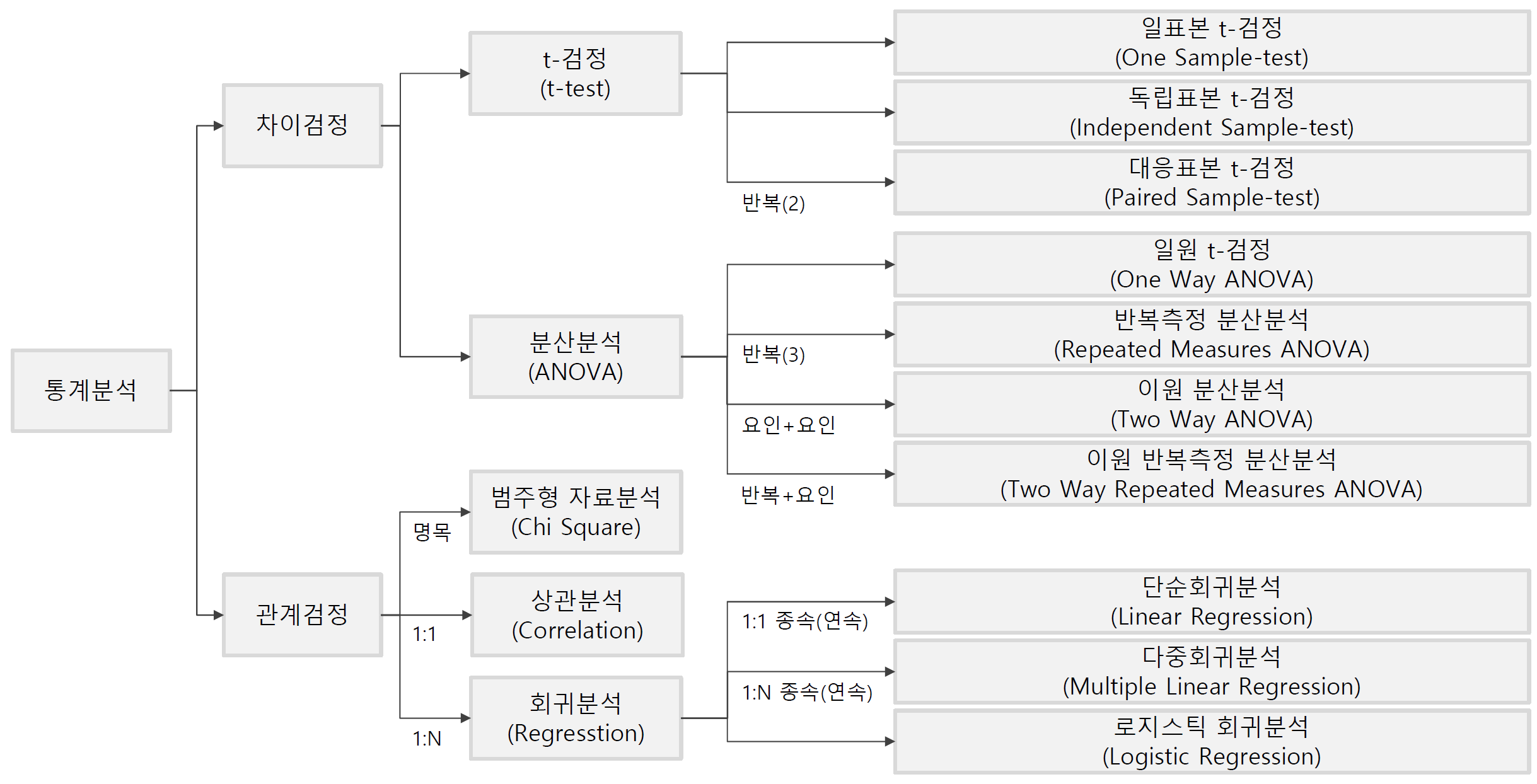
통계분석
가설검정
가설이란?
주어진 사실 또는 조사하려고 하는 사실에 대한 주장 또는 추측이다.
통계학에서는 특히 모수를 추청 할 때 모수가 어떠하다는 증명하고 싶은 추측이나 주장을 가설이라고 한다.
[가설검정(Hypothesis Testing) 절차 ]
가설수립H 0 H_0 H 0 H 1 H_1 H 1
유의수준 설정: 유의수준 α \alpha α
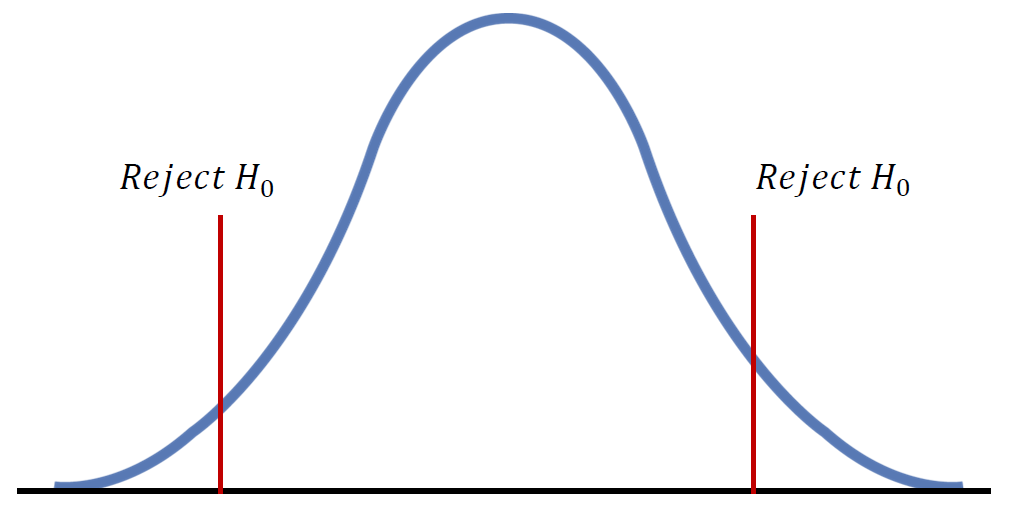
기각역(Reject Region) 설정
검정통계량 계산
의사 결정
👉 귀무 가설(Null hypothesis), H 0 H_0 H 0
기존의 사실(아무것도 없다, 의미가 없다)
대립가설과 반대되는 가설
연구하고자 하는 가설의 반대 가설로 귀무 가설은 연구 목적이 아님
Ex) H 0 \textcolor{blue}{H_0} H 0 , H 0 : μ = 0 ,~\textcolor{blue}{H_0}: \mu=0 , H 0 : μ = 0
👉 대립 가설(Alternative hypothesis), H 1 H_1 H 1
데이터로부터 나온 주장하고 싶은 가설 또는 연구의 목적이 되는 (밝혀내야 할) 가설
귀무가설의 반대
Ex) H 1 \textcolor{blue}{H_1} H 1 , H 1 : μ ≠ 0 o r μ ≥ 0 ,~\textcolor{blue}{H_1} : \mu \not= 0~~or~~\mu \ge 0 , H 1 : μ = 0 o r μ ≥ 0
👉 제1종 오류(Type 1 Error)
귀무가설이 실제로는 참이지만, 귀무가설을 기각하는 오류
H 0 H_0 H 0 α \alpha α 1 − α 1-\alpha 1 − α 제 1종오류를 범할 확률의 최대 허용 한계를 유의수준이라고 하며 α \alpha α
유의수준은 신뢰구간에 반대되는 개념이다.
👉 제2종 오류(Type 2 Error)
귀무가설을 기각해야 하지만, 귀무가설을 기각하지 않은 오류
👉 검정통계량
귀무가설이 참이라는 가정하에 얻은 통계량
검정결과 귀무가설을 기각할 충분한 근거가 있어 대립가설 H 1 H_1 H 1 H 0 H_0 H 0
검정결과 귀무가설을 기각할 충분한 근거가 없어 귀무가설 H 0 H_0 H 0
👉 P-value
귀무가설이 참일 확률로 0~1사이의 표준화된 지표(확률값) 이다.
귀무가설이 참이라는 가정하에 통계량이 귀무가설을 얼마나 지지하는지를 나타내는 확률이다.
계산된 p-value를 선택한 유의수준과 비교한다. 보통 유의수준은 0.05로 선택되는데 만약 계산된 p-value가 유의수준보다 작으면 귀무가설을 기각하고 대립가설을 채택한다. 그렇지 않으면 귀무가설을 기각할 수 없다.
👉 기각역(Reject Region)
귀무가설을 기각시키는 검정통계량의 관측값의 영역
검정통계량이 기각역 내에 포함된다면 귀무가설 H 0 H_0 H 0
👉 양측검정(two-tide test)
대립가설의 내용이 같지 않다 또는 차이가 있다 등의 양쪽 방향의 주장
ex.
A백신과 B백신의 코로나 면역력에는 차이가 있다
A팀과 B팀의 평균 연봉은 차이가 있다
양측 검정에서는 분포의 두 꼬리(tails) 양쪽에 기각역이 위치한다. ⇒ Z α 2 ~\Rightarrow~Z_{\frac{\alpha}{2}} ⇒ Z 2 α
👉 단측검정(one-side test)
한쪽만 검증하는 방식으로 대립가설의 내용이 크다 또는 작다 처럼 한쪽 방향의 주장
ex.
A제품의 수율이 B제품의 수율보다 크다
A팀의 평균 연봉이 B팀의 평균 연봉보다 크다
단측 검정에서는 분포의 한쪽 꼬리에만 기각역이 위치한다. ⇒ Z α ~\Rightarrow~Z_{\alpha} ⇒ Z α
🔰 단일 표본
❕ 모평균
✅ 모분산을 아는 경우 : Z Z Z
가설
[양측검정] H 0 : μ = μ 0 H_0 : \mu=\mu_0 H 0 : μ = μ 0 H 1 : μ ≠ μ 0 H_1 : \mu \not= \mu_0 H 1 : μ = μ 0
[단측검정] H 0 : μ ≤ μ 0 H_0 : \mu \le \mu_0 H 0 : μ ≤ μ 0 H 1 : μ > μ 0 H_1 : \mu > \mu_0 H 1 : μ > μ 0
[단측검정] H 0 : μ ≥ μ 0 H_0 : \mu \ge \mu_0 H 0 : μ ≥ μ 0 H 1 : μ < μ 0 H_1 : \mu < \mu_0 H 1 : μ < μ 0
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
검정통계량: Z = X ˉ − μ σ / n ∼ N ( 0 , 1 ) Z=\cfrac{~\bar X-\mu~}{\sigma/ \sqrt{n~}} \thicksim N(0,~1) Z = σ / n X ˉ − μ ∼ N ( 0 , 1 )
검정통계량 관측값: Z 0 = X ˉ − μ 0 σ / n Z_0=\cfrac{~\bar X-\mu_0~}{\sigma/ \sqrt{n~}} Z 0 = σ / n X ˉ − μ 0
∣ z 0 ∣ ≥ z α / 2 |z_0| \ge z_{\alpha/2} ∣ z 0 ∣ ≥ z α / 2 H 0 H_0 H 0 z 0 ≥ z α z_0 \ge z_{\alpha} z 0 ≥ z α H 0 H_0 H 0 z 0 ≤ − z α z_0 \le -z_{\alpha} z 0 ≤ − z α H 0 H_0 H 0
ex.
커피의 카페인 함량이 140mg이라고 표기 되어 있다. 이 수치가 정확한지 확인하기 위해서 조사해본 결과 100개의 제품을 대상으로 측정한 결과 평균 138.0로 확인 되었다. 표준편차가 15일 때 유의수준 0.05에서 가설 검정을 해보자.
가설: H 0 : μ = 140 H_0 : \mu = 140 H 0 : μ = 1 4 0 H 1 : μ ≠ 140 H_1 : \mu \not= 140 H 1 : μ = 1 4 0
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
양측검정하면, z 0 = X ˉ − μ 0 σ / n = 138 − 140 15 / 10 = − 2 1.5 = − 1.3333 z_0=\cfrac{~\bar X-\mu_0~}{\sigma/ \sqrt{n~}} = \cfrac{138-140}{15/10} = - \cfrac{2}{1.5} = -1.3333 z 0 = σ / n X ˉ − μ 0 = 1 5 / 1 0 1 3 8 − 1 4 0 = − 1 . 5 2 = − 1 . 3 3 3 3
∣ z 0 = − 1.3333 ∣ ≤ [ z 0.025 = 1.96 ] |z_0=-1.3333| \le [z_{0.025}=1.96] ∣ z 0 = − 1 . 3 3 3 3 ∣ ≤ [ z 0 . 0 2 5 = 1 . 9 6 ] H 0 H_0 H 0
✅ 모분산을 모르는 경우, 소표본( n ≤ 30 ) (n \le 30) ( n ≤ 3 0 ) T T T
가설
[양측검정] H 0 : μ = μ 0 H_0 : \mu=\mu_0 H 0 : μ = μ 0 H 1 : μ ≠ μ 0 H_1 : \mu \not= \mu_0 H 1 : μ = μ 0
[단측검정] H 0 : μ ≤ μ 0 H_0 : \mu \le \mu_0 H 0 : μ ≤ μ 0 H 1 : μ > μ 0 ⇒ H_1 : \mu > \mu_0 ~~~\Rightarrow~~~ H 1 : μ > μ 0 ⇒
[단측검정] H 0 : μ ≥ μ 0 H_0 : \mu \ge \mu_0 H 0 : μ ≥ μ 0 H 1 : μ < μ 0 ⇒ H_1 : \mu < \mu_0 ~~~\Rightarrow~~~ H 1 : μ < μ 0 ⇒
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
검정통계량: T = X ˉ − μ s / n ∼ t ( n − 1 ) T=\cfrac{~\bar X-\mu~}{s/ \sqrt{n~}} \thicksim t(n-1) T = s / n X ˉ − μ ∼ t ( n − 1 )
검정통계량 관측값: t 0 = X ˉ − μ 0 s / n t_0=\cfrac{~\bar X-\mu_0~}{s/ \sqrt{n~}} t 0 = s / n X ˉ − μ 0
∣ t 0 ∣ ≥ t α / 2 , d f |t_0| \ge t_{\alpha/2,~df} ∣ t 0 ∣ ≥ t α / 2 , d f H 0 H_0 H 0 t 0 ≥ t α , d f t_0 \ge t_{\alpha,~df} t 0 ≥ t α , d f H 0 H_0 H 0 t 0 ≤ − t α , d f t_0 \le -t_{\alpha,~df} t 0 ≤ − t α , d f H 0 H_0 H 0
❕ 모비율
가설
[양측검정] H 0 : p ^ = p 0 H_0 : \hat p = p_0 H 0 : p ^ = p 0 H 1 : p ^ ≠ p 0 H_1 : \hat p \not= p_0 H 1 : p ^ = p 0
[단측검정] H 0 : p ^ ≤ p 0 H_0 : \hat p \le p_0 H 0 : p ^ ≤ p 0 H 1 : p ^ > p 0 H_1 : \hat p > p_0 H 1 : p ^ > p 0
[단측검정] H 0 : p ^ ≥ p 0 H_0 : \hat p \ge p_0 H 0 : p ^ ≥ p 0 H 1 : p ^ < p 0 H_1 : \hat p < p_0 H 1 : p ^ < p 0
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
검정통계량: Z = p ^ − p p ( 1 − p ) / n ∼ N ( 0 , 1 ) Z=\cfrac{~\hat p-p~}{\sqrt{p(1-p)/n~}} \thicksim N(0,~1) Z = p ( 1 − p ) / n p ^ − p ∼ N ( 0 , 1 )
검정통계량 관측값: Z 0 = p ^ − p 0 p 0 ( 1 − p 0 ) / n Z_0=\cfrac{~~\hat p-p_0~}{\sqrt{p_0(1-p_0)/n~}} Z 0 = p 0 ( 1 − p 0 ) / n p ^ − p 0
∣ z 0 ∣ ≥ z α / 2 |z_0| \ge z_{\alpha/2} ∣ z 0 ∣ ≥ z α / 2 H 0 H_0 H 0 z 0 ≥ z α z_0 \ge z_{\alpha} z 0 ≥ z α H 0 H_0 H 0 z 0 ≤ − z α z_0 \le -z_{\alpha} z 0 ≤ − z α H 0 H_0 H 0
ex.
코로나 백신 A약에 대해서 80%이상 백신효과가 나타나야 효과가 있다고 판단하고 계속해서 약을 판매할 수 있다고 하자. 100명에 대해서 조사를 한 결과 78명만 백신 효과가 있었다고 한다면 이에 대해서 유의 수준 0.05에서 검정해보자.
가설: H 0 : p ^ ≤ 80 100 H_0 : \hat p \le \frac{80}{100} H 0 : p ^ ≤ 1 0 0 8 0 H 1 : p ^ > 80 100 H_1 : \hat p > \frac{80}{100} H 1 : p ^ > 1 0 0 8 0
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
양측검정하면, z 0 = p ^ − p 0 p 0 ( 1 − p 0 ) / n = 0.8 − 0.78 0.8 ( 0.2 ) / 100 = 1 2 = 0.5 z_0=\cfrac{~\hat p-p_0~}{\sqrt{p_0(1-p_0)/n~}} = \cfrac{0.8-0.78}{\sqrt{0.8(0.2)/100}~} = \cfrac{1}{2} = 0.5 z 0 = p 0 ( 1 − p 0 ) / n p ^ − p 0 = 0 . 8 ( 0 . 2 ) / 1 0 0 0 . 8 − 0 . 7 8 = 2 1 = 0 . 5
[ z 0 = 0.5 ] ≤ [ z 0.05 = 1.69 ] [z_0=0.5] \le [z_{0.05}=1.69] [ z 0 = 0 . 5 ] ≤ [ z 0 . 0 5 = 1 . 6 9 ] H 0 H_0 H 0
🔰 두개 표본
두 표본은 등분산이고 서로 독립이어야 한다. ∼ i i d \thicksim iid ∼ i i d
❕ 대표본
모분산을 아는 경우
가설
[양측검정] H 0 : μ 1 = μ 2 H_0 : \mu_1=\mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 ≠ μ 2 H_1 : \mu_1 \not= \mu_2 H 1 : μ 1 = μ 2
[단측검정] H 0 : μ 1 = μ 2 H_0 : \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 > μ 2 H_1 : \mu_1 > \mu_2 H 1 : μ 1 > μ 2
[단측검정] H 0 : μ 1 = μ 2 H_0 : \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 < μ 2 H_1 : \mu_1 < \mu_2 H 1 : μ 1 < μ 2
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
검정통계량: Z = ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) σ 1 2 / n 1 + σ 2 2 / n 2 ∼ N ( 0 , 1 ) Z=\cfrac{~(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)~}{\sqrt{{\sigma_1}^2/n_1 + {\sigma_2}^2/n_2}} \thicksim N(0,~1) Z = σ 1 2 / n 1 + σ 2 2 / n 2 ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) ∼ N ( 0 , 1 )
검정통계량 관측값: Z 0 = ( X 1 ˉ − X 2 ˉ ) σ 1 2 / n 1 + σ 2 2 / n 2 Z_0=\cfrac{~(\bar{X_1}-\bar{X_2})}{\sqrt{{\sigma_1}^2/n_1 + {\sigma_2}^2/n_2}~} Z 0 = σ 1 2 / n 1 + σ 2 2 / n 2 ( X 1 ˉ − X 2 ˉ )
∣ z 0 ∣ ≥ z α / 2 |z_0| \ge z_{\alpha/2} ∣ z 0 ∣ ≥ z α / 2 H 0 H_0 H 0 z 0 ≥ z α z_0 \ge z_{\alpha} z 0 ≥ z α H 0 H_0 H 0 z 0 ≤ − z α z_0 \le -z_{\alpha} z 0 ≤ − z α H 0 H_0 H 0
ex.
모집단1에서 추출한 표본의 X 1 ˉ : 35 , σ 1 2 : 8 \bar{X_1}: 35,~~{\sigma_1}^2: 8 X 1 ˉ : 3 5 , σ 1 2 : 8 n 1 n_1 n 1 X 2 ˉ : 32 , σ 2 2 : 6 \bar{X_2}: 32,~~{\sigma_2}^2: 6 X 2 ˉ : 3 2 , σ 2 2 : 6 n 2 n_2 n 2
가설: H 0 : μ 1 = μ 2 H_0 : \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 ≠ μ 2 H_1 : \mu_1 \not= \mu_2 H 1 : μ 1 = μ 2
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
검정통계량 관측값: Z 0 = ( X 1 ˉ − X 2 ˉ ) σ 1 2 / n 1 + σ 2 2 / n 2 = 35 − 32 8 / 50 + 6 / 80 = 6.188527 ~~Z_0=\cfrac{~(\bar{X_1}-\bar{X_2})}{\sqrt{{\sigma_1}^2/n_1 + {\sigma_2}^2/n_2}~} = \cfrac{35-32}{\sqrt{8/50+6/80}~} = 6.188527 Z 0 = σ 1 2 / n 1 + σ 2 2 / n 2 ( X 1 ˉ − X 2 ˉ ) = 8 / 5 0 + 6 / 8 0 3 5 − 3 2 = 6 . 1 8 8 5 2 7
∣ z 0 = 6.188527 ∣ ≥ [ z 0.025 = 1.96 ] |z_0=6.188527| \ge [z_{0.025}=1.96] ∣ z 0 = 6 . 1 8 8 5 2 7 ∣ ≥ [ z 0 . 0 2 5 = 1 . 9 6 ] H 0 H_0 H 0
❕ 소표본
모분산을 모르는 경우
가설
[양측검정] H 0 : μ 1 = μ 2 H_0 : \mu_1=\mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 ≠ μ 2 H_1 : \mu_1 \not= \mu_2 H 1 : μ 1 = μ 2
[단측검정] H 0 : μ 1 = μ 2 H_0 : \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 > μ 2 H_1 : \mu_1 > \mu_2 H 1 : μ 1 > μ 2
[단측검정] H 0 : μ 1 = μ 2 H_0 : \mu_1 = \mu_2 H 0 : μ 1 = μ 2 H 1 : μ 1 < μ 2 H_1 : \mu_1 < \mu_2 H 1 : μ 1 < μ 2
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
합동분산추정량: S p 2 = ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2 n 1 + n 2 − 2 {S_p}^2 = \cfrac{~(n_1-1){s_1}^2+(n_2-1){s_2}^2~}{n_1+n_2-2} S p 2 = n 1 + n 2 − 2 ( n 1 − 1 ) s 1 2 + ( n 2 − 1 ) s 2 2
검정통계량: T = ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) S p ⋅ 1 / n 1 + 1 / n 2 ∼ t ( n 1 + n 2 − 2 ) T=\cfrac{~(\bar{X_1}-\bar{X_2})-(\mu_1-\mu_2)~}{S_p \cdot \sqrt{1/n_1 + 1/n_2}} \thicksim t(n_1+n_2-2) T = S p ⋅ 1 / n 1 + 1 / n 2 ( X 1 ˉ − X 2 ˉ ) − ( μ 1 − μ 2 ) ∼ t ( n 1 + n 2 − 2 )
검정통계량 관측값: T 0 = ( X 1 ˉ − X 2 ˉ ) S p ⋅ 1 / n 1 + 1 / n 2 T_0=\cfrac{~(\bar{X_1}-\bar{X_2})}{S_p \cdot \sqrt{1/n_1 + 1/n_2}~} T 0 = S p ⋅ 1 / n 1 + 1 / n 2 ( X 1 ˉ − X 2 ˉ )
∣ t 0 ∣ ≥ t α / 2 , d f |t_0| \ge t_{\alpha/2,~df} ∣ t 0 ∣ ≥ t α / 2 , d f H 0 H_0 H 0 t 0 ≥ t α , d f t_0 \ge t_{\alpha,~df} t 0 ≥ t α , d f H 0 H_0 H 0 t 0 ≤ − t z α , d f t_0 \le -tz_{\alpha,~df} t 0 ≤ − t z α , d f H 0 H_0 H 0
ex.
체중 감소 보조제의 성능을 비교하기 위해 A와 B 두 군으로 나누고 약을 먹고 6개월 후 체중 변화를 측정하였다. B약이 A약보다 더 체중감소에 효과가 좋다고 할 수 있는지 유의수준 0.05에서 검정하여라.
가설: H 0 : μ A = μ B H_0 : \mu_A = \mu_B H 0 : μ A = μ B H 1 : μ A < μ B H_1 : \mu_A < \mu_B H 1 : μ A < μ B
유의수준: α = 0.05 \alpha = 0.05 α = 0 . 0 5
검정통계량 관측값: t 0 = ( X 1 ˉ − X 2 ˉ ) S p ⋅ 1 / n 1 + 1 / n 2 = − 2.7118 t_0=\cfrac{~(\bar{X_1}-\bar{X_2})}{S_p \cdot \sqrt{1/n_1 + 1/n_2}~} = -2.7118 t 0 = S p ⋅ 1 / n 1 + 1 / n 2 ( X 1 ˉ − X 2 ˉ ) = − 2 . 7 1 1 8
z 0 = − 2.7118 ≤ [ t 0.05 , 28 = − 1.701131 ] z_0=-2.7118 \le [t_{0.05,~28}=-1.701131] z 0 = − 2 . 7 1 1 8 ≤ [ t 0 . 0 5 , 2 8 = − 1 . 7 0 1 1 3 1 ] H 0 H_0 H 0
❕ 대응표본
범주형 자료분석
🔰 적합도 검정
Goodness of Fit Test
한 개의 요인을 대상으로 검정한다.
ex.
카이제곱 적합도 검정
적합도 검정은 관측된 빈도가 특정한 이론적 분포에 적합한지를 검정하는 통계적 절차로 가장 흔히 사용되는 적합도 검정은 카이제곱(χ²) 적합도 검정이다.
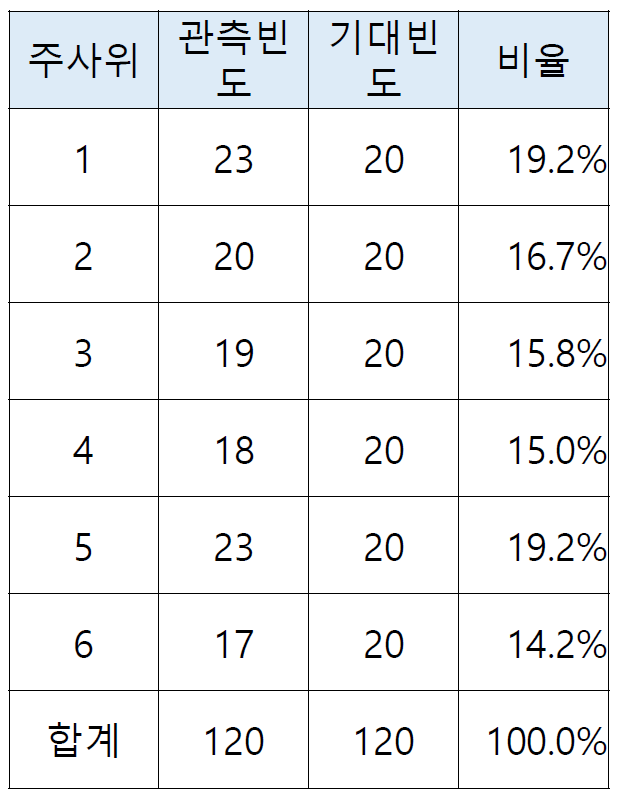
카이제곱(χ²) 적합도 검정 예시: 주사위의 공정성 검정
가설 수립
유의 수준 설정 : 0.05
기각역 설정 :
자유도 = 범주의 개수 - 1 = 5
χ 5 2 = 11.07 {\chi_5}^2 = 11.07 χ 5 2 = 1 1 . 0 7
검정통계량 계산 : 카이제곱(χ²) 통계량 계산
χ 2 = ∑ ( O i − E i ) 2 E i ~~~\chi^2 = \sum\cfrac{(O_i-E_i)^2}{E_i} χ 2 = ∑ E i ( O i − E i ) 2
O는 관찰 빈도(observed frequency): 데이터로 부터 수집된 값
E는 기대 빈도(expected frequency): 기대값과 비슷한 개념
χ 2 = ( 23 − 20 ) 2 20 + ( 20 − 20 ) 2 20 + ( 19 − 20 ) 2 20 + ( 18 − 20 ) 2 20 + ( 23 − 10 ) 2 20 + ( 17 − 20 ) 2 20 ~~~\chi^2 = \frac{(23-20)^2}{20}+\frac{(20-20)^2}{20}+\frac{(19-20)^2}{20}+\frac{(18-20)^2}{20}+\frac{(23-10)^2}{20}+\frac{(17-20)^2}{20} χ 2 = 2 0 ( 2 3 − 2 0 ) 2 + 2 0 ( 2 0 − 2 0 ) 2 + 2 0 ( 1 9 − 2 0 ) 2 + 2 0 ( 1 8 − 2 0 ) 2 + 2 0 ( 2 3 − 1 0 ) 2 + 2 0 ( 1 7 − 2 0 ) 2 = 1.6 ~~~~~~~~ = 1.6 = 1 . 6
의사결정:
🔰 독립성 검정
Test of Independence
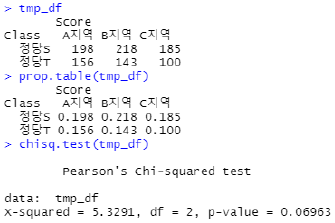
🔰 동질성 검정
Test of Homogeneity
ex.
남자와 여자는 서로 다른 모집단(Population) P 1 , P 2 P_1,~P_2 P 1 , P 2