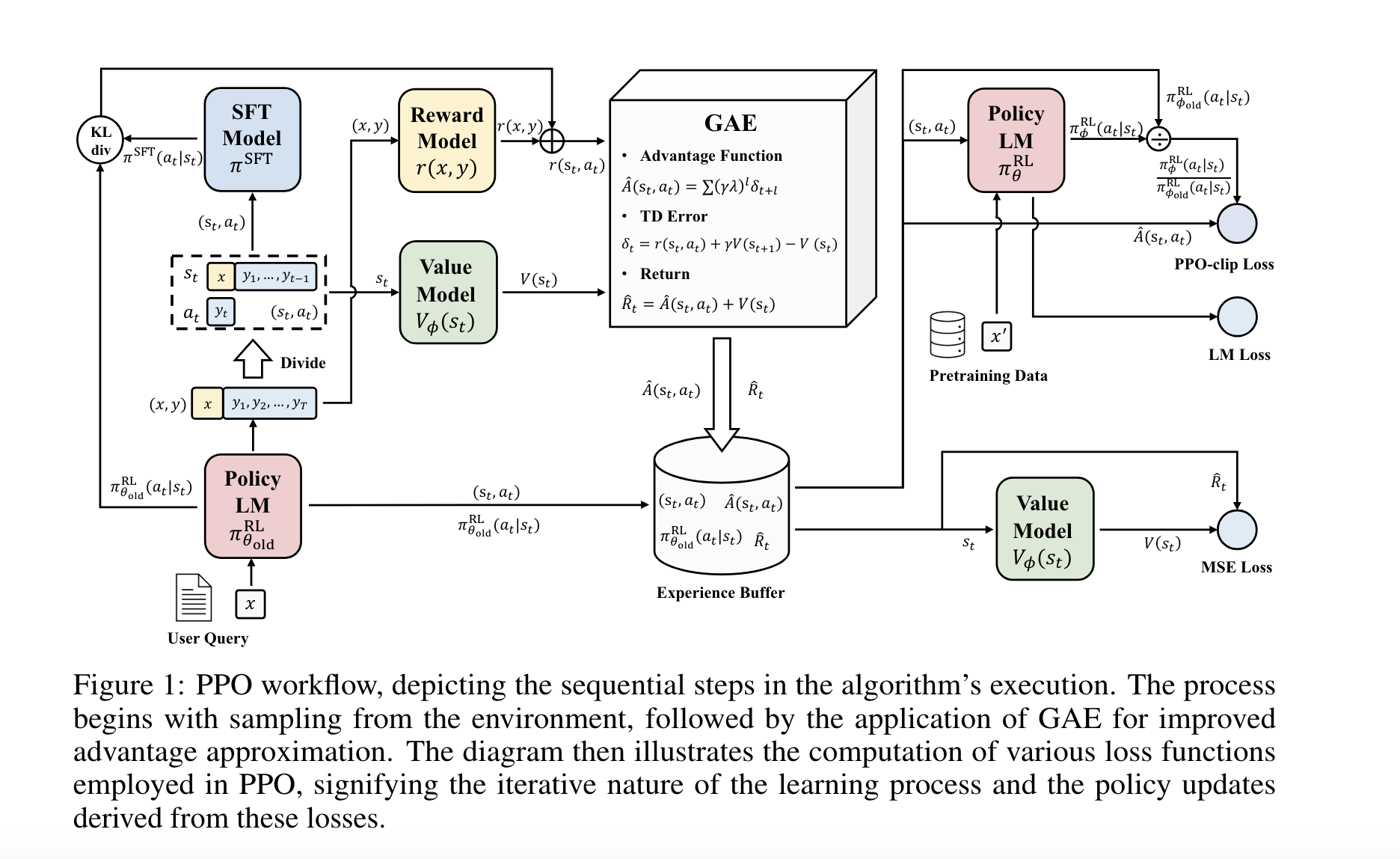
PPO 알고리즘, GAE 개념 등은 다음 포스트에서 작성할 것.
