추정
추정이란, 모평균, 모표준편차와 같이 모집단의 특성을 나타내는 값을 표본을 이용하여 추측하는 것을 말한다.
-
추정(estimation)
모집단의 모수를 모를 경우 표본으로 추출된 통계량을 모집단의 근사값으로 사용하는 것을 추정이라고 한다.
-
추정량(estimator)
표본 평균으로 모평균을 추정할 때 표본 평균을 모평균에 대한 추정량이라고 한다.
-
모수를 추정 하는 방법에는 점추정 과 구간 추정이 있다.
- 점추정(point estimation) : 모수를 하나의 특정값으로 추정 하는 방법
- 구간 추정(interval estimation) : 모수가 포함될 수 있는 구간을 추정하는 방법
🔰 점추정

🔰 구간추정

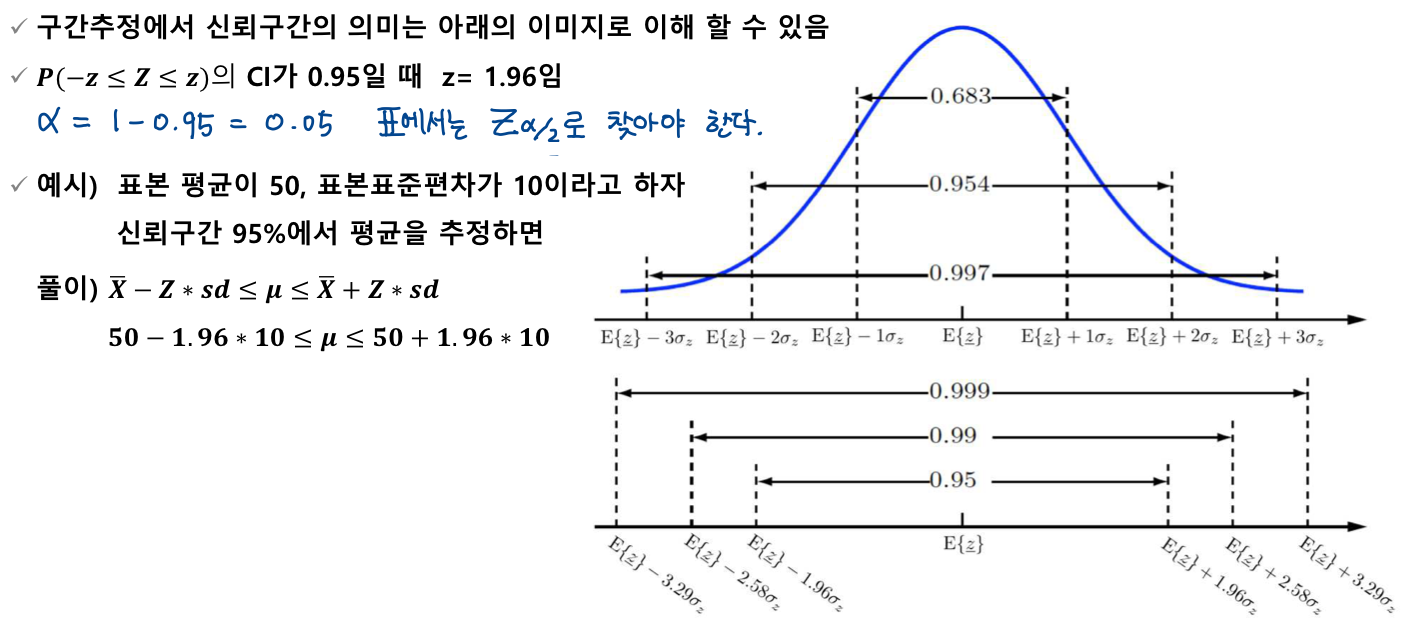
모평균의 구간추정
🔰 모평균의 신뢰구간


🔰 표본 크기 결정
-
허용오차(d)를 가지고 표본의 크기(n)를 결정할 수 있다.
n=(dz2α×σ)2
-
허용오차(Permissible Error) : 추정한 값이 틀려도 허용할 수 있는 오차
-
정규분포의 신뢰구간을 통해 허용오차를 계산한다.
P( ∣Xˉ−μ∣≤d )=1−α
⇒ d=z2α×n σ ⇒ n=d zα/2 ⋅ σ
모비율의 추정
- 모집단에서 어떤 사건에 대한 비율을 고려할 때 그 비율을 그 사건에 대한 모비율 p라 한다.
🔰 모비율의 점추정:표본비율
-
비율에 대한 추정으로 우리가 원하는 속성(class)에 속하면 ‘1’ 아니면 ‘0’ 일 때,
1의 속성을 갖는 것의 개수를 X라고 하면 X∼B(n, p)이다.
이때 모비율의 점추정량을 표본비율(Sample Proportion)이라고 한다.
p^=n X
- ex. A대학의 취업에 성공한 학생의 비율은 몇 %일까?
표본을 통해 전체 비율을 추정할 수 있다.
-
모집단에서 어떤 사건에 대한 모비율이 p일 때, 크기가 n인 표본을 임의추출하면 표본비율 p^에 대하여
평균, E(p^)=E(n X )=n1 E(X)=n1 np=p
분산, V(p^)=V(n X )= n21 V(X)= n21 np(1−p)
=n p(1−p) =n pq
표준편차, σ(p^)=n pq (단, q=1−p)
🔰 모비율의 구간추정
-
모비율 구간 추정에서 정규분포의 근사가 가능한 대표본(n≥30)은 보통 np>5, n(1−p)>5를 동시에 만족해야 한다.
-
n이 충분히 크면 C.L.T(중심극한정리)에 의해서
Z=p(1−p)/n p^−p ∼ N(0, 1)
-
표본비율의 분포
모비율이 p이고 표본의 크기 n이 충분히 클 때,
표본비율 p^은 근사적으로 정규분포 N(p, n pq )를 따른다. (단, q=1−p)
- 확률변수 Z=pq/n p^−p 는 근사적으로 표준정규분포 N(0, 1)을 따른다.
-
모집단에서 임의추출한 크기가 n인 표본의 표본비율 p^에 대하여 표본의 크기 n이 충분히 크면 모비율 p의 신뢰구간은 다음과 같다. (단, q^=1−p^)
P(−z2α≤Z≤z2α)=1−α
⇒P⎝⎜⎛−z2α≤n p(1−p) p^−p≤z2α⎠⎟⎞=1−α
⇒P(−z2α×n p(1−p) ≤p^−p≤z2α×n p(1−p) )=1−α
⇒P(p^−z2α×n p(1−p) ≤p≤ p^+z2α×n p(1−p) )=1−α
-
ex.
20대 전체의 A사 핸드폰 사용률을 알기 위해서 무작위로 500명을 대상으로 조사한 결과 212명이 A사 핸드폰을 사용 중이었다.
20대 전체의 A사 핸드폰 사용률에 대한 추정값을 구하고 95% C.I.(신뢰구간)을 구하시오.
-
p^=500212=0.424 , z2α=z0.025=1.96
-
np^=500×500212 > 5 , n(1−p^)=500×500288 > 5 를 만족하므로 정규분포를 따른다고 볼 수 있다.
-
p^−z2α×n p(1−p) ≤p≤ p^+z2α×n p(1−p)
⇒0.424−1.96×500 0.424(1−0.424) ≤p≤ 0.424+1.96×500 0.424(1−0.424)
⇒(0.38, 0.46)
🔰 모비율의 표본 크기
-
대표본(n≥30)일 때,
오차의 한계 : ∣p^−p∣≤z2α×np^(1−p^)≤d ,
(단, p^(1−p^)의 최대값은 4 1 이다.)
np^(1−p^)≤(z2αd )2 ⇒ n≥ p^(1−p^)×(d z2α)2
⇒ ∴ n≥4 1 (d z2α)2
-
ex.
20대 전체의 A사 핸드폰 사용률을 알기 위해 A 사용률을 추정할 때,
추정에 대한 95% 신뢰구간으로 오차의 한계를 0.01로 하기 위한 표본의 크기는?
모평균 차이의 추정
각 모집단에서 추출한 두 표본(Sample)을 비교하는 방법이다.

🔰 모평균 차이의 점추정
∙ E(X1ˉ−X2ˉ)=E(X1ˉ)−E(X2ˉ)=μ1−μ2
∙ Var(X1ˉ−X2ˉ)=Var(X1ˉ)−Var(X2ˉ)=n1σ12+n2σ22
🔰 모평균 차이의 구간 추정
-
대표본 : n≥30
-
모분산을 아는 경우 대표본이든 소표본이든 Z분포를 사용한다.
-
Z=n1σ12+n2σ22 (X1ˉ−X2ˉ)−(μ1−μ2) ∼N(0, 1)
-
P(−z2α≤Z≤z2α)=1−α
⇒P(−z2α≤σ12/n1+σ22/n2 (X1ˉ−X2ˉ)−(μ1−μ2) ≤z2α)=1−α
⇒P⎝⎜⎛(X1ˉ−X2ˉ)−z2α⋅n1σ12+n2σ22≤μ1−μ2≤(X1ˉ−X2ˉ)+z2α⋅n1σ12+n2σ22 ⎠⎟⎞
-
ex.

-
소표본, 모분산을 모르는 경우
-
모분산을 모르는 경우 소표본일 때 T분포를 사용한다.
-
두 모집단의 분산을 아는 경우 대표본과 동일하게 추정 가능하지만,
모분산을 모르는 경우 등분산 가정이 추가적으로 필요하다.
즉, 두 모집단의 분산이 같다는 가정이 필요~!!! σ12=σ22=σ2
-
합동 분산 추정량(Pooled Variance Estimator)
공통 분산의 추정량 Sp2=n1+n2−2 (n1−1)s12+(n2−1)s22
∘ T=Spn11+n21 (X1ˉ−X2ˉ)−(μ1−μ2) ∼T(n1+n2−2)
∘ P(−t2α, (n1+n2−2)≤Sp1/n1+1/n2 (X1ˉ−X2ˉ)−(μ1−μ2) ≤t2α, (n1+n2−2))=1−α
⇒P⎝⎜⎛(X1ˉ−X2ˉ)−t2α, (n1+n2−2)⋅Spn11+n21≤μ1−μ2≤(X1ˉ−X2ˉ)+t2α, (n1+n2−2)⋅Spn11+n21 ⎠⎟⎞
-
ex.
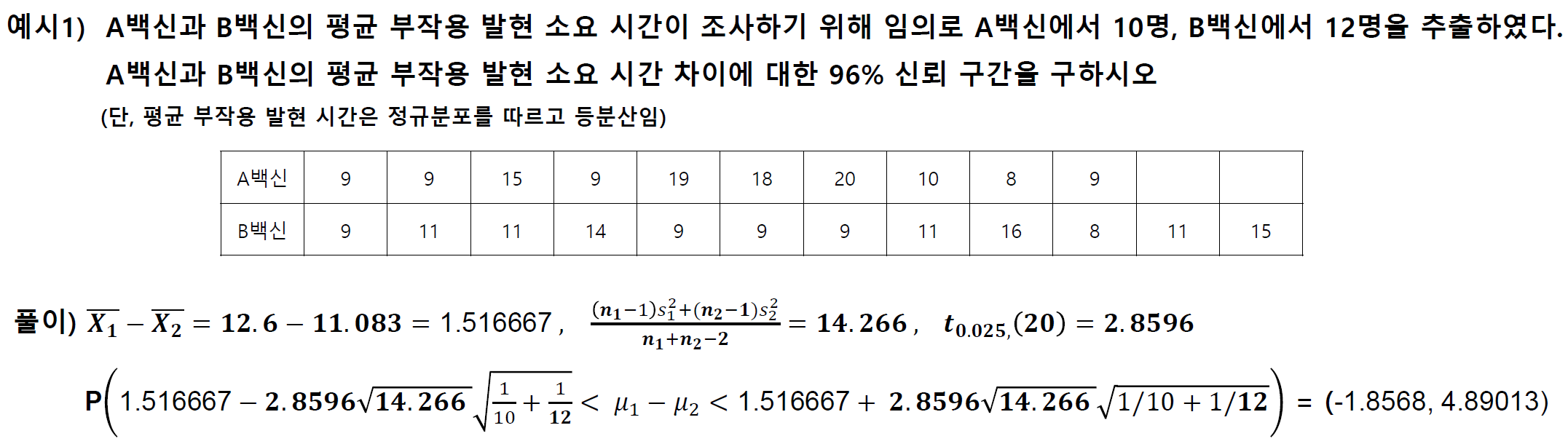
모비율 차이의 추정
🔰 모비율 차이의 점추정
∙ E(p1^−p2^)=E(p1)−E(p2)=p1−p2
∙ Var(p1^−p2^)=Var(p1)−Var(p2)=n1 p1(1−p1) +n2 p2(1−p2)
🔰 모비율 차이의 구간 추정
∙ Z=n1p1(1−p1)+n2p2(1−p2) (p1−p2)−(p1−p2) ∼ N(0, 1)
∙ P(−z2α≤Z≤z2α)=1−α
⇒P⎝⎜⎛−z2α≤n1p1(1−p1)+n2p2(1−p2) (p1−p2)−(p1−p2) ≤z2α⎠⎟⎞=1−α
⇒P((p1−p2)−z2α⋅n1p1(1−p1)+n2p2(1−p2)≤ p1−p2≤(p1−p2)+z2α⋅n1p1(1−p1)+n2p2(1−p2))
- ex.


